Introduction
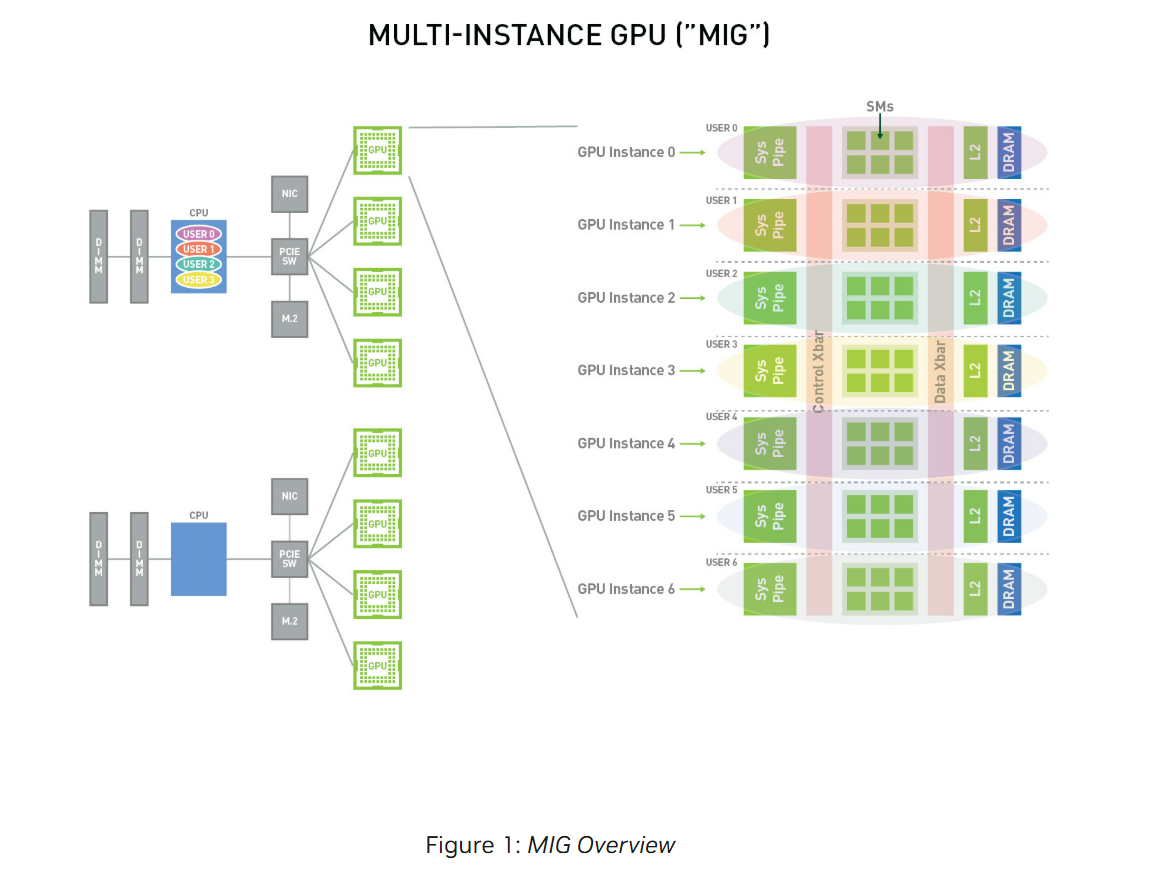
Multi-Instance GPU (MIG)는 GPU를 최대 7개의 독립적인 GPU instance로 안전하게 분할해 준다.
MIG가 없던 시절에는 GPU 전체를 단일 사용자가 독점하는 방식이었다. 이때 해당 사용자의 workload가 GPU를 100% 활용하지 않으면, 남은 resources(compute units, memory, cache & memory controllers, copy engines, etc.)는 그대로 idle 상태로 남게 된다.
반면, MIG는 GPU를 하드웨어 레벨에서 여러 instance로 분할하고, 각 instance에게 전용 SM·메모리·캐시·DRAM 대역폭을 보장한다. 또한 사용자는 자신에게 할당된 GPU instance 안에서 여러 workload를 병렬로 실행할 수 있어 이전보다 GPU utilization을 크게 향상시킬 수 있다.
그림에서는 하나의 GPU를 7개의 GPU instance로 분할한 상황이다. 각 instance에는 Sys Pipe(시스템 파이프라인, 사용자 요청이 GPU 내부 연산 유닛으로 전달되는 경로), SMs(실제 연산을 수행하는 코어 집합), L2/DRAM이 포함돼 있다. 즉 각 instance는 자신만의 SM, L2 cache, DRAM을 보장받아 다른 instance와는 완전히 격리되어 있는 것을 확인할 수 있다.
