오라클에 있는 데이터를 뽑아내서 가공하기 위해 함수가 필요함,
데이터를 빼낼 때 select 자체를 처음부터 알맞은 형태로 가공해서 뽑아오면 추가로 코딩할 필요 없이 바로 사용 가능
1)단일행 함수
하나의 row 당 하나의 결과값을 반환하는 함수
단일행 함수 => 문자함수
<1> CHR(아스키 코드)
SQL>SELECT CHR(65) FROM DUAL ; <2>CONCAT(칼럼명, '붙일문자') =>문자열 연결함수
concat : 서로 합친다 (|| 대신 쓸 수 있음)
SQL>SELECT CONCAT(ename, ' 님' ) name FROM emp ;<3>INITCAP( '문자열' ) => 시작문자를 대문자로 바꿔준다.
SQL>SELECT INITCAP( 'hello world') FROM DUAL;<4>LOWER( '문자열' ) =>문자열을 소문자로 바꿔준다.
SQL>SELECT LOWER( 'HELLO!' ) FROM DUAL;<5>UPPER( '문자열' ) =>문자열을 대문자로 바꿔준다.
SQL>SELECT UPPER( 'hello!' ) FROM DUAL;<6>LPAD( '문자열' , 전체 자리수 , '남는자리를 채울 문자') =>왼쪽에 채운다.
lpad : left padding
SQL>SELECT LPAD( 'HI', 10 , '*' ) FROM DUAL;<7>RPAD( '문자열' , 전체 자리수 , '남는자리를 채울 문자') =>오른쪽에 채운다.
rpad : right padding
SQL>SELECT RPAD( 'HELLO', 15 , '^' ) FROM DUAL; <8>LTRIM( '문자열' , '제거할문자' )
왼쪽에서부터 잘라내기
SQL>SELECT LTRIM( 'ABCD' , 'A' ) FROM DUAL;
SQL>SELECT LTRIM( ' ABCD', ' ' ) FROM DUAL;
SQL>SELECT LTRIM( ' AAAABBACC', 'A' ) FROM DUAL;
SQL>SELECT LTRIM( 'ACACBCD' , 'AC' ) FROM DUAL; <9>RTRIM( '문자열' , '제거할문자')
오른쪽에서부터 잘라내기
SQL>SELECT RTRIM( 'ACACBCD', 'CD') FROM DUAL; <10>REPLACE( '문자열1' , '문자열2' , '문자열3')
=> 문자열 1에 있는 문자열중 문자열2를 찾아서 문자열3 으로 바꿔준다.
SQL>SELECT REPLACE( 'Hello mimi' , 'mimi', 'mama' ) FROM DUAL; <11>SUBSTR( '문자열' , N1, N2 )
=>문자열의 N1 번째 위치에서 N2 개만큼 문자열 빼오기
SQL>SELECT SUBSTR( 'ABCDEFGHIJ' , 3 , 5) FROM DUAL;<12> ASCII('문자') =>문자에 해당하는 ASCII 코드값을 반환한다.
SQL>SELECT ASCII( 'A' ) FROM DUAL;<13> LENGTH( '문자열' ) =>문자열의 길이를 반환한다.
SQL>SELECT LENGTH( 'ABCDE' ) FROM DUAL;<14>LEAST( '문자열1', '문자열2' , '문자열3' )
=>문자열 중에서 가장 앞의 값을 리턴한다. (가장 작은 거)
SQL>SELECT LEAST( 'AB','ABC','D') FROM DUAL; <15>NVL(칼럼명 , 값 ) => 해당 칼럼이 NULL 인경우 정해진 값을 반환한다.
NVL(null value) : null값을 다룰 때 자주 쓰임, null의 기본값을 줄 때
SQL>SELECT ename,NVL(comm, 0) FROM emp ;
-> comm값이 null이면 기본값을 0으로 주겠다(기본값 문자도 가능)
단일행 함수 => 숫자함수
<1>ABS(숫자) => 숫자의 절대값을 반환한다.
SQL>SELECT ABS(-10) FROM DUAL;<2>CEIL(소수점이 있는 수) => 파라미터 값보다 같거나 가장 큰 정수를 반환(올림)
SQL>SELECT CEIL(3.1234) FROM DUAL;
SQL>SELECT CEIL(5.9999) FROM DUAL;<3>FLOOR(소수점이 있는 수) =>파라미터 값보다 같거나 가장 작은 정수반환(내림)
SQL>SELECT FLOOR(3.2241) FROM DUAL;
SQL>SELECT FLOOR(2.888829) FROM DUAL;<4>ROUND(숫자,자리수) =>숫자를 자리수+1 번째 위치에서 반올림한다.
