📌Optional<T>
T 타입 객체의 래퍼 클래스
public final class Optional<T> {
// T타입 참조변수 -> 모든 종류의 객체 저장 가능(null 까지)
private final T value;
...
}-
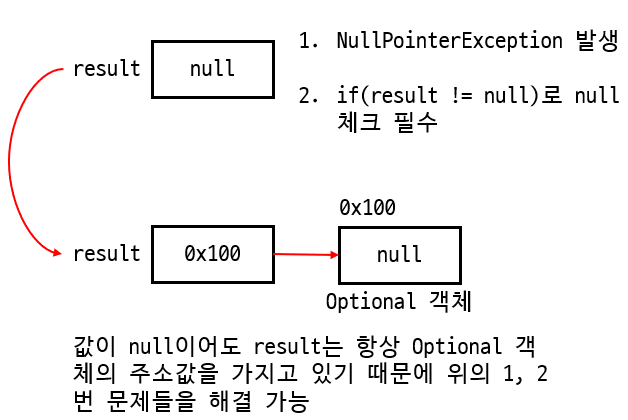
T value: T 타입의 참조변수로써 null 포함 모든 종류의 객체를 저장할 수 있다. -
null을 간접적으로 다루기 위해 사용한다.
- null을 직접 다루게 되면
NullPointerException이 발생할 위험이 있는데 이를 방지할 수 있다. - null 체크를 위한 if문 작성으로 지저분해질 수 있는 코드를 간결하게 할 수 있다.
- null을 직접 다루게 되면
Optional<T> 객체 생성하기
Optional<T> 객체를 생성하는 방법
String str = "abc";
Optional<String> optStr = Optional.of(str);
Optional<String> optStr = Optional.of("abc");
Optional<String> optStr = Optional.ofNullable(null); // null을 저장할 때 사용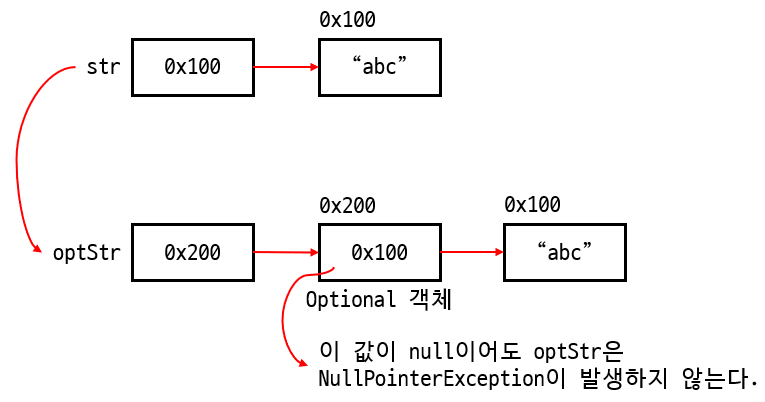
null 대신 빈 Optional<T> 객체를 사용
Optional<String> optVal = null; // 가능은 하나 바람직하지 않음
Optional<String> optStrVal = Optional.empty();Optional<T> 객체의 값 가져오기
Optional<String> optVal = Optional.of("abc");
// optVal에 저장된 값을 반환. null이면 예외 발생 -> 잘 쓰지 않음
String str1 = optVal.get();
// optVal에 저장된 값을 반환. null이면 "" 반환
String str2 = optVal.orElse("");
// optVal에 저장된 값을 반환. null이면 new String 객체 반환
String str3 = optVal.orElseGet(String::new);
// 람다식으로도 가능
String str3 = optVal.orElseGet(() -> new String());
// optVal에 저장된 값을 반환. null이면 예외 발생
String str4 = optVal.orElseThrow(NullPointerException::new);isPresent(), ifPresent()
boolean isPresent()
Optional 객체의 값이 null이면 false, 아니면 true 반환
String str = "abc";
if(Optional.ofNullable(str).isPresent()) {
System.out.println(str);
}abc
Optional객체의 값이 null이 아닐 때 작업 수행
void ifPresnet(Consumer<T> action)
Optional 객체의 값이 null이 아닐 때 ifPresent() 괄호 안의 람다식 수행
String str = "abc";
Optional.ofNullable(str).ifPresent(System.out::println);abc
OptionalInt, OptionalLong, OptionalDouble
기본형 값을 감싸는 래퍼 클래스
public final class OptionalInt {
private final boolean isPresent;
private final int value;
...