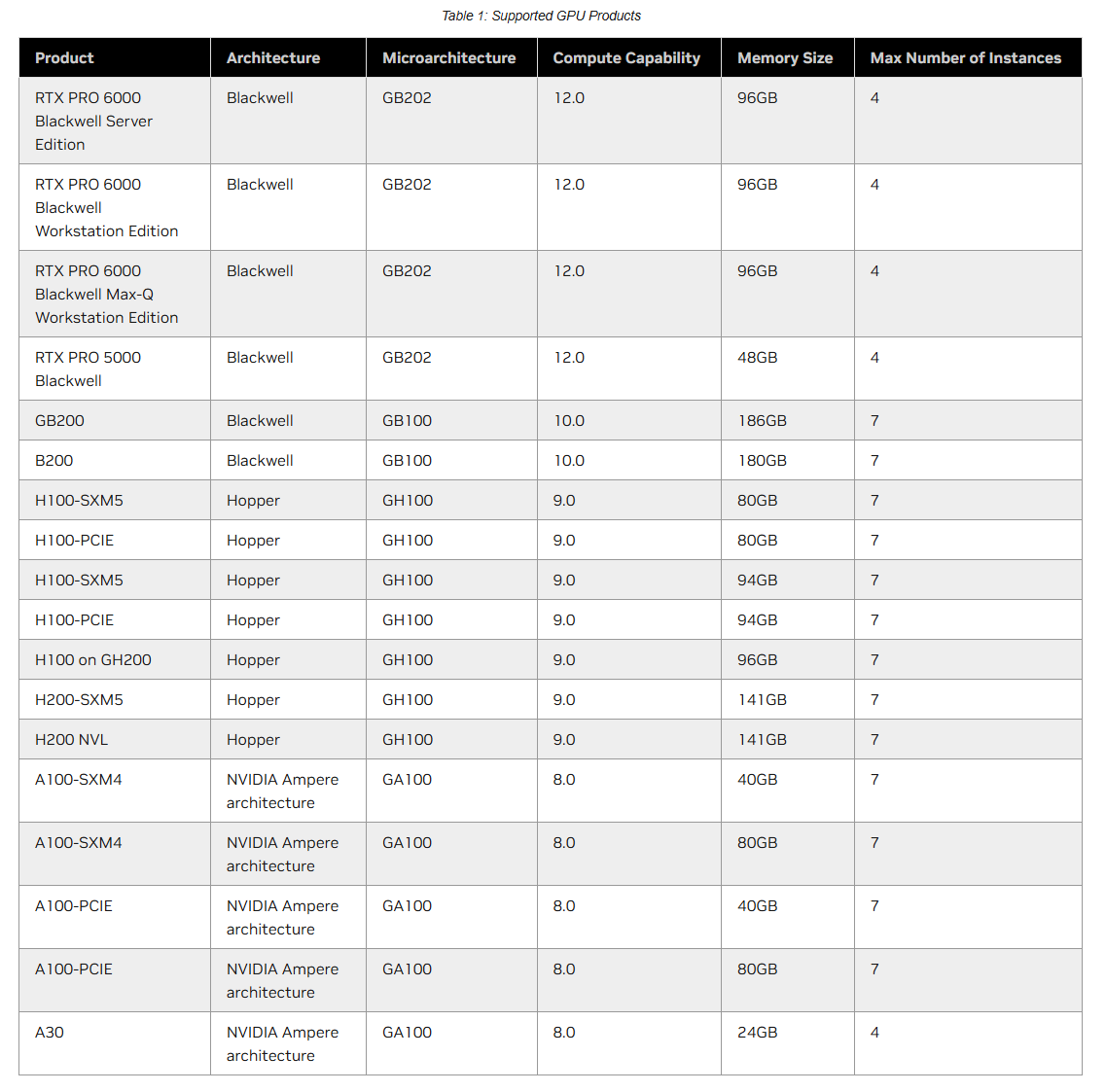
Supported GPUs
MIG는 A100, A30, A10 등 NVIDIA Ampere 세대부터 지원되는 GPU에서 사용할 수 있으며, 이는 Compute Capability 8.0 이상의 GPU를 의미한다.
번외로, compute capability는 NVIDIA가 정의한 GPU 아키텍처 세대와 기능을 나타내는 버전 번호로, GPU가 어떤 명령어 세트와 기능을 지원하고, CUDA 커널을 어떤 방식으로 컴파일할 수 있는지를 나타내는 기준이다. 버전을 표기할 땐, X.Y 형식으로 표기하는데, X는 GPU 아키텍처 세대, Y는 세부 변형(같은 세대 내 모델 차이)를 의미한다.
Concepts
Terminology
Streaming Multiprocessor
GPU의 핵심 연산 단위이자 CPU 코어 같은 존재이다. 실제 연산을 수행하고 thread를 스케줄링하며, MIG 환경에서는 slice 단위로 나뉘어 각 GI에 전용으로 할당된다.
GPU Context
GPU에서 실행되는 작업의 실행 환경이다. CPU에서 process가 실행되려면 독립된 주소 공간, 메모리 자원, 스케줄링이 필요했던 것처럼 GPU도 context 단위로 독립된 실행 환경, 메모리 공간을 갖는다.
GPU context의 특징으로는 다음 세 가지가 있다.
첫째, 한 context에서 문제가 발생해도 다른 context에는 영향이 없다. (fault isolation) 둘째, 각 GPU context는 다른 context와 독립적으로 스케줄링된다. 즉, 다른 context와 실행 큐를 공유하지 않고 각 context는 개별적으로 스케줄링 대상이 된다. 마지막으로, context마다 자신만의 독립적인 virtual address space가 존재한다. (Distinct Address Space) 즉, 같은 GI에 존재하는 context들은 하나의 physical memory를 공유하지만, 각 context는 자신만의 virtual address space를 갖는다.
GPU Engine
GPU에서 특정 종류의 작업을 담당하는 실행 유닛이다. 가장 흔히 사용되는 엔진은 Compute/Graphics Engine으로, compute instructions를 실행한다. 이 compute engine이 앞서 언급한 여러 SM을 사용해서 연산을 수행한다. 이 외에도 DMA를 수행하는 copy engine, 비디오 디코딩을 진행하는 NVDEC, 비디오 인코딩을 진행하는 NVENC 등이 존재한다. 각 engine은 서로 다른 GPU context의 작업을 동시에 실행할 수 있다. 예를 들어, compute engine에서는 context A의 작업을, copy engine에서는 context B의 작업을, NVENC에서는 context C의 작업을 수행할 수 있다.
GPU Memory Slice
memory와 이에 대응되는 memory controller, cache까지 모두 포함해서 GPU memory를 가장 작은 단위로 나눈 것을 GPU memory slice라고 한다. 이 GPU memory slice 1개의 capacity, bandwidth는 전체 GPU memory의 capacity, bandwidth의 약 1/8에 해당한다. 예를 들어 전체 memory 크기가 40GB이고, bandwidht가 1.5 TB/s인 A100의 memory slice는 크기가 5GB이고, bandwidht는 187.5 GB/s이다.
MIG에서는 GI마다 전용 memory slices를 할당하기 때문에 다른 사용자가 자신의 memory slices를 과도하게 쓰거나 bandwidth를 saturate 시켜도 다른 GI는 영향을 받지 않는다.
GPU SM Slice
GPU는 수십~수백 개의 SM을 가지고 있다. MIG는 물리 GPU를 여러 GI로 쪼개야 하는데, 이때 각 instance마다 SM을 전용으로 주어야 서로 다른 사용자의 workload간 간섭 없이 실행될 수 있다. 그래서 SM들을 일정 단위로 묶어 만든 최소 할당 단위가 SM slice이다.
예를 들어 A100-40GB는 SM 108개를 갖고 있는데, MIG에선 이를 7개의 SM slice로 나누어 SM slice 1개당 15~16개의 SM이 포함되게 한다.
하나의 SM slice 안에는 cuda core, tensor core, warp scheduler, l1/shared memory 등 SM resource가 포함돼 있다.
