Spring Batch를 알아보기 위해 실습을 진행해 보았다.
이론에 대한 내용보다는 실습 중심으로 정리해 보려 한다.
Spring Batch
Spring Batch는 엔터프라이즈 시스템의 운영에 있어 대용량 일괄처리의 편의를 위해 설계된 가볍고 포괄적인 배치 프레임워크다. Spring의 특성을 그대로 가져왔기 때문에 DI, AOP, 서비스 추상화 등 Spring 프레임워크의 3대 요소를 모두 사용할 수 있다.
자세한 내용은 링크를 통해 확인해볼 수 있다.
소스코드
- Spring Batch Dependency 추가
build.gradle.kts
implementation("org.springframework.boot:spring-boot-starter-batch:3.0.6")- 메타 데이터 테이블 추가
스프링 배치를 사용하기 위해서는 메타 데이터 테이블들이 필요하다.
메타 데이터는 아래와 같은 내용들을 담고 있다.
- 이전에 실행한 Job이 어떤 것들이 있는지
- 최근 실패한 Batch Parameter가 어떤 것들이 있고, 성공한 Job은 어떤 것들이 있는지
- 다시 실행한다면 어디서부터 시작하면 될지
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공한 Step과 실패한 Step들은 어떤 것들이 있는지
schema-h2.sql
DB별 SQL 스크립트 링크
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP(9) NOT NULL,
START_TIME TIMESTAMP(9) DEFAULT NULL ,
END_TIME TIMESTAMP(9) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP(9),
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
PARAMETER_NAME VARCHAR(100) NOT NULL ,
PARAMETER_TYPE VARCHAR(100) NOT NULL ,
PARAMETER_VALUE VARCHAR(2500) ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP(9) NOT NULL,
START_TIME TIMESTAMP(9) DEFAULT NULL ,
END_TIME TIMESTAMP(9) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP(9),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT LONGVARCHAR ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT LONGVARCHAR ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;- spring batch 설정 추가
application.yml
spring:
batch:
jdbc:
initialize-schema: always # 배치 관련 테이블 있으면 사용하고, 없으면 생성하는 옵션인데, 자동 생성되지 않아 테이블 직접 생성함잡을 구성하는 독립된 작업의 단위에는 Chunk와 Tasklet이 있다. 예제에서는 Chunk를 사용하였다.
Chunk
- 한 번에 하나씩 데이터(row)를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다루는 것
- Chunk 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영이 된다.
- Chunk 기반 Step은 ItemReader, ItemProcessor, ItemWriter라는 3개의 주요 부분으로 구성될 수 있다.
- ItemReader와 ItemProcessor에서 데이터는 1건씩 다뤄지고, Writer에선 Chunk 단위로 처리된다.
Tasklet
- Step이 중지될 때까지 execute 메서드가 계속 반복해서 수행하고 수행할 때마다 독립적인 트랜잭션이 얻어진다. 초기화, 저장 프로시저 실행, 알림 전송과 같은 잡에서 일반적으로 사용된다.
MyBatchConfig.kts
@Configuration
class MyBatchConfig(
private val entityManagerFactory: EntityManagerFactory,
): DefaultBatchConfiguration() {
companion object { const val chuckSize = 3 }
@Bean
fun myJob(jobRepository: JobRepository, step: Step): Job {
return JobBuilder("myJob", jobRepository)
.start(step)
.build()
}
@Bean
fun myStep(jobRepository: JobRepository, transactionManager: PlatformTransactionManager, entityManagerFactory: EntityManagerFactory): Step {
return StepBuilder("myStep", jobRepository)
.chunk<Member, String>(chuckSize, transactionManager)
// chunk 단위만큼 데이터가 쌓이면 writer에 전달하고, writer는 저장
// 마지막 chunk에서는 사이즈 만큼 안채워져도 실행됨
.reader(reader(null))
.processor(processor(null))
.writer(writer(null))
.build()
}
@Bean
@StepScope // Bean의 생성 시점이 스프링 애플리케이션이 실행되는 시점이 아닌 @JobScope, @StepScope가 명시된 메서드가 실행될 때까지 지연
fun reader(@Value("#{jobParameters[requestDate]}") requestDate: String?): JpaPagingItemReader<Member> {
println("==> reader: $requestDate")
return JpaPagingItemReaderBuilder<Member>()
.name("reader")
.entityManagerFactory(entityManagerFactory)
.pageSize(chuckSize)
.queryString("SELECT m FROM Member m")
.build()
}
@Bean
@StepScope
fun processor(@Value("#{jobParameters[requestDate]}") requestDate: String?): ItemProcessor <Member, String> {
println("==> processor: $requestDate")
return ItemProcessor<Member, String> { item: Member ->
item.name
}
}
@Bean
@StepScope
fun writer(@Value("#{jobParameters[requestDate]}") requestDate: String?): ItemWriter<String> {
println("==> writer: $requestDate")
return ItemWriter<String> { items ->
for (item in items) {
println("name: $item")
}
}
}
}주기적으로 잡을 실행시키고자 스케줄러를 설정했다.
