File Concept
- File : 논리적 저장단위.
비휘발성 보조기억장치에 저장되며 block, record단위로 저장된다. - File System
운영체제와 모든 데이터, 프로그램 저장,접근을 위한 기법 제공.
파일 시스템이라는 개념이 없다면? 고유 블록 번호로 데이터를 관리해야한다. 그러므로 파일시스템을 사용하여 계층적 디렉토리 구조를 사용해 접근,저장,관리가 용이하도록 함. - file attribute
파일 이름, 유형, 저장된 위치, 파일 사이즈, 접근권한,소유자,시간 등 파일이 담고있는 정보들 : meta 영역에 저장된다. 파일의 데이터는 data영역에 저장됨.
Access Methods
파일에 접근하는 방법은?
순차접근(Sequential)
대부분 연산 read, write로 가장 간단하게 접근하는방법.
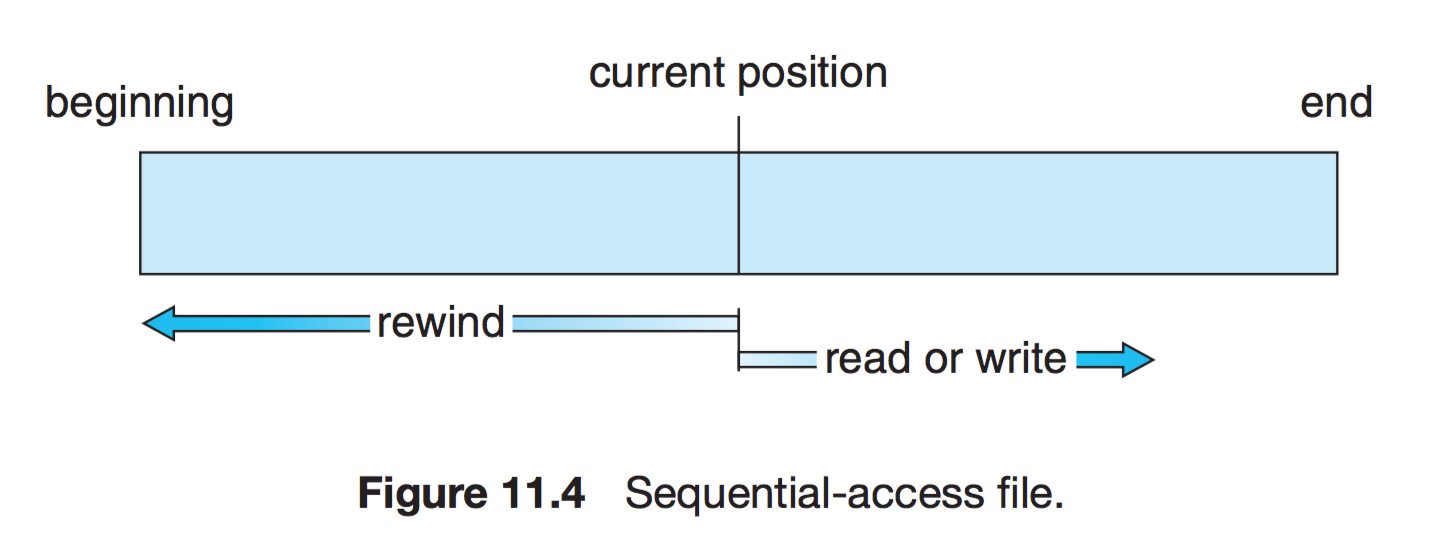
현재 위치를 가리키는 포인터에서 시스템 콜이 발생할 경우 포인터를 앞으로 보내면서 read와 write를 진행. 뒤로 돌아갈 땐 지정한 offset만큼 되감기를 해야 한다.
직접접근(Direct)
현재 위치를 가리키는 cp변수를 사용하여 빠르게 레코드를 read,write한다.