} isPresent: 값이 저장되어 있으면 true 반환value: int 타입의 변수
OptionalInt의 값 가져오기
| Optional 클래스 | get() 메서드 |
|---|---|
Optional<T> | T get() |
OptionalInt | int getAsInt() |
OptionalLong | long getAsLong() |
OptionalDouble | double getAsDouble() |
빈 OptionalInt 객체와 비교
OptionalInt optInt1 = OptionalInt.of(0); // 0을 저장
OptionalInt optInt2 = OptionalInt.empty(); // 빈 객체 생성
System.out.println(optInt1.isPresent()); // true
System.out.println(optInt2.isPresent()); // false
System.out.println(optInt1.getAsInt()); // 0
System.out.println(optInt2.getAsInt()); // 에러
System.out.println(optInt1.equals(optInt2)); // false- 0을 저장한 OptionalInt와 빈 객체를 생성해서 초기값이 0으로 저장된 OptionalInt를 구분하기 위해
isPresent()를 사용한다.
📌최종 연산
: 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하기 때문에 단 한번만 수행 가능
최종 연산 메서드
| 최종 연산 | 설명 |
|---|---|
void forEach(Consumer<? super T> action) | 각 요소에 지정된 작업을 수행 |
void forEachOrdered(Consumer<? super T> action) | 병렬 스트림일 때 순서를 유지하며 각 요소에 지정된 작업을 수행 |
long count() | 스트림의 요소 개수를 반환 |
Optional<T> max(Comparator<? super T> comparator) | 스트림의 최대값을 반환 |
Optional<T> min(Comparator<? super T> comparator) | 스트림의 최소값을 반환 |
Optional<T> findAny() | 병렬 스트림의 요소 중 아무거나 하나를 반환(filter와 같이 사용) |
Optional<T> findFirst() | 직렬 스트림의 요소 중 첫 번째 요소를 반환(filter와 같이 사용) |
boolean allMatch(Predicate<T> p) | 주어진 조건을 모든 요소가 만족하면 true 반환 |
boolean anyMatch(Predicate<T> p) | 주어진 조건을 요소 중 하나라도 만족하면 true 반환 |
boolean noneMatch(Predicate<T> p) | 주어진 조건을 모든 요소가 만족하지 않으면 true 반환 |
Object[] toArray()A[] toArray(IntFunction<A[]> generator) | 스트림의 모든 요소를 배열로 반환 |
reduce()
| 최종 연산 | 설명 |
|---|---|
Optional<T> reduce(BinaryOperator<T> accumulator) | |
T reduce(T identity, BinaryOperator<T> accumulator) | 스트림의 요소를 하나씩 줄여가면서 계산 |
U reduce(U identity, BiFunction<U,T,U> accumulator, BinaryOperator<U> combiner) |
collect()
| 최종 연산 | 설명 |
|---|---|
R collect(Collector<T,A,R> collector) | |
R collect(Supplier<R> supplier, BiConsumer<R,T> accumulator, BiConsumer<R,R> combiner) | 스트림의 요소를 수집한다. 주로 요소를 그룹화하거나 분할한 결과를 컬렉션에 담아 반환하는데 사용된다. |
forEach()
스트림의 모든 요소에 지정된 작업을 수행
void forEach(Consumer<? super T> action)
void forEachOrdered(Consumer<? super T> action)forEachOrdered()병렬 스트림일 경우에도 순서가 보장된다.
// 직렬 스트림, forEach() -> 순서 보장 O
IntStream.rangeClosed(1,10).forEach(System.out::print);
System.out.println();
// 병렬 스트림, forEach() -> 순서 보장 X
IntStream.rangeClosed(1,10).parallel().forEach(System.out::print);
System.out.println();
// 병렬 스트림, forEachOrdered() -> 순서 보장 O
IntStream.rangeClosed(1,10).parallel().forEachOrdered(System.out::print);12345678910
76395128104
12345678910
allMatch(), anyMatch(), noneMatch()
스트리의 요소를 조건 검사해서 boolean 타입 반환
boolean allMatch(Predicate<? super T> Predicate)
boolean anyMatch(Predicate<? super T> Predicate)
boolean noneMatch(Predicate<? super T> Predicate) // allMatch와 반대allMatch(): 모든 요소가 조건을 만족하면 trueanyMatch(): 한 요소라도 조건을 만족하면 truenoneMatch(): 모든 요소가 조건을 만족하지 않으면 true
findFirst(), findAny()
조건에 일치하는 요소 반환. 보통 중간 연산인 filter()와 같이 사용
Optional<T> findFirst()
Optional<T> findAny()
Optional<Student> result = stuStream.filter( s -> s.getTotalScore() <= 100).findFirst();
Optional<Student> result = stuStream.parallel().filter( s -> s.getTotalScore() <= 100).findAny();-
결과가 null일수도 있기 때문에 반환타입이
Optional<T>이다. -
findFirst(): 직렬 스트림에서 사용.filter()의 조건을 만족하는 요소 중 첫 번째 요소를 반환 -
findAny(): 병렬 스트림에서 사용.filter()의 조건을 만족하는 요소 중 아무거나 하나를 반환
reduce()
스트림의 요소를 하나씩 줄여가면서 누적 연산(accumulator) 수행
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(U identity, BiFunction<U,T,U> accumulator, BinaryOperator<U> combiner)
// identity : 초기값
// accumulator : 이전 연산 결과와 스트림의 요소에 수행할 연산
// combiner : 병렬 처리된 결과를 합치는데 사용할 연산(병렬 스트림)
Optional<T> reduce()와T reduce()
이 두 메서드는 초기값의 유무가 차이날 뿐 같은 기능을 한다.
