Lecture2.Linear Regression with Multiple Variables
Model & Cost Function
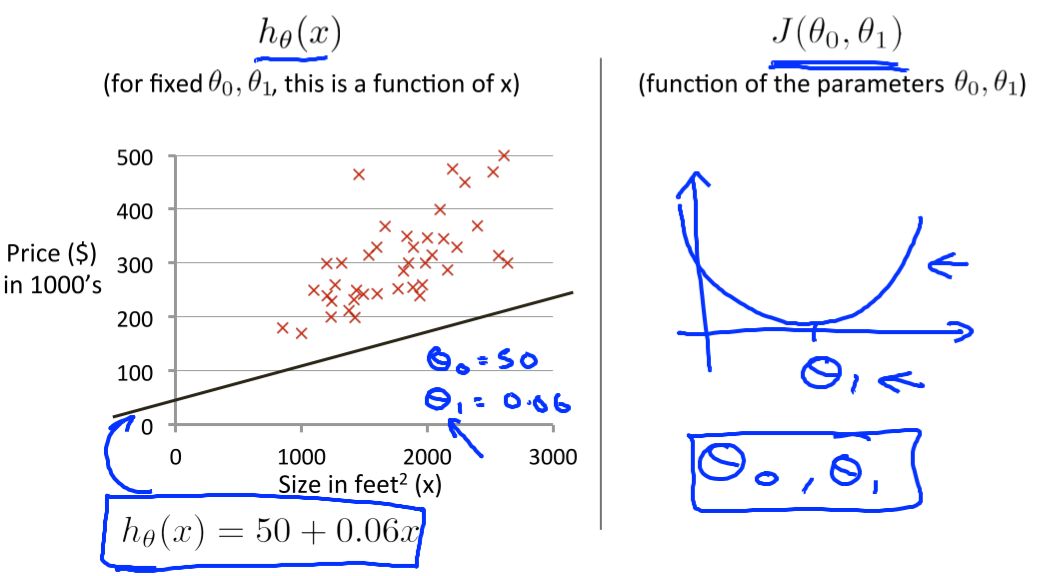
Model 표현
모델이라는 것은 데이터들을 학습해서 그 결과로 얻어진 무언가이고, 기계(모델)은 학습한 결과로 어떠한 데이터가 들어왔을 때 그 input에 대한 result를 예측 혹은 판단해줄 수 있게 된다.
m = Number of training examples
x’s = “input” variable / features
y’s = “output” variable / “target” variable
model 표현은 training example 수와, input feature, output variable로 이루어진다.
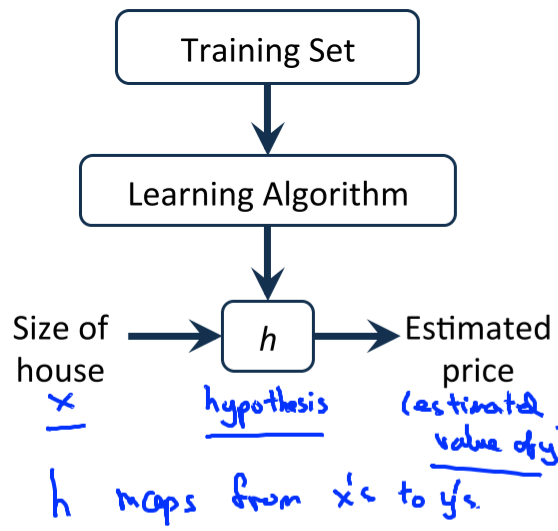
모델 h는, x input을 결과인 y로 매핑시켜주는 것.
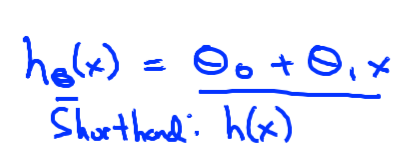
Cost Function
CostFunction은 주어진 training set(데이터셋)에 가장 적합한 선형 함수를 도출해낸다.
