THE RED : Area Chair 이광무 교수의 Neural Fields & 3D 컴퓨터 비전 강의를 바탕으로 작성된 글입니다.
Point clouds
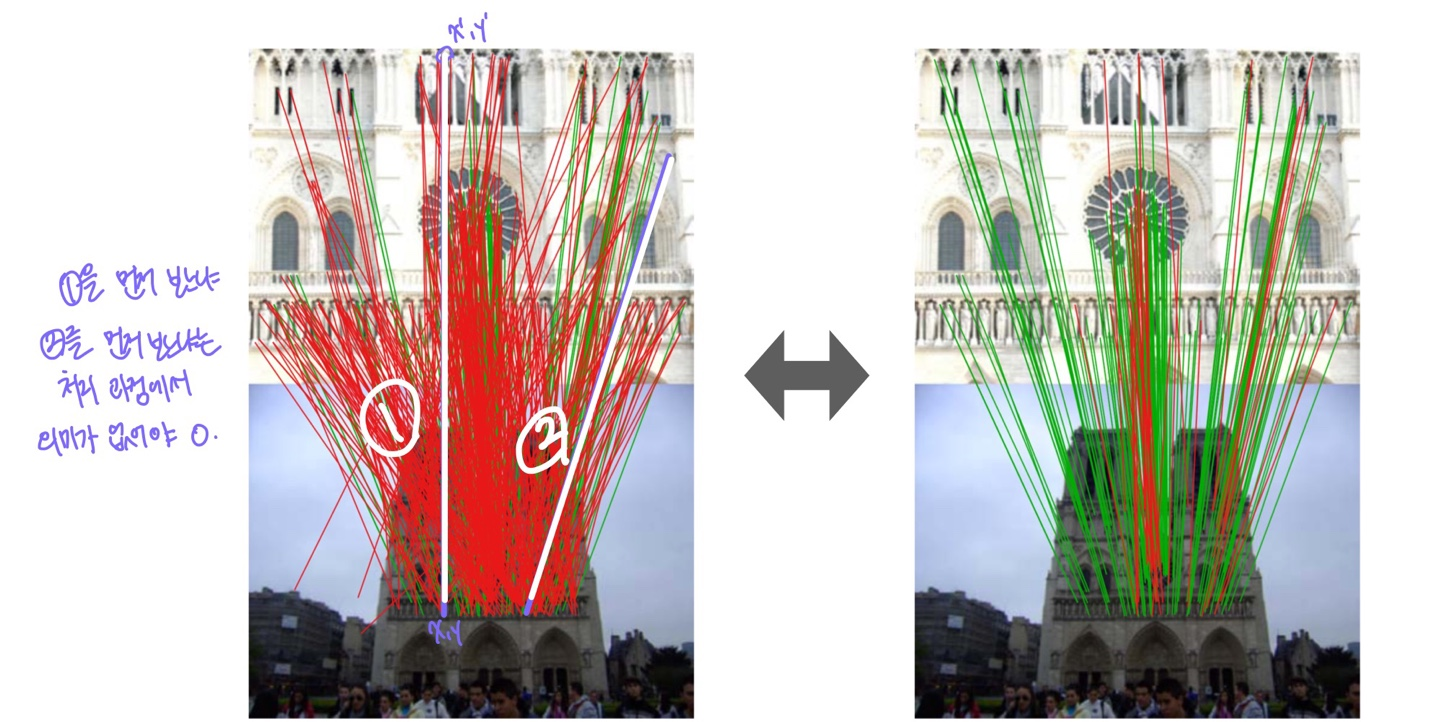
앞선 포스팅에서 Geometric Verification을 향상시키기 위한 딥 네트워크가 2018년 이전까지 등장하지 않았다고 설명한 바 있다. 이는 후보 correspondence(대응점 후보)가 갖는 독특한 특성 때문이다. 즉, 어떤 correspondence를 먼저 선택하든 결과가 항상 동일해야 하며, 순서에 의존해서는 안 된다. 이러한 제약이 딥 네트워크 설계에 어려움을 주었기 때문에, 해당 기술이 본격적으로 발전하기까지 시간이 걸렸다.
이런 data type을 point cloud data type이라고 한다. point cloud data type을 어떻게 처리하느냐가 최근 몇 년 사이에 크게 발전을 했지만 이전에는 어려움이 많았던 type이었다.