그런데 만약, 비어있는 스트림의 경우T reduce()은 초기값을 반환한다. 그래서 초기값의 반환타입과reduce()의 반환타입이T로 같은 것이다.
그러나Optional<T> reduce()는 초기값이 없어 반환값이 null이 되기 때문에 반환타입이Optional<T>인 것이다.
최종 연산인 count(), sum(), max(), min() 등을 reduce를 활용해 구현할 수 있다.
IntStream intStream = IntStream.of(1, 4, 2, 11, 3);
int count = intStream.reduce(0, (a, b) -> a + 1);
intStream = IntStream.of(1, 4, 2, 11, 3);
int sum = intStream.reduce(0, (a, b) -> a + b);
intStream = IntStream.of(1, 4, 2, 11, 3);
int max = intStream.reduce(Integer.MIN_VALUE, (a, b) -> a > b ? a : b);
intStream = IntStream.of(1, 4, 2, 11, 3);
int min = intStream.reduce(Integer.MAX_VALUE, (a, b) -> a > b ? b : a);
System.out.printf("%d, %d, %d, %d", count, sum1, max, min);5, 21, 11, 1
실습예제
import java.util.*;
import java.util.stream.*;
class Ex14_9 {
public static void main(String[] args) {
String[] strArr = {
"Inheritance", "Java", "Lambda", "stream",
"OptionalDouble", "IntStream", "count", "sum"
};
// 빈 문자열을 하나도 가지고 있지 않다면 true 반환
boolean noEmptyStr = Stream.of(strArr).noneMatch(s -> s.length() == 0);
// s로 시작하는 문자열 중 첫 번째 요소를 반환
Optional<String> sWord = Stream.of(strArr)
.filter(s -> s.charAt(0) == 's').findFirst();
System.out.println("noEmptyStr = " + noEmptyStr);
// s로 시작하는 문자열이 없다면 문구 출력
System.out.println("sWord = " + sWord.orElse("s로 시작하는 단어가 없습니다."));
// Stream<String[]>을 IntStream으로 변환
Stream.of(strArr).mapToInt(String::length).forEach(s -> System.out.print(s + " "));
System.out.println();
IntStream intStream1 = Stream.of(strArr).mapToInt(String::length);
int count = intStream1.reduce(0, (a, b) -> a + 1);
IntStream intStream2 = Stream.of(strArr).mapToInt(String::length);
int sum = intStream2.reduce(0, Integer::sum);
// int sum = intStream2.reduce(0, (a, b) -> a + b); // 람다식
// 초기값을 설정안하면 반환타입은 OptionalInt로 설정해줘야 한다.
IntStream intStream3 = Stream.of(strArr).mapToInt(String::length);
OptionalInt max = intStream3.reduce(Integer::max);
// OptionalInt max = intStream3.reduce((a,b)-> a > b ? a : b); // 람다식
IntStream intStream4 = Stream.of(strArr).mapToInt(String::length);
OptionalInt min = intStream4.reduce(Integer::min);
// OptionalInt min = intStream4.reduce((a,b)-> a > b ? b : a); // 람다식
System.out.println("count = " + count);
System.out.println("sum = " + sum);
System.out.println("max = " + max.orElse(0));
System.out.println("min = " + min.orElse(0));
}
}noEmptyStr = true
sWord = stream
11 4 6 6 14 9 5 3
count = 8
sum = 58
max = 14
min = 3
-
IntStream intStream1 = Stream.of(strArr).mapToInt(String::length);: String[] 배열의 각 요소의 길이를 IntStream으로 변환할 때 mapToInt 사용 -
OptionalInt max = intStream3.reduce(Integer::max);: 초기값을 설정안하면 반환타입은 Optional 타입으로 해줘야 한다. -
reduce((a,b)-> a > b ? a : b)이 람다식을reduce(Integer::max)변경 가능
collect()와 Collectors
collect()는 Collector를 매개변수로 하는 스트림의 최종 연산
R collect(Collector<T,A,R> collector) // Collector를 구현한 클래스의 객체를 매개변수로 지정
R collect(Supplier<R> supplier, BiConsumer<R,T> accumulator, BiConsumer<R,R> combiner) // 잘 안쓰임Collector는 수집(collect)에 필요한 메서드를 정의해 놓은 인터페이스
// T(요소)를 A에 누적한 다음, 결과를 R로 변환해서 반환
public interface Collector<T, A, R> {
// 누적할 곳
Supplier<A> supplier(); // StringBuilder::new
// 누적 방법
BiConsumer<A, T> accumulator(); // (sb, s) -> sb.append(s)
// 결합 방법(병렬)
BinaryOperator<A> combiner(); // (sb1, sb2) -> sb1.append(sb2)
// 최종 변환 (R타입으로)
Function<A, R> finisher(); // sb -> sb.toString()
// 컬렉터 특성의 담긴 Set 반환
Set<Characteristics> characteristics() ;
...