SQL>SELECT ROUND(3.22645, 2) FROM DUAL;
SQL>SELECT ROUND(5.2345, 3) FROM DUAL;<5>MOD(숫자1 , 숫자2) =>숫자1을 숫자2로 나눈 나머지를 리턴한다.
SQL>SELECT MOD(10,3) FROM DUAL;<6>TRUNC(숫자1, 자리수)
=> 숫자1의 값을 소수점이하 자리수까지만 나타낸다. 나머지는 잘라낸다.
SQL>SELECT TRUNC(12.23532576 , 2) FROM DUAL;
SQL>SELECT TRUNC(34.1234) FROM DUAL;단일행 함수 => 날짜함수
-
날짜 함수 : 날짜 타입 ! 문자타입 아님
오라클에서 인자로 전달할 게 없는 함수는 그냥 함수 이름만 적는다 ()안붙임 ! -
문자변환함수 (to char 문자열로 !)
TO_CHAR( date type, ‘날짜 포맷’ )
year => Y
month => M
date => D
hour => H
minute => MI
sec => S
수요일 => DAY
수 => DY
<1> SYSDATE = > 현재 시간을 리턴한다.
SQL>SELECT SYSDATE FROM DUAL;<2>ADD_MONTHS( 날짜, 더해질월)
SQL>SELECT ADD_MONTHS(SYSDATE, 10) FROM DUAL;<3>LAST_DAY(날짜) => 해당날짜에 해당하는 달의 마지막 날짜을 반환한다.
SQL>SELECT LAST_DAY(SYSDATE) FROM DUAL;<4>MONTHS_BETWEEN(날짜1, 날짜2) => 두 날짜 사이의 월의 수
SQL>SELECT empno,MONTHS_BETWEEN(SYSDATE, HIREDATE) 근무개월
FROM emp ;.
select to_char(sysdate, 'YYYY.MM.DD (dy) HH24:MI') from dual;
2022.04.13 (수) 14:36
sql>INSERT INTO message
VALUES(2, ‘hello’, ‘2016/10/20’);
// 임의로 날짜 문자열로 넣어주면 날짜타입으로 보여줌sql>INSERT INTO message
VALUES(2, ‘gura!’, TO_DATE(‘20161020123020’,’YYYYMMDDHHMISS’));
sql>INSERT INTO message
VALUES(2, ‘gura!’, TO_DATE(‘20161020 오전 12:30’,’YYYYMMDD AM HH:MI’));날짜넣고 어떤타입인지 적어줘도 됨
SQL>SELECT TO_CHAR(SYSDATE , 'YYYY-MM-DD') FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'YYYY:MM:DD') FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'YYYY.MM.DD') FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'YY.MM.DD') FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'YY" 년 "MM" 월 "DD" 일 "') FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'HH:MI:SS' ) FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'AM HH:MI:SS' ) FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'PM HH:MI:SS' ) FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'HH24:MI:SS' ) FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'HH24" 시 "MI" 분 "SS" 초 "' ) FROM DUAL;
SQL>SELECT TO_CHAR(SYSDATE , 'YY" 년 "MM" 월 "DD" 일 " HH24" 시 "MI" 분
"SS" 초 "') D FROM DUAL;단일행 함수 => 숫자변환함수, 날짜변환함수
- TO_NUMBER('숫자에 대응되는 문자');
SQL>SELECT TO_NUMBER('999') +1 FROM DUAL;- TO_DATE('날짜에 대응되는 문자')
SQL>SELECT TO_DATE('2012-12-12') FROM DUAL;- TO_DATE( 문자열, 형식)
CREATE TABLE message(
num NUMBER PRIMARY KEY,
msg VARCHAR2(20),
regdate DATE );- 데이터 저장하기
sql>INSERT INTO message (num,msg,regdate)
VALUES(1, ‘hi’, SYSDATE);
sql>INSERT INTO message
VALUES(2, ‘hello’, ‘2016/10/20’);
sql>INSERT INTO message
VALUES(2, ‘gura!’, TO_DATE(‘20161020123020’,’YYYYMMDDHHMISS’));
sql>INSERT INTO message
VALUES(2, ‘gura!’, TO_DATE(‘20161020 오전 12:30’,’YYYYMMDD AM HH:MI’));2) 복수행 (그룹) 함수 : 여러 row의 값을 반영하는 함수
1) COUNT(칼럼명) =>해당 칼럼이 존재하는 ROW 의 갯수를 반환한다.
단, 저장된 데이터가 NULL 인 칼럼은 세지 않는다.
