1. 파이썬 문법
어제 밤에 백준 기초 문제들을 풀다 구글링한 문법들을 정리.
1) 슬라이싱
string, list 등에서 활용가능하다. 간단하게 string으로 예시
my_string = "hello, world"
# [시작인덱스:종료할인덱스+1:증가폭]
# 아무것도 넣지않으면 자동으로 시작과 끝을 지정해준다.
my_string[7::] # world
my_string[:5:] # hello
my_string[::2] # hlo ol
# 증가폭을 -1로 설정하면 뒤집어준다
my_string[::-1] # dlrow ,olleh
my_string[4::-1] # olleh
my_string[:6:-1] # dlrow2) list.count()
list에서 특정값이 몇개 있는지 세어준다
my_list = [1,54,6,2,2,4,24]
my_list.count(2) # 2
my_list.count(0) # 02. Vanilla JS로 SPA 만들기
튜터님의 특강이 있었다.
특강 내용중 나에게 새로운 개념과 핵심 개념을 정리해본다.
1) MPA / SPA
[1]MPA
최초 클라이언트 init 요청에 서버는 HTML을 보내준다.
이후 클라이언트 요청에 의해 HTML을 다시 서버에서 받아 랜더링을 진행한다.
[2]SPA
최초 클라이언트 init 요청에 서버는 HTML을 보내준다.
이후 클라이언트 요청에 의해 JSON을 보내준다.
2) Hashed url vs Non-hashed url
https://example.com/abc/#def
해시(#) 이전까지의 url을 브라우저에서 서버에서 데이터 또는 문서를 GET요청하는것으로 인식
해시처리를 하지 않으면, 새로고침할 때 서버에서 404를 보내준다.
해시는 window.location.hash로 접근 가능.
3. 자료구조
1) 트리에서의 탐색
[1] BFS ( Breadth-First Search, 너비 우선 탐색 )
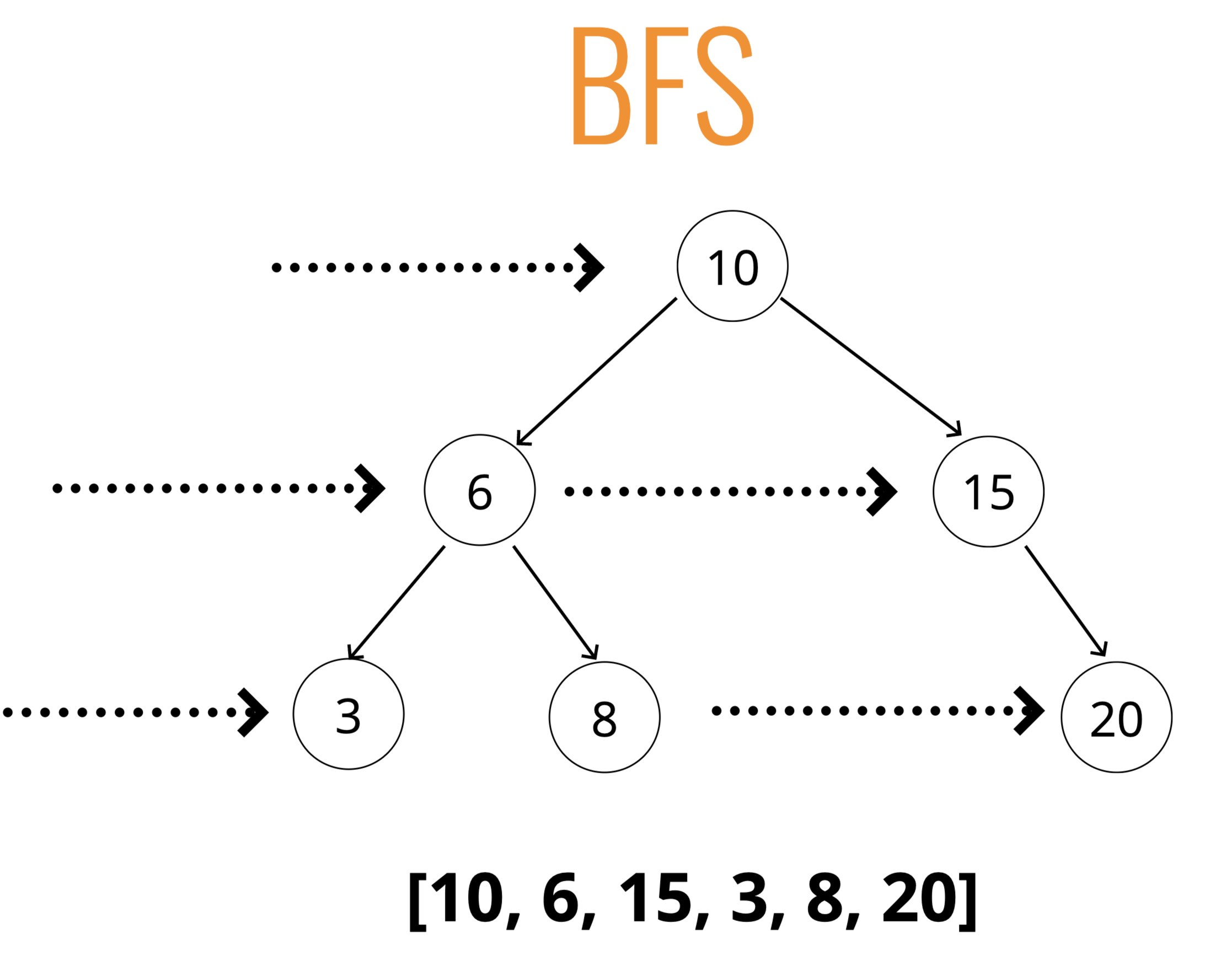