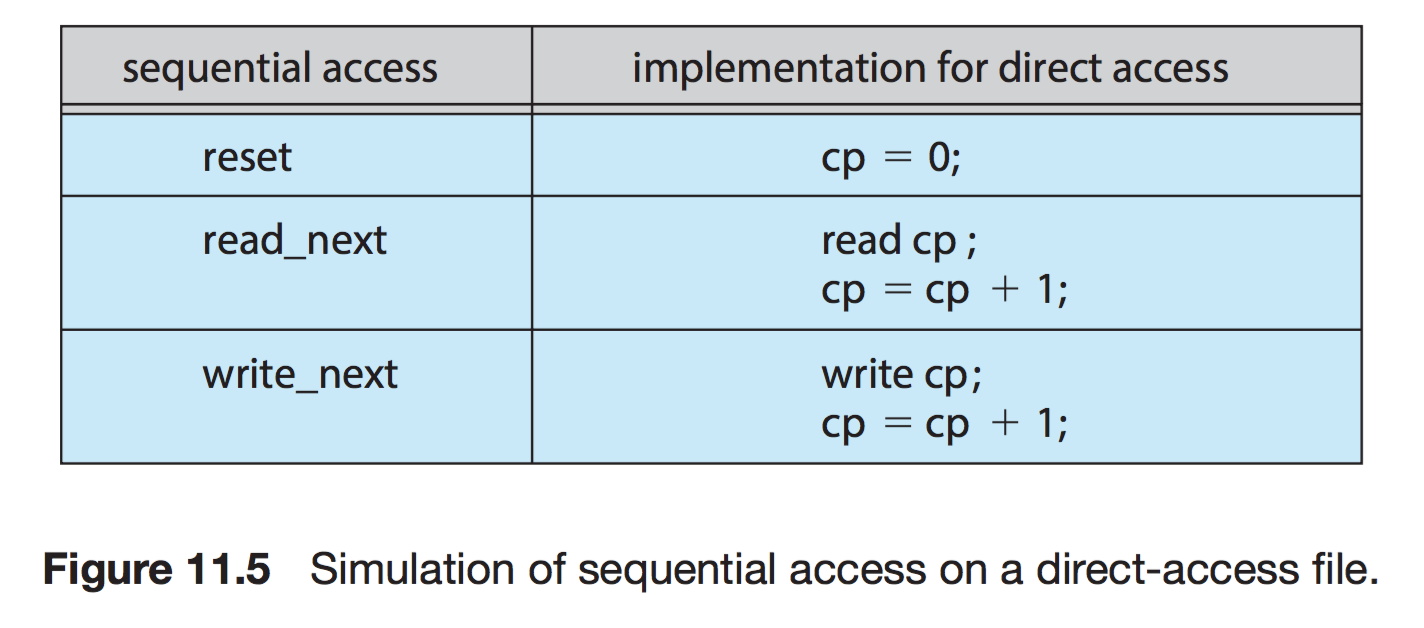
무작위 파일 블록에 대한 임의 접근을 허용해 순서의 제약이 없고, 데이터베이스에서 활용한다.
색인접근(Index)
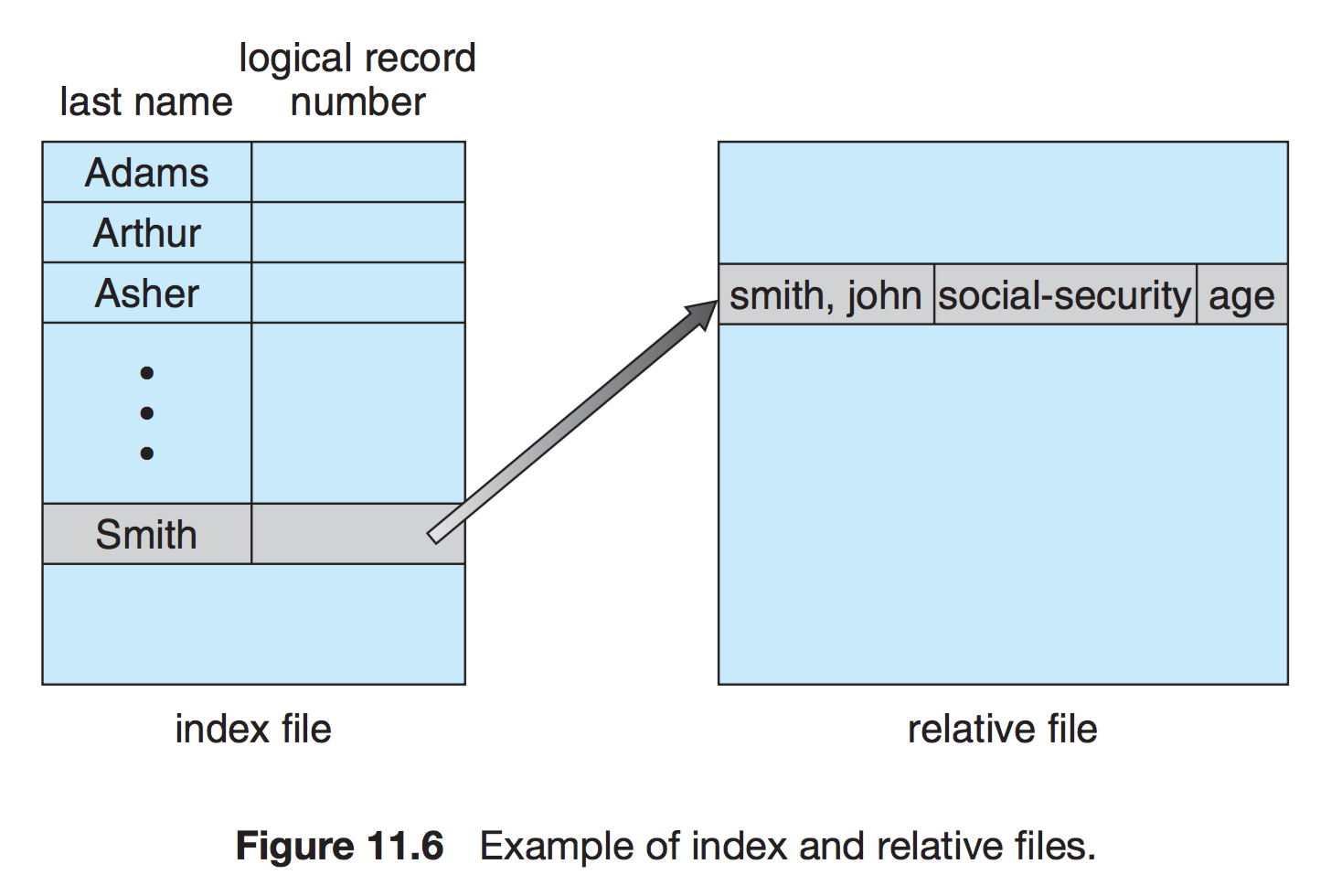
파일에서 레코드를 찾기위한 색인을 찾고 대응되는 포인터를 얻는다.
Directory and Disk Structure
디렉터리(Directory)는 파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별한 파일. 