SQL>SELECT COUNT(ename) FROM emp;
SQL>SELECT COUNT(comm) FROM emp;
SQL>SELECT COUNT(*) FROM emp ; => 모든 행(row)의 갯수를 얻어온다.2)SUM(칼럼명) => 해당 칼럼의 값을 모두 더한 값을 리턴한다.
SQL>SELECT SUM(sal) FROM emp;3)AVG(칼럼명) => 해당 칼럼의 값을 모든값을 더한후 ROW 의 갯수로 나눈 평균값을 리턴한다. 단 NULL 칼럼은 제외된다.
SQL>SELECT AVG(sal) FROM emp;
SQL>SELECT AVG(comm) FROM emp; ex) comm 이 NULL 인 사원도 평균에 포함 시켜서 출력을 하려면?
hint : NVL() 함수를 이용한다.
SQL>SELECT AVG( NVL( comm , 0 ) ) FROM emp;4) MAX(칼럼명) => 최대값을 리턴한다.
SQL>SELECT MAX(sal) FROM emp;5) MIN(칼럼명) =>최소값을 리턴한다.
SQL>SELECT MIN(sal) FROM emp;GROUP BY : 그룹 함수
- 여러개의 행당(하나의 그룹당) 하나의 값을 반환하는 함수
- 그룹을 따로 묶지 않으면 FROM절에 있는 대상을 하나의 그룹으로 인식한다.
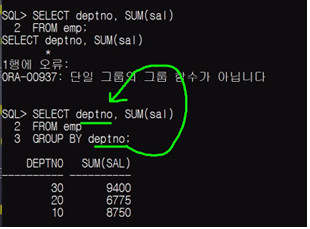
그룹으로 묶어줘야 사용 가능
그룹으로 묶었는데 그룹의 구성원이 하나인 경우도 있음(EX: PRESIDENT)
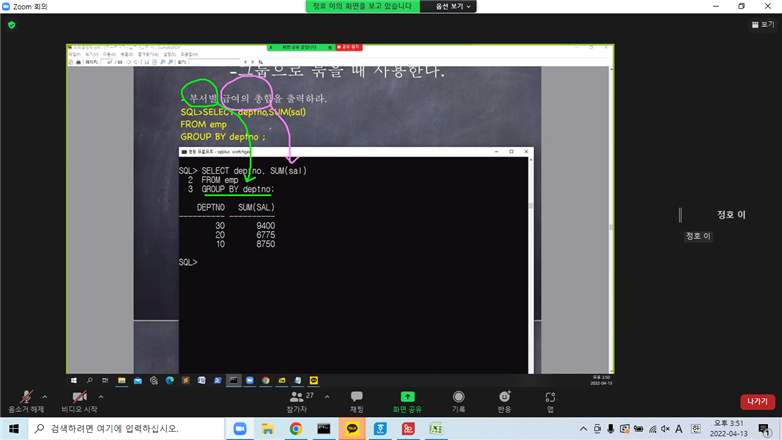
* 실행순서
SQL> SELECT DEPTNO, JOB, COUNT(*) FROM EMP
2 GROUP BY DEPTNO, JOB
// 각 부서별 같은 업무 ! 니까 GROUP BY 두 번 하기
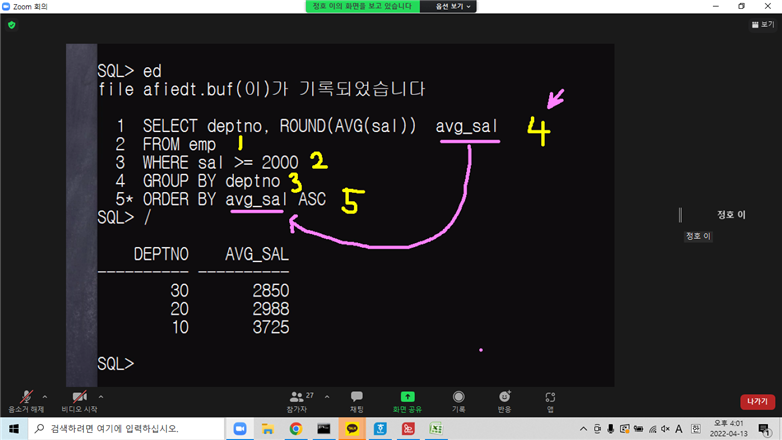
3 ORDER BY deptno ASC;별칭이 붙은 뒤에 정렬하는 거니까 ORDER BY 뒤에 별칭붙이는게 인식됨
SELECT DEPTNO, JOB, COUNT(*) : 로우의 수 세줌
