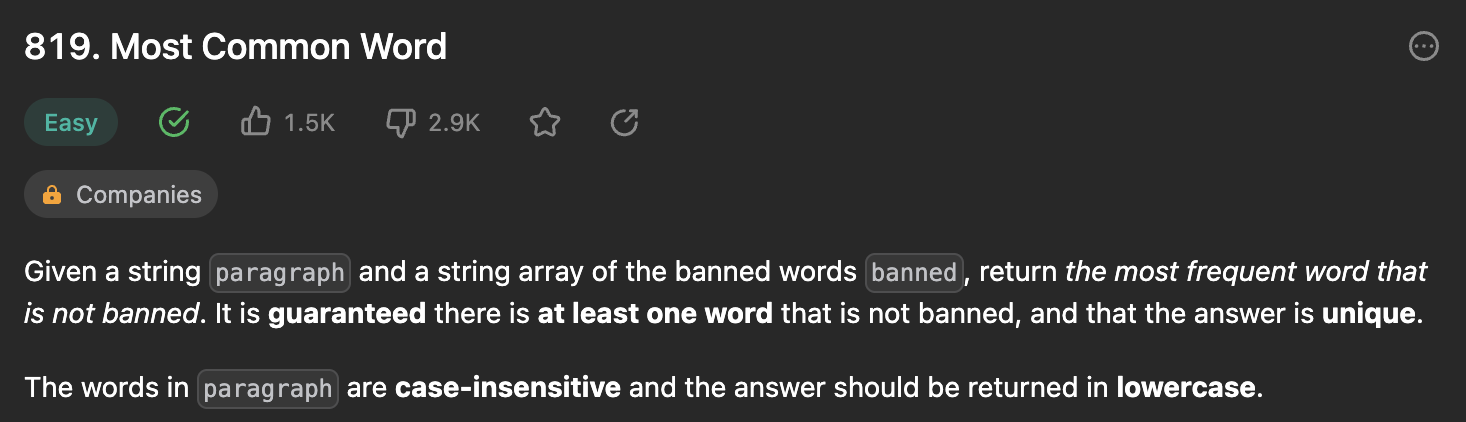
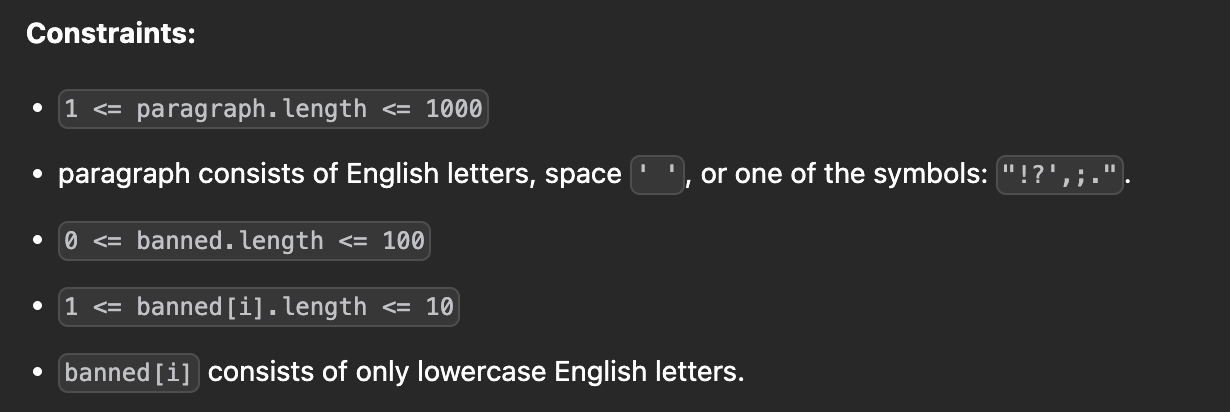
Problem
Solve
- banned[i] 은 소문자 영어로만 이루어져있다고 했으므로 paragraph 도 소문자로 치환해주고, 소문자를 제외한 값도 공백으로 처리한다. ➡️
toLowerCase(),replaceAll([^ a-z], " ") - 단어의 횟수를 세기 전, banned[i] 문자열이 paragraph 에 포함되어 있는 경우 공백으로 치환한다.
- paragraph 문자열을 공백을 기준으로 나뉜 단어 배열을 순회하면서 hashmap 을 이용해
{문자열=횟수}로 key와 value 로 구성한다. - 횟수(hashmap의 value 값들)를 기준으로 내림차순하여 가장 많이 나온 횟수max 를 구한다.
- 다시 hashmap 을 순회하면서 key 값과 대응하는 value가 max 와 같은 경우 결과값을 반환한다.
class Solution {
public String mostCommonWord(String paragraph, String[] banned) {
//banned 는 소문자로만 이루어져있으므로 비교를 쉽게 하기 위해 paragraph 도 소문자로 변경
paragraph = paragraph.toLowerCase();
//banned 는 영어로만 이루어져있으므로 공백, ! ? ; , ; . 제거
String regex = "[^a-z ]";
paragraph = paragraph.replaceAll(regex, " ");
//banned 한 문자열 제거
for(String ban : banned){
paragraph = paragraph.replaceAll(ban, " ");
}
//띄어쓰기를 기준으로 split
String[] words = paragraph.split(" ");
HashMap<String, Integer> hashmap = new HashMap<>();
for(String word : words){
//공백이나 아무의미없는 값은 건너뛰기
if(word.equals(" ") || word.equals("")) continue;
hashmap.put(word, hashmap.getOrDefault(word, 0)+1);
}
List<Integer> count = new ArrayList<>(hashmap.values());
Collections.sort(count, Collections.reverseOrder());
int max = count.get(0);
String result = "";
for(String key : hashmap.keySet()){
if(hashmap.get(key).equals(max)){
result = key;
break;
}
}
return result;
}
}Refactoring
아쉬웠던 점은 replaceAll 을 통해 공백으로 치환을 해주어서 두 번 이상의 공백이 생겨 이것을 문자로 받아들여 hahsmap 에 추가된다는 점이었다. 따라서 이 부분을 해결해주기 위해서 불필요하게 공백을 조건문으로 처리하는 과정이 생겼는데 이 부분이 아직은 매끄럽지 못하다고 생각한다.
과거의 내가 푼 과정은
1. paragraph 를 소문자로 변경 후, 특수문자들을 공백으로 처리하고 두번이상의 공백을 한 번의 공백으로 치환해주는 과정을 거친다.
➡️ replaceAll("[\\s+]", " ")
paragraph = paragraph.toLowerCase();
paragraph = paragraph.replaceAll("[!?',;.]", " ");
paragraph = paragraph.replaceAll("\\s+", " ");- hashmap 의 keySet 을 List 로 만들어주고, Collection.sort 를 이용하여 번거롭지 않게 정렬을 한 스텝으로 할 수 있다.
List<String, Integer> list = new ArrayList<>(hashmap.keySet());
Collections.sort(list, (k1, k2) -> (hashmap.get(k1).compareTo(hashmap.get(k2))));
// k1, k2 는 list 요소인 key 값들이고
// 비교하는 대상은 각각 k1, k2 에 대응하는 value 값들로
// list 를 정렬하면 value의 순서대로 key 값이 정렬된다.- value 값을 기준으로 정렬을 마친 key 요소들이 담긴 list 에서 banned 배열에 담긴 key 값은 삭제하고 가장 첫번째 요소를 반환한다.
for(String ban : banned){
list.remove(ban);
}
return list.get(0);