디렉토리는 파일을 빠르게 탐색, 분류하기 위한 일종의 구조이므로 이를 위해 고안된 여러 논리적 구조 정의 방법들이 존재.
1단계 디렉토리
파일들은 서로 유일한 이름을 가짐. 서로 다른 사용자라도 같은 이름 사용 불가, 모든 파일들이 디렉토리 밑에 존재한다.
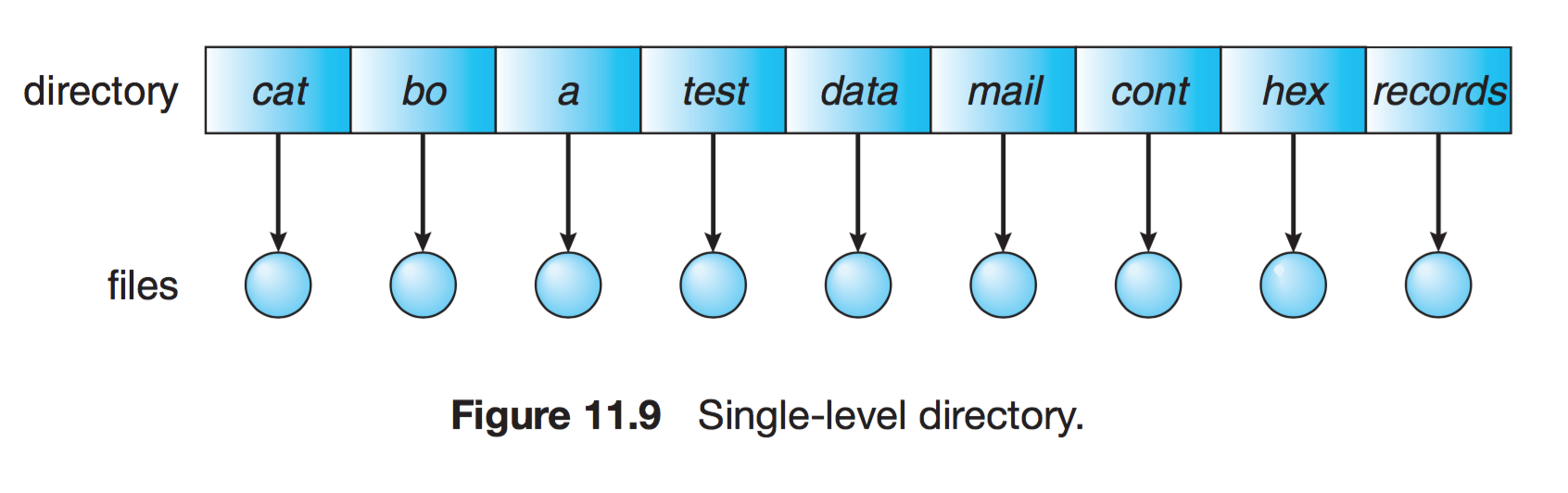{kind=link}
2단계 디렉토리
사용자에게 개별적인 디렉터리 만들어줌
- UFD : 자신만의 사용자 파일 디렉터리(user file)
- MFD : 사용자의 이름과 계정번호로 색인되어 있는 디렉터리(master file)