PointNet
One of the simpler ways to deal with point clouds
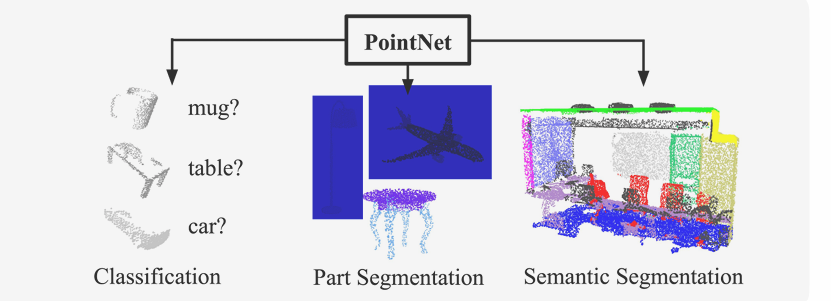
point clouds를 사용한 원조격의 아키텍처가 바로 pointnet이다. 해당 아키텍처는 point clouds가 주어졌을 때 Classification, Part Segmentation, Semantic Segmentation 등을 수행할 수 있다.
Main idea

PointNet의 핵심은 point cloud를 permutation-invariant(순서에 영향을 받지 않는)한 방식으로 처리한다는 점에 있다. 즉, 입력된 point들의 순서와 관계없이 각 point를 독립적으로 동일한 방식으로 처리한 뒤, 최종적으로 모든 결과를 순서에 상관없이 통합하여 분석하는 구조를 갖는다.
PointNet architecture
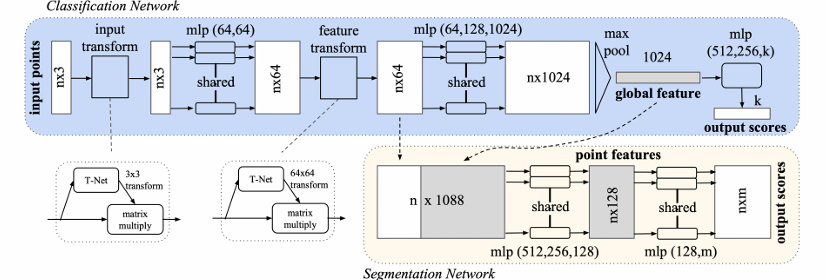
전체적인 아키텍처 구조이다. 하나씩 뜯어서 살펴보자.
MLP Layer
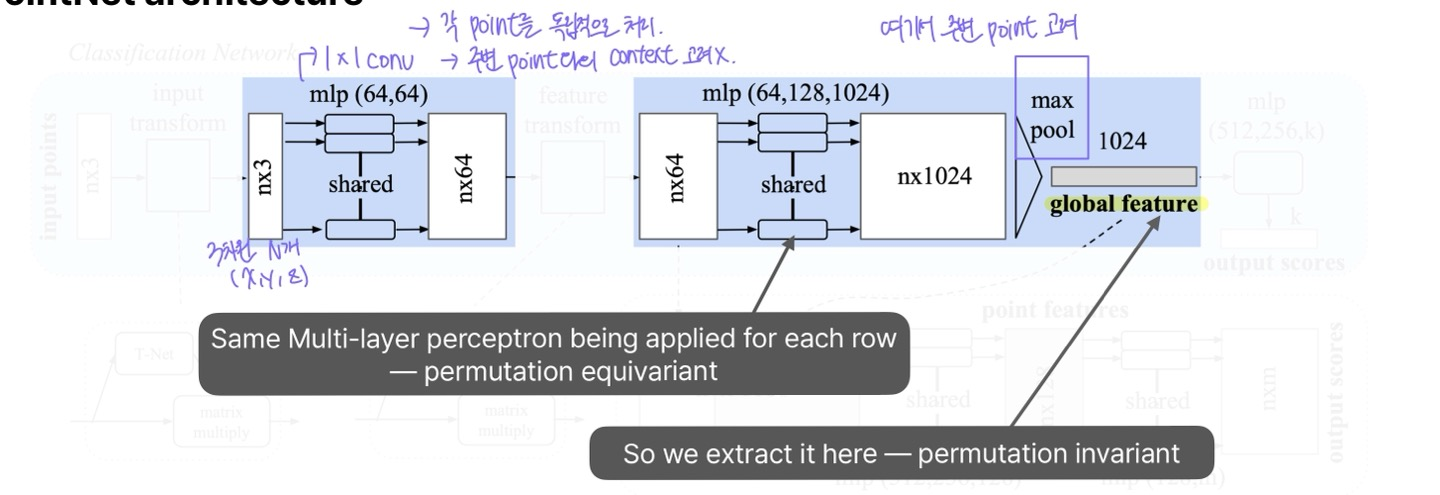
PointNet이 point cloud를 처리할 때 사용하는 MLP는 사실상 1x1 conv로 볼 수 있다. 1x1 conv는 각 포인트를 독립적으로 처리하는데, 이는 결국 각 포인트에 동일한 Linear Layer(선형 변환)을 적용하는 것과 같다.
