CleanCode
깨끗한 코드
의미있는 이름
이름 짓기는 개발자들이 생각보다 고민을 많이 하는 부분 중 한가지. 간단하지만 개발업무의 중요한 부분들에 강력한 효과가 있기 때문. 코드의 가독성, 유지보수성, 협업 효율성을 모두 고려하여 명명 규칙을 신중하게 적용해야 하며 좋은 이름은 코드의 품질을 높이고, 개발자 간 소통을 원활하게 한다.
-
의도를 분명히 밝혀라
코드의 이름은 그 역할과 목적을 명확히 드러내야 함. 변수명이나 함수명만 보고도 무엇을 하는 코드인지 쉽게 이해할 수 있어야 한다.
예: calculateTotalPrice()는 총 가격을 계산한다는 의도가 명확. 반면, calc() 같은 이름은 코드의 목적을 모호하게 함 -
그릇된 정보를 피하라
이름이 잘못된 의미를 전달/혼동 오해를 불러일으킬 수 있음.
account_list라는 변수명이 배열이나 집합을 나타내는 경우 혼란을 초래할 수 있음. 프로그래머에게 List는 특수한 의미이며 account_group이나 bunch_of_account, accounts 등을 사용해야한다 List형으로 사용하더라도 나중에 타입이 변경될수있음.
유사한 개념은 유사한 표기법을 사용하며 이것도 정보이다. 일관성이 떨어지는 표기법은 그릇된 정보임. -
의미있게 구분하라
이름이 구체적이어야 같은 프로젝트 내에서 혼동되지 않음.
코드 안에서 같은 의미를 가지는 이름이 비슷비슷하면 혼란을 야기. 이름이 비슷해 보이지만 서로 다른 역할을 한다면, 구체적으로 구분할 수 있도록 해야한다.
잘못된 예: getData()와 getInfo() (차이가 불분명)
올바른 예: getUserData()와 getOrderInfo() (명확한 구분)
- 클래스와 메서드 이름
일반적으로 클래스 이름은 명사를 사용하여 개체를 표현하고, 메소드 이름은 동사를 사용하여 행동을 나타냄.
CapWords와 lowerCamelCase 사용
클래스 이름: UserManager, OrderService (명사형, CapWords)
메소드 이름: getUser(), calculateTotal() (동사형, lowerCamelCase)
이러한 명명 규칙은 코드의 역할을 명확히 하고 일관성을 유지하여 코드베이스 전반에서 가독성을 높이고. 특히 메소드 이름은 행동을 표현하기 때문에 동사로 시작하는 것이 바람직하다. 클래스 이름은 역할을 강조하기 위해 명사로 명명
- 한 개념에 한 단어를 사용하라
같은 개념을 여러 가지로 표현하면 혼란이 생김. 일관성 있는 용어 사용이 중요.
잘못된 예: fetch, get, retrieve 혼용
올바른 예: get으로 통일
-
해법 영역과 문제 영역의 이름 사용
기술적인 부분은 해법 영역의 용어로, 도메인 로직은 문제 영역의 용어로 표현하여 혼동을 줄인다.
(기술적인 코드에는 기술 용어를, 비즈니스 로직에는 도메인 용어를 사용한다는 의미)
예: calculateChecksum() (해법 영역), computeOrderTotal() (문제 영역). -
의미 있는 맥락을 추가하라
이름만으로 충분히 의미를 전달할 수 없는 경우, 맥락 정보를 추가하여 더 명확히 표현하면 좋음.
예: address 대신 shippingAddress와 billingAddress로 구분. -
불필요한 맥락을 없애라
불필요한 접두어나 맥락을 제거하여 간결하고 명확한 이름을 유지. 클래스 이름이 Product라면 변수명으로 productPrice 대신 price를 사용하는 것이 바람직.
코드 가독성, 협업 효율성 고려. 코드 자체가 스스로 설명할 수 있도록 명명 규칙을 신중하게 고려해야 한다. -
검색하기 쉬운 이름을 사용하라
검색이 어려운 이름은 유지보수를 방해. 한 글자 변수명이나 공통적인 이름을 피하고, 코드에서 쉽게 찾을 수 있도록 구체적이고 일관된 이름을 사용. -
인코딩을 피하라
의미를 전달하지 않는 접두사나 약어 사용은 가독성을 해침. m, a 같은 인코딩 방식을 피하고, 직관적으로 의미를 전달하는 이름을 사용.
예: m_age 대신 age 사용.
- 발음이 어려운 네이밍 지양, 상식적이지 않은 이름 지양,
함수
- 작게 만들어라
- 한 가지만 해라
- 함수당 추상화 수준은 하나로
- Switch문
- 서술적인 이름을 사용하라
- 함수 인수
- 부수 효과를 일으키지 마라
- 명령과 조회를 분리하라
- 오류 코드보다 예외를 사용하라
- 반복하지 마라
- 구조적 프로그래밍
- 함수를 어떻게 짤지
Clean Code에서 함수는 코드의 핵심 구성 요소이다. 프로그램의 기본.
코드의 가독성, 유지보수성, 재사용성을 크게 좌우한다.
- 작게 만들어라
함수는 최대한 작게. 가능한 한. 작고 명확한 함수는 이해하기 쉽고, 테스트하기도 용이합니다. 특히, 하나의 함수 안에 많은 로직이 들어가면 함수의 목적이 불분명해지고 복잡성이 증가한다.