}Collectors 클래스는 다양한 기능의 컬렉터(Collector를 구현한 클래스)를 제공
toList(), toSet(), toMap(), toCollection()
: 스트림을 컬렉션으로 변환
Stream<Student> studentStream = Stream.of(
new Student("이빛나", 3, 300),
new Student("김자바", 1, 200),
new Student("안정호", 2, 100),
new Student("박코딩", 2, 150),
new Student("최자연", 1, 200),
new Student("연보라", 3, 290),
new Student("정나라", 3, 180)
);
List<String> list = studentStream
.map(Student::getName)
.collect(Collectors.toList());
System.out.println(list);[이빛나, 김자바, 안정호, 박코딩, 최자연, 연보라, 정나라]
- studentStream의 이름을 List로 변환
ArrayList<Integer> arrayList = studentStream
.map(Student::getTotalScore)
.sorted()
.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayList);[100, 150, 180, 200, 200, 290, 300]
- ArrayList로 변환하고 싶을 때
.collect(Collectors.toCollection(ArrayList::new));사용
Map<String, Student> map = studentStream
.collect(Collectors.toMap(Student::getName, p -> p));
System.out.println(map);{박코딩=[박코딩, 2, 150], 김자바=[김자바, 1, 200],
이빛나=[이빛나, 3, 300], 안정호=[안정호, 2, 100],
연보라=[연보라, 3, 290], 최자연=[최자연, 1, 200],
정나라=[정나라, 3, 180]}
- 이름을 key로 하고 Student 객체를 value로 하는 map으로 변환
p -> p는 항등함수로 입력한 변수가 그대로 출력된다.
toArray()
스트림을 배열로 변환
Student[] students = studentStream.toArray(Student[]::new);
System.out.println(Arrays.toString(students));[[이빛나, 3, 300], [김자바, 1, 200],
[안정호, 2, 100], [박코딩, 2, 150],
[최자연, 1, 200], [연보라, 3, 290],
[정나라, 3, 180]]
counting(), summingInt(), maxBy(), minBy()
스트림의 통계 정보를 제공
long count = studentStream.count();
long count = studentStream.collect(Collectors.counting());- 똑같이 studentStream의 요소 개수를 반환한다. 그러나
count()는 전체 요소만 카운팅할 수 있지만collect(Collectors.counting())은 그룹별로 나눠서 카운팅할 수 있다.
long totalScore = studentStream.mapToInt(Student::getTotalScore).sum();
long totalScore = studentStream.collect(Collectors.summingInt(Student::getTotalScore));
Optional<Student> topStudent = studentStream
.max(Comparator.comparingInt(Student::getTotalScore));
Optional<Student> topStudent = studentStream
.collect(Collectors.maxBy(Comparator.comparingInt(Student::getTotalScore)));summingInt(), maxBy(), minBy()모두 기능은 기존sum(), max(), min()과 동일하지만 그룹별로 나눠서 작업을 수행할 수 있다.
reducing()
reduce()는 전체만 리듀싱할 수 있지만 reducing()은 그룹별로 나눠서 리듀싱 할 수 있다.
IntStream intStream = Arrays.stream(new int[]{1, 2, 3, 4, 5});
long sum = intStream.reduce(0, (a, b) -> a + b);
long sum = intStream.boxed().collect(Collectors.reducing(0, (a, b) -> a + b));joining()
문자열 스트림의 요소를 모두 연결
String strName = studentStream
.map(Student::getName)
.collect(Collectors.joining(","));
System.out.println(strName);이빛나,김자바,안정호,박코딩,최자연,연보라,정나라
map()으로 이름을 뽑아내고joining(",")을 통해,구분자로 해서 이름을 나열하는 String 문자열을 생성
String strName = studentStream
.map(Student::getName)
.collect(Collectors.joining(",", "[", "]"));
System.out.println(strName);[이빛나,김자바,안정호,박코딩,최자연,연보라,정나라]
joining(",", "[", "]"):,를 구분자로 하고 문자열의 처음과 끝에[,]추가
그룹화 & 분할
partitioningBy() : 스트림을 2분할 한다.