예를들어 linear regression의 h(θ)에서는 θ1, θ2를 결정해야 매핑 역할인 1차함수를 결정할 수 있다.
- 이 때 학습을 통해서 θ들을 결정할텐데, 데이터들을 가지고 이 θ 값을 어떻게 결정할 수 있을까 ?
-> 각 데이터들에 대해 한 직선과 데이터 오차 최소를 구하면 된다.
이 때 이 직선을 구하기 위해 θ값들을 바꿔가며 테스트하게되는데, 이 때 데이터 오차에 해당하는 '비용'이 Cost이고 이 Cost를 구하기 위한 측정방법, 함수가 Cost Function인 것이다.

여기서는 이 차이를 절대값이 아닌 square를 사용해서 구하고있고,
h(xi)는 i번째 훈련셋의 입력값에 대한 h의 예측값.
yi는 실제 i번째 훈련셋의 정답이다.
(h(xi)-yi)^2들의 시그마는 모든 훈련셋들에대해
이 θ0, θ1을 사용했을 때 오차가 얼마나 나올지를 측정하는 것이다. = J(θ0,θ1)
그렇기 때문에 최종적으로 이 J(θ0,θ1)를 최소화하는 것이 = cost function을 최소화하는 θ들을 찾는 것이 regression의 핵심인 것. (= 딱 맞는 기울기를 찾는다.)
- 이 때, Cost Function을 최소화한다는 것의 의미는 ?
cost function에서 J는 결과값이다. θ는 input값이다.
cost function은
theta 0=-0.5 theta 1=800쯤이라고 했을 때,
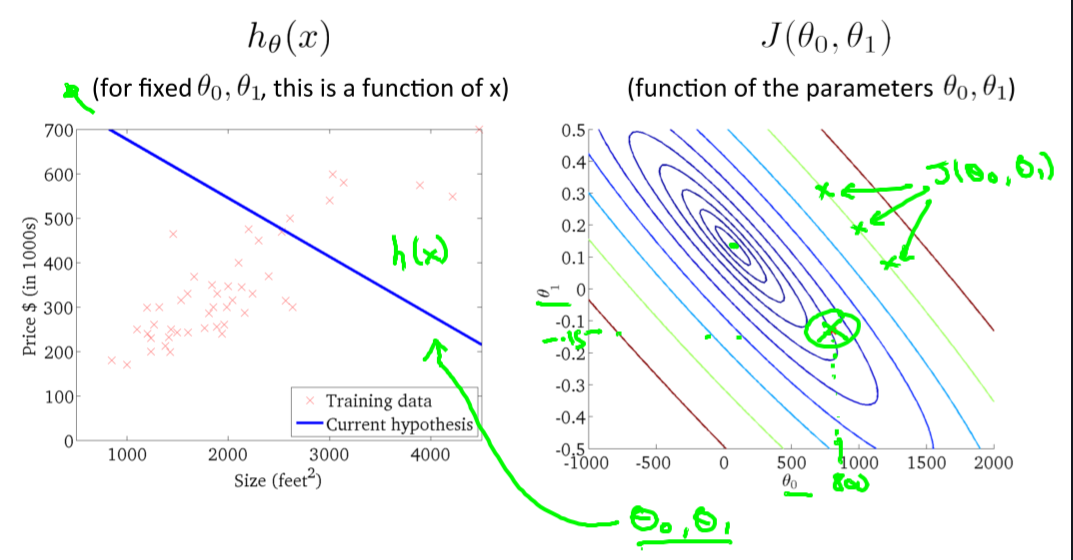
오른쪽 그래프는 같은 J 결과값을 갖는 theta값들을 연결한 선이며, 같은 값을 같는 theta들의 값이 넓게 떨어져 분포하며, 많은 theta들에서 동일값이 나오는 것을 볼 수 있다.