- 한 줄로 작성할 수 있는 블록을 사용하라.
- 들여쓰기 수준은 어지간하면 1~2단계로 제한하라.
ex) 잘못된 예
개선된 예public void calculate() { if (isValid()) { int result = data * 2; if (result > 100) { save(result); } } }public void calculate() { if (isEligible()) { saveResult(compute()); } }
- 한 가지만 해라
함수는 하나의 작업만 수행해야 한다. 여러 가지를 동시에 처리하려고 하면 함수가 길어지고 복잡해져 이해하기 어려워짐.
- 하나의 책임을 가지도록 작성해야한다.
- 함수명으로 그 작업이 명확히 드러나게 하라.
ex) 잘못된 예:
개선된 예:public void updateUserAndSendEmail(User user) { user.update(); email.send(user); }public void updateUser(User user) { user.update(); } public void sendEmail(User user) { email.send(user); }
- 함수 당 추상화 수준은 하나로
함수 내 모든 문장은 동일한 추상화 수준을 가지는 것이 좋다. 추상화 수준이 혼재되면 코드의 의도가 불명확해짐.
- 고수준과 저수준 논리가 뒤섞이지 않도록 해야함
- 함수 내부에서 단계별로 추상화 수준이 일관되게 내려가게 하라.
ex) 잘못된 예:
개선된 예:public void renderUser() { connectToDB(); // 저수준: 데이터베이스 연결 User user = fetchUser(); // 중간 수준: 사용자 데이터 가져오기 user.display(); // 고수준: 사용자 정보 표시 }public void renderUser() { User user = retrieveUser(); // 고수준: 사용자 정보 가져오기 display(user); // 고수준: 사용자 정보 표시 //**저수준 세부사항(데이터베이스 연결 등)**은 retrieveUser() 내부로 감추어져 있다. //함수 자체가 **"사용자를 가져와서 표시한다"**는 고수준 동작을 명확하게 보여줌. }
- Switch문
Switch문은 본질적으로 여러 가지 작업을 처리하기 때문에 작게 만들기 어렵고. 다형성을 이용하여 Switch문을 저수준 클래스에 숨기는 것이 좋다.
- Switch문을 한 곳에 모아서 관리.
- 다형성을 사용하여 중복을 최소화.
ex)
잘못된 예:
개선된 예:switch (employee.type) { case MANAGER: payManager(); break; case ENGINEER: payEngineer(); break; }employee.pay();
-
서술적인 이름을 사용하라
함수의 이름은 그 역할과 목적을 명확하게 표현해야함. 길어도 괜찮다. -
함수 인수
함수 인수는 적을수록 좋습니다. 이상적인 인수 개수는 0개이며, 많아도 2개를 넘지 않는 것이 좋습니다.
- 인수가 많다면 객체로 묶어 전달.
- 불필요한 플래그 인수를 피할 것.
ex) 잘못된 예:
개선된 예:public void createUser(String name, int age, String address) {}public void createUser(UserInfo info) {}
- 부수 효과를 일으키지 마라
함수는 한 가지 작업만 수행해야 하며, 숨겨진 부수 효과를 피해야 함. 부수 효과는 예기치 못한 버그를 유발할 수 있다.유닛테스틑 할때도 독립성 보장하기가 어려움. 문제 발생 위치 추적도 어려워진다.
ex)
잘못된 예:
개선된 예:public int calculateTotal() { discount = 0.1; // 부수 효과: 외부 상태를 수정 return price * quantity; }public int calculateTotal(double discount) { return price * quantity * (1 - discount); } - 명령과 조회를 분리하라
함수는 동작을 수행하거나 데이터를 조회하는 둘 중 하나의 역할만 해야한다.
잘못된 예:
개선된 예:if (setAndCheckStatus()) { process(); }setStatus(); if (isStatusValid()) { process(); } - 오류 코드보다 예외를 사용하라
오류 코드 방식은 함수가 정상적으로 처리되지 않았을 때, 특정 숫자나 상태 값을 반환하여 오류를 알린다.
오류를 코드로 반환하는 것보다는 예외를 사용하여 명시적으로 처리하는 것이 좋다. 오류 코드는 흐름 제어를 복잡하게 만들며, 코드가 길어지고 가독성이 떨어짐.
ex)
잘못된 예:
개선된 예:if (deleteFile() == -1) { System.out.println("Error"); }try { deleteFile(); } catch (IOException e) { handleError(e); }
chat gpt 문의 - 오류코드를 쓰는 상황은 없는지?
Exception )
가독성 향상: 오류 코드보다 명시적이고 직관적입니다.
코드 관리 용이: 오류 처리와 비즈니스 로직이 명확히 분리됩니다.
일관된 처리: 여러 오류를 한 곳에서 집중적으로 관리할 수 있습니다.
디버깅 용이: 콜 스택 정보를 보존하여 문제 해결이 쉽습니다.
오류코드 )
1. 성능이 중요한 경우
예외는 예외가 발생할 때만 성능에 영향을 미치지만,
예외를 자주 던지고 catch하는 경우, 성능 저하가 발생할 수 있습니다.
예외 처리 과정은 스택 트레이스 추적 등 부가 작업이 많기 때문에,
성능이 중요한 코드 경로에서는 오류 코드를 사용하는 것이 더 효율적입니다.