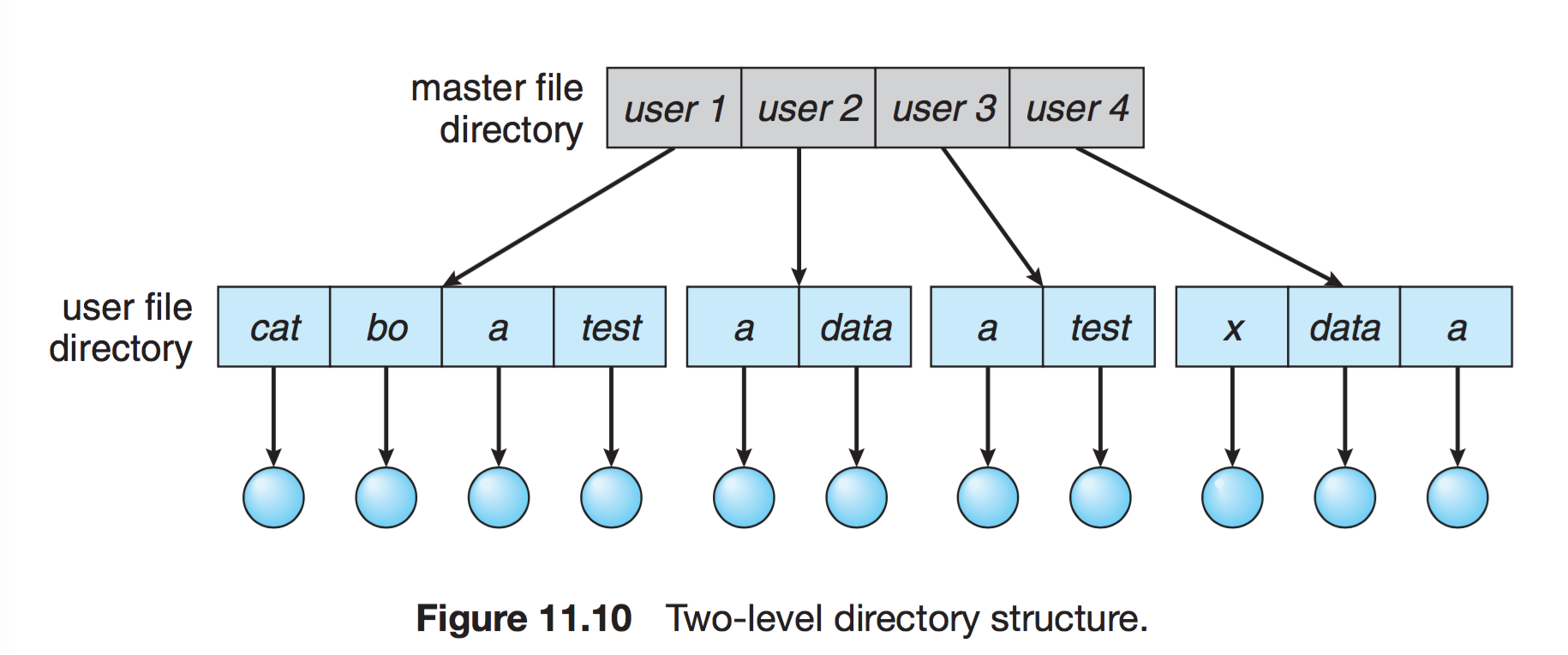
그룹화가 불가능하고, 다른 사용자의 파일에 접근해야 하는 경우에는 단점
트리구조
비트를 활용하여, 일반 파일(0)인지 디렉터리 파일(1) 구분
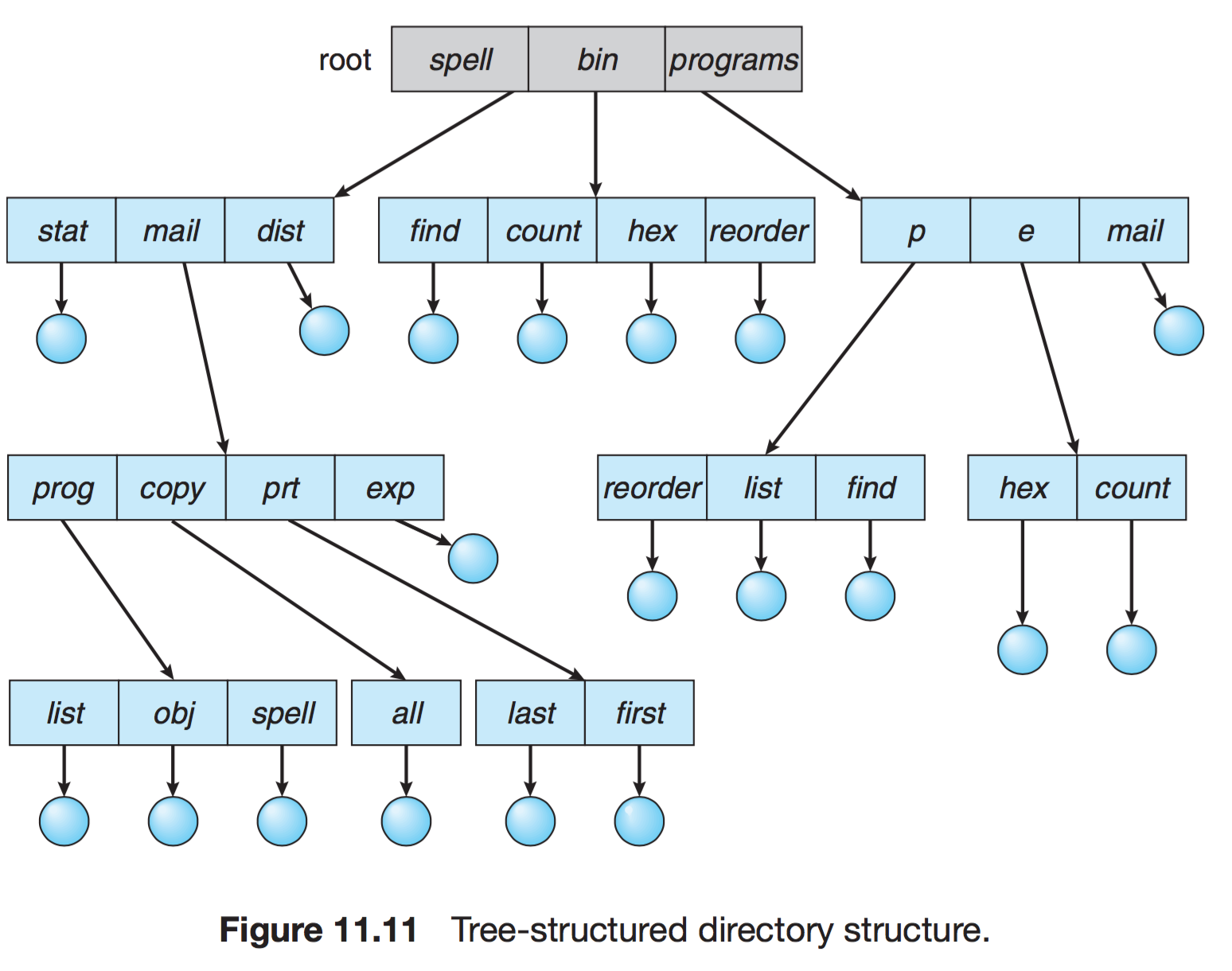
사용자들이 자신의 서브 디렉터리(Sub-Directory)를 만들어서 파일을 구성할 수 있다. 하나의 루트 디렉터리를 가지며 모든 파일은 고유한 경로(절대 경로/상대 경로)를 가진다. 이를 통해 효율적인 탐색이 가능하고, 그룹화가 가능
그래프구조
-
비순환
순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나, 가비지 컬렉션을 이용해 전체 파일 시스템을 순회하고 접근 가능한 모든 것을 표시
디렉터리들이 서브 디렉터리들과 파일을 공유할 수 있도록함.
파일을 무작정 삭제하게 되면 현재 파일을 가리키는 포인터는 대상이 사라지게 된다. 따라서 참조되는 파일에 참조 계수를 두어서, 참조 계수가 0이 되면 파일을 참조하는 링크가 존재하지 않는다는 의미이므로 그때 파일을 삭제할 수 있도록 한다. -
순환 허용
순환이 허용되면 무한 루프에 빠질 수 있다.