Collector partitioningBy(Predicate predicate)
Collector partitioningBy(Predicate predicate, Collector downstream)- 괄호 안에 조건식을 넣어서 Map의 key를 true/false로 하고 조건식을 만족하는 값을 true의 value 값으로 저장한다.
실습예제
import java.util.*;
import java.util.stream.*;
import static java.util.stream.Collectors.*;
import static java.util.Comparator.*;Collectors.partitioningBy->partitioningBy으로 축약Comparator.comparing->comparing으로 축약
class Student2 {
String name;
boolean isMale;
int hak;
int ban;
int score;
Student2(String name, boolean isMale, int hak, int ban, int score) {
this.name = name;
this.isMale = isMale;
this.hak = hak;
this.ban = ban;
this.score = score;
}
String getName() { return name; }
boolean isMale() { return isMale; }
int getHak() { return hak; }
int getBan() { return ban; }
int getScore() { return score; }
public String toString() {
return String.format("[%s, %s, %d학년 %d반, %3d점]",
name, isMale ? "남" : "여", hak, ban, score);
}
}- Student2 변수, 생성자, getter 정의
toString()오버라이딩
class Ex14_10 {
public static void main(String[] args) {
Student2[] stuArr = {
new Student2("김코딩", true, 1, 1, 300),
new Student2("정수민", false, 1, 1, 250),
new Student2("오정호", true, 1, 1, 200),
new Student2("김선미", false, 1, 2, 150),
new Student2("정주일", true, 1, 2, 100),
new Student2("이효리", false, 1, 2, 50),
new Student2("이정현", false, 1, 3, 100),
new Student2("유정선", false, 1, 3, 150),
new Student2("강호동", true, 1, 3, 200),
new Student2("이수근", true, 2, 1, 300),
new Student2("김미희", false, 2, 1, 250),
new Student2("최시원", true, 2, 1, 200),
new Student2("박지원", false, 2, 2, 150),
new Student2("안세훈", true, 2, 2, 100),
new Student2("오채원", false, 2, 2, 50),
new Student2("임희민", false, 2, 3, 100),
new Student2("홍은채", false, 2, 3, 150),
new Student2("신정우", true, 2, 3, 200)
};- Student2 객체들을 정의하고 Student2[] 배열로 저장
System.out.printf("1. 단순분할(성별로 분할)%n");
Map<Boolean, List<Student2>> stuBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale));
List<Student2> maleStudent = stuBySex.get(true);
List<Student2> femaleStudent = stuBySex.get(false);
for (Student2 s : maleStudent) System.out.println(s);
for (Student2 s : femaleStudent) System.out.println(s);
- 단순분할(성별로 분할)
[김코딩, 남, 1학년 1반, 300점]ㅤ
[오정호, 남, 1학년 1반, 200점]ㅤ
[정주일, 남, 1학년 2반, 100점]ㅤ
[강호동, 남, 1학년 3반, 200점]ㅤ
[이수근, 남, 2학년 1반, 300점]ㅤ
[최시원, 남, 2학년 1반, 200점]ㅤ
[안세훈, 남, 2학년 2반, 100점]ㅤ
[신정우, 남, 2학년 3반, 200점]ㅤ
[정수민, 여, 1학년 1반, 250점]ㅤ
[김선미, 여, 1학년 2반, 150점]ㅤ
[이효리, 여, 1학년 2반, 50점]ㅤ
[이정현, 여, 1학년 3반, 100점]ㅤ
[유정선, 여, 1학년 3반, 150점]ㅤ
[김미희, 여, 2학년 1반, 250점]ㅤ
[박지원, 여, 2학년 2반, 150점]ㅤ
[오채원, 여, 2학년 2반, 50점]ㅤ
[임희민, 여, 2학년 3반, 100점]ㅤ