2.정상흐름의 일부
3.임베디드 시스템 등 제한된 환경
4.단순 유효성 검사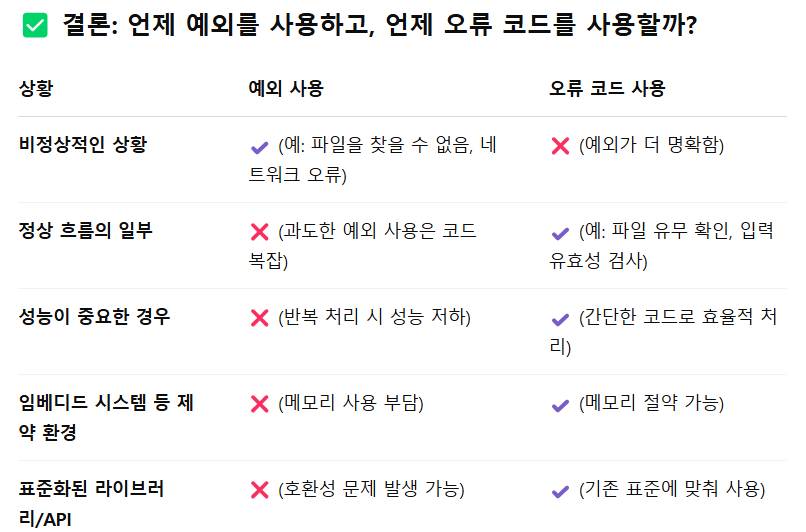
-
반복하지 마라
중복코드 하지 말 것 -
구조적 프로그래밍
구조적 프로그래밍은 코드의 흐름을 명확하고 일관되게 작성하는 것을 목표로 함.
잘못된 예 : 복잡한 흐름public int calculate(int value) { if (value < 0) return -1; int result = value * 2; if (result > 100) return 100; if (result < 10) return 0; return result; }개선된 예 : 구조적 프로그래밍 적용
public int calculate(int value) { int result; if (value < 0) { result = -1; } else { result = value * 2; if (result > 100) { result = 100; } else if (result < 10) { result = 0; } } return result; }
chat gpt : 구조적 프로그래밍이 항상 좋은가?
구조적 프로그래밍을 무조건 강제하면 오히려 코드가 불필요하게 길어질 수 있습니다.
💡 예외 상황
함수가 아주 짧고 간단할 때는 중간에 return을 사용하는 것이 더 직관적일 수 있습니다.
예를 들어, 입력값이 잘못된 경우를 초반에 필터링하는 방식은 return을 여러 개 써도 자연스럽습니다.
예시: 간단한 검증 함수주석
- 주석은 나쁜 코드를 보완하지 못한다
주석을 추가하는 일반적인 이유는 코드의 품질이 나쁘기 때문인데, (코드를 보고 이해하기가 어렵기 때문) 코드가 지저분하면 주석을 달기보다 코드를 정리하는 데 시간을 투자해야 하며, 표현력이 풍부하고 깔끔하며 주석이 거의 없는 코드가 복잡하고 주석이 많이 달린 코드보다 훨씬 좋다. - 코드로 의도를 표현하라
많은 경우 주석으로 달려는 설명을 코드로 직접 표현할 수 있다. 예를 들어
// 직원에게 복지 혜택을 받을 자격이 있는지 검사한다.
if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))위의 코드는 아래와 같이 개선될 수 있다
if (employee.isEligibleForFullBenefits())이렇게 하면 코드 자체로 의도가 명확해져 주석이 필요 없게 된다.
-
좋은 주석
-
법적인 주석: 각 소스 파일 첫머리에 들어가는 저작권 정보와 소유권 정보 등은 필요하고 타당
-
정보를 제공하는 주석: 정규표현식과 같이 복잡한 코드의 의도를 설명하는 주석은 이해를 돕는다.
// kk:mm:ss EEE, MMM dd, yyyy 형식이다. Pattern timeMatcher = Pattern.compile("\\d*:\\d*:\\d* \\w*, \\w* \\d*, \\d*"); -
의도를 설명하는 주석: 특정 구현 결정의 이유나 목적을 설명하는 주석은 유용할 수 있다
// 스레드를 대량 생성하는 방법으로 어떻게든 경쟁 조건을 만들려 시도한다. for (int i = 0; i < 2500; i++) { // ... } -
TODO 주석: 앞으로 해야 할 작업이나 개선 사항을 표시하는 데 사용.
-
-
나쁜 주석
- 중복된 주석: 코드 자체로 명확한 내용을 반복해서 설명하는 주석은 불필요
- 오해의 소지가 있는 주석: 부정확하거나 오래되어 실제 코드와 일치하지 않는 주석
- 의무적으로 다는 주석: 모든 함수나 변수에 주석을 다는 것은 오히려 가독성을 해칠 수 있다
- 이력을 기록하는 주석: 버전 관리 시스템이 이러한 역할을 하므로, 소스 코드에 변경 이력을 주석으로 남기는 것은 불필요
형식 맞추기
- 팀은 한 가지 규칙에 합의하고 모든 팀원은 그 규칙을 따라 일관적인 스타일을 유지해야한다. -> 코드 가독성 향상과 협업 효율성 증대
- code formatter, lint등 사용
- 적절한 행 길이를 유지하라
- 한 줄에 200자에서 500자 사이를 권장
- High Level -> Low Level 순서로 작성
- 첫 부분은 고차원 개념, 알고리즘 설명.