아래 레벨로 내려가기 전, 같은 레벨의 노드부터 탐색.
즉, Child노드를 보기 전, Sibling 노드들부터 탐색 후 Child노드를 탐색하는 방식.
[2] DFS ( Depth-First Search, 깊이 우선 탐색 )
트리에서의 DFS는 전위(Pre-Order)순회, 중위(In-Order)순회, 후위(Post-Order)순회로 나뉜다.
- 전위순회
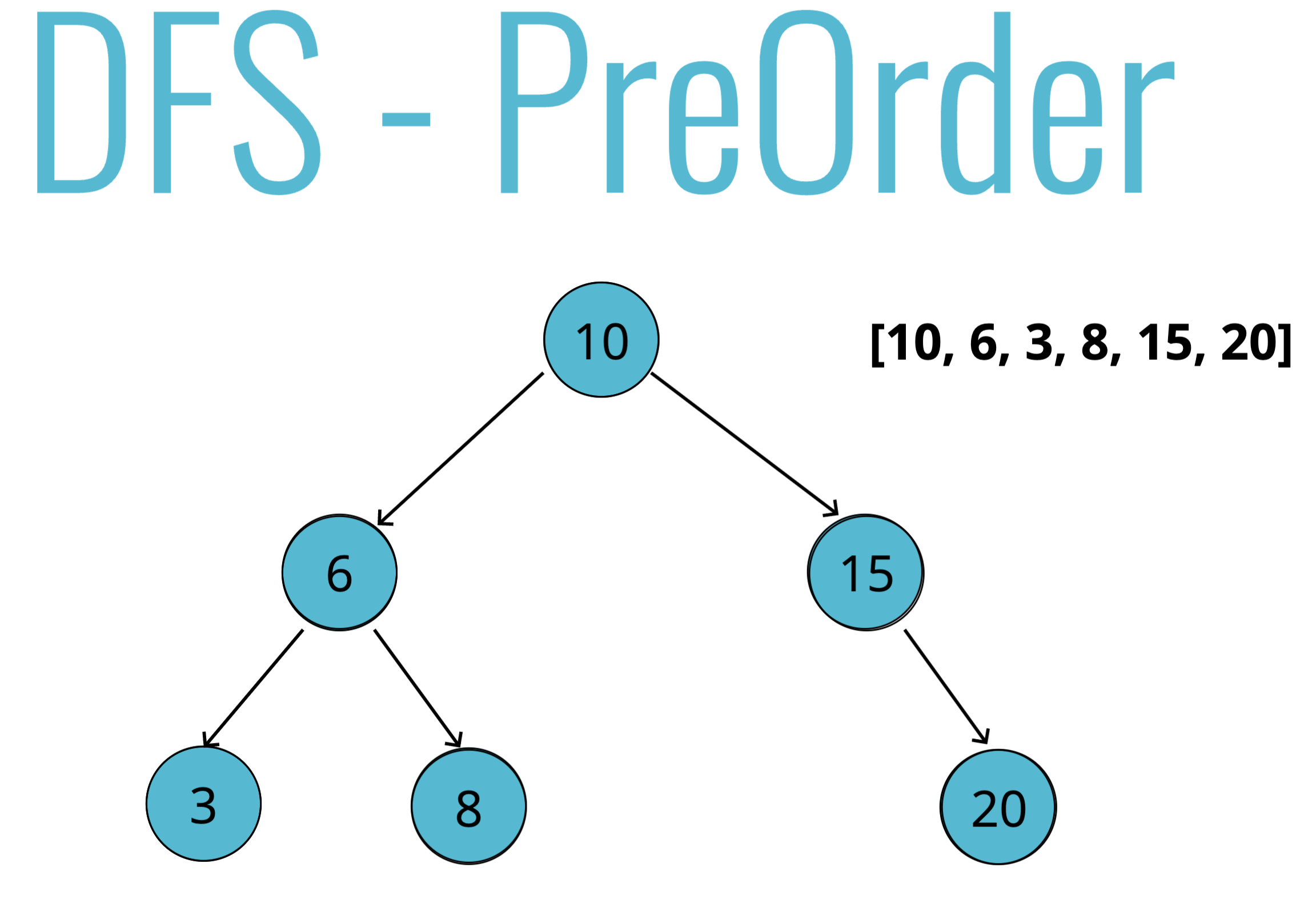
- 루트에 방문 후 왼쪽먼저 탐색 후 방문, 오른쪽 탐색 후 방문.
def traverse(node): data.push(node.value) if(node.left): traverse(node.left) if(node.right): traverse(node.right)
- 루트에 방문 후 왼쪽먼저 탐색 후 방문, 오른쪽 탐색 후 방문.
- 후위순회
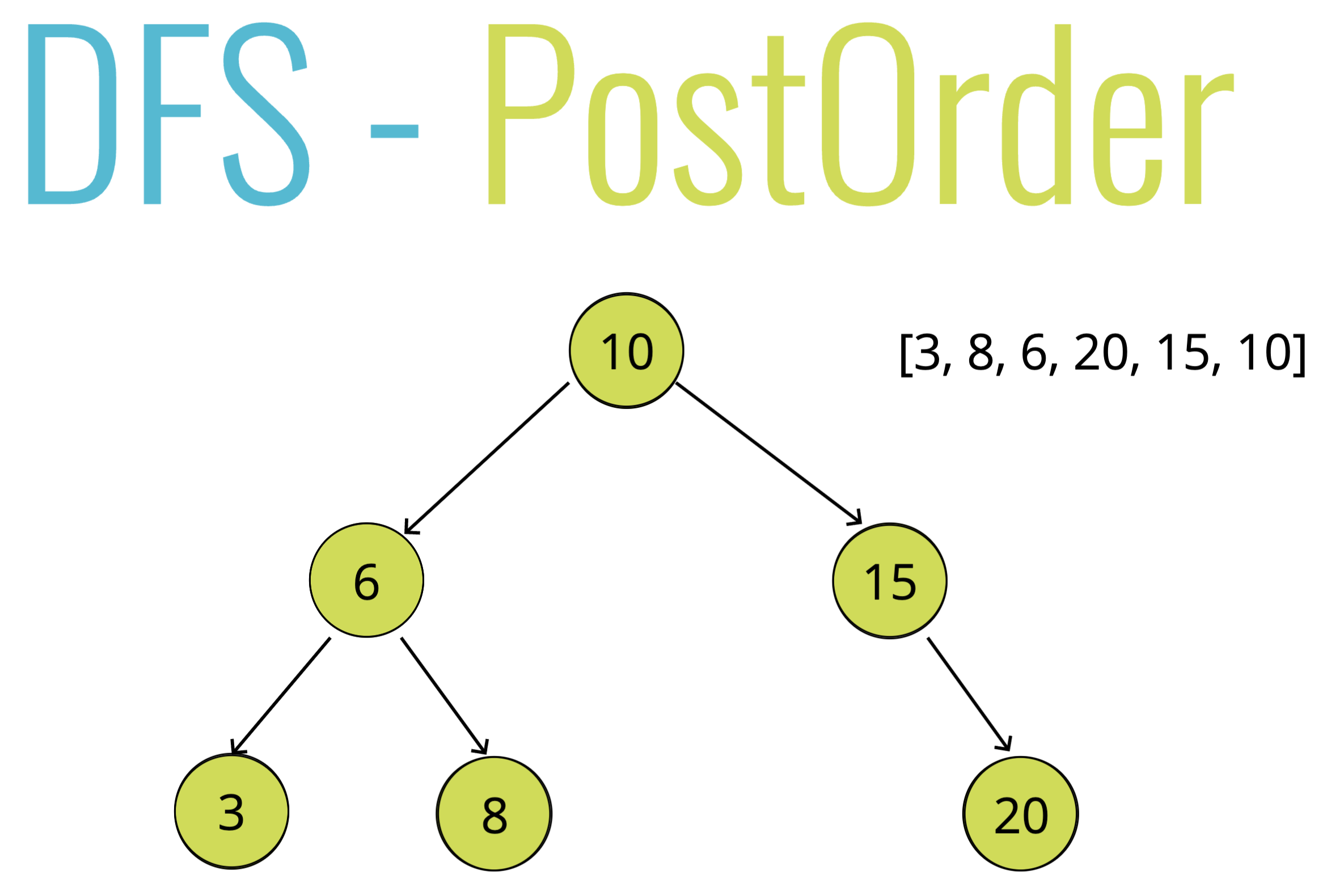