예를 들어 한 포인트가 (x, y, z) 좌표를 갖고 있다고 해 보자. PointNet에는 이런 포인트들이 수천 개에서 수백만 개까지 입력될 수 있다. 이때, 1x1 conv를 적용하면 모든 point에 대해 같은 변환을 수행하게 된다. 즉, 3 x N (3차원 포인트 N개) 데이터에 대해 동일한 변환이 각각의 포인트에 독립적으로 적용되는 것과 같다.
이 방식의 단점은 포인트 간 관계(Spatial Relationship)를 고려하지 않는다. 각 포인트가 개별적으로 처리되기 때문에, 서로 다른 포인트들이 어떻게 연결되어 있는지, 서로 어떤 의미를 갖는지 반영되지 않는다. 즉, 주변 포인트들과의 context와 relationship이 사라지게 된다.
PointNet은 위 문제를 해결하기 위해 Max pooling 연산을 적용한다. Max Pooling을 사용하면, 모든 포인트에서 가장 강한 특징을 추출하여 global feature를 얻을 수 있다. 즉, 포인트 하나하나를 독립적으로 처리한 후, 최종적으로 전체 포인트 클라우드에서 중요한 정보들을 하나로 압축하는 방식을 사용한다.
Transform
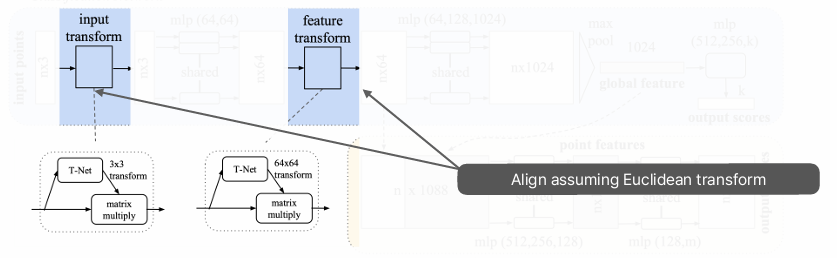
Input Transform은 입력된 point cloud 데이터에 대해 3x3 변환 행렬을 학습하여 조정하는 역할을 한다.
point cloud data는 센서(LiDAR, RGB-D 카메라)나 3D 스캔 방식에 따라 좌표계가 다를 수 있고, 회전/이동된 상태로 주어질 수 있다. 예를 들어, 같은 객체라도 다른 각도에서 촬영된 points는 서로 다른 위치와 방향을 가질 수 있다.
이런 변화를 보정하기 위해 PointNet은 3x3 변환 행렬을 학습하여 조정하는 것이다.
Feature Transform은 64x64 변환 행렬을 학습하여 feature space에서도 alignment를 수행한다. 같은 물체라도 시점이 다르면 네트워크의 feature 값이 다르게 추출될 수 있다. feature transform은 학습된 feature를 변환하여 네트워크가 학습한 feature 또한 같도록 align한다.
Euclidean transform을 기반으로 하는 input transform과 feature transform은 point cloud data를 학습 과정에서 일관되게 align하여 네트워크가 위치 및 방향 변화에 robust한 특성 (위치, 회전, 순서 변화에 영향을 받지 않고 같은 결과로 표현되는 특성)을 갖도록 하다.