따라서, 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나 garbage collection을 통해 전체 파일 시스템을 순회하고, 접근 가능한 모든 것을 표시
Allocation File data in disk & File-system Mounting
물리적은 하드디스크 하나를 파티셔닝을 통해 여러 논리적 디스크로 나눠서 사용할 수 있는데, 각각 논리적 디스크별 파일시스템을 설치해 사용할 수 있다. : mounting연산을 제공, 다른 파티션의 파일시스템을 OS를 통해 접근할 수 있다.
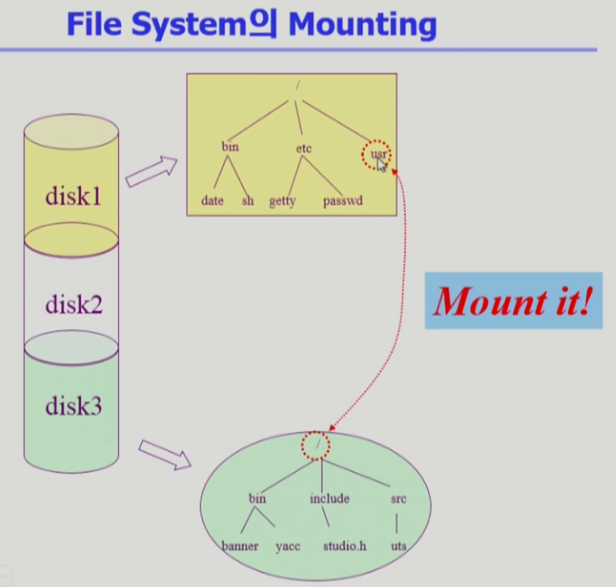
파일은 블록단위(논리)로 관리되는 물리 디스크의 데이터들을 추상화하여 객체로 관리하는 것이라 했다. 이 때 데이터를 어떻게 효율적으로 저장할 수 있을지. -> disk에 파일 데이터를 할당하는방법.
Contiguous Allocation
연송할당. 디스크에 연속되게 파일을 저장한다. 파일의 시작부분 주소(+길이정보)만 알면 해당 파일 전체를 탐색할 수 있다.
:외부단편화가 발생한다. 큰 파일 크기를 고려해 미리 큰 공간 할당 시 내부단편화 발생가능성.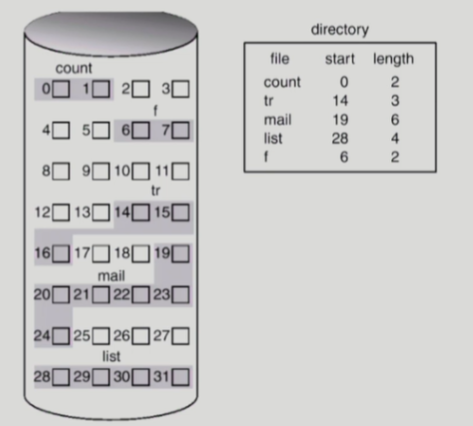
Linked Allocation
연속적으로 할당하지 않고 linked해서 할당, 블록 체인. 링크드 리스트로 블록들을 연결하고, 첫 번째 블록 주소를 알고있으면 링크,링크해서 ..끝까지 탐색한다.
외부 단편화가 발생하지 않다면, random access가 존재하지 않고 포인터를 위한 공간도 block의 일부가 되어 효율성을 떨어뜨린다. 또한 한 sector가 고장나 포인터가 유실되면 많은 부분을 잃게되는 신뢰성 문제도 존재.
단점개선방법: 단위를 block이 아닌 여러개 블록으로 구성된 cluster단위로 저장.
Indexed Allocation
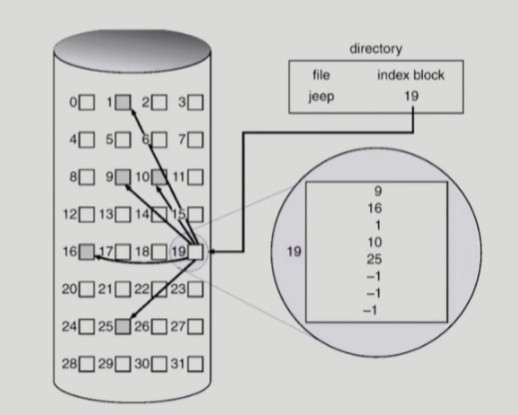
한 블록에 하나의 파일에 대한 index들을 모두 저장하는 방식(테이블블록처럼). 랜덤접근이 가능하고 외부단편화도 발생하지 않지만 파일이 작으면 위치를 저장하는 블록 공간의 낭비가 생길 수 있고 혹은 너무 큰 파일의경우 하나의 블록으로 파일 인덱스들을 모두 저장하기에 부족할 수도 있다.