- 아래로 내려가며 의도를 세세하게 묘사, 마지막은 가장 저차원 함수와 세부 내역
- 개념은 빈 행으로 분리하라.
- 각 행은 수식이나 절을 나타내고, 일련의 행 묶음은 완결된 생각 하나를 표현
- 세로 밀집도는 연관성을 표현.
- 밀접한 코드 행은 세로로 가까이 배치
- 비슷한 기능 함수는 인접 배치
- 변수는 사용 위치에 가깝게 선언
- 가로 형식 맞추기
- 80~120정도 권장
- 가로 공백 사용해 밀접한 개념과 느슨한 개념을 표현
- 들여쓰기를 통하여 코드가 속하는 범위를 시각적으로 쉽게 파악 가능
- 팀 규칙
- 밥 아저씨의 형식 규칙
객체와 자료구조
객체와 자료구조의 차이점을 명확히 이해하고, 그에 따라 적절히 사용하는 것이 코드의 가독성과 유지보수성을 높이는 데 중요.
-
자료 추상화
자료 구조를 잘 설계하려면 자료를 추상화하여 내부 구현을 감춰야 함. 자료 추상화는 구조의 세부 사항을 감추고, 인터페이스를 통해 데이터에 접근하는 방법만 제공. -
자료/객체 비대칭
자료와 객체는 다른 목적을 갖고 설계되어야 한다.-
객체: 데이터를 숨기고, 데이터를 다루는 함수를 외부에 노출.
-
자료 구조: 데이터를 노출하고, 함수는 별도로 구현.
-
객체 지향적 설계
public class Rectangle { private double length; private double width; public double area() { return length * width; } }특징: 객체는 데이터를 감추고, 기능을 제공하여 데이터 중심이 아닌 기능 중심으로 설계.
-
자료 구조적 설계
public class RectangleData { public double length; public double width; }
-
public double area(RectangleData rect) {
return rect.length * rect.width;
}
특징: 구조체처럼 데이터를 직접 노출하여 기능과 데이터를 분리.
* 디미터 법칙 : 객체는 자신의 메서드와 필드, 자신이 생성하거나 소유한 객체의 메서드만 호출해야 한다는 규칙
* 기차 충돌
```csharp
person.getAddress().getStreet().getName();
->
//개선
person.getStreetName();문제점: 메서드 체이닝으로 인해 객체 간 결합도가 높아짐
- 잡종 구조
객체와 자료 구조를 혼합하여 설계하는 문제 ex)객체처럼 보이지만, 내부에 자료 구조를 그대로 노출 - 구조체 감추기
자료 구조를 감추고, 인터페이스를 통해 접근하도록 설계하여 디미터 법칙을 준수 - 자료 전달 객체 (DTO: Data Transfer Object)
데이터 전달에 특화된 객체로, 게터와 세터만 존재하며 비즈니스 로직이 없음.- 활성 레코드
데이터베이스 테이블과 직접 매핑되는 구조로, 데이터 필드와 데이터 조작 메서드가 함께 존재.ORM(Object-Relational Mapping)에서 일반적으로 사용.간결한 CRUD 처리 가능하나 비즈니스 로직 혼재 문제와 SRP(단일 책임 원칙) 위반 가능성이 있다. 복잡한 비지니스 로직이 있거나 대규모 시스템, 테스트가 중요한 애플리케이션에는 적합하지 않고, 간단 CRUD 중심이나 데이터 조작이 주목적인 경우에 사용.
- 활성 레코드
경계
클린 코드에서 경계(boundary)는 내부 코드와 외부 라이브러리 또는 모듈을 연결하는 지점을 의미. 다. 경계를 잘 관리하면 외부 코드의 변경으로부터 내부 코드를 보호할 수 있어 유지보수성이 높아진다.
-
외부 코드 사용하기
외부 라이브러리나 모듈을 사용하면 개발 속도가 빨라지고 코드 재사용성이 증가하지만 외부 코드는 언제든지 변경(버전 업데이트, Deprecated)될 수 있으므로, 이를 잘 격리하고 관리하는 것이 중요-
직접 연결하지 않고, 중간 어댑터를 사용하여 의존성을 줄여 사용한다.
-
인터페이스를 통해 간접 접근하여 외부 변화에 유연하게 대응
public interface LogService { void logInfo(String message); } public class Log4jAdapter implements LogService { private static final Logger logger = Logger.getLogger(MyClass.class); public void logInfo(String message) { logger.info(message); } } LogService logService = new Log4jAdapter(); logService.logInfo("Message");logger의 info 함수가 변경되었을 때, (default tag를 param0에 추가된다던지..)-> logInfo가 사용된 곳 전체가 아니라 logService의 logInfo함수만 고쳐주면 된다.
-
-
경계 살피고 익히기
테스트를 통해 경계 파악 필요.
권장사항- 기능 실험/ API 문서 참고해 기본 동작을 이해해야한다.
- 학습 테스트 : 새로운 라이브러리/외부 코드 도입 시 간단한 테스트 코드를 작성하여 기능 검증. 버전 업 시에도 동작 확인용으로 사용이 가능하다.
