✅백준 문제 정답률 높은 순으로 정렬하기
1)취지
그리디 문제들을 풀기위해 여기저기 구글링을 하며 찾아보다가
백준 온라인 저지에 그리디 문제만 모아둔 페이지를 발견했다. (야호!) 링크
그리고 프로그래머스, 백준, leetcode 등 각기 다른 사이트에서 찾은 문제들을 편리하게 관리하기 위하여 notion에 정리 해두기로했다 (다람쥐가 도토리 보관하듯이!🥜🐹 아직은 안 푼 문제가 수두룩하다.)
막상 적으려하니 이왕이면 쉬운 난이도부터 차츰 문제를 푸는것이 좋겠다는 생각이 들어,
웹 개발 종합반에서 배운 크롤링을 활용해 볼겸 높은 정답률 순으로 정리해보기로 했다.
2)설명
해당 사이트에 들어가보면 링크 그리디 문제들이 정답률과 관계 없이 쭉 나열 되어있다. 이 문제들을 높은 정답률 순으로 소팅해 console창에 출력해보았다.
2.1. 준비사항
-우선 크롤링을 하기위해 bf4와 requests 라이브러리를 설치했다.
-bs4는 웹사이트에서 데이터를 크롤링 하기 위해 사용하고, requests는 api를 받기 위해 활용 된다.
-설치가 되었다면 설치된 라이브러리를 import하는 코드 적어준다.
import requests
from bs4 import BeautifulSoup-함수를 하나 만들어 request 준비를 한다.
우리는 함수명으로 sorting_title로 만들어보자.
get 할 URL https://www.acmicpc.net/workbook/view/4380 도 잘 적어주자.
이렇게!
def sorting_title():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.acmicpc.net/workbook/view/4380', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
3)기술설명
1.크롤링할 데이터 경로 찾기
오른쪽 마우스를 클릭하여 검사를 누르면! devTool페이지가 뜨는데
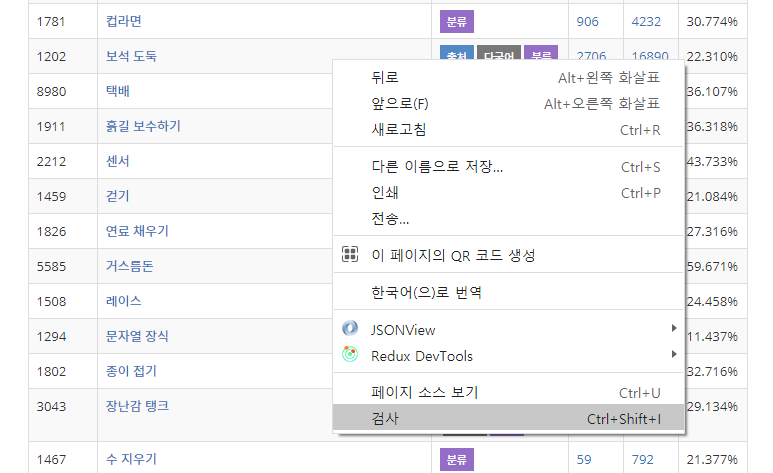
여기서 한행을 감싸고 있는 tr을 찾아 해당 위치에서 오른쪽 마우스를 클릭하여 copy select해준다.
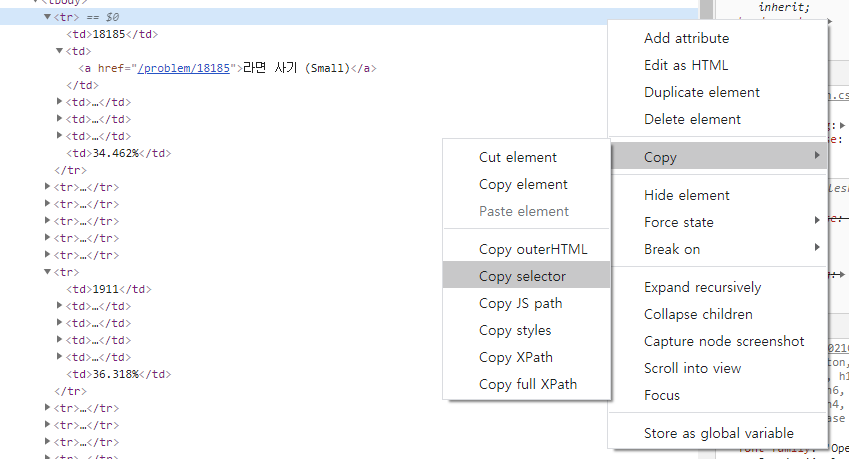
그럼 body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr:nth-child(1) 이 경로가 선택 될텐데, 이는 아래 이미지를 뜻한다.