Universal approximation
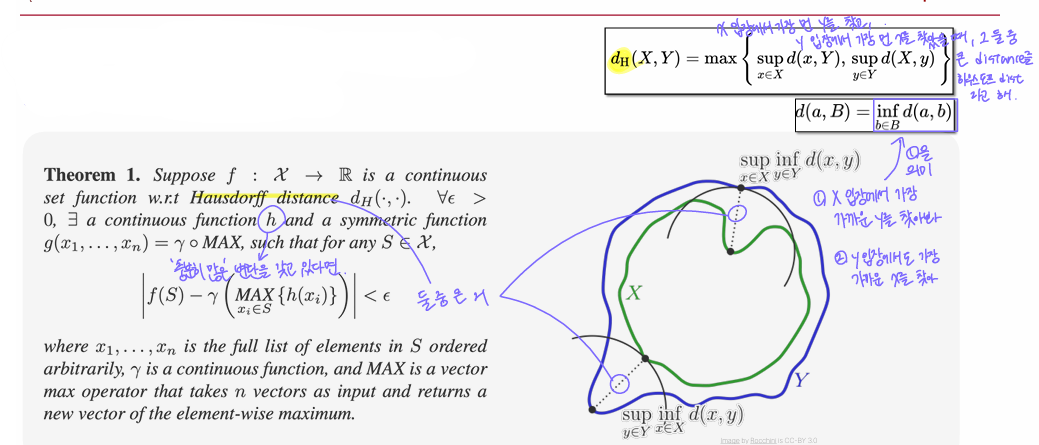
PointNet에서 Universal Approximation Theorem이 갖는 의미는, PointNet 구조가 모든 Point Cloud Dataset을 적절히 학습하고 표현할 수 있다는 수학적 보장이다. 즉, PointNet이 어떤 point cloud data라도 잘 처리할 수 있도록 충분한 표현력을 갖추고 있음을 증명한 것이다.
여기서 PointNet이 잘 학습했는지 나타내는 지표로 사용되는 게 Hausdorff Distance이다. 이 지표는 두 point cloud dataset이 얼마나 다른지, 얼마나 비슷한지를 측정한다. 예를 들어, 자동차 point cloud X와 변형된 자동차 point cloud Y가 있다고 하자. PointNet이 잘 동작하려면 이 두 점 집합이 같은 자동차라는 것을 인식할 수 있어야 한다. 이때 Hausdorff Distance로 두 점 집합 간의 차이를 측정한다.
다만 Universal Approximation이 성립되기 위해서는 개별 point에서 feature를 추출하는 h(x) 함수가 충분히 많은 변환를 가져야 (=복잡한 feature를 뽑아낼 수 있어야) 한다. 그래야 서로 다른 point가 다른 feature로 매핑되며 네트워크가 서로 다른 point cloud set을 구별할 수 있게 된다.
수식은 자세히 설명하진 않으셨지만, f(S)는 PointNet을 수식으로 표현한 것이다. 각 기호의 의미는 아래와 같다.
- S: point Cloud
- h(x): 개별 point에서 feature를 추출하는 MLP 같은 네트워크
- max: global max pooling
- gamma: global feature를 최종적으로 변환하는 pointnet의 마지막 MLP 레이어
Qualitative examples
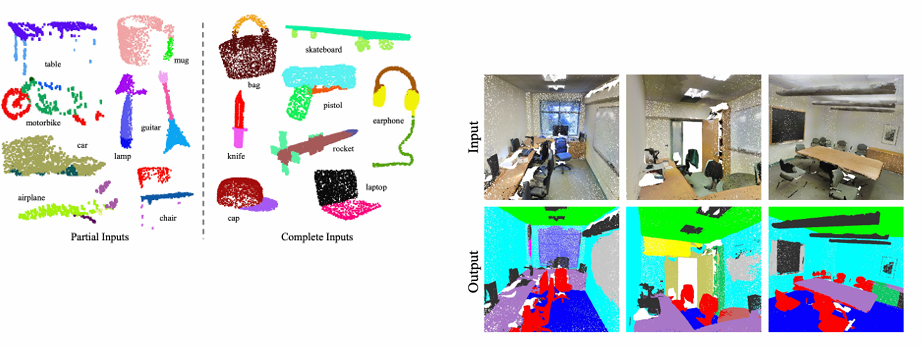
보이는 것처럼 꽤나 결과가 좋다.
