저번 포스트에서 다뤘던 인코딩 문제에 대해 더 공부하고 정리한 내용을 기록한다.
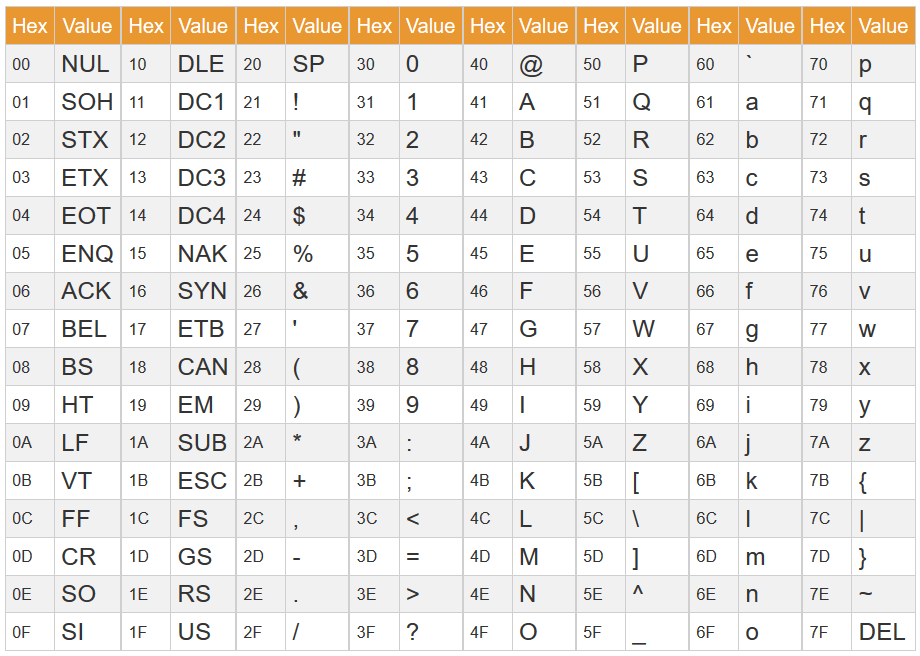
캐릭터셋 테이블(Character set table)
모니터라는 출력장치가 생기면서 컴퓨터의 연산 결과를 사람이 알아볼 수 있는 문자로 표현해야 했다.
컴퓨터는 전기신호(0, 1)로 연산하는 장치이기 때문에 이 신호를 각 문자에 대응시켜 문자를 표현했다.
이렇게 각 대응되는 관계를 적어놓은 것이 Character set table이다.
앞으로 전기신호는 알아보기 편하게 16진수로 나타내자.
인코딩(Encoding)
앞서 말했듯이 컴퓨터는 데이터를 이진으로 처리하고 저장한다.
따라서 사람이 알아보는 문자로 만들어진 어떤 데이터를 컴퓨터가 처리하고 저장하기위해서는 이진형식으로 변환되어야 한다.
그 반대 과정도 마찬가지다.
이렇게 캐릭터셋 테이블을 참고하여 각 형태로 변환하는 것을 인코딩이라 한다.
(A → B 로 가는 과정을 인코딩이라 한다면 B → A 로 가는 과정은 디코딩이라 한다.)
아스키코드(ASCII)
ASCII(American Standard Code for Information Interchange)는 문자를 표현하는 대표적 방식이다.
미국에서 만들어진만큼 영어와 숫자, 특수기호만으로 구성된 테이블을 가진다.
표현할 문자가 많지 않기 때문에 1byte만 사용한다.
7bit(128가지 표현)에 문자를 할당하고 1bit는 패리티비트로 사용된다.
컴퓨터가 보급되면서 많은 나라에서 컴퓨터를 사용하기 시작했고,
각 나라별 언어를 표현하기 위해 아스키코드에 각 나라별 언어를 추가(128~255)하여 사용하게 됐다.
그에따라 무수히 많은 각 나라별 ASCII 테이블이 만들어졌고,
서로 다른 테이블을 사용하는 시스템끼리는 문자가 이상하게 보이는(흔히 깨진다고 표현하는) 문제가 발생한다.
정리
지금까지의 내용을 예시로 정리해보자.
다음과 같은 내용이 담긴 파일이 있다고 가정하자.
48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21이 파일을 ASCII 인코딩을 사용하여 열어보면,
각 16진수가 ASCII 캐릭터셋 테이블에따라 문자로 표현된다.
Hello, World!유니코드(Unicode)
앞서 말했던 아스키코드의 문제를 해결하기 위해 유니코드가 등장했다.
유니코드는 흩어져있던 각 나라의 문자를 하나의 테이블로 통합했다.
테이블의 크기가 커짐에 따라 문자 한 글자를 표현하기 위해 사용되는 바이트 수도 증가한다.
이에 자원을 효율적으로 사용하기 위해 다양한 인코딩 방식이 존재한다.