위 경로를 다시 살펴보면 경로의 마지막인 tr:nth-child(1)의 숫자가 바뀌며 각각의 문제를 가리키는 것을 알 수 있다.
(tr:nth-child(2)는 두번째 줄에 위치한 '깊콘이 넘처흘러'라는 문제가 있는 행인 2행을 가리킴)
우리는 for문을 돌려 값을 반복적으로 받아올 것이므로 nth-child(n)을 제외한 공통된 경로 (body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr:)를 trs = soup.select('') 소괄호 안에 넣어준다.
이렇게!
trs = soup.select('body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr')
2.한 행을 찾았으니 이제 for문을 돌려 우리가 필요한 값을 받아와보자.
우리는 문제 목록에서 각 문제의 '제목과, 정답률'이 필요하므로

다시 devTool을 켜 해당 값이 위치한 태그에서 copy-select를 진행한다.
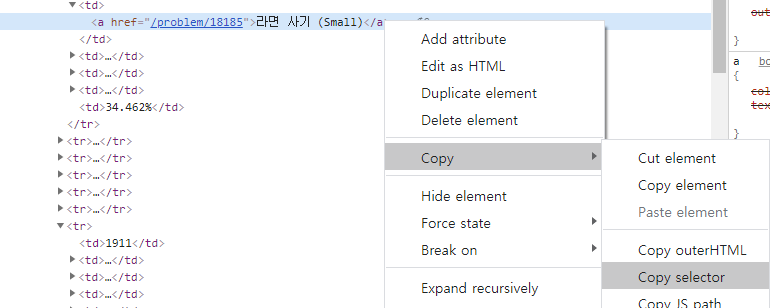
그 결과,
제목인 라면사기 텍스트가 있는 태그는
body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr:nth-child(1) > td:nth-child(2) > a
정답률인 34.462% 텍스트가 있는 태그는
body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr:nth-child(1) > td:nth-child(6)
경로가 선택됨을 알 수 있다.
이미 위에서 trs라는 변수에 공통된 경로는 담아 줬으므로, 각 행마다 다른 경로만 새로운 변수에 넣어 관리한다.
이렇게!
title = tr.select_one('td:nth-child(2) > a').text
level = tr.select_one('td:nth-child(6)').text
이 상태에서 title과 level의 type은 str 문자열이다.
3.받아온 정답률인 level의 크기를 비교하기 위한 작업을 한다.
1.우선 strip('%')로 '%'문자는 제거해준다.
2.그 후 float()로 형변환 해 숫자형으로 만들어준다.
3.완성 된 값을 num이라는 변수에 담아준다.
이렇게!
num = float(level.strip('%'))
이제 값의 대소 비교를 할 수 있게 되었다.
이제 한 행의 제목 title과, 정답률을 의미하는 실수형 값 level을 하나의 리스트로 만들어 list_num이라는 리스트에 넣어준다.(그 전에 sorting_title 함수내에 list_num = list()로 리스트 변수 생성해주기!)
이렇게!
list_num.append([title,num])
그럼 for문을 돌며 list_num에는 이와 같이 [['제목1',30.2],['제목2',70.544], ...] 값이 들어갈 것이다.
거의 다 완성 되었다!
값이 큰 순으로 정렬하기 위해서는
level 값끼리 비교해야하므로 2차원 리스트 list_num에서 [i][1] 번째 값들이 필요하다.
그래서 [0]번째 제목이 아닌 [1]번째 값 level을 불러다가 값 정렬을 해준다.
이렇게!
list_num.sort(key=lambda x:x[1])
자, 이렇게 하면 오름차순으로 값이 정렬이 되는것을 볼 수 있다.
이제 이 값들을 reverse()를 이용해 뒤집어 주면 된다.
