
어느 날 검색엔진이 느려졌다...
찾아보니 엘라스틱서치가 느려지는 이유는 정말 여러 가지가 있었다.
서버 메모리 부족, 엘라스틱서치 설정, 인덱싱 전략, GC, 스토리지..
모니터링 환경
먼저 원인을 분석하는데 가장 중요한것은 모니터링 환경 구축이다.
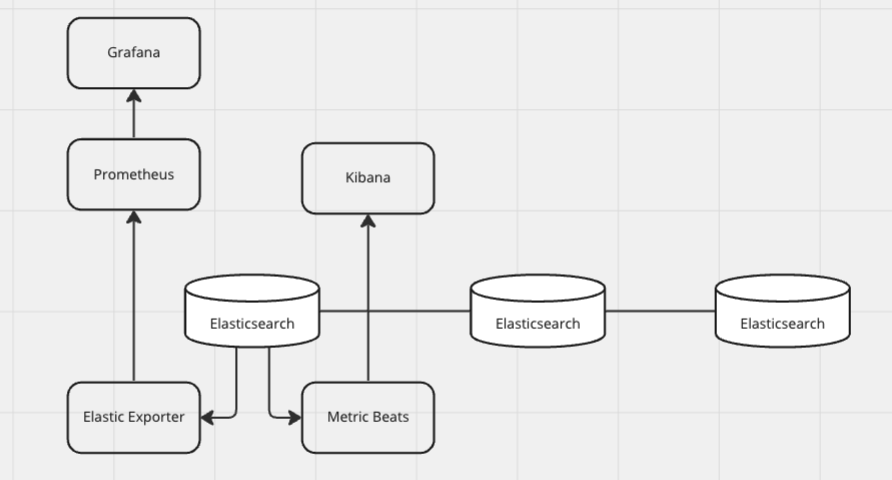
최대한 많은 데이터를 확인하기 위하여 Kibana, Grafana를 사용하였다.
데이터가 지속적으로 증가하는 상황에서 속도 저하 및 장애는 대부분 메모리 부족이다.
가장 빠르게 확인하는 방법은 Grafana에서 JVM Memory usage를 보는 것이다.
아래는 JVM 설정 및 확인 사항이다.
JVM Option
JVM Heap Size는 최소한 시스템 메모리의 절반 이하로 지정해야 한다.
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/advanced-configuration.html
Elasticsearch는 JVM 힙 이외의 목적으로 네트워크 통신, off-heap buffers를 사용하고 파일에 대한 효율적인 액세스를 위해 운영체제의 파일 시스템 캐시를 사용한다.
즉 설정한 한도보다 더 많은 메모리를 사용한다.
또한 루씬이 커널 시스템 캐시를 많이 활용하기 때문에 시스템 메모리의 절반은 운영체제가 캐시로 쓰도록 놔두는 것이 좋다.
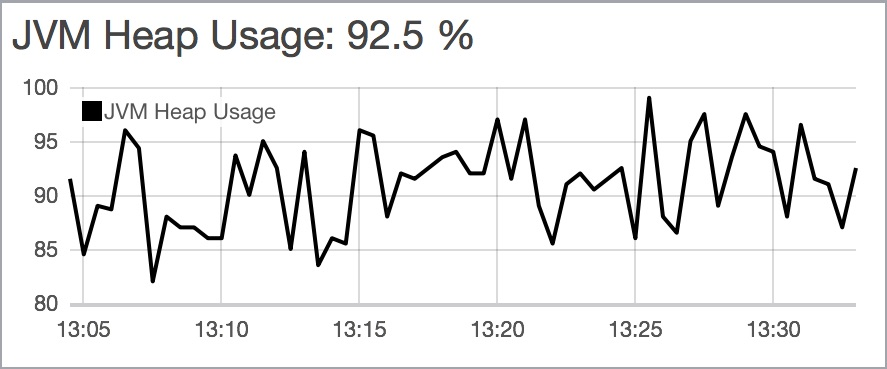
heap that is too small
JVM heap을 너무 작게 설정한 경우이다.
아래 그래프의 패턴이 나타난다면 메모리를 늘려야 한다.
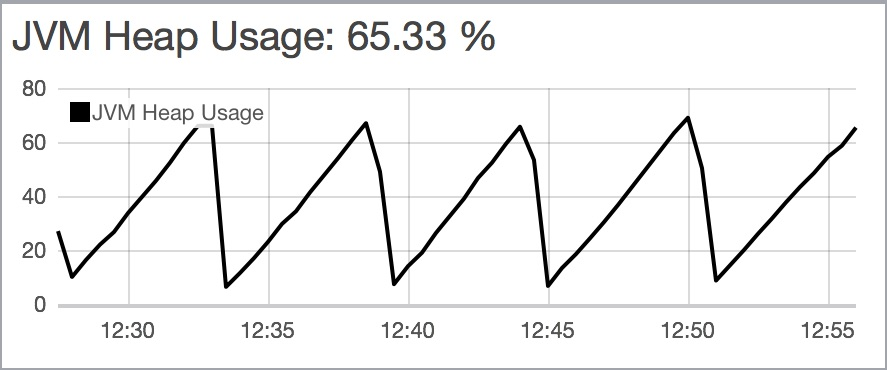
heap that is too large
JVM heap을 너무 크게 설정한 경우이다.
