관계형 DB는 데이터 관리를 하기위해 정규화 과정을 거치는데 이 데이터들을 합친 결과를 얻고 싶을 때 조인을 사용한다.
조인이란 두 개이상의 테이블을 하나의 집합으로 만드는 연산이다.
3개의 테이블을 하나의 집합으로 만든다면
A, B를 먼저 조인하고 그 결과와 C를 조인하는 과정을 거친다.
이런 테이블을 합치는 과정을
관계형에서는 Join 이라하며,
비관계형에서는 LookUp 이라한다.
비관계형의 LookUp 쿼리는 Join 연산보다 성능이 떨어지기 때문에
(성능이 떨어지거나 지원을 하지 않는다. 조인 없이 효율적으로 쿼리 할수 있도록 설계 됨)
관계형에서의 Join만 다뤄보도록 하겠다.
조인의 종류
📌Inner Join
내부 조인은 두 테이블 간에 교집합을 의미
(Inner를 생략하고 Join만 쓸 수 있다.)
SELECT * FROM TableA A
(INNER) JOIN TableB B ON
A.key = B.key✔ SELECT: 데이터 조회를 위한 명령문
✔ *: 만족하는 모든 요소
✔ FROM: 기본 테이블 지정
✔ TableA: 기본 테이블
✔ A: TaleA의 별칭
✔ INNER JOIN: 조인의 종류 중 하나
✔ TableB: 조인 될 테이블
✔ B: TableB의 별칭
✔ ON: 어떤 조건으로? (Join condition)
✔ A.Key = B.key : A의 키값과 B의 키값이 같은 조건다양한 연산자 가능( = , > , < , != )
null 값을 가지는 튜플(tuple)은 result table에 포함되지 못한다.
📌Outer Join
두 테이블에서 Join condition을 만족하지 않는 튜플들도 result table에 포함하는 join
(null 값을 가져도 포함될 수 있다.)
*다양한 연산자 가능( = , > , < , != )
예시) EMPLOYEE라는 TableA와 DEPARTMENT라는 TableB 가 있을때
A의 dept_id와 B의 id의 같은 값을 조인해보자
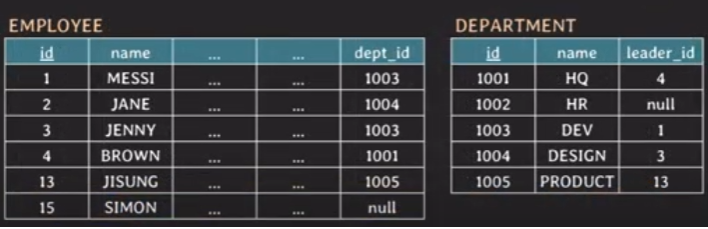
LEFT [OUTER] JOIN
SELECT * FROM TableA A
LEFT OUTER JOIN TableB B ON
A.key = B.key
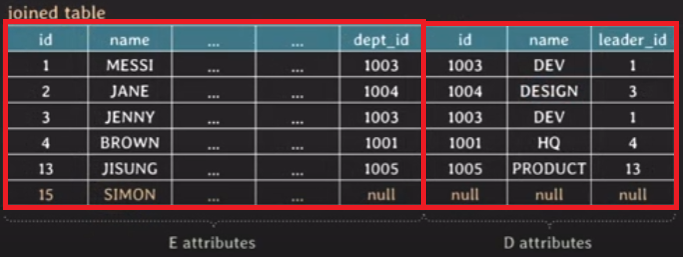
RIGHT [OUTER] JOIN
SELECT * FROM TableA A
RIGHT OUTER JOIN TableB B ON
A.key = B.key
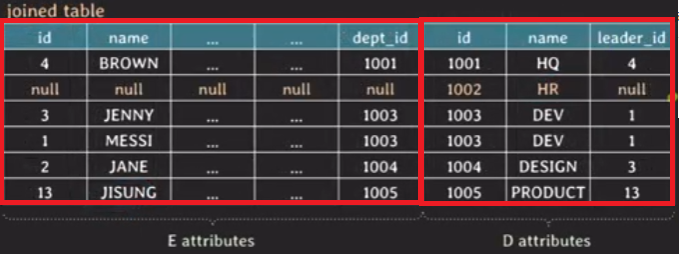
FULL [OUTER] JOIN
SELECT * FROM TableA A
FULL OUTER JOIN TableB B ON
A.key = B.key

📌Cross Join
중첩 for문 처럼 각각의 튜플을 모든 타 테이블의 튜플에 매칭 시키는 것
📌Natural Join
같은 속성을 합쳐서 join 하는 경우 (속성은 같은데 속성 값들이 다르다면 빈 테이블이 결과값이 된다.)
📌Self Join
table이 자기 자신에게 join하는 경우
=> 조인의 종류는 inner, outer, cross, natural, self 가 있다.
