Problem
Solve
- 중복되지 않는 문자 조합을 만들어 길이를 매 for문을 돌 때마다 체크하여 반환한다.
public static int lengthOfLongestSubstring(String s) {
if(s.length() == 0) return 0;
int max = Integer.MIN_VALUE;
for(int i = 0 ; i < s.length() ; i++){
String temp = String.valueOf(s.charAt(i));
for(int j = i+1 ; j < s.length() ; j++){
if(temp.indexOf(String.valueOf(s.charAt(j))) == -1){
//중복되지 않을 경우의 문자열 조합
temp += String.valueOf(s.charAt(j));
}else{
break;
}
max = Math.max(max, temp.length());
// System.out.println("temp : "+temp + " max : "+max);
}
}
return max == Integer.MIN_VALUE ? 1 : max;
}이 방법은 for문 두 개를 쓰므로써 O(n^2) 시간 복잡도 이기 때문에 굉장히 비효율적이다.
- 나름 커리큘럼에는 해시테이블을 이용하라고 하는데, 어떻게 사용할 수 있을까?
public static int lengthOfLongestSubstring(String s) {
Set<Character> set = new Set<>();
int max = 0;
int left = 0;
for(int right = 0 ; right < s.length ; right++){
if(!set.contains(s.charAt(right)){
set.add(s.charAt(right));
max = Math.max(max, right-left+1);
}else{
while(s.charAt(left)!=s.charAt(right)){
s.remove(s.charAt(left));
left++;
}
set.remove(s.charAt(left));
left++;
set.add(s.charAt(right));
}
}
return max;
}중복 판단을 해시 테이블이나 셋을 이용한다.
어찌보면 비슷한 패턴이긴 하나, 또 어떻게 보면 two pointers 를 사용한다고 할 수 있겠다.
그렇기 때문에 for문을 두 번 반복하지 않아도 된다.
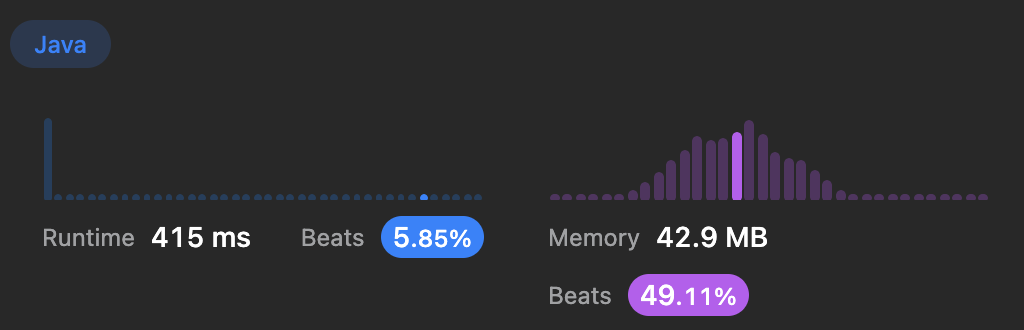
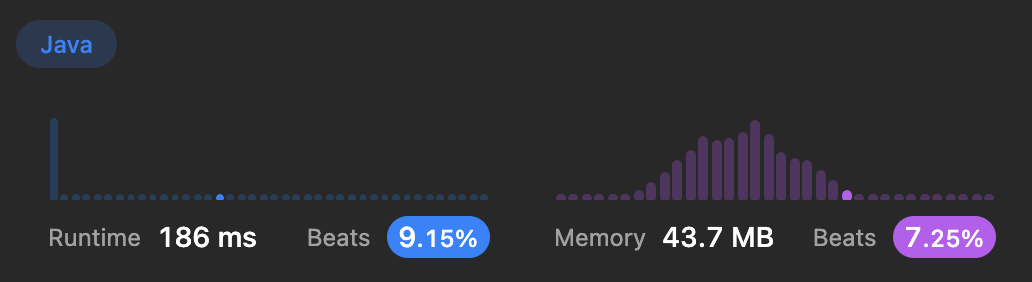
조금 빨라진 것을 볼 수가 있으나 공간 복잡도에서는 늘어났다. 그치만 1MB도 안되긴 하니, 문자열 중복 판단보다는 해시를 쓰는 것이 더 효율적이긴 한가보다!
