CPU Scheduling
CPU Scheduling
single processor라면 한 순간에 하나의 프로세스만이 실행될 수 있으므로 multiprogram에서 각 프로그램(프로세스)들이 CPU이용을 상황에 맞게 할당방아야한다. 보통 ready queue에 들어간 순서대로 실행하는데, 이를 우선순위에 따라 다시 재정렬하는 방식이다. -> 할당 방식에 따라 context switching 횟수가 바뀌고, cpu 자원을 얼마나 효율적으로 사용하게 되는지 결정된다.
Scheduler
OS는 준비완료큐에 있는 Process들 중에서 하나를 선택해 실행하고, 이는 Short Term 스케줄러가 수행한다(CPU Scheduler)
복습)
- 장기 스케줄러(Long term) : 장기 스케줄러: job scheduler. 디스크(풀)에 대기중인 프로세스들 중에서 ready queue로 옮겨질 프로세스들을 선택(현대 OS는 가상메모리 덕분에 장기스케줄러 잘 사용하지 않음)
- 단기 스케줄러(Short term) : ready queue에 다음 cpu 실행될 프로세스를 선택
- 중기 스케줄러 : swapping - 메인 메모리에서 장기간 사용하지 않는 프로세스를 하드디스크(swap device)로 옮겨주고(swap-out) 나중에 프로세스가 다시 사용되려고 하면 하드디스크에서 해당 프로세스를 다시 메인메모리에 할당(swap-in).
- Dispatcher : CPU의 control을 단기 스케줄러가 선택한 프로세스에게 주는 모듈. = cpu control을 주는 일,context switching하는 일, 사용자모드로 전환하는 일.
-> 운영체제가 ready queue에 있는 어떤 프로세스를 dispatch할 것인가를 정하는 것이 프로세스 스케줄링이다. (프로세스를 processor(cpu)에 할당하는 것, 프로세스 상태를 ready-> running으로 만드는 것.)- dispatch latency : 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는 데까지 소요되는 시간(지연시간)
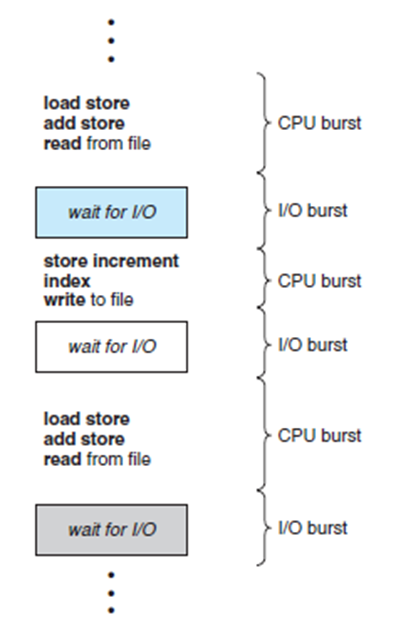
CPU-입출력 burst cycle
버스트(burst)란 특정 기준에 따라 한 단위로서 취급되는 연속된 신호나 데이터의 모임. 어떤 현상이 짧은 시간 집중적으로 일어나는 현상이나 주기억장치의 내용을 캐시기억장치에 블록단위로 한꺼번에 전송하는 것.
- CPU burst : cpu를 사용할 때. : 프로그램 수행 중 연속적으로 CPU사용 구간. 스케줄링 단위.
- I/O(입출력) burst : 입출력을 기다릴 때. 프로그램 수행 중 I/O작업이 끝날 때 까지 block되는 구간. 스케줄링 단위
process는 아래와 같이 new, ready, running, waiting, terminated의 상태를 갖는다.

ready에서 running으로는 dispatcher가 해주지만,
CPU스케줄링은 다음과 같은 4가지 상황에서만 생김.
(1) 프로세스 종료 시 :비선점
(2) running-> wait상태 전환될 때(ex- 입출력 요청이나 자식 프로세스가 종료되기를 기다리기 위해 wait 호출 시 , hw interrupt) : 비선점
(3) running-> ready로 전환될 때(ex- interrupt발생했거나 time slice 만료되거나 우선순위 더 큰 프로세스 들어올 때 = sw interrupt) : 선점
(4) waiting -> ready로 전환될 때(ex-입출력 종료 시) : 선점
Scheduling Criteria
(1) CPU 이용률 : 최대화 지향. CPU의 이용률을 높여야한다.
(2) 처리량 : 최대화 지향. 일정 시간동안 프로세스를 끝마친 수 (순서에영향)
(3) 총 처리시간(turnaround) : 최소화 지향. 프로세스 접수와 완료 사이 interval. 메모리 들어가기 위한 소비시간=ready queue에서 대기한 시간, CPU실행시간, I/O시간을 합한 시간
(4) 대기시간(wait) : 최소화 지향. 하나의 process가 ready queue에서 기다리는 시간.