오늘날 가장 많이 사용하는 유니코드 인코딩 방식은 UTF-8이다.
UCS-2
UCS-2 인코딩 방식은 2byte로 유니코드 문자를 표현한다.
한 문자를 표현하는 고정 길이 방식으로 2byte 이상의 유니코드 문자는 표현하지 못한다.
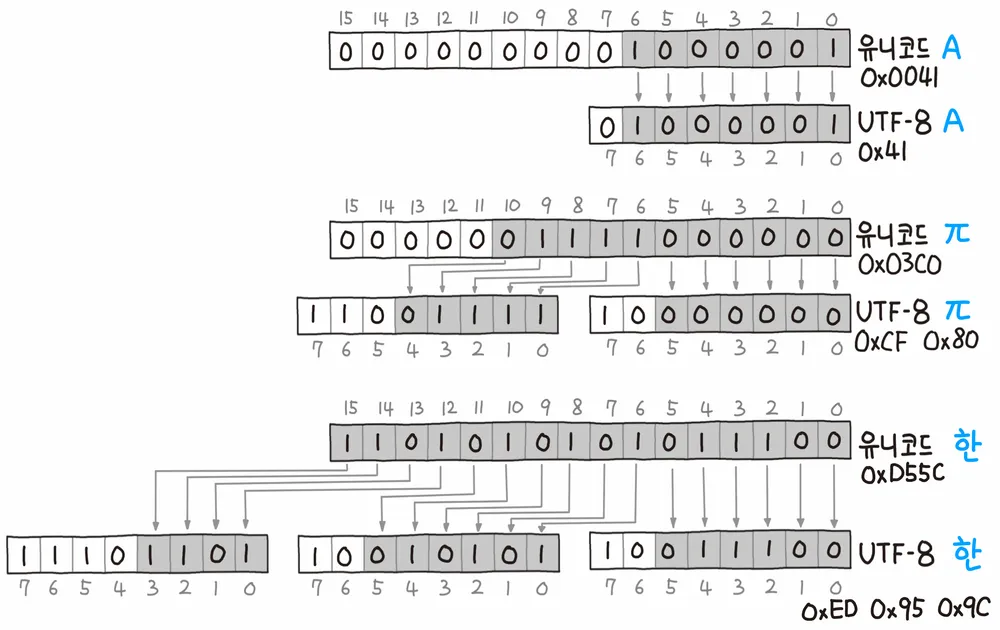
UTF-8
UTF-8 인코딩 방식은 가변 길이 방식이다.
모든 문자를 같은 크기로 처리하지 않고 테이블의 문자 위치에 따라 크기를 다르게 사용한다.
7bit(아스키코드 범위) 내에 있는 문자는 1byte만 사용해서 문자를 표현한다.
제일 왼쪽 1bit는 0으로 고정하여 1byte만 사용함을 알린다.
7bit 이후부터 11bit 범위까지는 2byte를 사용해서 문자를 표현한다.
첫 번째 바이트에서 110을 붙여 2byte가 사용됨을 알린다.
다음 바이트 앞에 10을 붙여 이어짐을 알린다.
같은 방법으로 바이트를 늘려 확장할 수 있다.
정규화(Normalization)
유니코드로 한글을 표현할 떄 대표적으로 두 가지 정규화 방식을 사용한다.
NFC(Normalization Form Composition)
리눅스나 윈도우 계열은 완성형이라고 불리는 NFC 방식을 사용한다.
한글 한 글자는 3byte로 표현한다.
즉, 키보드로 ㅎ(E3 85 8E) + ㅏ(E3 85 8F) + ㄴ(E3 84 B4)를 입력하면 한(ED 95 9C)이라는 문자로 표현된다.
NFD(Normalization Form DeComposition)
반면 맥에서는 조합형이라 불리는 NFC 방식을 사용한다.
우리 눈에는 완성형과 똑같이 보이지만 초성, 중성, 종성 각 문자가 그대로 살아있다.
즉, 완성형과 같이 키보드로 ㅎ(E3 85 8E) + ㅏ(E3 85 8F) + ㄴ(E3 84 B4)를 입력하면
우리 눈에는 한으로 보이지만 실제 바이트는 E1 84 92 E1 85 A1 E1 86 AB가 된다.
URL Encoding
앞선 포스트에서 다뤘던 URL 인코딩을 한 마디로 설명하자면,
URL은 ASCII만 사용할 수 있기 때문에 URL에 사용된 유니코드는 ASCII로 표현할 수 있도록 인코딩이 필요하다.
여기서 한글을 인코딩할 경우 완성형, 조합형 각각 아래와 같이 표현된다.
- 완성형:
한(%ED%95%9C) - 조합형:
한(%E1%84%92%E1%85%A1%E1%86%AB)
웹 서버에 리소스를 요청할 경우 위의 두 가지를 다르게 보기 때문에 정규화 방식을 통일 시켜줄 필요가 있다.
참고