Classification perf. with different ways of achieving permutation invariance
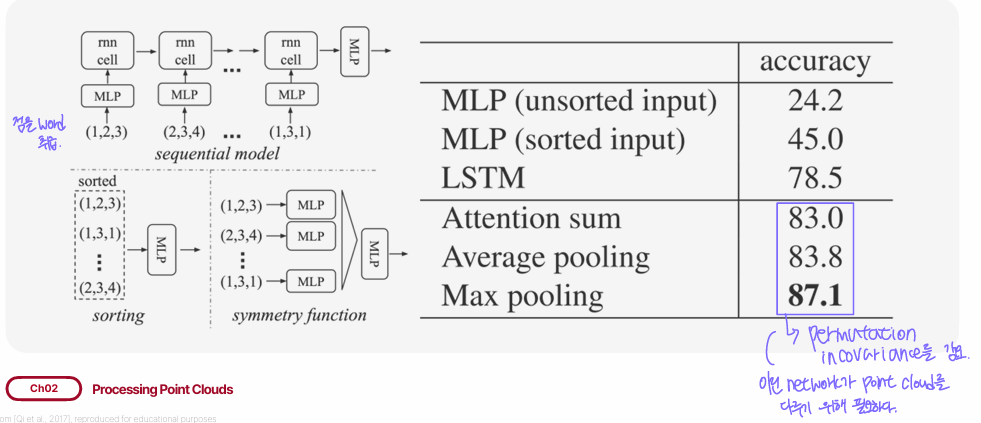
point cloud를 word 취급하여 sequential model에 input으로 제공하였을 때와 point cloud를 permutation invariant한 model에 제공하였을 때 성능 비교이다. permutation invariant한 model의 acc가 훨씬 높은 걸 알 수 있다.
How the alignment component affects performance
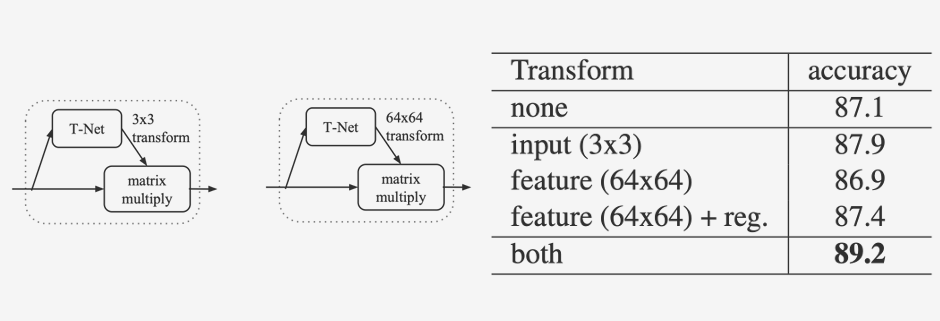
앞서 설명하였던 transform을 제거했을 때와 추가했을 때의 성능 비교다. 미미하지만 둘 다 추가하였을 때 성능이 더 좋을 것을 알 수 있다.
Visualizing what the network is seeing

PointNet이 실제로 point cloud로부터 어떤 정보를 학습하는지 시각화한 자료이다.
Critical Point Sets는 PointNet이 실제로 학습 과정에서 중요하다고 판단한 points만 남긴 것이다. 이 적은 수의 points만으로도 PointNet은 원래 물체를 인식할 수 있다.
Segment Network
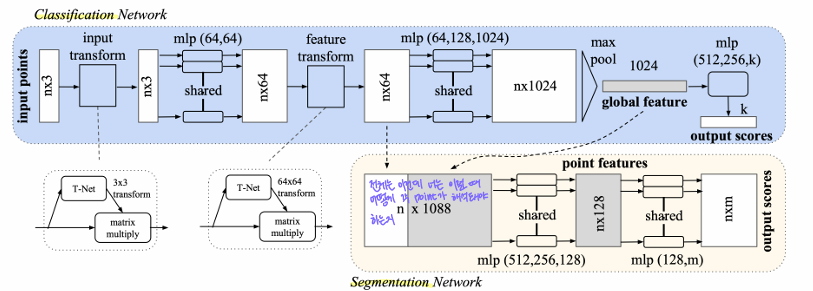
여기서 설명할 부분은 그림의 노란색 block이다.
Segmentation Network는 각 point에 대해 어떤 segment(부분)에 속하는지 예측하는 역할을 한다. 이 예측을 수행하기 위해서는 각 point의 local 정보뿐만 아니라 전체 point cloud의 global feature까지 함께 사용해야 한다.
에를 들어 의자의 다리 부분을 인식하려면, 이 물체가 의자라는 global feature를 참고해야 더 정확히 할 수 있다. 그래서 n x 64 feature에 global feature를 concatenate하여 각 point의 최종 feature를 만든다.