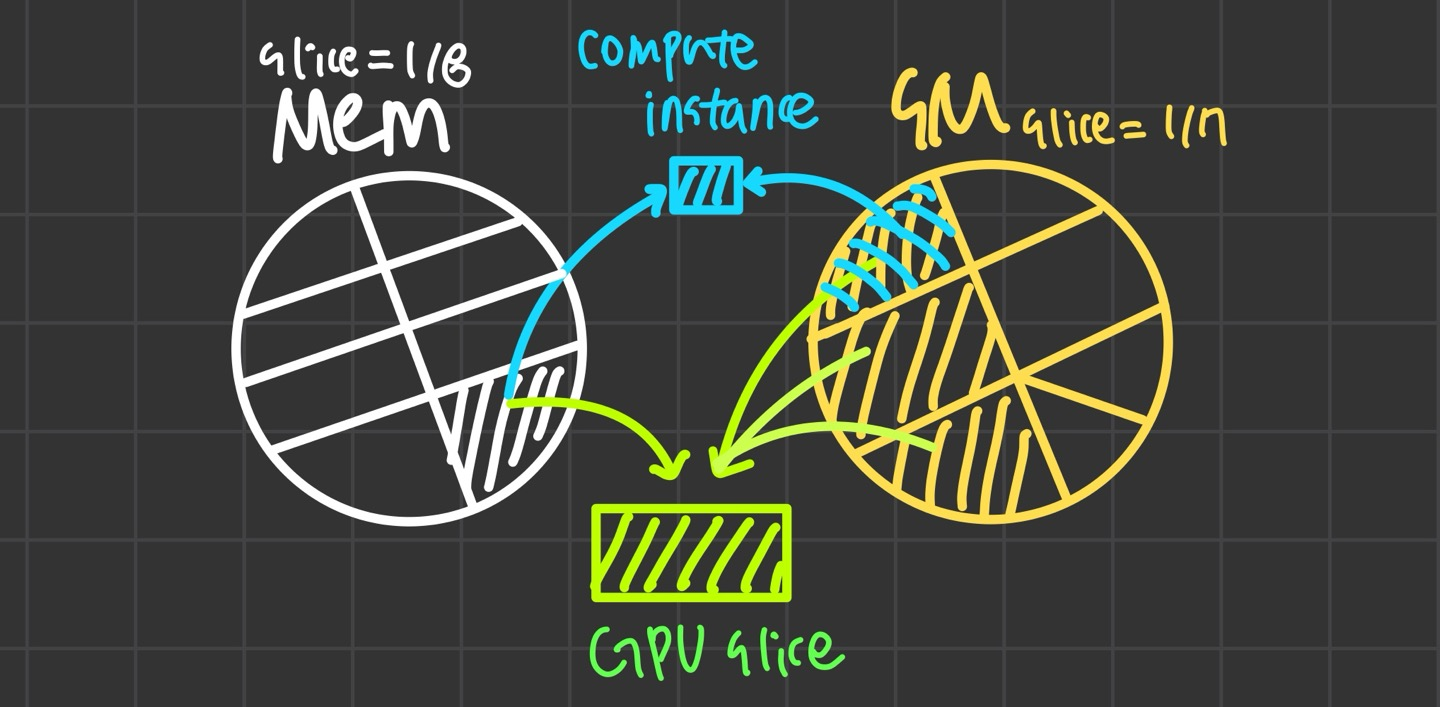
GPU Slice
GPU를 구성하는 최소 단위로 GPU memory slice 1개와 GPU SM slice 1개를 결합한 형태이다. 즉, A100 40GB 기준으로는,
GPU slice = memory slice 1개 + SM slice 1개
GPU memory slice 1개 = 전체 GPU memory의 1/8
GPU SM slice 1개 = 전체 SM 개수의 1/7
의 형태이다.
GPU Instance
GPU instance는 여러 GPU slice와 GPU engine의 조합으로 구성된다. 하나의 GPU instance 안에서는 모든 GPU memory slice와 GPU engine을 공유한다.
GPU instance는 memory QoS(Quality of Service)를 제공한다. 즉, 다른 사용자나 GI에 영향을 받지 않고 자신의 GI memory capacity와 bandwidth는 항상 보장되어 예측 가능한 성능을 제공한다.
Compute Instance
GPU instance는 더 작은 단위인 compute instance로 나눌 수 있다. compute instance는 GI 내부에서 SM slice 단위로 생성되는 논리 실행 단위이므로 SM 단위로만 격리되고, memory와 engine은 공유한다.
이런 느낌인 것 같다.
Partitioning
GPU Instance
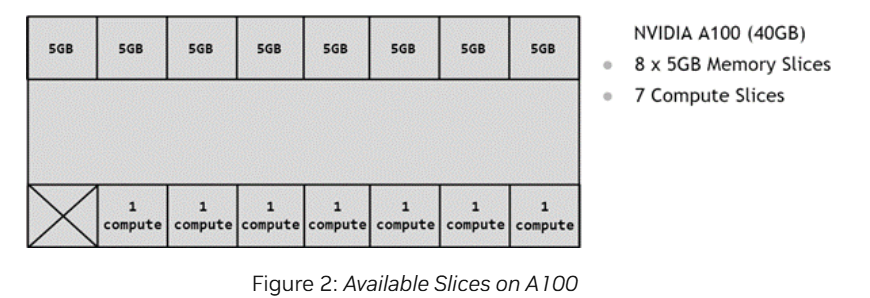
위에서 소개한 concept들을 이용해서 어떻게 GPU를 여러 partition으로 나누는지 알아볼 것이다. 예시로 들 GPU는 A100-40GB이다.
NVIDIA A100은 5GB memory slice 8개와 7개의 SM slice(=compute slice)로 이루어져 있다.
GPU를 MIG에서 쪼갤 때 임의로 SM 몇 개, 메모리 몇 GB 이렇게 직접 지정하는 게 아니라 NVIDIA에서 정해둔 profile 중 하나를 선택한다. 다음은 5GB memory slice를 1개의 compute slice로 구성된 1g.5gb GI profile이다.

아래는 5GB memory slice 4개와 1개의 compute slice로 구성된 4g.20gb GI profile이다.