단점개선방법 : multilevel index : index를 여러 레벨로 구성,outer index에는 file block number가 아닌 index block number를, inner (index) blocks는 각자 가지고있는 파일 블록 주소를 넘겨준다. 페이징때처럼 2중 참조 문제가 발생하나 캐싱으로 어느정도 해결가능. 인덱스 블록을 메모리에 keep.
FileSystem Implementation
Data structure for file system
- block : 정보를 담는 디스크의 한 물리공간. 저장단위.(일반적으로 512b), 하나 이상의 sector로 이루어진다. 디스크와 메모리 사이에 데이터 전송 실행 시 이 블록을 최소 단위로 사용한다.
- Disk상 구조(unix/linux)
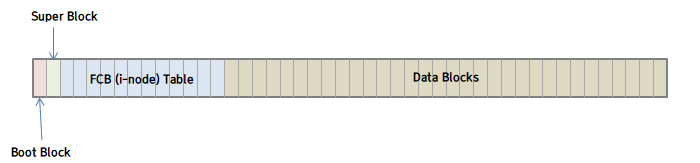
디스크는 Partition / Volumne이라는 독립적인 공간들로 나누어서 사용되며, 한 볼륨은 아래와 같이 구성되어있다. - 디스크에 존재하는 정보들
- Boot Control Block
disk에 존재, 시스템이 OS를 부팅하기 위해 필요한 정보 저장. 각 디스크 볼륨(partition)의 첫번째블록에위치한다. - Volume control block(super block)
파티션마다 존재하며 별도 파일 시스템에 대한 정보이다. - Directory structure
디렉토리들 메타데이터(파일이름..파일관리하기위한정보) file control block number등.. - FCB (파일 컨트롤 블록)
파일에 대한 정보 포함하고있으며, 리눅스에서는 i-node라고도 함. 가장 중요하게는 데이터 블록에 대한 포인터들을 가진다.(permission,dates,owner,size,location..) - Data block : 실제 데이터를 저장하는 역할.
- Boot Control Block
- File Control Block
파일에 대한 제어를 수행할 수 있는 블록.- file pointer : 현재 파일 offset
- file open count : 해당 파일 오픈한 프로세스수
- disk location : 파일이 저장된 disk 위치
- access right : 접근권한
file operation
create,write,read,fseek,delete,truncate
-
파일 저장(write)
사용자가 create()함수와 같은 파일 생성 명령어를 실행시키면 운영체제는 FCB table중에서 비어있는 하나의 블록을 골라 FCB(i-node)를 만들어주고, FCB에 만들고자 하는 파일들의 정보를 입력해준다. 그런 다음 파일 저장에 필요한 만큼 Data block을 할당받고, 해당 data block 번호를 FCB에 저장한다. 이후 OS가 디렉토리업데이트. -
파일 열기(open)
커널에 있는 system-wide-open-file table에 원하는 파일의 FCB가 있는지 찾아보고, 존재한다면 FCB에 대한 인덱스값을 per-process-open-file-table로 가져와 추가시켜준다. 존재하지 않는다면 디렉토리구조에서 검색해 FCB테이블에서 원하는 FCB를 찾아 각 테이블들에 차레로 등록(system/process) 후 인덱스를 반환해준다.
System-wide-open과 per-process-open 테이블 차이는 전체 시스템에서 열려있는 파일들에 대한 FCB를 저장하는 테이블이냐 프로세스가 열고있는 파일 목록에 대한 테이블이냐 차이.
정리하면, 파일 입출력은 파일에 대한 정보를 읽어서 table형태로 관리. entry를 메모리에 불러오고 유지한다.
- open()
File Control Block(FCB)를 Open file table에 저장.
FCB가 메모리에 없다면 FCB를 읽기위해 DISK I/O를 수행하고, 아니라면 read,write,seek를 효과적으로 수행가능. - close()
FCB를 open-file-table에서 제거.
등을 저장한다.
-
Open-file table
열려있는 파일 정보를 포함한다. 파일위치,attribute들을 메모리에 유지한다.

-
메모리에 존재하는 정보들
- in-memory mount table
: mount된 각각의 volume 정보,현재 mount된 file system의 정보. 부팅 시 자동으로 mount,OS에서 파일시스템 사용 위해 필수) - in-memory directory structure
:최근에 접근한 directory structure를 메모리에 keep (빠른 접근 가능) - system-wide open-file table
:열려있는 파일들의 FCB 사본과 기타 정보 포함 - per-process open file table
:system-wide open-file table에 있는 entry에 대한 포인터와 기타 정보 포함
- in-memory mount table
Free space management
-
bitmap 방식
비어있으면 0, 비어있지 않으면 1로 표시.