-
아직 존재하지 않는 코드를 사용하기
프로젝트 초기에는 외부 라이브러리가 개발되지 않았거나 도입이 확정되지 않은 경우도 있는데, 인터페이스를 먼저 정의하고 구체적인 구현체는 나중에 추가하는 방식으로 진행 -
깨끗한 경계
외부 코드와 내부 코드의 경계를 명확히 정의하여 외부 변화로부터 내부 코드를 보호하는 것이 중요. (내부 코드와의 결합도를 최소화)
원칙- 중간계층(어댑터)를 사용해 외부와 내부 분리
- 외부 라이브러리에 직접 의존하지 않도록 인터페이스 활용.
클래스
-
클래스 체계
- 캡슐화 : 내부 구현을 감추고, 필요한 부분만 외부에 공개하여 코드 안정성을 높여야함.
- 내부 데이터를 직접 노출하지 않고, getter/setter 메서드를 통해 제어
- 캡슐화 : 내부 구현을 감추고, 필요한 부분만 외부에 공개하여 코드 안정성을 높여야함.
-
클래스는 작아야 한다 -> 클래스가 작아야 코드 가독성이 높고, 변경에 유연
- 단일 책임 원칙(SRP)
클래스는 하나의 책임만 가져야 하며, 변경의 이유가 하나여야 함. - 응집도
클래스의 메서드와 변수가 밀접하게 연관되어 있을 때, 그 클래스는 응집도가 높다고 함.
높은 응집도는 클래스의 일관성과 이해의 용이성을 높인다.
- 단일 책임 원칙(SRP)
-
SRP와 응집도: 잘못된 코드
public class UserManager { private List<User> users; private Logger logger; public void addUser(User user) { users.add(user); logger.log("User added: " + user.getName()); } public void removeUser(User user) { users.remove(user); logger.log("User removed: " + user.getName()); } public void printUsers() { for (User user : users) { System.out.println(user.getName()); } } }public class UserManager { private List<User> users; public void addUser(User user) { users.add(user); } public void removeUser(User user) { users.remove(user); } public List<User> getUsers() { return users; } } public class UserLogger { private Logger logger; public void logUserAdded(User user) { logger.log("User added: " + user.getName()); } public void logUserRemoved(User user) { logger.log("User removed: " + user.getName()); } } -
응집도를 유지하면 작은 클래스 여럿이 나온다
-
변경하기 쉬운 클래스
-
변경으로부터 격리
클래스 설계 시, 변경이 필요한 부분과 그렇지 않은 부분을 분리하여 변경의 영향을 최소화해야 한다.public class ReportGenerator { public void generateHTMLReport() { System.out.println("HTML Report"); } public void generatePDFReport() { System.out.println("PDF Report"); } }문제점 : 출력 형식이 추가되면 메서드가 계속 늘어남, 새로운 포맷 추가 시 기존 클래스를 수정해야 함
public interface Report { void generate(); } public class HTMLReport implements Report { @Override public void generate() { System.out.println("HTML Report"); } } public class PDFReport implements Report { @Override public void generate() { System.out.println("PDF Report"); } } public class ReportGenerator { public void generateReport(Report report) { report.generate(); } }개선 -> 새로운 포맷을 추가하려면 Report 인터페이스를 구현한 클래스를 추가하기만 하면 된다.
기존 코드 수정 없이 확장성 확보
-
단위 테스트
오류처리
- 오류 코드보다 예외를 사용하라
예외를 사용하라 (Return Code 대신)
오류를 반환 코드로 처리하지 말고, 예외로 처리하자.
반환 코드는 프로그램 흐름을 꼬이게 만들고, 실수로 무시될 가능성이 있다.
예외 처리를 사용하면 오류 발생 시 바로 감지할 수 있어 디버깅이 용이하다.
예시: 잘못된 방식 (Return Code 사용)
예시: 올바른 방식 (예외 사용)if (deletePage(page) == -1) { System.out.println("Error: Could not delete page."); }try { deletePage(page); } catch (PageDeletionException e) { System.out.println("Error: " + e.getMessage()); } - Try-Catch-Finally문부터 작성하라
예외를 사후 처리하지 말고, 처음부터 구조적으로 잡을 수 있는 곳에서 예외를 처리하는것이 좋다 - 미확인(unchecked)예외를 사용하라
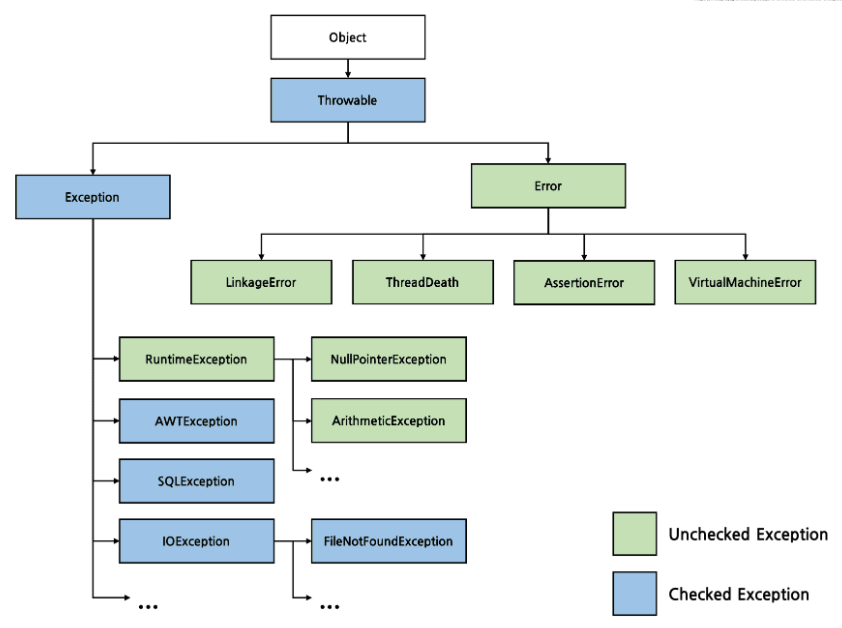

Checked 예외는 호출부에서 반드시 처리해야 하므로, 코드가 복잡해진다.