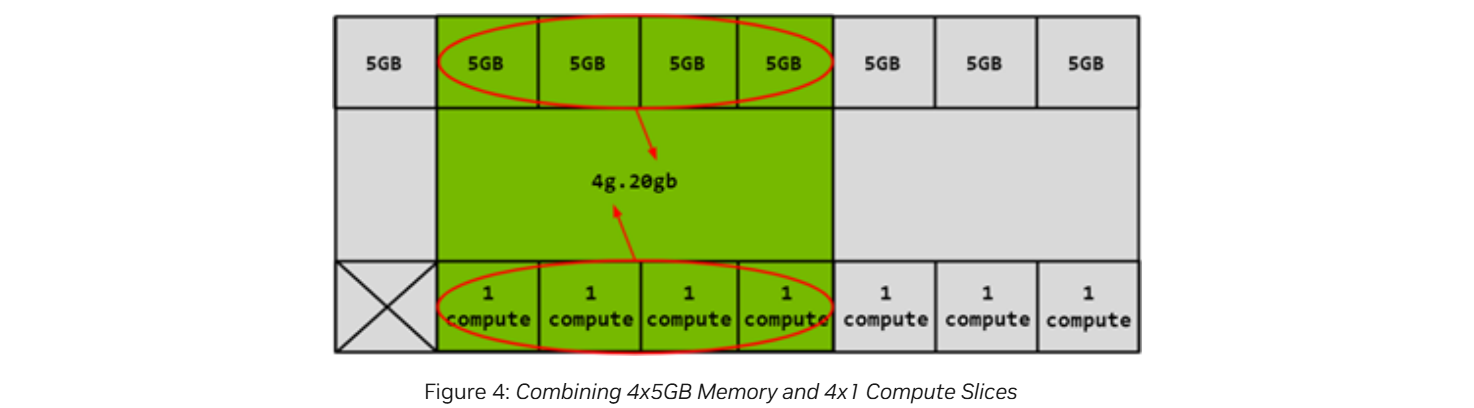
Compute Instance
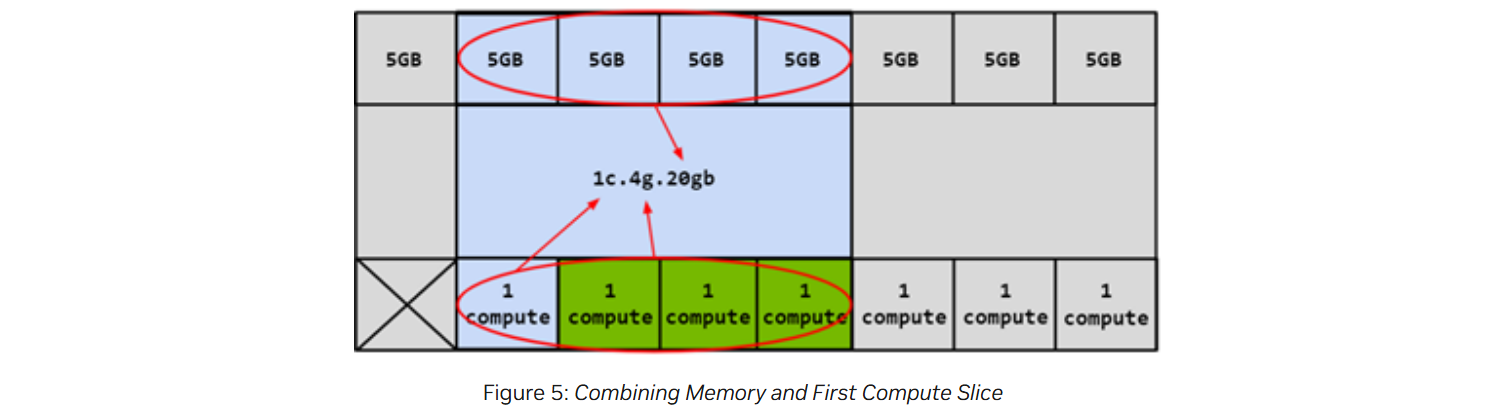
GI instance의 compute slice's'를 더 세분화하여 여러 개의 compute instance로 나눌 수 있다고 앞서 설명했다. 이때 각 CI는 GI의 engine과 memory는 공유하지만, SM은 전용으로 할당된다는 점을 잊지 말자.
4개의 compute slices가 있으므로 서로 다른 4개의 CIs를 만들 수 있는 상황이다. 다음은 첫 번째 compute slice만을 사용하는 CI를 만든 예시이다.
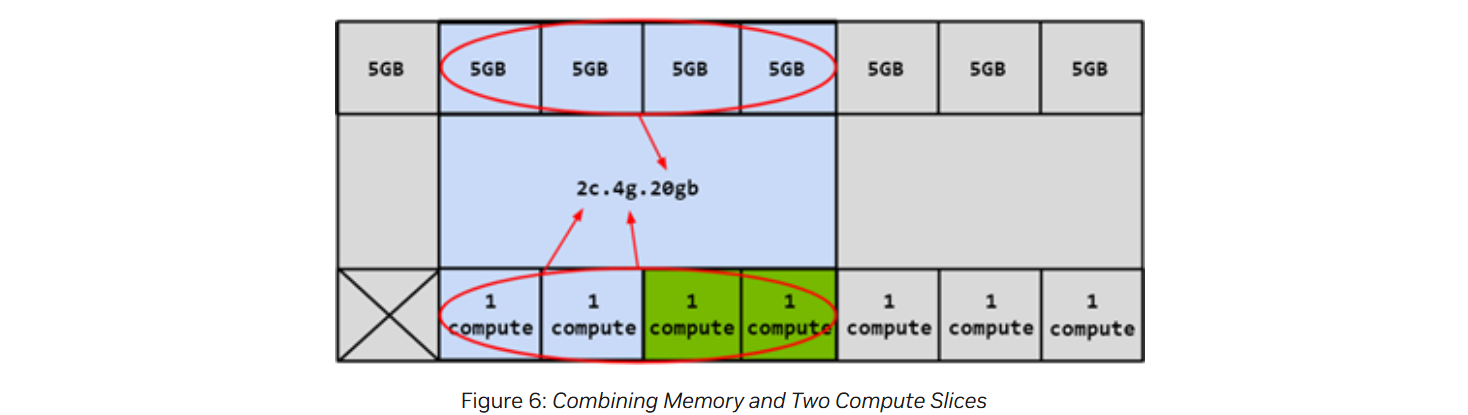
아래 그림은 4g.20gb GI에서 SM slice 2개를 각각 CI로 할당해 두 개의 CI를 생성한 그림이다.
Profile Placement
앞서 GPU를 쪼갤 때 임의로 쪼개는 것이 아니라 NVIDIA에서 지정한 Profile을 참고한다고 했다. NVIDIA driver APIs는 수많은 GPU instance profile을 제공한다. 따라서 user는 이러한 profile을 조합해 여러 개의 GPU instance을 생성할 수 있다.