부가적 공간(bitmap mask)필요로하며 연속적인 공간을 찾는데 효과적이다. -
Linked list : 모든 free block들을 링크로 연결한다. 연속적인 공간 찾기가 어렵지만 공간의 낭비는 없다
-
Grouping : linked list를 변형. 비어있는 블록들 중 하나의 블록이 n개의 비어있는 블록의 포인터를 저장. 저장된 블록 중 마지막 블록이 다음 n개의 블록의 포인터를 저장할 블록에 대한 인덱스를 가진다.
Directory 구현
- 선형 리스트 : filename,file meta의 리스트. 디렉토리 파일을 찾기위해서는 선형탐색(O(N))이 필요하다.
- 해시 테이블 : 선형리스트 + 해싱, 해시 테이블은 file name을 list의 index로 바꾸어준다. 탐색시간이 O(1), 해시 충돌이 발생할 수 있음.

VFS : virtual file system
서로 다른 다양한 파일시스템에 대해 동일한 system call 인터페이스(API)를 통해 접근할 수 있게 해주는 OS layer. R/W/Open 시 실제 file system api를 이용하지 않고 VFS Interface를 사용하여 filesystem에 맞춰 자동 변환해줌.
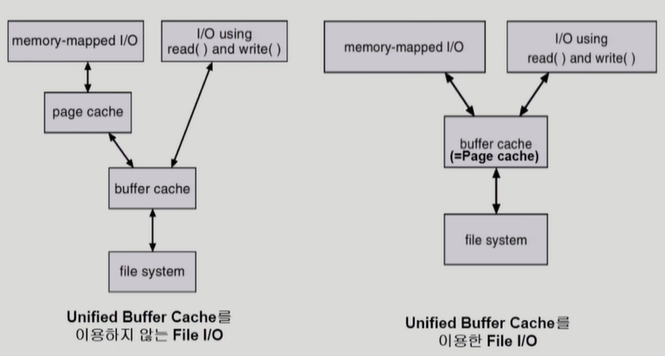
통합 버퍼 캐시
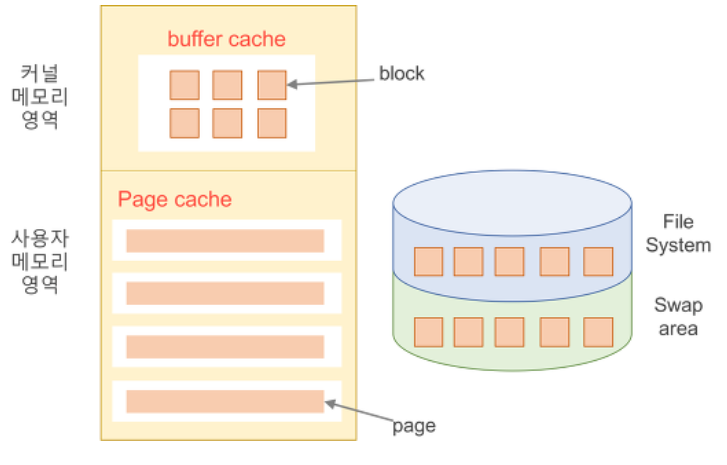
- Memory Mapped I/O
파일의 일부를 가상메모리에 매핑. 매핑한 영역에 대한 메모리 접근 연산은 파일 입출력을 수행하게한다.
가상 메모리에 올라온 영역=파일 이므로 시스템 콜 없이 I/O작업이 가능하며, 페이지캐시를 참조할 필요가 없다. read()메서드를 사용하면 요청마다 운영체제의 중재를 받고, 페이지 캐시 내용을 복사해야한다. - Page Cache
페이지 캐시는 가상 메모리의 페이징 시스템에서 사용하는 페이지 프레임을 캐싱의 관점에서 설명하는 용어인데, Memory Mapped I/O를 쓰는 경우 파일의 I/O에서도 페이지 캐시를 사용한다. - Buffer Cache
파일 시스템을 통한 I/O연산은 메모리의 특정 영역인 버퍼 캐시를 사용함. 한번 읽어온 블록에 대한 후속요청시, 버퍼 캐시에서 즉시 전달한다. 모든 프로세스가 사용하며 교체알고리즘 필요하며, 최근 OS에서는 기존 버퍼 캐시가 페이지 캐시에 통합되었다.