이렇게!
list_num.reverse()
4.이제 그 값을 출력해주기만 하면 된다.
이렇게!
for i in list_num:
print(i)
완성 된 함수를 호출해 본 결과
sorting_title()
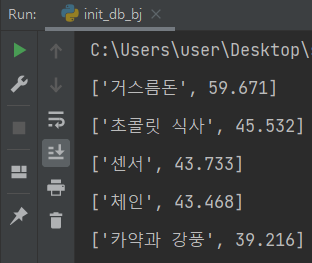
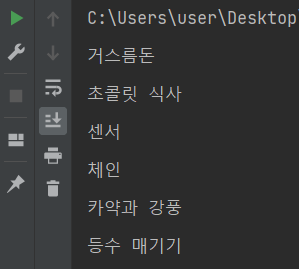
위와 같이 정답률이 높은 순으로 출력되는 것을 확인할 수 있다.
우리는 이중에서도 제목만 필요하므로
for문을 이렇게 바꿔
for i in list_num:
print(i[0])실행해주면 끝!
4)어려웠던 점 극복 방법
for문을 돌려 list_num 2차원 리스트에서 제목들만 뽑아 출력하려하는데
for i in list_num:
print(list_num[i][0]) 이렇게 for문을 돌리니 'TypeError: list indices must be integers or slices, not list'에러 발생했다. (해석 해보니 리스트의 인덱스는 문자열이 아니라 정수여야한다.라는)
이유를 찾아보니 for문을 돌며 i가 의미하는건 리스트의 인덱스가 아니라 원소이기 때문이었다.
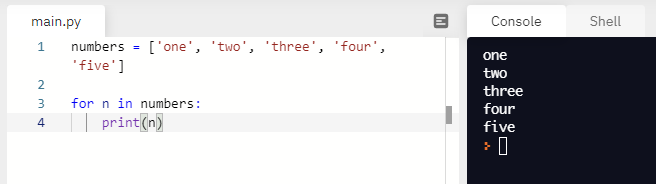
cf.n을 출력해보니 인덱스가 아니라, 리스트의 원소가 출력 되는 것을 볼 수 있다.
for i in list_num:
print(i[0])이렇게 수정해서 실행하니 잘 출력이 된다.
어렵지 않은 for문 활용인데, 아직은 파이썬이 익숙하지 않은 것 같다.
익숙해질 수 있도록 철저히 학습하자.╰(°▽°)╯
5)후기
웹 개발 강의에서 배운것을 실제로 활용해보며 익히니 매우 유익한 시간이었다. 그래서인지 이 포스트는 더욱 공들여 작성하게 되었다.
지금은 몇개 안되는 데이터를 정렬했지만, 이 코드가 몇백 몇천개의 데이터를 정렬할 때에도 사용할 수 있을 거라는 생각에 큰 보람도 느꼈다.
강의를 듣고 따라할 때는 쉽게 했던 내용을, 직접 코드 짜보니 실수도 하고 헤매기도 하였는데,
다시한번 복습을 철저히해서 다양하게 응용해 봐야겠다는 생각이 들었다.
앞으로 좀 더 많은 데이터를 활용해 웹에 출력하는 프로젝트를 진행해봐야겠다.
그리고 그 프로젝트 결과물도 잘 정리해서 포스팅 하도록 하자!
6)전체코드
import requests
from bs4 import BeautifulSoup
def sorting_title():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.acmicpc.net/workbook/view/4380', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('body > div.wrapper > div.container.content > div.row > div:nth-child(3) > div > table > tbody > tr')
list_num = list()
urls = []
for tr in trs:
title = tr.select_one('td:nth-child(2) > a').text
level = tr.select_one('td:nth-child(6)').text
num = float(level.strip('%'))
list_num.append([title,num])
list_num.sort(key=lambda x:x[1])
list_num.reverse()
for i in list_num:
print(i[0])
#!!!cf. print(list_num[i][0]) 이렇게 하면, 'TypeError' 발생
### 실행하기
sorting_title()
결과물
🟡🟢🟠마무리🟡🟢🟠
귀한 결과는 notion에 정리해 적어두었다.
문제 목록이 필요한 분은 위 링크에 접속해 복제하여 사용해도 된다.
🌻이제 문제 풀 일만 남았다!!! 아자아자!!!!!!