- 루트에서 왼쪽먼저 탐색, 계속 왼쪽 탐색 후 왼쪽 없을 시 왼쪽 방문, 둘다 없을 시 부모노드의 오른쪽 탐색, 왼쪽탐색...... 모든 자식노드를 방문한 후 부모노드 방문
def traverse(node): if(node.left): traverse(node.left) if(node.right): traverse(node.right) data.push(node.value)
- 루트에서 왼쪽먼저 탐색, 계속 왼쪽 탐색 후 왼쪽 없을 시 왼쪽 방문, 둘다 없을 시 부모노드의 오른쪽 탐색, 왼쪽탐색...... 모든 자식노드를 방문한 후 부모노드 방문
- 중위순회
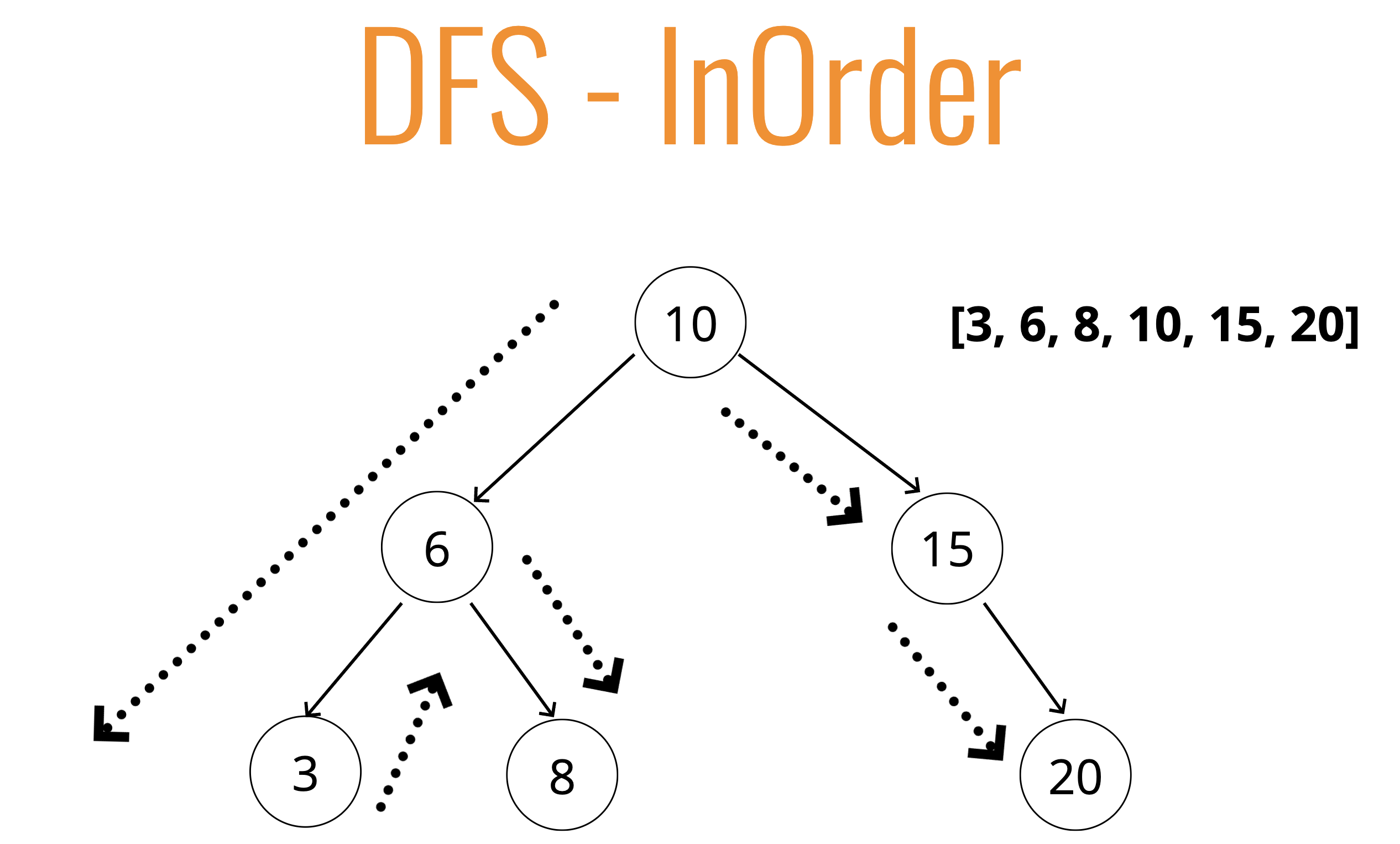
- 루트에서부터 왼쪽 먼저 탐색, 왼쪽이 없을 시 왼쪽 방문, 그 후 부모노드 방문 후 오른쪽 노드 탐색...
def traverse(node): if(node.left): traverse(node.left) data.push(node.value) if(node.right): traverse(node.right)
- 루트에서부터 왼쪽 먼저 탐색, 왼쪽이 없을 시 왼쪽 방문, 그 후 부모노드 방문 후 오른쪽 노드 탐색...
BFS vs DFS
두 탐색방법 모두 같은 T(N)을 가진다, 하지만 공간복잡도가 다르다.
BFS의 경우 넓게 퍼진 트리일 때 큐에 수많은 정보들을 저장해야하기 때문에 불리하다.
DFS의 경우 얇고 깊은 트리일 때 콜스택에 수많은 재귀함수가 쌓이게 되므로 불리하다.
중위 vs 전위 vs 후위 순회
중위순회는 이진 탐색 트리 일 때, 오름차순의 리스트를 얻을 수 있다.
전위순회는 이진 탐색 트리 일 때, 획득한 리스트로 다시 트리를 재구성하기 쉽다.
2) 힙(heap)
힙은 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리를 베이스로 한 자료구조.
힙을 배우는 이유
- 힙은 우선순위 큐를 만들기 위해 사용된다.
- 그래프 순회 알고리즘에 사용된다.