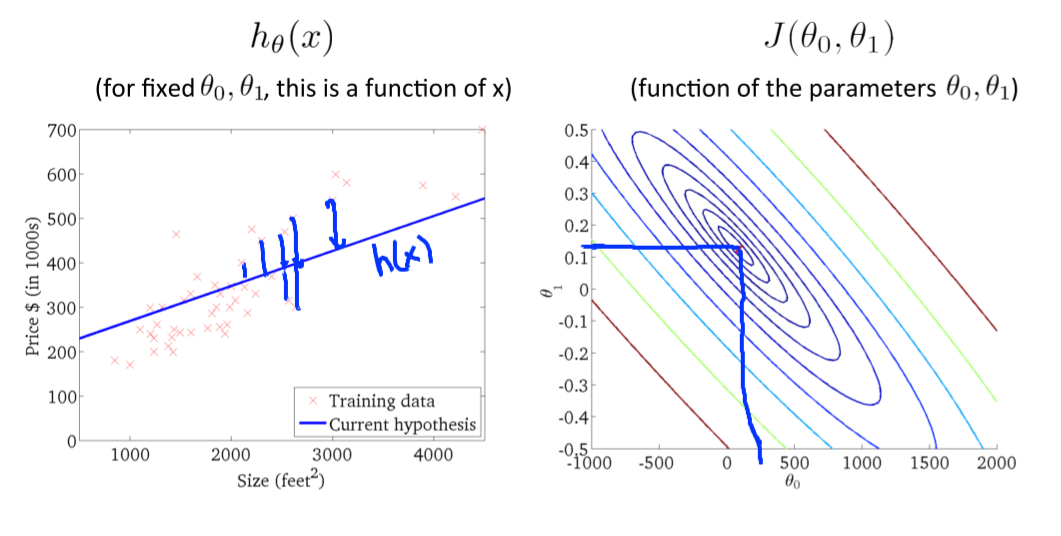
최적의 기울기를 선택했을 때, 최저 J값을 가질 때에는,다음과 같이 한 점으로 수렴하는 분포를 가지는 J값을 가지게 된다.
이 때, J는 어떤 함수인지?
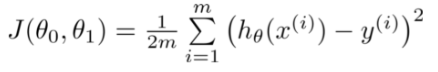
h에대한 2차함수이다. h에 대한 이차함수라는 것은 변수인 theta0,theta1에 대한 이차함수라는 것.
-> 극값에서 최소이므로, 결국 수렴점에서 최소를 갖는다.
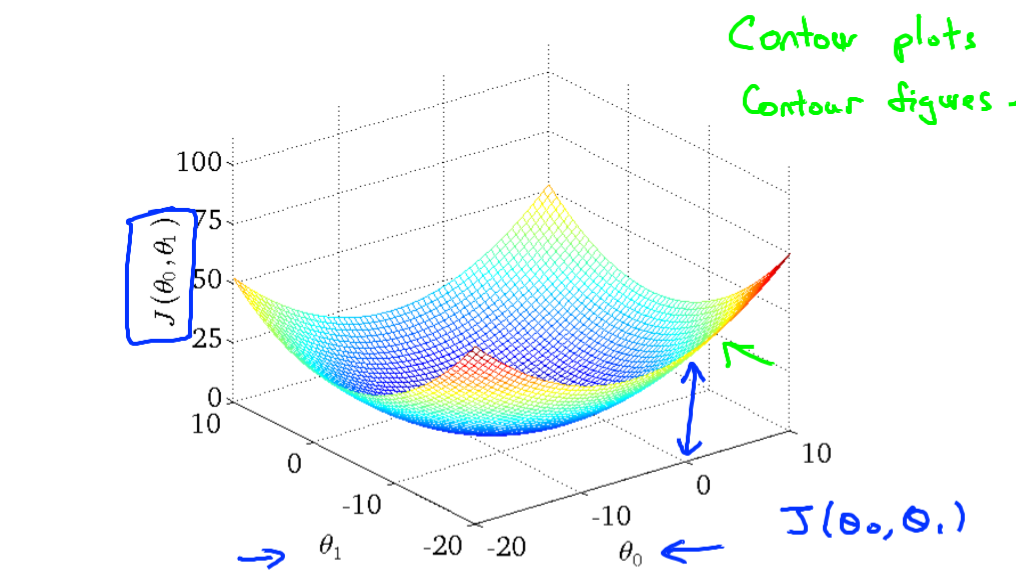
theta가 많아지면 복잡해지며, local min, opt min등이 발생하겠지만, 어찌되었든 cost function이라는 것은 결국 이 min, 극값(extremum)을 찾아나가는 것이고,
이 방법으로는 Gradient Descent가 존재한다.(경사하강법)
Gradient Descent
Gradient Descent는 경사하강법으로, Min Cost Function을 구하는 알고리즘이다. 경사가 하강한다는 의미는 기울기(절대값, 실질적 경사)가 감소하는 방향으로 = 극값방향으로 = J값이 작아지는 방향으로 theta들을 이동, 갱신시켜나가는 방법.