(5) 응답시간(response) : 최소화 지향. ready queue에 들어가서 첫 반응을 보인 시간.
Preemptive(선점) / Non-Preemptive(비선점)
- Preemptive (선점) : 운영체제가 강제로 프로세스 사용권을 통제하는 방식, 특정 프로세스가 CPU 독점 불가능. 프로세스가 CPU를 할당받아 실행중에 있어도 다른 프로세스가 뺏어갈 수 있음. 각 프로세스 요청시 특정 요건들을 기준으로 자원을 분배하는 방식.
- 우선순위가 높은 프로세스 빠르게 처리 필요시 유용. 응답률 높아짐. but context switching비용 크다.
- Non-Preemptive (비선점) : 스스로 다음 프로세스에게 자리를 넘겨주는방식, 특정 프로세스가 CPU 독점 가능.이떤 프로세스가 CPU할당 이후 종료/입출력요구 발생해 자발적으로 중지될 때까지 계속 실행 보장. 공정. 선점 방식보다 스케줄러 호출 빈도 낮고, 문맥교환에 의한 오버헤드 적다. 일괄처리시스템에 적합.처리율떨어질수있는단점
- starvation 발생 가능. 특정 기준에 따라 먼저 할당한 프로세스가 먼저 처리됨.(짧은시간순으로 할당 시 오래 걸리는 프로세스는 계속 밀려 starvation생길수도)
Scheduling Algorithm
FCFS (First come, First Served)
- 비선점 스케줄링
- 먼저 들어온 프로세스 순서 대로 할당하는 방식.
수행시간이 큰 프로세스가 먼저 들어올 시 뒤에 들어온 프로세스들이 오래 기다려야하는 비효율 존재.(콘보이 효과)
- 낮은 overhead. disk load / I/O batch 프로세싱에 적절. 시분할 프로세스에 비적절.
- waiting ,reponse, turnaround time:
들어온 순서대로 P1,P2,P3라 할 때,

SJF (Shortest Job First)
- 비선점 스케줄링
- 수행시간이 짧은 프로세스 순서 대로 할당하는 방식.
- burst가 큰 프로세스는 starvation 발생.
- 비현실적 - 평 균 대기에 최적인 알고리즘이나 수행시간(next CPU request의 length) 정확히 알 수 없다. :이전 프로세스 기록을 보고 추측.) -> 현실적으로 CPU 점유(burst)시간을 측정하려면 오버헤드가 큰 작업으로 잘 사용되지 않는다.
- 다음CPU버스트예측(a: 0<=a<=1, 하이퍼파라미터, 임의의 가중치)
다음CPU버스트 예측값 = a * 이전실제CPU버스트값 +(1-a) * 이전CPU버스트예측값
- waiting ,reponse, turnaround time:
P1,P2,P3,P4 동시에 들어왔음 가정 할 때,

SRT (Shortest Remaining Time)
- 선점 스케줄링
- 남은 수행시간이 짧은 프로세스 순서 대로 할당하는 방식.
- SJF의 선점형 방식. 이 역시 burst time 예측이 어렵다.
위에서 1초 경과 시 P1은 burst time이 1초 수행 후 7이 남았고 P2는 방금 arrived해서 burst time이 4가 있는 상태로 context switching이 이루어져 P2에 CPU를 할당하게된다.
Priority
- 선점, 비선점 모두 가능
- 지정한 우선순위 대로 할당하는 방식.
우선 순위는 시간제한,메모리 요구량, 프로세스 중요성, 자원사용 등에 따라 기준 지정하며 SJF는 비선점으로 bursttime을 우선순위로, SRT는 선점으로 남아있는 실행시간을 우선순위로 하는 것.- starvation 혹은 무한봉쇄 나타날 수 있다(높은 우선순위만을 실행할 때 낮은 우선순위 실행 x)
- aging : 오래 대기한 프로세스의 우선순위를 높이는 방식으로 starvation 문제를 해결하곤 함.
- waiting ,reponse, turnaround time:
(낮은 정수 숫자가 높은 우선순위 : linux기준)
RR (Round-Robin)
- 기본적으로 선점 스케줄링
- Time Quantum 단위로 프로세스를 번갈아가며 할당한다.
- time sharing(시분할)에서 주로 사용하는 방식(실제 프로그램들에서 많이사용됨). 내부 동작은 ready queue가 원형(circular) 큐로 되어있어, CPU스케줄러는 readyqueue를 돌면서 한번에 한 프로세스에 quantum(기준시간)만큼 CPU를 할당해준다. context switch 일어날 시 실행주이던 프로세스는 ready queue 끝(tail)에 삽입된다.
- 높은 응답(response)속도. 반응성이 좋다.