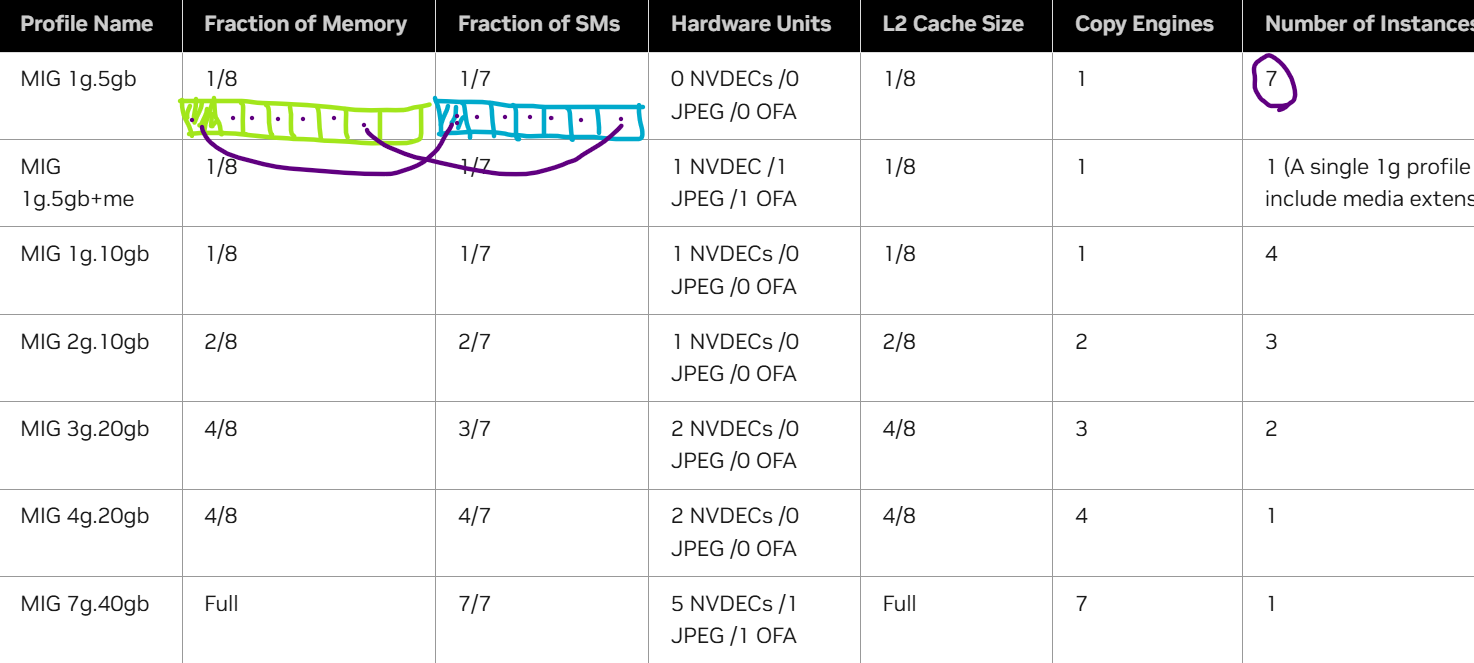
아래는 A100의 가능한 모든 GPU 인스턴스(GI) 조합이다.
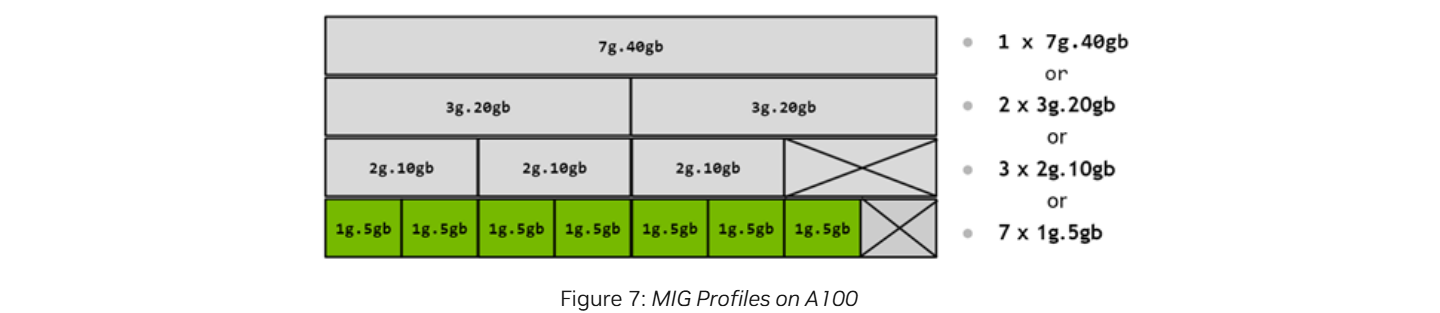
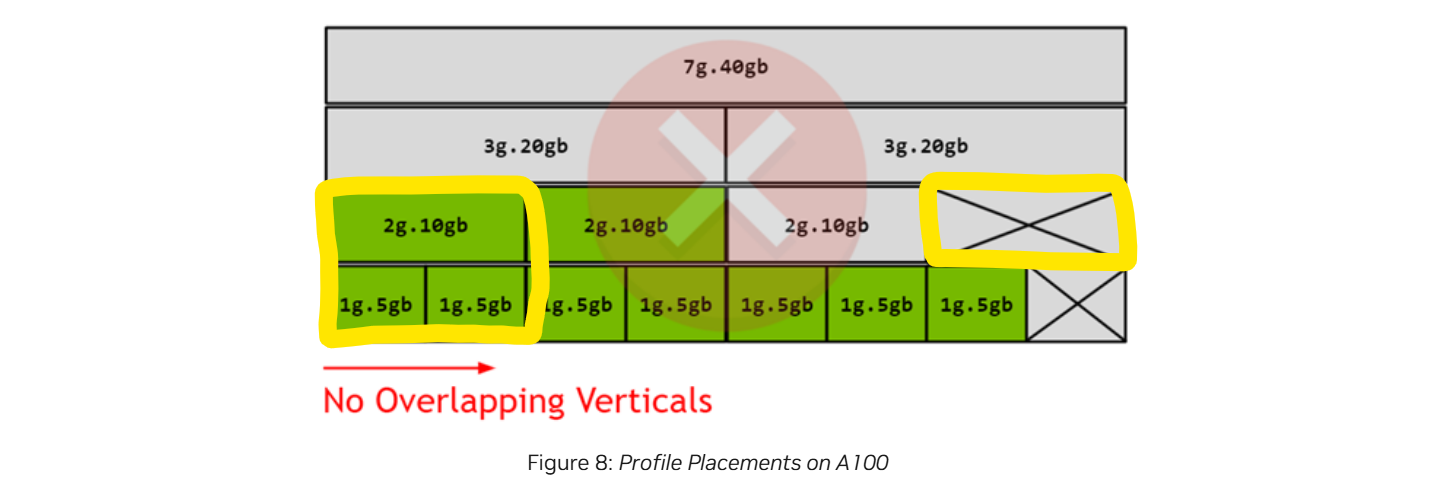
조합을 만들 때 세로 방향의 profile이 겹쳐서는 안 된다. 즉, 그림처럼 2g.10gb와 1g.5gb를 선택해선 안 된다. 이는 서로 다른 두 GI가 같은 memory slices와 SM slices를 공유한다는 것을 의미하기 때문이다.