- 이 때, α : Learning Rate이다. 한 스텝에 얼마나 이동하는지에 대한 수치로, 사람이 지정한다. 이 때,
만약 α가 너무 크다면 ? 극값을 뛰어넘어버릴 수 있다. -> 값이 수렴하지 않고 발산할 수 있다.(극값을 지나침)
α가 너무 작다면 ? -> 지나치게 느려 학습 효율이 떨어질것이다.
(∂/∂θj) * J(θ0,θ1) : θ에 대한 J(Cost Function)의 미분계수=기울기 이다.
결국 위 수식은, theta값들에대해(linear regression의 theta number in (0,1))
어떠한 값들을 더해주는데(빼주는데), 그 값은 현재의 접선의 기울기,방향만큼(* 속도)이다 . -> 기준이 되는 점을 이동시키는 것 의미.
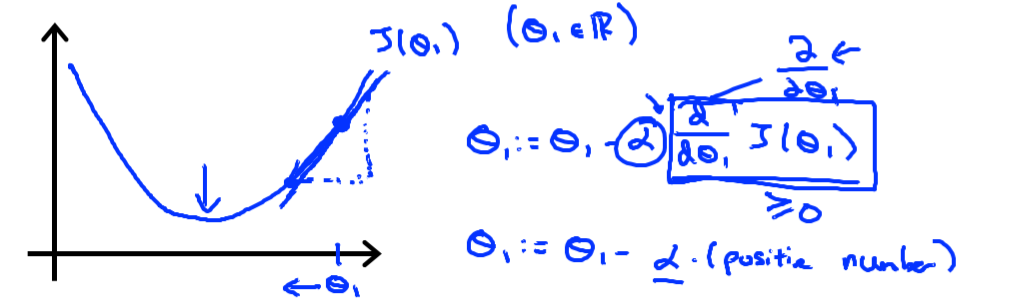
마이너스는 해당 위치에서 (theta), theta만큼 이동했을 때 양의 방향으로 J값이 나아간다는 것을 의미하므로 역으로 빼준다.
Gradient descent for linear regression
J를 실제로 대입해보면 Linear Regression에서의 실제 적용해야할 값을 알 수 있다.

계산과정은 다음과 같다.
θ가 0인경우, 상수에대한 미분이므로 연쇄법칙에의해
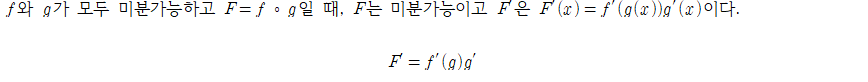 g'는 theta0에대한 미분이므로1, f'는 g^2에대한 미분이므로 2g.
g'는 theta0에대한 미분이므로1, f'는 g^2에대한 미분이므로 2g.
θ가 1인경우에는 g'는 theta1에대한 미분이므로 x이다.
(* hθ(x) = θ0 + θ1x)
초기 theta값들로부터 반복적으로 theta0, theta1를 순차적으로 갱신시켜나가고, 최종적으로 cost function J(θ0,θ1)이 최소가되는 θ set을 얻게된다.
