Problem
Solve
이 또한 monotone stack 을 이용한 풀이였지만,
문제에서 lexicographical order 사전식순으로 결과값은 정해져있다고 했다.
이 사전식순이란 무엇인가하니,
cbacdcbc = adbc
cbacdcbc = adcb
cbacdcbc = badc
cbacdcbc = badc
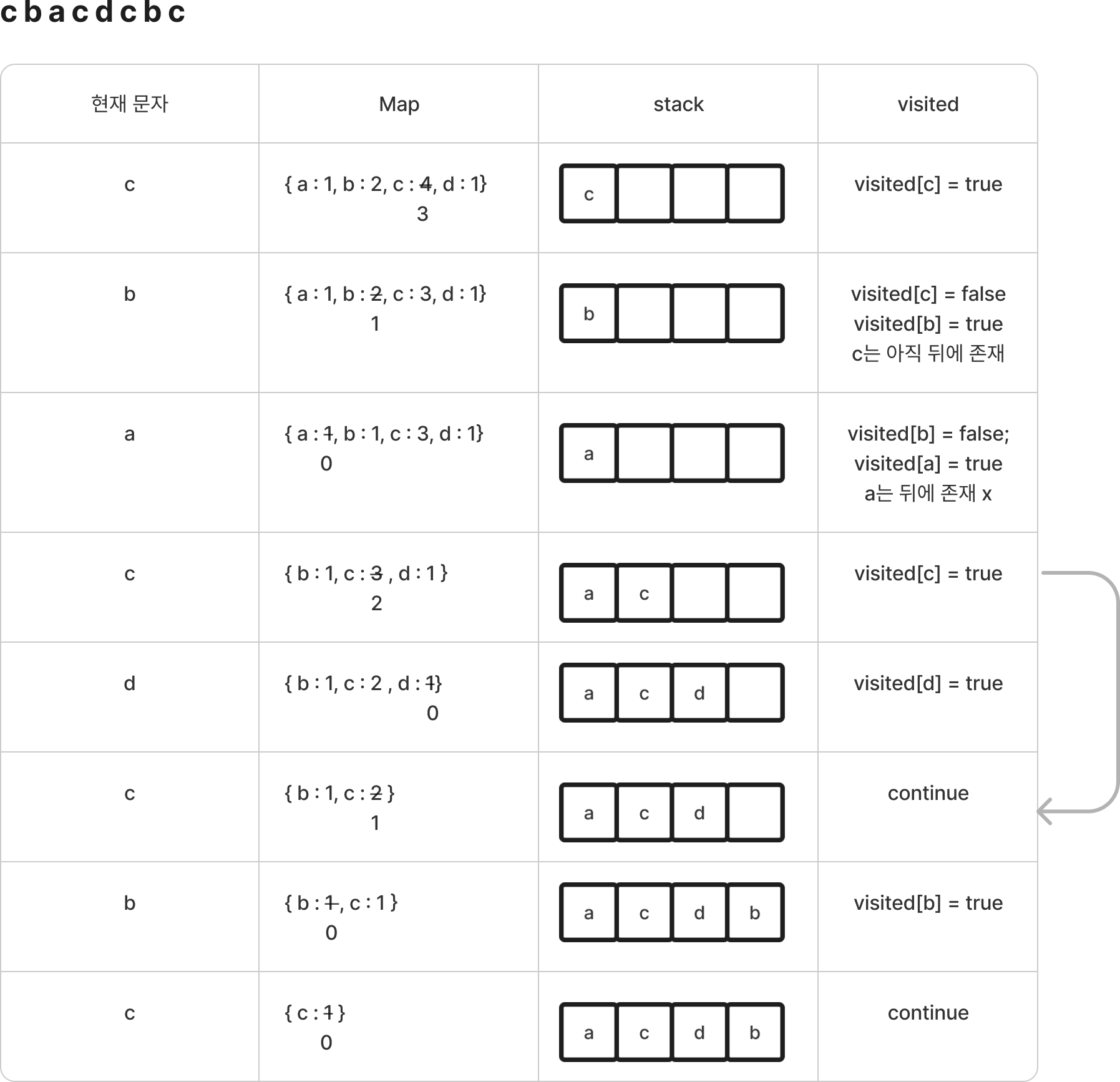
중복된 문자는 하나만 나타나되, 중복된 문자 중에서도 조합하여 사전식순으로 빠른 순이었다. 어떻게 나중의 문자를 캐치하냐인데 바로 먼저 s 문자열을 순회하면서 각각의 문자가 몇개씩있냐를 확인해보는 방법밖에 없단다.
그래서 확인하는 방법은 문자열 s 를 순회하면서 배열을 사용하느냐, map 을 사용하느냐이다.
- 배열 사용
public String removeDuplicateLetters(String s) {
Stack<Character> stack = new Stack<>();
int[] count = new int[26];
boolean[] visited = new boolean[26];
for(char c : s.toCharArray()){
count[c-'a']++;
}
for(char c : s.toCharArray()){
count[c-'a']--;
if(visited[c-'a']) continue;
while(!stack.isEmpty() && stack.peek() > c && count[stack.peek()-'a'] > 0){
visited[stack.peek()-'a'] = false;
stack.pop();
}
stack.push(c);
visited[c-'a'] = true;
}
StringBuilder sb = new StringBuilder();
for(char c : stack){
sb.append(c);
}
return sb.toString();
}알파벳 갯수만큼 배열을 만들어주고 아스키 코드를 이용한 인덱스로 문자열에 포함된 문자의 갯수를 확인한다.
그 후 monotone stack 을 이용하되 해당 문자가 문자열 뒤에 아직 남아있다면 while문을 계속 돌린다. 또, 추가적으로는 방문여부 visited이다. 이렇게 아직 남아있다면 이미 방문했더라도 방문하지 않았음을 알리는 flag로 visited = false 로 변경해준다.
그 후, stack 에 남아있는 문자가 곧 사전식으로 빠른 순이므로 pop으로 문자열을 조합하지 말고, for문을 이용하면 stack의 가장 아래쪽에 있는 순으로 문자를 조합할 수 있다.
- map 이용
public String removeDuplicateLetters(String s) {
Stack<Character> stack = new Stack<>();
boolean[] visited = new boolean[26];
HashMap<Character, Integer> map = new HashMap<>();
for(char c : s.toCharArray()){
map.put(c, map.getOrDefault(c, 0)+1);
}
for(char c : s.toCharArray()){
map.put(c, map.get(c)-1);
if(map.get(c) < 1) map.remove(c);
if(visited[c-'a']) continue;
while(!stack.isEmpty() && stack.peek() > c && map.containsKey(stack.peek())){
visited[stack.peek()-'a'] = false;
stack.pop();
}
stack.push(c);
visited[c-'a'] = true;
}
StringBuilder sb = new StringBuilder();
for(char c : stack){
sb.append(c);
}
return sb.toString();
}
이 둘의 차이는 배열을 26개까지 만들 필요가 있겠냐는 메모리의 문제로 보여지나,

위는 map을 사용했을 때,

아래는 배열을 사용했을 때를 본다면,
시간복잡도나 공간복잡도면에서는 크게 차이가 없는 것같다.