비용적으로나 성능적으로나 너무 크게 설정하는 것도 좋지 않다.
적정한 크기로 조정하자.
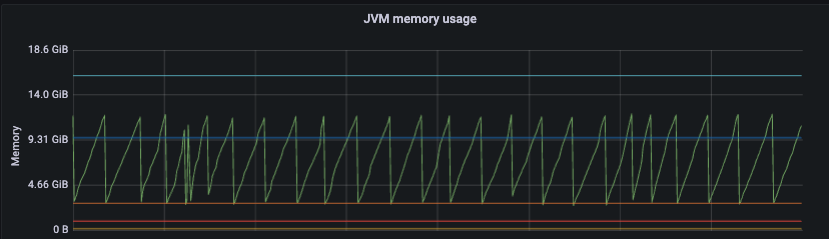
위 패턴은 Grafana 의 JVM memory usage 영역에서 해당부분을 확인 할 수 있다.
JVM Heap Size는 32GB 이상 지정하지 않아야 한다.
JVM이 힙 영역에 생성된 객체에 접근하기 위한 포인터를 Ordinary Object Pointer 라고 한다.
이 OOP는 메모리 주소를 직접 가리킨다.
32GB 이내의 힙 영역에만 접근한다면 Compressed OOPs 라는 기능을 적용해 포인터를 32비트로 유지할 수 있다.
그럼 메모리가 부족하다면 어떻게 해야할까
엘라스틱서치의 버전, 데이터의 속성, 클러스터링 구조, 인덱싱에 따라 대응해야 하는 방법이 모두 다르다.
서버 성능 올리기
클라우드 환경이라면 가장 빠르고 쉬운 방법이다.
JVM 설정이 32G보다 적다면 스케일 업을 32G까지 사용하고 있다면 스케일 아웃을 한다.
스케일 업을 한 경우에는 jvm option을 변경 해준다.
노드 재실행 프로세스는 다른 글에서 작성하겠다.
(모든 노드를 바로 재시작 하면 샤드 재할당 과정에서 장애가 발생할 수 있다.)
버전 올리기
Elasticsearch는 성능 개선을 위하여 자주 업데이트된다.
또한 코어 라이브러리인 아파치 루씬의 업데이트에도 참여하고 있다.
최신 버전과 두 개 이상 차이 난다면 버전을 올리는 것만으로도 성능이 개선된다.
Vector 검색을 사용하는 경우
Elasticsearch is introducing a new type of vector in 8.6! This vector has 8-bit integer dimensions, where each dimension has a range of [-128, 127]. This is 4x smaller than the current vector with 32-bit float dimensions, which can result in substantial space savings.
https://www.elastic.co/kr/blog/save-space-with-byte-sized-vectors
Elasticsearch 8.4 부터는 8-bit 유형의 벡터를 사용할 수 있다.
기존 32-bit float 유형의 벡터를 사용한다면 8.4 이후 버전 사용시 성능 증가와 데이터를 줄일 수 있다.
*차원수가 줄어든 만큼 성능 검증은 필수이다.
기타 설정
스와핑
엘라스틱서치는 스와핑을 사용하지 않도록 강력히 권고한다.
밀리세컨드 단위로 끝나야 할 GC를 분 단위 시간까지 걸리게 만든다.
boostrap.memory_lock 설정
bootstrap.memory_lock : true 이 설정은 프로세스의 주소 공간을 메모리로 제한시키고 스와핑되는 것을 막아 준다.
vm.max_map_cout
루씬은 mmap을 적극적으로 활용하기 때문에 vm.max_map_count 값을 높일 필요가 있다.
$ sysctl vm.max_map_count
vm.max_map_count = 65530이 값이 262144 보다 작다면 늘려주도록 한다.
물론 262144 보다 작다면 elasticsearch 가 실행이 안되니 정상적으로 실행되고 있다면 해당 값보다 높을 것이다.
sudo vi /etc/sysctl.conf
vm.max_map_count=262144
sudo sysctl -p운영체제 레벨의 가이드에서는 보통 이 값을 시스템 메모리의 크기를 128KB로 나눈 크기가 추천된다.
Kibana에서의 과도한 요청
키바나를 통해 과도한 집계나 정렬 등을 요청하면 노드에 full GC가 일어나면ㄴ서 STW 타임이 길어지는 상황에 빠질 수 있다.
많은 사용자가 접근하여 과도한 요청을 하지 않도록 한다.
참고 문서
https://www.elastic.co/kr/blog/a-heap-of-trouble
https://www.elastic.co/kr/blog/prometheus-monitoring-at-scale-with-the-elastic-stack
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/advanced-configuration.html
Thank You for Reading:
부족한 글을 읽어주셔서 감사합니다.
Elastic 관련 글들이 주로 설치와 설정에 중점을 두고 있어서 장애 상황에 대한 분석이 어려웠습니다.
부족한 부분이나 잘못된 내용이 있다면, 피드백 주시면 즉시 반영하도록 하겠습니다.