[홍은채, 여, 2학년 3반, 150점]ㅤ
partitioningBy(Student2::isMale)를 통해 성별로 2분할해서 Map의 key에 남자면 true, 여자면 false 저장, value에는 key에 해당하는 Student2 객체를 List 타입으로 저장
System.out.printf("%n2. 단순분할 + 통계(성별 학생 수)%n");
Map<Boolean, Long> stuNumBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale, counting()));
System.out.println("남학생 수 :" + stuNumBySex.get(true));
System.out.println("여학생 수 :" + stuNumBySex.get(false));
- 단순분할 + 통계(성별 학생 수)
남학생 수 :8
여학생 수 :10
partitioningBy(Student2::isMale, counting()): 성별로 2분할(true, false)하고 각각의 요소의 개수르 카운팅
System.out.printf("%n3. 단순분할 + 통계(성별 1등)%n");
Map<Boolean, Optional<Student2>> topScoreBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale,
maxBy(comparingInt(Student2::getScore))));
System.out.println("남학생 1등 :" + topScoreBySex.get(true));
System.out.println("여학생 1등 :" + topScoreBySex.get(false));
// Optional 객체의 값을 꺼내서 저장
Map<Boolean, Student2> topScoreBySex2 = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale,
collectingAndThen(
maxBy(comparingInt(Student2::getScore)),
Optional::get)));
System.out.println("남학생 1등 :" + topScoreBySex2.get(true));
System.out.println("여학생 1등 :" + topScoreBySex2.get(false));
- 단순분할 + 통계(성별 1등)
남학생 1등 :Optional[[김코딩, 남, 1학년 1반, 300점]]
여학생 1등 :Optional[[정수민, 여, 1학년 1반, 250점]]
남학생 1등 :[김코딩, 남, 1학년 1반, 300점]
여학생 1등 :[정수민, 여, 1학년 1반, 250점]
-
성별로 2분할 후
maxBy(comparingInt(Student2::getScore)를 이용하여 각 성별의 점수가 최대값이 Studeent2 객체 추출 -
maxBy()의 반환타입은 Optional이기 때문에 Map의 value 반환타입을Optional<Student2>으로 지정 -
collectingAndThen()을 이용해서 Optional 객체의 값을 꺼내서 Map의 value에 저장 가능
System.out.printf("%n4. 다중분할(성별 불합격자, 100점 이하)%n");
Map<Boolean, Map<Boolean, List<Student2>>> failedStuBySex =
Stream.of(stuArr).collect(partitioningBy(Student2::isMale,
partitioningBy(s -> s.getScore() <= 100))
);
List<Student2> failedMaleStu = failedStuBySex.get(true).get(true);
List<Student2> failedFemaleStu = failedStuBySex.get(false).get(true);
for (Student2 s : failedMaleStu) System.out.println(s);
for (Student2 s : failedFemaleStu) System.out.println(s);
}
}
- 다중분할(성별 불합격자, 100점 이하)
[정주일, 남, 1학년 2반, 100점]ㅤ
[안세훈, 남, 2학년 2반, 100점]ㅤ
[이효리, 여, 1학년 2반, 50점]ㅤ
[이정현, 여, 1학년 3반, 100점]ㅤ
[오채원, 여, 2학년 2반, 50점]ㅤ
[임희민, 여, 2학년 3반, 100점]ㅤ
- 성별로 2분할 후, value 값을 다시 점수가 100점 이하면 key를 true로 하고 value를 Student2 객체로 저장 -> 다중분할
groupingBy() : 스트림을 n분할 한다.
Collector groupingBy(Function classifier)
Collector groupingBy(Function classifier, Collector downstream)
Collector groupingBy(Function classifier, Supplier mapFactory, Collector downstream)- 괄호 안에 스트림을 나눌 기준을 정해주고 그 값을 Map의 key에 저장하고 각 key에 해당하는 값을 value에 저장한다.