더불어 그림에 보이는 것처럼 생성된 GI의 크기에 따라 fragmentation이 발생할 수 있다.
CUDA Concurrency Mechanisms
MIG는 CUDA application에 대해 전반적으로 transparent 하게 설계돼 있어서 기존 CUDA 코드나 프로그래밍 방식을 크게 바꿀 필요가 없다.
CUDA는 이미 작업을 병렬로 실행할 수 있는 여러 방법을 제공한다.
예를 들어, CUDA Streams를 사용하면, 하나의 프로세스 내 작업을 여러 stream을 통해 GPU에 병렬로 요청할 수 있다. 이 방식은 GPU가 여러 stream의 명령을 동시에 실행하거나 오버랩할 수 있다는 장점이 있다. 그러나 각 stream은 완전히 독립적이지 않아 동일한 리소스를 공유하므로 성능 간섭이 발생할 수 있으며, 하나의 stream에서 오류가 나면 전체 stream에 영향을 미친다는 단점이 있다.
MPS는 CUDA Multi-Process Service로, SM을 logical 하게 나누어 여러 process에게 할당함으로써 하나의 GPU를 동시에 공동으로 사용할 수 있게 해 준다. 이를 통해 SM 활용률을 높일 수 있다. 그러나, 한 process에서 메모리 접근이나 잘못된 커널 실행 등으로 인해 오류가 발생한다면 전체 process가 죽거나 GPU가 reset 된다는 문제가 있다. 더불어 각 process가 자신만의 virtual address space를 갖기 때문에 다른 process의 memory에는 접근하지 못하지만, memory controller나 memory bandwidth, l2 cache는 여전히 공유하는 구조이므로 process간 서로 간섭이 가능하고 QoS도 불안정해진다.
앞서 언급된 한계들을 극복하려고 나온 게 MIG다. MIG는 계속 언급했듯, SM + l2 cache + memory bandwidth를 물리적으로 쪼개서 격리시키므로 성능 간섭이 거의 없다.
이를 표로 정리하면 아래와 같다.
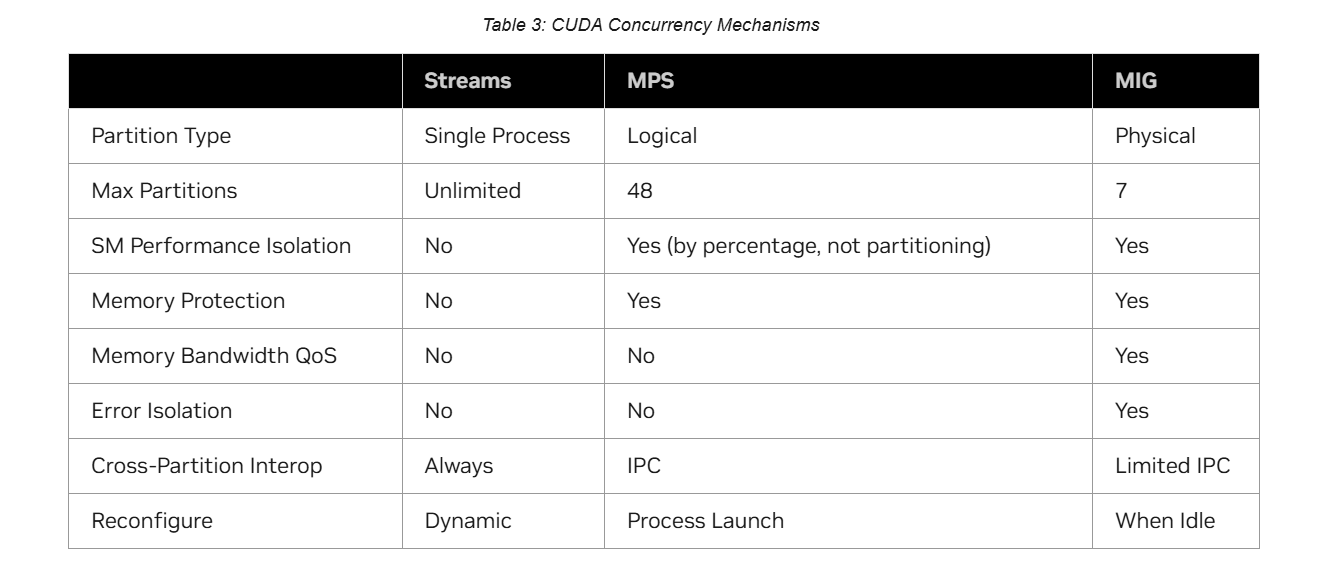
참고로 Cross-Partition Interop은 서로 다른 partition 간 data 공유나 통신 가능 여부를 나타낸다. Streams 방법은 한 process 내부에서 여러 stream을 만드는 것이므로 항상 가능하고, MPS는 IPC(Inter-Process Communication)를 필요로 하며, MIG는 같은 instance를 사용하는 process끼리만 IPC가 가능하다.
Reconfigure는 partition을 재구성할 수 있는 시점을 말한다. Streams 방법은 언제든 stream을 생성/삭제할 수 있고, MPS는 process가 시작할 때만 SM 할당 비율을 조정할 수 있으며, MIG는 GPU가 idle 상태일 때만 가능하다.
Deployment Considerations
MIG 기능을 사용하기 위해선 별도의 프로그램이나 소프트웨어를 따로 설치할 필요 없이, NVIDIA에서 제공하는 GPU 드라이버만 설치하면 된다.