Unchecked 예외(런타임 예외)는 명시적 처리가 필요하지 않아 간결한 코드 작성이 가능하다.
단, 비즈니스 로직에서 꼭 필요한 경우에만 사용해야 한다.
일반적으로 런타임 시점에 발생할 가능성이 높은 예외에 적합하다.
예시: checked 예외 사용
public void process() throws IOException {
// 복잡하고 불필요한 예외 처리
}예시: unchecked 예외 사용
public void process() {
throw new RuntimeException("Process failed");
}-
호출자를 고려해 예외 클래스를 정의하라
오류를 정의할 때 프로그래머에게 가장 중요한 관심사는 오류를 잡아내는 방법이 되어야 한다.
잘못된 예시 : 예외 유형이 세분화된 경우다음은 오류를 형편없이 분류한 사례다. ACMEPort port = new ACMEPort(12); try { port.open(); } catch (DeviceResponseException e) { reportPortError(e); logger.log("Device response exception", e); } catch (ATM1212UnlockedException e) { reportPortError(e); logger.log("Unlock exception", e); } catch (GMXError e) { reportPortError(e); logger.log("Device response exception"); } finally { ... //자원 해제 코드 }-
위 문제점
- 중복 처리 코드가 많음(다른 예외들이나 처리 방식이 거의 동일)
위 경우 예외에 대응하는 방식이 예외 유형과 무관하게 거의 동일하다. 그래서 코드를 간결하게 고치기가 쉽다.
- 호출자 입장에서 복잡함
포트 열기라는 단순 작업을 수행하는 코드에 너무 다양한 예외 처리가 들어가 있다.
예외가 다양하니, 호출자 입장에서 어떤 예외가 발생할지 예측하기 어렵다. -
올바른 예시: 예외를 래핑하여 단일화
LocalPort port = new LocalPort(12); try { port.open(); } catch (PortDeviceFailure e) { reportError(e); logger.log(e.getMessage(), e); } finally { ... }호출하는 라이브러리 API를 감싸면서 예외 유형 하나를 반환.
ACMEPort 클래스가 던지는 예외를 래퍼 클래스로 감싸서 예외 코드를 보다 간결하게 작성할 수 있다.PortDeviceFailure라는 단일 예외로 모든 오류를 처리여기서 LocalPort 클래스는 단순히 ACMEPort 클래스가 던지는 예외를 잡아 변환하는 래퍼 클래스일 뿐이다.
public class LocalPort { private ACMEPort acmePort; public LocalPort(int portNumber) { acmePort = new ACMEPort(portNumber); } public void open() throws PortDeviceFailure { try { acmePort.open(); } catch (DeviceResponseException | ATM1212UnlockedException | GMXError e) { throw new PortDeviceFailure(e); // 예외를 감싸서 던짐 } } }LocalPort 클래스 내부에서 여러 가지 예외를 하나의 예외로 감싼다.
이렇게 하면 저수준 API의 복잡성을 숨기고, 상위 계층에서는 단일화된 예외만 처리할 수 있다.
-
- 정상 흐름을 정의하라
정상 흐름과 오류 처리 흐름을 분리하여, 코드의 의도가 명확하게 보이도록 해야한다.
정상 로직을 중심으로 하고, 예외 처리 코드는 별도로 분리
잘못된 예시
try {
MealExpenses expenses = expenseReportDAO.getMeals(employee.getID());
m_total += expenses.getTotal();
} catch (MealExpensesNotFound e) {
m_total += getMealPerDiem(); // 기본 식비를 추가
}식비 정보가 없으면 기본값을 사용하는 게 핵심인데,
예외를 던지는 방식은 예외 상황처럼 보이기 때문에 의도가 불명확하다.
올바른 예시
MealExpenses expenses = expenseReportDAO.getMeals(employee.getID());
m_total += expenses.getTotal();
public class ExpenseReportDAO {
public MealExpenses getMeals(int employeeId) {
MealExpenses expenses = findMealExpenses(employeeId);
if (expenses == null) {
return new PerDiemMealExpenses(); // 기본 식비 객체 반환
}
return expenses;
}
}
public class PerDiemMealExpenses implements MealExpenses {
@Override
public int getTotal() {
return getMealPerDiem(); // 기본 식비 반환
}
}특수 사례 패턴 (Special Case Pattern) :
특수 상황을 처리하기 위한 별도 객체를 만들어 코드 흐름을 단순화하는 패턴
-
null을 반환하지 마라
null을 반환하면 호출자가 매번 null을 체크해야 하며,
하나라도 빠지면 NullPointerException(NPE)가 발생할 가능성이 있다. -> 특수 사례 객체나 빈 컬렉션을 반환하여 null 검사를 방지
잘못된 코드: null을 반환하는 경우public void registerItem(Item item) { if (item != null) { ItemRegistry registry = persistentStore.getItemRegistry(); if (registry != null) { Item existing = registry.getItem(item.getId()); if (existing.getBillingPeriod().hasRetailOwner()) { existing.register(item); } } } }문제점
null을 반환함으로써 호출자에게 문제를 떠넘긴다.