주의점은 hθ(x)는 θ에대한 함수이므로 두 값이 simultaneously 변경되어야한다는 점.
Lecture4.Linear Regression with multiple variables
Multivariate Linear Regression
Multiple features
linear regression의 다음 Feature(x)는
m = Number of training examples
x’s = “input” variable / features
y’s = “output” variable / “target” variable

다음과 같이 multiple feature(xj)들로 확장될 수 있으며 모델인 가설함수 hθ(x)도 다음과 같이 표현할 수 있다.
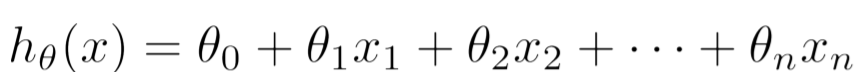
예측할 때 단순 변수가 하나가 아닌 경우가 많으므로, 위와 같이 일반화하는게 더 합리적. (ex- 집갑 예측에서 위치,평수,연도,방 개수 등.
Gradient descent for multiple variables
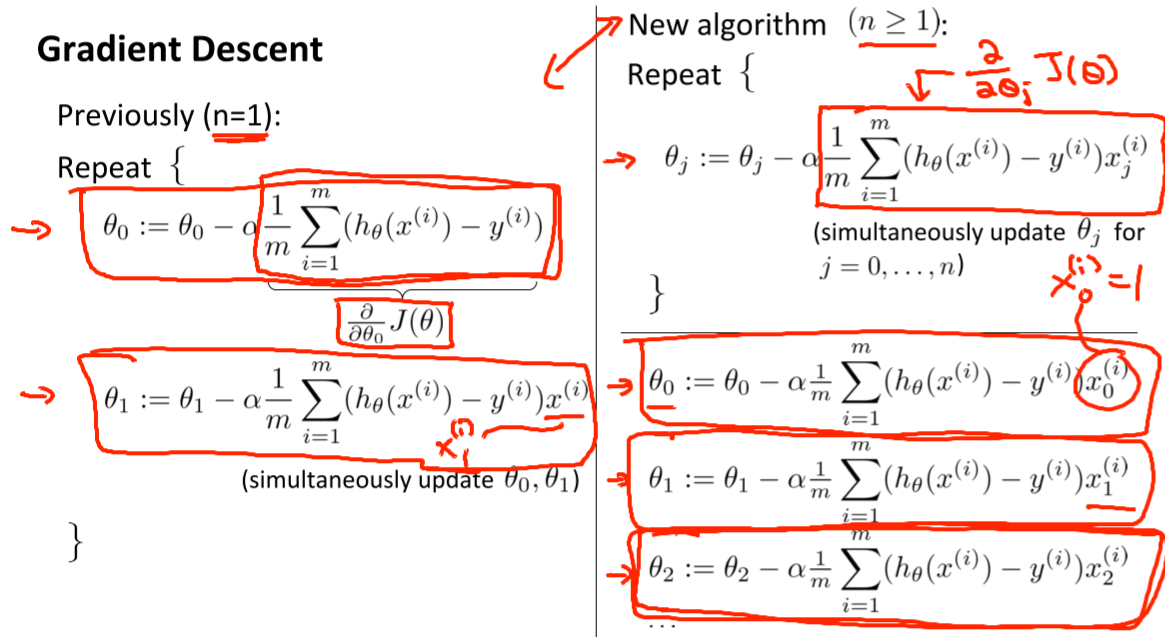
multiple feature를 가진다면, (hθ(x)-yi)^2= ((θ0+x1θ1+x2θ2+x3θ3+x4θ4.....)-yi)^2이므로 각각의 theta들을 모두 갱신시켜주어야하고(simultaneoulsy..), 미분계수(기울기) 는 마찬가지로 각각 theta에 곱해진 x를 (error(h - y)=예측과 정답의 차이)에 곱해준 것과 같다. 0,1이 0,1,2,3,4..로 확장된것.