조인의 수행 원리
NLJ(Nested Loop Join)
☑ 중첩된 반복문과 유사한 방식으로 조인을 수행
☑ 반복문 외부에 있는 테이블을 선행 테이블 또는 외부테이블(Outer Table)이라 함
☑ 반복문 내부에 있는 테이블을 후행 테이블 또는 내부테이블(Inner Table)이라 함
☑ 선행 테이블의 조건을 만족하는 행을 추출하여 후행 테이블에 조인을 수행
☑ (조건을 만족하는 행이 적은 선행 테이블을 선택해야 전체 일량을 줄일 수 있다)
☑ 랜덤 방식으로 데이터를 엑세스

특징
✅절차적이며, 프로그래밍에서 FOR, WHILE문 과 같은 구조로 수행된다.
✅선행테이블은 풀스캔하므로, 선행테이블의 크기가 작을수록 유리하다
(So. 두 테이블의 크기 차이가 있는 경우, 유리하게 사용될 수 있는 방법임)
✅후행테이블에 대해서는 반드시 인덱스가 존재해야 NL 조인이 가능하다.
✅랜덤 액세스 방식으로 데이터를 읽는다.-> 처리 범위가 좁은 것이 유리하다.
이런 여러가지 특징을 종합할 때, NL 조인은 소량의 데이터를 주로 처리하거나 부분범위처리가 가능한 온라인 트랜잭션 환경에 적합한 조인 방식이라고 할 수 있다.
SMJ(Sort Merge Join)
☑ 조인 컬럼을 기준으로 데이터를 정렬하여 조인을 수행합니다.
☑ 후행 테이블의 적절한 인덱스가 없어도 가능
☑ 스캔 방식 ( <-> NL : 랜덤 엑세스 방식)
=> 대용량의 테이블들을 조인 가능
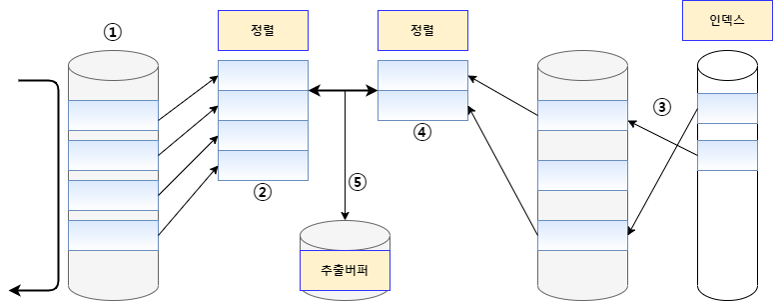
특징
✅인덱스가 없어도 가능한 조인법
✅조인할 테이블이 이미 정렬되어 있을 때 유리
✅조인 조건식이 등차(=)조건이 아닐 때도 가능
✅두 테이블의 사이즈가 비슷한경우에 유리하며, 사이즈 차이가 큰 경우에는 불리하고, 비효율적인 방법이다.
HASH JOIN
☑ Hash Join은 해싱 기법을 이용하여 조인을 수행합니다.
☑ 조인될 두 테이블 중 하나를 해시 테이블로 선정하여 (빌드 단계)
조인될 테이블의 조인 키 값을 Hash 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식입니다. (프로브 단계)
☑ HASH JOIN은 '=' 비교를 통한 조인에서만 사용될 수 있습니다.
☑ 주로 많은 양의 데이터를 조인해야 하는 경우에 주로 사용됩니다.
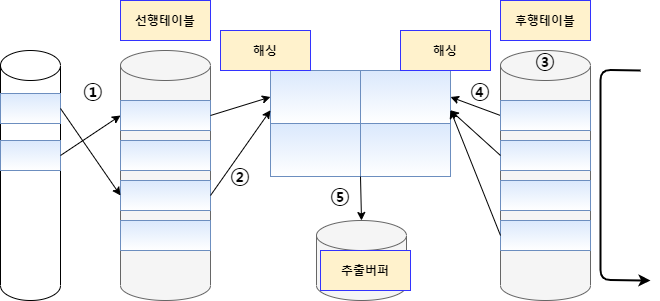
특징
✅ 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우데도 사용할 수 있는 기법이다.
✅ 해쉬 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 조인에서만 사용가능 합니다.
✅ 대용량 테이블에 유리
✅ 테이블을 한번씩만 읽게 되어 성능에 유리 ( <-> NLJ)
정리, 조인의 종류와 수행 원리(알고리즘) 매칭
-
INNER JOIN:
NLJ, Sort-Merge Join, Hash Join -
OUTER JOIN:
NLJ, Sort-Merge Join, Hash Join -
CROSS JOIN:
주로 NLJ로 수행되며, 모든 가능한 조합을 생성합니다. -
NATURAL JOIN:
INNER JOIN의 일종으로 NLJ, Sort-Merge Join, Hash Join을 사용합니다. -
SELF JOIN:
테이블을 두 번 조인하는 방식으로 NLJ, Sort-Merge Join, Hash Join을 사용할 수 있습니다.
각 조인 알고리즘은 특정 상황에 따라 최적화 될 수 있으며, 조인의 종류에 따라 선택 된다.
실행 계획을 보면 어떤 알고리즘이 쓰이고 있는지 알 수 있고
내가 생각한 최적화 방법이 아니라면
오라클 힌트를 사용하여 다른 알고리즘으로 유도할 수 있다.
(다시 실행 계획을 살펴 보고 알고리즘이 바뀌었는지 확인 할 수 있다.)