null 확인 누락 가능성
불필요한 null 체크 발생
개선 방법 1: 특수 사례 객체 사용public class NullItemRegistry extends ItemRegistry { @Override public Item getItem(String id) { return new NullItem(); // 특수 사례 객체 반환 } } public void registerItem(Item item) { ItemRegistry registry = persistentStore.getItemRegistry(); Item existing = registry.getItem(item.getId()); if (existing.getBillingPeriod().hasRetailOwner()) { existing.register(item); } }-> null인지 검사할 필요 없이 항상 Item 타입으로 처리 가능
NullItem에서, 내부의 getBillingPeriod()가 NullBillingPeriod를 반환하여 null이 아님
NullItem의 register() 메서드도 호출 가능하므로 NPE 발생 가능성이 없음
개선 방법 2: 빈 컬렉션 반환public List<Employee> getEmployees() { if (/* 직원이 없다면 */) { return Collections.emptyList(); // 빈 리스트 반환 } return employeeList; } List<Employee> employees = getEmployees(); for (Employee e : employees) { totalPay += e.getPay(); }null체크 없이 반복문 바로 사용이 가능하다.
-
null을 전달하지 마라
null을 인수로 전달하면 NullPointerException(NPE)이 발생 가능.null을 허용하는지 아닌지 불명확하여 코드 사용이 불편. -> 명시적 예외 처리 또는 null 금지 규칙을 적용하여 코드 안정성 확보 필요
잘못된 코드: null을 허용하는 메서드public class MetricsCalculator { public double xProjection(Point p1, Point p2) { return (p2.x - p1.x) * 1.5; } } // 호출부 MetricsCalculator calculator = new MetricsCalculator(); calculator.xProjection(null, new Point(12, 13)); // NPE 발생대안) 명시적 예외 던지기
public class MetricsCalculator { public double xProjection(Point p1, Point p2) { if (p1 == null || p2 == null) { throw new IllegalArgumentException("Invalid argument for MetricsCalculator.xProjection"); } return (p2.x - p1.x) * 1.5; } }대안) assert 문 사용(단, assert 문은 기본적으로 비활성화되어 있어,프로덕션 환경에서는 오류를 잡지 못할 가능성)
public class MetricsCalculator { public double xProjection(Point p1, Point p2) { assert p1 != null : "p1 should not be null"; assert p2 != null : "p2 should not be null"; return (p2.x - p1.x) * 1.5; } }
시스템
창발성
동시성
점진적인 개선
JUnit
SerialDate 리팩터링
냄새와 휴리스틱
OCP (개방 폐쇄의 원칙 : Open Close Principle)
유지 보수와 확장이 쉬운 시스템을 만들고자 로버트 마틴이 명명한 객체지향설계 5대 원칙 SOLID중 하나
소프트웨어 구성 요소(컴포넌트, 클래스, 모듈, 함수)는 확장에 대해서는 개방(OPEN)되어야 하지만 변경에 대해서는 폐쇄(CLOSE)되어야 한다
OCP 적용방법-> 상속/컴포지션
클린코드 중 무엇이 중요할까? (chat gpt 문의 : 챕터 구분 및 그 내에서 중요도 순 배치 요청)
a. 필수 챕터 (핵심 원칙과 기본기)
이 파트는 클린 코드의 핵심 원칙이자, 코드를 깨끗하고 이해하기 쉽게 만들기 위한 기본기야.
대부분의 클린 코드 요약에서도 가장 강조되는 부분들이야.
💎 1. 의미 있는 이름 (Chapter 2)
- 중요도: ★★★★★
- 이유: 코드 가독성의 첫걸음이자 가장 기본적인 원칙.
- 핵심 내용:
- 이름은 의도와 맥락을 명확히 전달해야 한다.
- 함수, 변수, 클래스 등 모든 부분에 적용되는 중요한 규칙.
- 잘못된 이름 선택은 코드 전체를 이해하기 어렵게 만든다.
- 이름은 의도와 맥락을 명확히 전달해야 한다.
📝 2. 함수 (Chapter 3)
- 중요도: ★★★★★
- 이유: 코드의 재사용성과 가독성을 크게 좌우하는 요소.
- 핵심 내용:
- 함수는 작고 하나의 역할만 해야 한다.
- 의미 있는 이름과 명료한 구조로 가독성을 높인다.
- 중복을 줄이고, 함수 간 의존성을 최소화한다.
- 함수는 작고 하나의 역할만 해야 한다.
🧪 3. 단위 테스트 (Chapter 9)
- 중요도: ★★★★★
- 이유: 코드의 안정성을 보장하고, 리팩토링과 수정이 쉽게 만든다.
- 핵심 내용:
- 테스트 코드도 깨끗하게: 가독성과 명확성을 갖추자.
- TDD로 코드 안정성을 먼저 확보하자.