Gradient descent Feature scaling
multiple features를 가지면서 feature들의 관계도 생각해주어야한다. cost function의 인자인 theta는, feature에 곱해지는 값이고, feature들이 동일 스케일을 가진다고 할 수 없으므로 (값들이 10000,0,-10000인 feature들과 1,2,3,4인 feature들 등) theta갱신 시 동일 속도로 optimum 혹은 local minimum에 수렴하지 않을 수 있다.
feature scaling을 통해 범위를 비슷하게 맞춰준다면 gradient descent는 더욱 빠르게,효율적으로 값을 찾아나갈 수 있다.
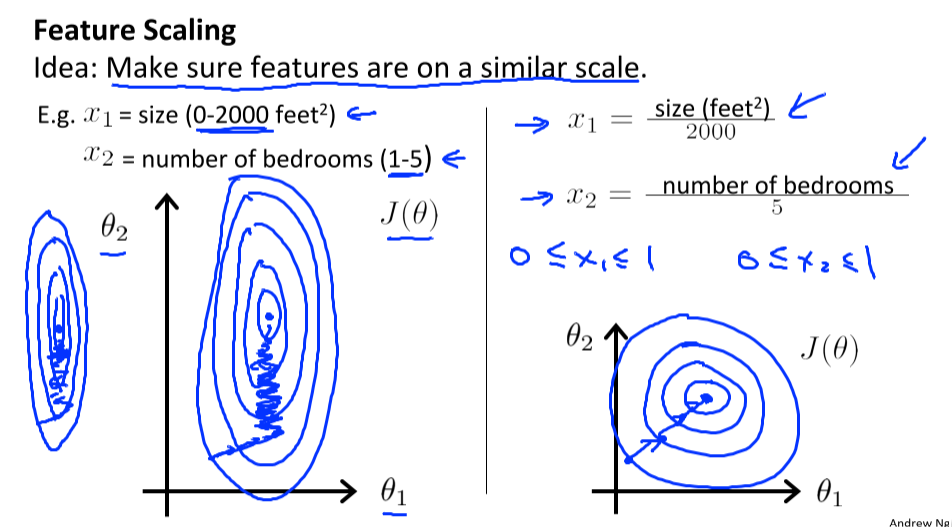
feature는 하나의 축.이므로 축의 편차가 클수록 찌그러지고, 비효율적으로 값을 찾아나갈가능성이 높다
- Mean Normalization
mean normalization은 mean값을 0으로 만들고, 길이를 1로 정규화시키는 방법이다.
-> -0.5<=xj<=0.5 로 변환.
xj=(xj−mean(xj))/(max(xj)-min(xj))
각 값에서 평균을 빼주고(중간 0으로 축 이동), 최대-최소 = 길이로 나눠준다.
Gradient descent Learning Rate
이전에 배웠듯이 too much small하면 비효율적이게 느리고, too much large하면 발산할 수도 있다. 그렇기 때문에 실험적으로 알파값(step size)를 구하기도 함.
Features and polynomial regression
polynomail regression : linear regression을 복잡한 비선형 함수에도 적용시키는 것.

frontage, depth 2가지 feature로 이루어진 polynomial regression을 예시로,
Area라는 Feature로 통합해 linear regression으로 변환할 수 있다.
(Area=Frontage * Depth),
hθ(x)= θ0+θ1x , x=Area
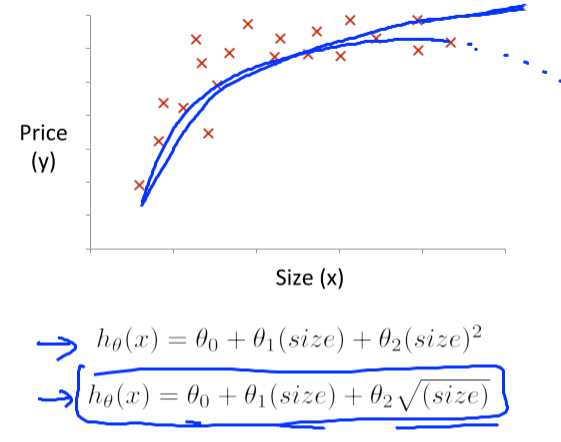
이렇게 동일 feature가 제곱,세제곱 꼴로 나타나는 경우도 치환하여 낮은 차수로 변경해줄수있다(3차함수->제곱근형태), x^4 + x^2인경우에는 4차함수를 x'^2 + x'인 2차함수로 변경하는 등.