실습예제
import java.util.*;
import java.util.stream.*;
import static java.util.stream.Collectors.*;
import static java.util.Comparator.*;
class Student3 {
String name;
boolean isMale;
int hak;
int ban;
int score;
Student3(String name, boolean isMale, int hak, int ban, int score) {
this.name = name;
this.isMale = isMale;
this.hak = hak;
this.ban = ban;
this.score = score;
}
String getName() { return name; }
boolean isMale() { return isMale; }
int getHak() { return hak; }
int getBan() { return ban; }
int getScore() { return score; }
public String toString() {
return String.format("[%s, %s, %d학년 %d반, %3d점]",
name, isMale ? "남" : "여", hak, ban, score);
}
enum Level {HIGH, MID, LOW}
}- 위 예제와 동일하나
enum Level {HIGH, MID, LOW}스트림을 그룹화할 enum 클래스 1개 추가
class Ex14_11 {
public static void main(String[] args) {
Student3[] stuArr = {
new Student3("김코딩", true, 1, 1, 300),
new Student3("정수민", false, 1, 1, 250),
new Student3("오정호", true, 1, 1, 200),
new Student3("김선미", false, 1, 2, 150),
new Student3("정주일", true, 1, 2, 100),
new Student3("이효리", false, 1, 2, 50),
new Student3("이정현", false, 1, 3, 100),
new Student3("유정선", false, 1, 3, 150),
new Student3("강호동", true, 1, 3, 200),
new Student3("이수근", true, 2, 1, 300),
new Student3("김미희", false, 2, 1, 250),
new Student3("최시원", true, 2, 1, 200),
new Student3("박지원", false, 2, 2, 150),
new Student3("안세훈", true, 2, 2, 100),
new Student3("오채원", false, 2, 2, 50),
new Student3("임희민", false, 2, 3, 100),
new Student3("홍은채", false, 2, 3, 150),
new Student3("신정우", true, 2, 3, 200)
};- 객체 데이터는 위 예제와 동일
System.out.printf("1. 단순그룹화(반별로 그룹화)%n");
Map<Integer, List<Student3>> stuByBan = Stream.of(stuArr)
.collect(groupingBy(Student3::getBan));
for (List<Student3> ban : stuByBan.values()) {
for (Student3 s : ban) {
System.out.println(s);
}
}
- 단순그룹화(반별로 그룹화)
[김코딩, 남, 1학년 1반, 300점]ㅤ
[정수민, 여, 1학년 1반, 250점]ㅤ
[오정호, 남, 1학년 1반, 200점]ㅤ
[이수근, 남, 2학년 1반, 300점]ㅤ
[김미희, 여, 2학년 1반, 250점]ㅤ
[최시원, 남, 2학년 1반, 200점]ㅤ
[김선미, 여, 1학년 2반, 150점]ㅤ
[정주일, 남, 1학년 2반, 100점]ㅤ
[이효리, 여, 1학년 2반, 50점]ㅤ
[박지원, 여, 2학년 2반, 150점]ㅤ
[안세훈, 남, 2학년 2반, 100점]ㅤ
[오채원, 여, 2학년 2반, 50점]ㅤ
[이정현, 여, 1학년 3반, 100점]ㅤ
[유정선, 여, 1학년 3반, 150점]ㅤ
[강호동, 남, 1학년 3반, 200점]ㅤ
[임희민, 여, 2학년 3반, 100점]ㅤ
[홍은채, 여, 2학년 3반, 150점]ㅤ
[신정우, 남, 2학년 3반, 200점]ㅤ
groupingBy(Student3::getBan)을 통해 반별로 그룹화 후 출력
System.out.printf("%n2. 단순그룹화(성적별로 그룹화)%n");
Map<Student3.Level, List<Student3>> stuByLevel = Stream.of(stuArr)
.collect(groupingBy(s -> {
if (s.getScore() >= 200) return Student3.Level.HIGH;
else if (s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
}));
for (Student3.Level key : Student3.Level.values()) {
System.out.println("[" + key + "]");
for (Student3 s : stuByLevel.get(key))
System.out.println(s);
System.out.println();
}
- 단순그룹화(성적별로 그룹화)
[HIGH]ㅤ
[김코딩, 남, 1학년 1반, 300점]ㅤ
[정수민, 여, 1학년 1반, 250점]ㅤ
[오정호, 남, 1학년 1반, 200점]ㅤ
[강호동, 남, 1학년 3반, 200점]ㅤ
[이수근, 남, 2학년 1반, 300점]ㅤ
[김미희, 여, 2학년 1반, 250점]ㅤ
[최시원, 남, 2학년 1반, 200점]ㅤ
[신정우, 남, 2학년 3반, 200점]ㅤ
[MID]ㅤ
[김선미, 여, 1학년 2반, 150점]ㅤ
[정주일, 남, 1학년 2반, 100점]ㅤ
[이정현, 여, 1학년 3반, 100점]ㅤ