- 코드 수정 시 회귀 버그 방지를 위한 필수 장치.
- 테스트 코드도 깨끗하게: 가독성과 명확성을 갖추자.
🚩 4. 오류 처리 (Chapter 7)
- 중요도: ★★★★☆
- 이유: 오류 처리가 코드 품질에 직접적인 영향을 미치기 때문.
- 핵심 내용:
- 예외를 명확히 사용하고, 오류 코드를 반환하지 않도록 한다.
- null 반환을 지양하고, 예외 메시지는 직관적이어야 한다.
- 예외 처리를 구조적으로 관리하여 코드 복잡성을 줄인다.
- 예외를 명확히 사용하고, 오류 코드를 반환하지 않도록 한다.
🏷️ 5. 클래스 (Chapter 10)
- 중요도: ★★★★☆
- 이유: 객체지향 설계의 기본 단위로, 코드 구조의 근간을 이룬다.
- 핵심 내용:
- 클래스는 단일 책임 원칙(SRP)을 지켜야 한다.
- 응집도를 높이고 결합도를 줄이는 설계가 중요하다.
- 작고 명확한 역할을 가지도록 설계한다.
- 클래스는 단일 책임 원칙(SRP)을 지켜야 한다.
🚧 b. 실무 필수 챕터 (프로젝트와 코드 개선)
코드의 구조적 개선과 유지보수성을 높이는 데 중요한 부분들로, 실무 프로젝트에서 반드시 고려해야 할 내용이다.
🗺️ 6. 시스템 (Chapter 11)
- 중요도: ★★★★☆
- 이유: 프로젝트 규모가 커질수록 구조적 관리가 필수.
- 핵심 내용:
- 의존성 주입(DI)와 IoC로 결합도 줄이기.
- 모듈 간 의존성 최소화와 설정 로직 분리를 통해 구조화.
- 의존성 주입(DI)와 IoC로 결합도 줄이기.
🔄 7. 동시성 (Chapter 13)
- 중요도: ★★★☆☆
- 이유: 멀티스레드 환경에서 데이터 안정성 확보가 필수.
- 핵심 내용:
- 스레드 안전성 확보를 위해 동시성 문제를 명확히 인식해야 한다.
- 락(lock) 사용과 상태 불변성 유지.
- 동시성 테스트를 통해 코드 안정성을 확보한다.
- 스레드 안전성 확보를 위해 동시성 문제를 명확히 인식해야 한다.
🧩 8. 창발성 (Chapter 12)
- 중요도: ★★★☆☆
- 이유: 코드가 자연스럽게 단순하고 명확하게 발전해야 한다.
- 핵심 내용:
- 중복 제거와 명료성 강화로 깨끗한 코드 유지.
- 테스트 주도 개발(TDD)로 코드 품질을 개선한다.
- 중복 제거와 명료성 강화로 깨끗한 코드 유지.
⚙️ c. 보조 챕터 (코드 품질 유지와 개선)
클린 코드의 원칙을 유지하고 개선하기 위한 부차적인 요소들이다.
🔧 9. 형식 맞추기 (Chapter 5)
- 중요도: ★★☆☆☆
- 이유: 코드 스타일이 일관되면 협업과 가독성이 좋아진다.
- 핵심 내용:
- 들여쓰기와 공백을 일관되게 관리.
- 코드 스타일 가이드라인을 설정하여 유지보수성 강화.
- 들여쓰기와 공백을 일관되게 관리.
🗂️ 10. 경계 (Chapter 8)
- 중요도: ★★☆☆☆
- 이유: 외부 라이브러리와의 경계를 명확히 해야 의존성 관리가 용이하다.
- 핵심 내용:
- 인터페이스로 경계 구분하여 외부 의존성을 줄이자.
- 테스트를 통해 외부 API와의 연동을 명확히 검증하자.
- 인터페이스로 경계 구분하여 외부 의존성을 줄이자.
🧱 11. 객체와 자료구조 (Chapter 6)
- 중요도: ★★☆☆☆
- 이유: 객체와 자료구조의 구분을 명확히 해야 코드의 역할이 뚜렷하다.
- 핵심 내용:
- 행위 중심의 객체와 데이터 중심의 자료구조를 구별하자.
- 데이터 캡슐화와 객체의 역할 강화를 통해 구조를 명확히 한다.
- 행위 중심의 객체와 데이터 중심의 자료구조를 구별하자.
🗃️ 기타 보조 챕터
- 점진적인 개선 (Chapter 14): 리팩토링의 중요성 강조
- JUnit 소개 (Chapter 15): 단위 테스트를 위한 도구 설명
- SerialDate 리팩터링 (Chapter 16): 실무 리팩토링 사례
- 냄새와 휴리스틱 (Chapter 17): 코드 개선을 위한 체크리스트
📝 최종 정리
- 필수 챕터는 클린 코드의 기본 원칙과 구조적 핵심을 다루며, 실무에서도 가장 중요하다.
- 실무 필수 챕터는 대규모 프로젝트와 코드 개선에서 필요하다.
- 보조 챕터는 코드 품질 유지를 위한 세부 사항으로, 상대적으로 덜 중요하지만 여전히 유용하다.
이렇게 나누면 실제 Clean Code를 공부할 때 더 현실적이고, 실무에서도 우선순위가 명확해! 💪🚀