Normal Equation
normal equation은 analytically(분석적으로) theta를 찾는 방법이다.
theta를 찾는다는 것은 기존에는 gradient descent를 이용해 더 낮은 J(cost function)을 가지는 값으로 갱신시켜나가고, 변화량이 일정 이하로 떨어질 때 까지(수렴할 떄 까지) 최소화하는것이었다.
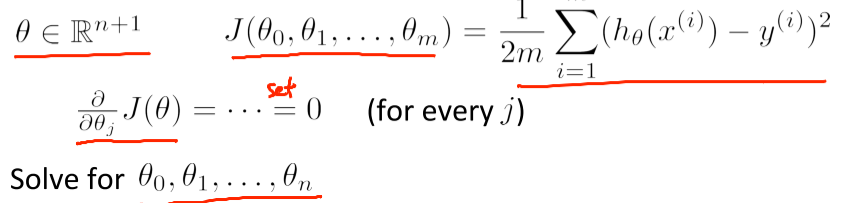
이 때, x feature을 행렬로 표현하면,
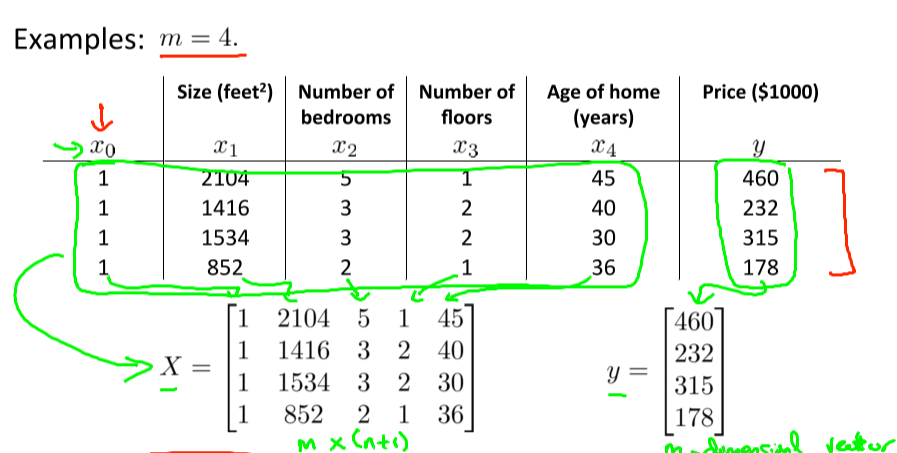
위와 같이 feature개수(열) 훈련셋개수(행) 으로 이루어지는 행렬을 이루게되고,
각 theta들은 각각의 feature들에 곱해지므로
X theta = Y로 표현할 수 있다. (theta는θ0,θ1,θ2,θ3,θ4로 이루어진 열벡터)
=> 선형대수 성질에의해,
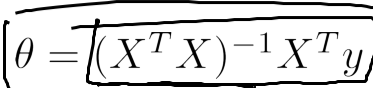
이고 이렇게 행렬을 이용해 값을 도출하는 방법을 normal equation이라고 함.
-
gradient descent, normal equation 비교
GD NE 러닝 스텝 알파를 선택해야함 알파를 선택하지 않아도 된다 반복적이다 반복적이지 않다 n이 충분히 크더라도 잘 동작 가능. n이 매우 크면 느리다. INV(X'X)를 계산해야한다. Normal Equation 방법은 행렬이 singular할경우 역행렬이 존재하지 않을 수도 있다. 그렇기 때문에 octave언어에서는 pinv라는 유사역행렬을 구하는 함수를 제공함( vs inv)