[유정선, 여, 1학년 3반, 150점]ㅤ
[박지원, 여, 2학년 2반, 150점]ㅤ
[안세훈, 남, 2학년 2반, 100점]ㅤ
[임희민, 여, 2학년 3반, 100점]ㅤ
[홍은채, 여, 2학년 3반, 150점]ㅤ
[LOW]ㅤ
[이효리, 여, 1학년 2반, 50점]ㅤ
[오채원, 여, 2학년 2반, 50점]ㅤ
- Map의 key로 enum 클래스 Level을 지정하고
groupingBy()로 점수별로 그룹화
System.out.printf("%n3. 단순그룹화 + 통계(성적별 학생수)%n");
Map<Student3.Level, Long> stuCntByLevel = Stream.of(stuArr)
.collect(groupingBy(s -> {
if (s.getScore() >= 200) return Student3.Level.HIGH;
else if (s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
}, counting()));
for (Student3.Level key : Student3.Level.values())
System.out.printf("[%s] - %d명%n", key, stuCntByLevel.get(key));
System.out.println();
- 단순그룹화 + 통계(성적별 학생수)
[HIGH] - 8명
[MID] - 8명
[LOW] - 2명
- 2번과 같이 점수별로 enum 클래스의 3개 값으로 그룹화하고 counting()을 통해 각 그룹별 학생 수 카운팅
System.out.printf("%n4. 다중그룹화(학년별, 반별)");
Map<Integer, Map<Integer, List<Student3>>> stuByHakAndBan =
Stream.of(stuArr)
.collect(groupingBy(Student3::getHak,
groupingBy(Student3::getBan)
));
for (Map<Integer, List<Student3>> hak : stuByHakAndBan.values()) {
for (List<Student3> ban : hak.values()) {
System.out.println();
for (Student3 s : ban)
System.out.println(s);
}
}
- 다중그룹화(학년별, 반별)
[김코딩, 남, 1학년 1반, 300점]ㅤ
[정수민, 여, 1학년 1반, 250점]ㅤ
[오정호, 남, 1학년 1반, 200점]ㅤ
[김선미, 여, 1학년 2반, 150점]ㅤ
[정주일, 남, 1학년 2반, 100점]ㅤ
[이효리, 여, 1학년 2반, 50점]ㅤ
[이정현, 여, 1학년 3반, 100점]ㅤ
[유정선, 여, 1학년 3반, 150점]ㅤ
[강호동, 남, 1학년 3반, 200점]ㅤ
[이수근, 남, 2학년 1반, 300점]ㅤ
[김미희, 여, 2학년 1반, 250점]ㅤ
[최시원, 남, 2학년 1반, 200점]ㅤ
[박지원, 여, 2학년 2반, 150점]ㅤ
[안세훈, 남, 2학년 2반, 100점]ㅤ
[오채원, 여, 2학년 2반, 50점]ㅤ
[임희민, 여, 2학년 3반, 100점]ㅤ
[홍은채, 여, 2학년 3반, 150점]ㅤ
[신정우, 남, 2학년 3반, 200점]ㅤ
- 학년을 key로 해서 그룹화하고 이 value 값을 다시 반을 key로 해서 그룹화한 다중그룹화
System.out.printf("%n5. 다중그룹화 + 통계(학년별, 반별 1등)%n");
Map<Integer, Map<Integer, Student3>> topStuByHakAndBan =
Stream.of(stuArr)
.collect(groupingBy(Student3::getHak,
groupingBy(Student3::getBan,
collectingAndThen(
maxBy(comparingInt(Student3::getScore))
, Optional::get
)
)
));
for (Map<Integer, Student3> ban : topStuByHakAndBan.values())
for (Student3 s : ban.values())
System.out.println(s);
- 다중그룹화 + 통계(학년별, 반별 1등)
[김코딩, 남, 1학년 1반, 300점]ㅤ
[김선미, 여, 1학년 2반, 150점]ㅤ
[강호동, 남, 1학년 3반, 200점]ㅤ
[이수근, 남, 2학년 1반, 300점]ㅤ
[박지원, 여, 2학년 2반, 150점]ㅤ
[신정우, 남, 2학년 3반, 200점]ㅤ
- 학년별로 나누고 다시 반별로 나눈 후 그 중 점수가 가장 높은 학생을
maxBy()를 통해 추출
System.out.printf("%n6. 다중그룹화 + 통계(학년별, 반별 성적그룹)%n");
Map<String, Set<Student3.Level>> stuByScoreGroup = Stream.of(stuArr)
.collect(groupingBy(s -> s.getHak() + "-" + s.getBan(),
mapping(s -> {
if (s.getScore() >= 200) return Student3.Level.HIGH;
else if (s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
}, toSet())
));
Set<String> keySet = stuByScoreGroup.keySet();
for (String key : keySet) {
System.out.println("[" + key + "]" + stuByScoreGroup.get(key));
}
}
}
- 다중그룹화 + 통계(학년별, 반별 성적그룹)
[1-1][HIGH]ㅤ
[2-1][HIGH]ㅤ
[1-2][MID, LOW]ㅤ
[2-2][MID, LOW]ㅤ
[1-3][MID, HIGH]ㅤ
[2-3][MID, HIGH]ㅤ
- 학년별로 그룹화 후 다시 반별로 그룹화하는게 아니라
s -> s.getHak() + "-" + s.getBan()하나의 문자열을 만들어서 이를 key 값으로 그룹화하고 각 그룹별 학생들의 점수에 대해 enum 클래스의 3개 값(HIGH, MID, LOW)으로 나눈 값을 value로 저장