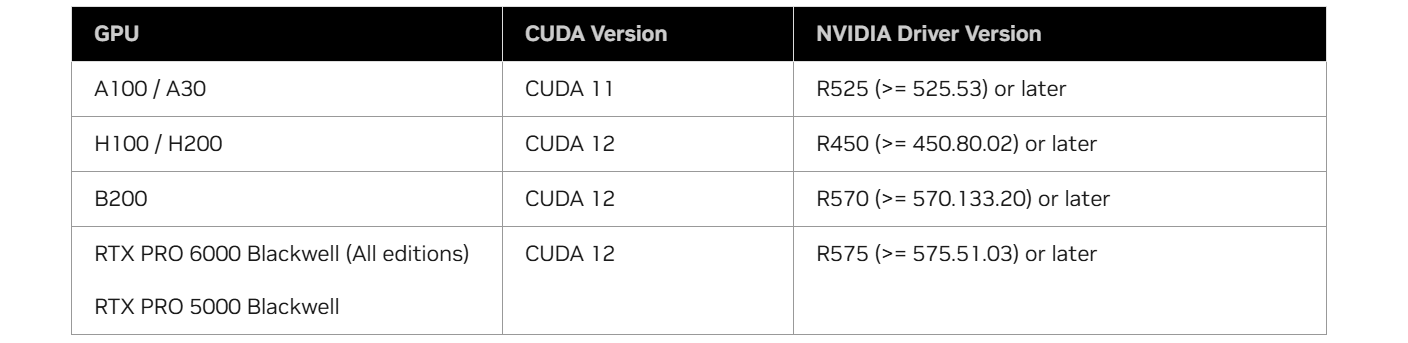
다음은 GPU 모델별로 MIG를 사용하기 위해 필요한 최소 CUDA 버전과 NVIDIA 드라이버 버전이다.
System Considerations
MIG는 CUDA가 공식적으로 지원하는 Linux 배포판에서만 사용할 수 있으며 최신 NVIDIA 데이터센터용 Linux 사용을 권장한다.
A100/A30 GPU에서 MIG 모드를 활성화하려면 GPU 리셋이 필요하다. GPU 리셋은 쉽게 말해서 GPU만 부분적으로 껐다 켜는 것이다. MIG 모드를 켜거나 끌 때는 GPU 내부의 하드웨어 파티셔닝 구조가 바뀌기 때문에 기존에 GPU를 사용하던 프로세스와 드라이버 상태를 모두 초기화해야 한다. 리셋이 진행되면 GPU에서 실행 중이던 모든 작업이 종료되고, 드라이버가 GPU를 다시 감지한 뒤 새로운 MIG 모드를 적용한다. 이 과정은 superuser 권한이 필요하다.
MIG를 켜기 전에는 GPU 드라이버를 통해 GPU에 연결돼 있는 상태인 백그라운드 서비스가 모두 꺼져 있어야 한다. 예를 들어 GPU 상태/성능/온도 같은 정보를 수집하는 DCGM 같은 서비스가 이에 해당된다. 이런 서비스가 켜져 있으면, GPU를 리셋하고 MIG 모드를 적용하려 할 때 GPU를 점유 중이라 모드 적용에 실패할 수 있다.
GPU를 한 번 MIG 모드로 전환하면, 이후에는 GPU instance를 자유롭게 만들거나 삭제할 수 있는 상태가 된다. 처음 MIG 모드로 전환할 때는 GPU 리셋이 필요하지만, 그 이후에 instance를 만들거나 지우는 작업은 GPU를 다시 끄거나 리셋할 필요 없이 바로 적용된다는 것이다. 또한, MIG 모드 설정은 GPU 단위(per-GPU)로 적용된다.
MIG 모드 설정은 사용자가 명시적으로 설정을 변경하지 않는 한 재부팅 후에도 유지된다.
Application Considerations
MIG 모드에선 그래픽 API(e.g. OpenGL, Vulkan, etc.)를 사용할 수 없다. (단, RTX Pro 6000 Blackwell GPUs의 경우, 일부 MIG profiles에서만 그래픽 기능을 지원한다.)
MIG 모드에서는 GPU 간 P2P(Peer-to-Peer) 통신이 지원되지 않는다. 즉, PCle 등 NVLink 등을 이용해 GPU끼리 직접 데이터를 주고받을 수 없다.
MIG 환경에 GPU는 먼저 GPU Instance로 크게 나뉘고 각 GI에선 CI가 생성될 수 있다고 하였다. CUDA application이 GPU를 사용할 때는 GI와 CI를 따로 구분하지 않고 CI를 각각 하나의 GPU처럼 인삭한다. 따라서 여러 CUDA application을 동시에 실행하면 각 application은 자신에게 할당된 CI를 독립적인 GPU처럼 사용하게 된다.
GI 간 IPC는 지원되지 않지만, 같은 GI 내의 CI 간 IPC는 지원이 가능하다. 즉, 서로 다른 GI에 있는 application끼리는 CUDA IPC로 메모리를 공유할 수 없지만, 같은 GI 안에서 서로 다른 CI를 사용하는 application끼리는 CUDA IPC를 사용할 수 있다.
(계속 헷갈려서 적는다. 일반적으로 IPC는 말 그대로 프로세스 간 소통을 의미한다. 파이프, 소켓, 공유 메모리, 메시지 큐 등 전통적인 IPC 방식이 여기에 속한다. 하지만 CUDA에서 말하는 IPC는 좁은 의미로 쓰인다. CUDA IPC는 프로세스 간 GPU 리소스 공유를 가능하게 해 주는 기능이다. 특히 GPU 메모리와 이벤트를 프로세스 간 공유할 수 있게 하는 게 핵심이다.)
MIG 모드에서도 GPU Instance 단위로는 RDMA를 활용할 수 있어 GPU 메모리를 네트워크 장치가 직접 접근하여 데이터 전송을 수행할 수 있다. CUDA application에겐 CI 단위로 할당이 되고, RDMA 지원 단위는 GI라서 헷갈릴 수 있다. application은 CI 단위로 동작하지만, CI의 메모리도 결국 GI의 physical memory 일부이므로, GI 단위로 RDMA가 활성화되면 CI memory 또한 RDMA 경로에 포함된다. 즉, RDMA는 GI 전체를 바라보지만, CI가 가진 메모리는 GI 메모리 안에 있으므로 CI 위에서 동작하는 app도 RDMA를 그대로 사용 가능하다.
MIG Device Names
MIG 디바이스 1개는 기본적으로 GPU Instance(GI) 1개 + Compute Instance(CI) 1개로 이루어져 있다.
MIG 디바이스 이름은 GI 기준으로 붙인다. 형식은 다음과 같다.