- quantum이 짧으면 context swtiching 오버헤드가 크고, 너무 길면 convoy 현상이 발생한다(FCFS랑 다를바 없어짐) : 적절한 quantum설정 필요.
- waiting ,reponse, turnaround time: (time quantum=3)

MQ (Multilevel Queue)
- ready queue를 다수의 queue들로 분류, 각 queue마다 고유의 스케줄링 알고리즘을 따르게 하는 것. ready queue를 어떤 프로세스냐에 따라 나누어 각각 각각에 맞는 스케줄링 방식을 적용시켜주는 것.
- Foreground queue
: 사용자와 직접 상호작용하는 프로세스가 모인 queue. foreground는 빠르게 처리되어야한다. 그렇기 때문에 보통 라운드로빈 스케줄링 방식을 사용한다.- Background queue
: 백그라운드에서 돌아가는 프로세스가 모인 queue. background는 덜 빠르게 처리되어도 괜찮으며 응답 시간이 큰 의미가 없기 때문에 FCFS 등 적절한 스케줄링 방식을 사용.- process 성격에 따라 분류 / queue를 분리한 예제
각 프로세스 성격에 따라 우선순위를 부여한다. (system 프로세스 먼저 처리.-> 배치프로세스 나중에 처리.) 이후 분리된 각 프로세스 큐에서 해당 프로세스 성격에 맞는 다시 우선순위를 배정해준다. (사용자 프로세스는 RR방식으로 빠르게 응답해주며 배치는 들어온 순서대로 적용)
MLF (Multilevel feedback queue)
- 프로세스들이 큐 사이 이동하는 것을 허용한다. multilevel queue에 aging을 적용한 방식.
- 대부분의 운영체제는 multilevel-queue(multilevel feedback queue) 사용.
quantum이 8, 16내에 끝나지 않으면 FCFS로 처리하는 MLF예.
Thread Scheduling
- 운영체제에서 스케줄링되는 대상은 kernel-level thread이다.
동일한 프로세스에 속한 thread들 사이에서 cpu 경쟁 시 프로세스 경쟁범위(Process condition scope)
ex - userlevel thread를 kernel level thread로 매핑하는 경쟁.
local scheduling - 유저 레벨 스레드에서 프로세스 내부 라이브러리가 스레드 스케줄링을 담당해준다.
global scheduling - 커널 레벨에서 해당 스레드를 통제할 경우 단기 스케줄러가 스케줄링을 담당한다.
Multiple-Processor Scheduling
하나의 cpu를 이용이 아닌 여러 cpu 이용의 경우 어떻게 스케줄링되는가에 대한 내용.
- AMP : 비대칭 다중처리기 , 한 processor(cpu,core)만 시스템 자료구조에 접근하여 공유 필요성을 배제한다. 간단한 방법. 마스터처리기가 모든 스케줄링을 결정하며, I/O처리 , 시스템 활동 처리. 다른 처리기들은 사용자 코드를 수행한다.
- SMP : 대칭 다중처리기 , 각 처리기가 독자적 스케줄링. 가장 많이 사용되는 방식.
ready queue는 공용 준비 queue에 thread를 투입하거나, 각 프로세서마다 고유 thread queue에 넣는 두가지 방법이 있다.
전자는 RaceCondition을 고려해주어야한다.
후자는 Load Balancing을 잘 처리해주어야한다.- Load Balancing
처리기가 다중이므로 적절하게 잘 분배해주어 처리율을 높이는 것.
push:특정 태스크가 주기적으로 각 처리기 부하를 검사. 불균형 상태일 시 과부하의 처리기 태스크를 저부하 처리기에게 넘겨준다.
pull:놀고있는 처리기가 바쁜 처리기 쓰레드를 끌어온다(wait중인) - processor affinity(친화성) : smp(대칭 다중처리)일 시 프로세서간 이주(load balancing)을 피하는 현상. soft affinity는 웬만하면 스레드를 안옮기려하지만 이주가 가능하고, hard affinity는 스레드 입장에서 실행될 CPU집합을 명시한다.
thread 이주 시 실행중이던 core의 cache 혜택(빠른처리) 받지 못하므로. warm cache를 이용하려 하기 때문에 이런 이주 기피현상이 발생함.- cahce
cache는 main memory보다 용량은 작지만 주요 data를 모아 둔 작고 빠른 임시저장장치.
temporal locallity : 어떤 data에 접근했을 때 가까운 미래에도 그 data를 사용할 것이라 예상
spatial locallity : 어떤 data 접근했을 때 그 근처 data도 접근할 것이라 예상
-> for문과 배열 사용 경우가 많으므로 위 아이디어로 cache에 있는 정보를 이용한다.