MyScheduler.kts
@EnableScheduling
@Component
class MyScheduler {
@Autowired lateinit var jobLauncher: JobLauncher
@Autowired lateinit var job: Job
@Scheduled(fixedDelay = 30000)
fun startJob() {
val jobParameterMap = mapOf("requestDate" to JobParameter(OffsetDateTime.now().toString(), String::class.java))
val jobParameters = JobParameters(jobParameterMap)
val jobExecution: JobExecution = jobLauncher.run(job, jobParameters)
while (jobExecution.isRunning) {
println("isRunning....")
}
}
}스케줄러 실행시 jobParameter를 설정하지 않은 경우 JobInstanceAlreadyCompleteException 발생했다.
org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException: A job instance already exists and is complete for parameters={'requestDate':'{value=1, type=class java.lang.String, identifying=true}'}. If you want to run this job again, change the parameters.
배치를 여러번 실행하고 싶다면 매 실행시 마다 JobParameter 값을 다르게 설정해줘야한다고 한다.
많은 예제에서 requestDate를 JobParameter로 설정하고 있던 이유가 아닐까.
JobParameter는 batch_job_execution_params에서 확인할 수 있다.
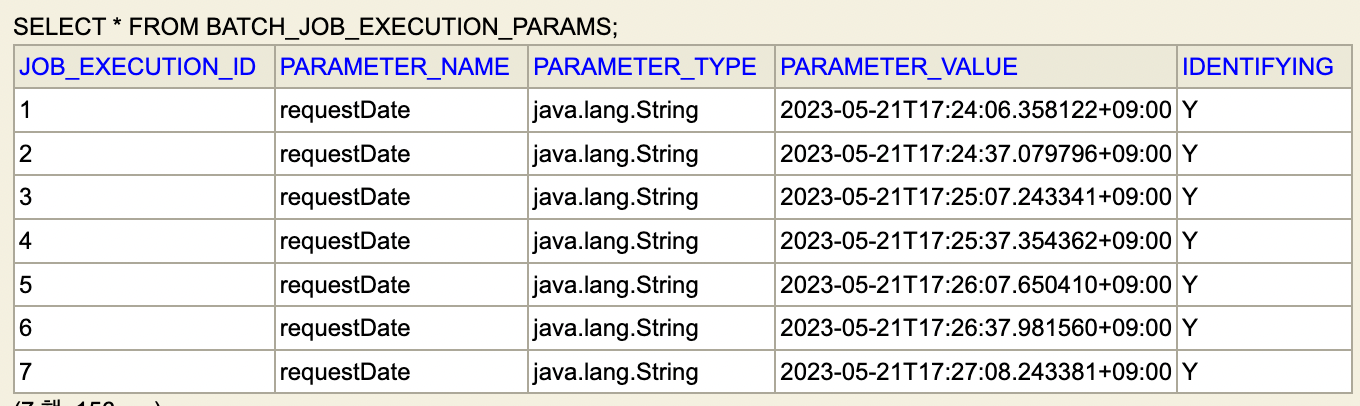
실행 결과
chunkSize를 3으로 설정하고, 멤버 테이블에 6명을 넣어놓고 스케줄러를 통해 잡을 실행시킨 결과
1. reader에서 select 쿼리가 실행되었고
2. processor에서 Member의 name을 wirter로 넘겨주고
3. witer에서 name 값을 출력했다
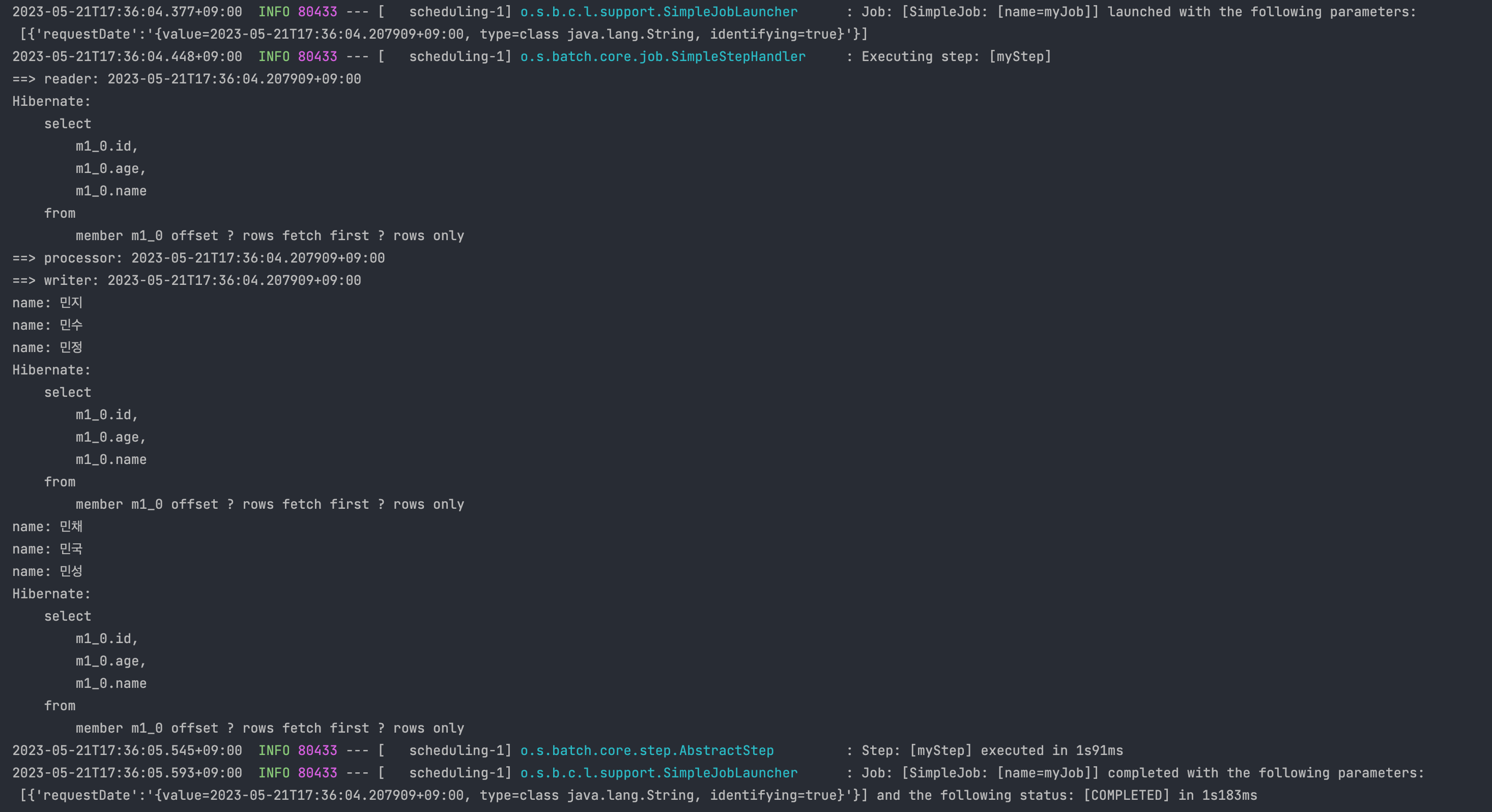
.
.
.
참고
https://wan-blog.tistory.com/53
https://docs.spring.io/spring-batch/docs/current/reference/html/whatsnew.html#whatsNew