<GI의 compute slice 개수>g.<GI의 총 메모리 GB>gb

예를 들어 1g.5gb는 compute slice 1개 + 총 메모리 5GB를 의미하고, 2g.10gb는 compute slice 2개 + 총 메모리 10GB를 의미한다.
CI가 GI 전체를 차지하면 CI 크기는 이름에 굳이 표시하지 않는다. 예를 들어, 1g.5gb 디바이스는 compute slice가 하나인데 기본 조합이 GI + CI이므로 CI 하나가 GI 전체를 사용하고 있음을 바로 알 수 있다.
하나의 GPU Instance를 사용자 workload에 따라 여러 개의 Compute Instance로 세분화했을 경우, 세분화한 방식에 따라 MIG 디바이스 이름도 다르게 표시될 것이다. 아래의 표는 3g.20gb GI를 여러 CI로 나눴을 때 각각의 MIG 디바이스 이름이 어떻게 표시되는지를 예시로 보여준다.
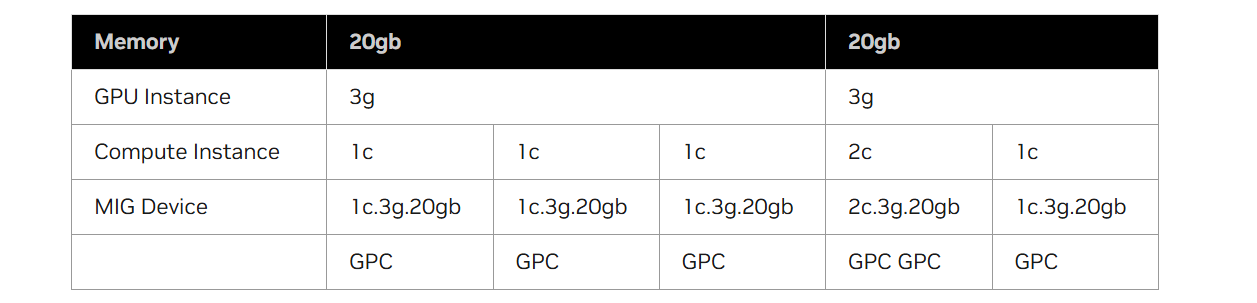
참고로 GPC(Graphics Processing Cluster)는 MIG에서 Compute Slice를 구성할 때 사용되는 실제 하드웨어 resource 단위이다. A100 기준으로는 compute slice 1개를 곧 GPC 1개라고 이해해도 무방하다.
Device Enumeration
A100 40GB GPU 1장에 MIG 모드를 켜고 1g.5gb CI 3개를 만든 상황을 가정해 보자.
/dev에 보이는 디바이스 파일들은 다음과 같을 것이다. /dev directory는 실제 디바이스에 접근하기 위한 디바이스 파일을 제공하는 곳이다.
$ ls -l /dev/nvidia*
crw-rw-rw- 1 root root 195, 0 Feb 1 12:00 nvidia0 # major num = 195(NVIDIA GPU), minor = 0
crw-rw-rw- 1 root root 195, 255 Feb 1 12:00 nvidiactl # 컨트롤 디바이스
crw-rw-rw- 1 root root 195, 254 Feb 1 12:00 nvidia-modeset
crw-rw-rw- 1 root root 506, 0 Feb 1 12:00 nvidia-cap0 # major num = 506(MIG 디바이스), minor = 0 → CI 0
crw-rw-rw- 1 root root 506, 1 Feb 1 12:00 nvidia-cap1 # major num = 506(MIG 디바이스), minor = 1 → CI 1
crw-rw-rw- 1 root root 506, 2 Feb 1 12:00 nvidia-cap2 # major num = 506(MIG 디바이스), minor = 2 → CI 2참고로, 리눅스에서 장치를 식별할 때는 major number와 minor number라는 두 가지 번호를 사용한다.
major number는 커널이 이 디바이스를 어떤 드라이버가 처리할지 식별하는 번호다. 프로세스가 /dev 밑의 디바이스 파일을 열면 커널은 그 파일의 major number를 확인하고, 이 번호에 등록된 드라이버를 찾아 I/O 요청을 전달한다. 즉, major number는 이 디바이스를 담당할 드라이버를 찾기 위한 식별 번호라고 이해하면 된다.
minor number는 같은 드라이버가 관리하는 여러 장치를 구분하기 위한 번호다. 예를 들어 NVIDIA GPU가 2장 있는 경우, 두 장 모두 major number는 동일하지만 각 GPU는 minor number가 달라 /dev/nvidia0와 /dev/nvidia1처럼 구분된다. 드라이버는 이 minor number를 통해 자신이 관리하는 여러 장치 중 어느 장치인지 식별한다.
/proc/driver/nvidia-caps/ 내용은 다음과 같이 나올 것이다. 이 경로에는 NVIDIA 드라이버의 내부 상태와 minor number mapping 정보 등을 보여주는 파일들이 존재한다.
$ ls -l /proc/driver/nvidia-caps/
-r--r--r-- 1 root root 0 Feb 1 12:00 mig-minors → 물리 GPU의 minor 번호 목록
-r--r--r-- 1 root root 0 Feb 1 12:00 nvlink-minors → MIG 디바이스(CI 단위) minor 번호 목록
-r--r--r-- 1 root root 0 Feb 1 12:00 sys-minors → NVLink 디바이스 minor 번호 목록
$ cat /proc/driver/nvidia-caps/sys-minors
0 # 물리 GPU 0번의 minor number
$ cat /proc/driver/nvidia-caps/mig-minors
0
1
2 # MIG 디바이스 3개의 minor number
$ cat /proc/driver/nvidia-caps/nvlink-minors
32
33
34 ... # NVLink 관련 디바이스 번호
별거 아닌 것 같은데 영 이해하기 어려웠다. 다시 간단히 정리해 보면, 원래였다면 GPU 1개에 major 번호 하나, minor 번호 하나만 부여하면 된다. 그러나 MIG 모드를 활성화 하면 GPU를 여러 MIG 디바이스(CI 단위)로 쪼개기 때문에, CUDA와 커널 입장에선 이제 GPU가 CI 개수만큼 존재하는 것처럼 보인다. 그래서 드라이버가 각 CI를 독립적인 장치처럼 여기고, minor number 또한 부여한 것이다. 더불어 얘네들의 minor number들을 관리하기 위한 파일들도 위에처럼 생겨난 것이다.
참고 자료: https://docs.nvidia.com/datacenter/tesla/mig-user-guide/#mig-device-names