CPU가 주기억장치에서 저장된 데이터를 읽어올 때, 자주 사용하는 데이터를 캐시 메모리에 저장한 뒤, 다음에 이용할 때 주기억장치가 아닌 캐시 메모리에서 먼저 가져오면서 속도를 향상시킨다.
- cahce
- Load Balancing
ReadTime CPU Scheduling
- realtime cpu sheduling : 프로세스의 deadline 고려하여 스케줄링하는 알고리즘.
- Realtime system : deadline개념 도입 system, deadline 내에 task를 수행하도록 하는 것 , 목표 : 실시간 성능 보장.(시간지나면성능감소)
- Soft-Realtime-System : 중요한 실시간 프로세스가 그렇지 않은 프로세스에 비해 우선권만 있을 뿐이다. deadline 지나도 어느정도 유효성이 존재.(처리시간지나면실패, 데드라인 지키는 것을 보장하진 않는다.)
- Hard-Realtime-System : Task는 deadline전까지 작업이 종료되어야한다.
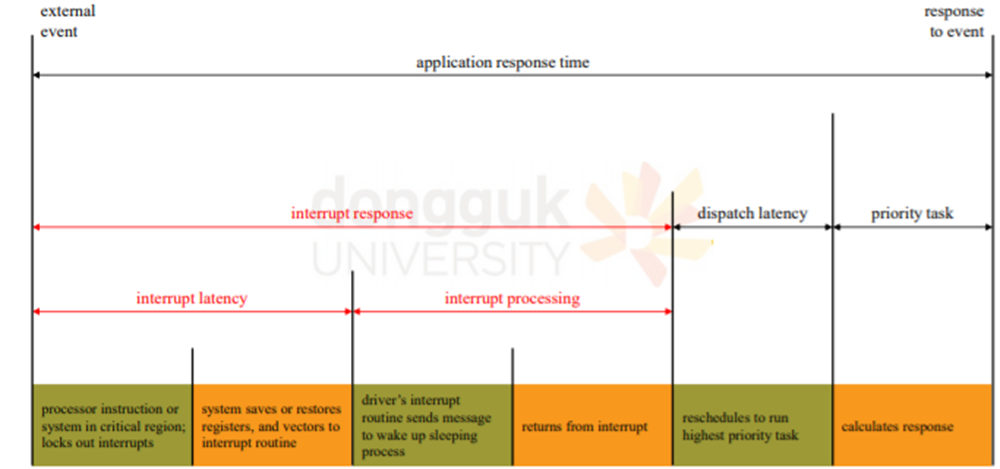
- Minimizing Event Latency해야함. (non-deterministic)->Event 중심특성, task가 발생하면 빠르게 처리해야한다.
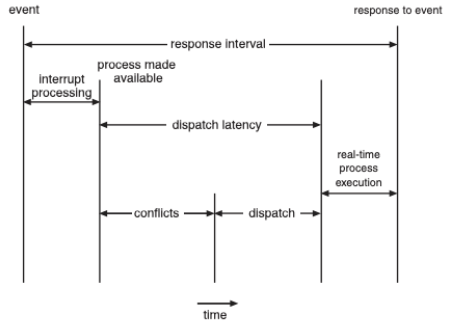
- event latency : 이벤트가 발생해서 그에 맞는 서비스가 수행될 때 까지 시간.
- Interrupt Latency : CPU에 interrupt 발생 시점부터 해당 인터럽트 처리 루틴이 시작하기 전까지의 시간.
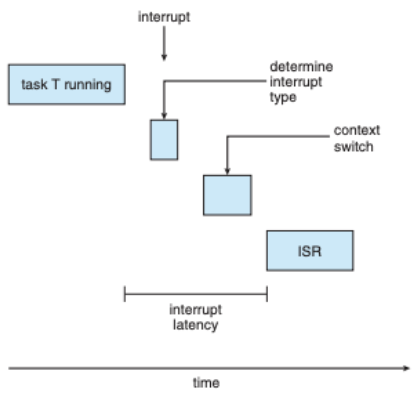
 언제 interrupt가 들어올지 모름.
언제 interrupt가 들어올지 모름. - Dispatch Latency : 스케줄링dispatcher가 프로세스를 block, 다른 프로세스 시작하게 하는데 걸리는 시간, conflicts가 생길 수 있음.
- Dispatch Latency : 스케줄링dispatcher가 프로세스를 block, 다른 프로세스 시작하게 하는데 걸리는 시간, conflicts가 생길 수 있음.
Rate-Monotonic scheduling
주기(Priority)에 따라 우선순위 결정. 주기가 짧을수록 우선순위가 높아지고 길면 낮은 우선순위(cpu를 더 자주 필요로 하는 태스크에게 높은 우선순위) : 선점.
Earliest-Deadline-First Scheduling(EDF)
Deadline이 빠를수록 우선순위는 높아지고, 높을수록 낮아지도록 우선순위 동적 부여.