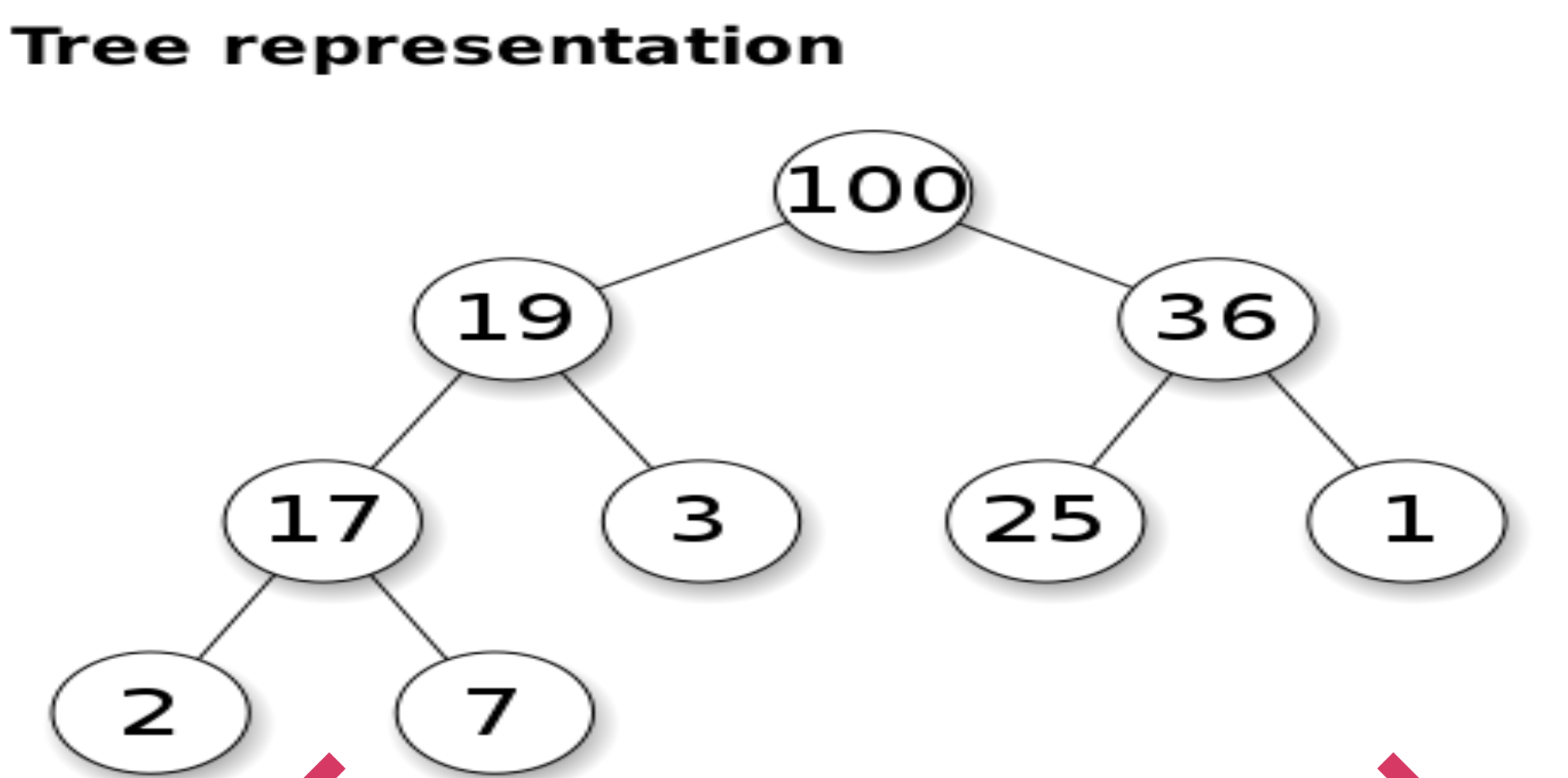
[1] 최대 이진 힙(Max Binary heap)
- 최대 이진 힙에서는 부모가 언제나 자식보다 크다.
- 하지만, 형제 노드 사이에는 관계가 정의되지 않는다.
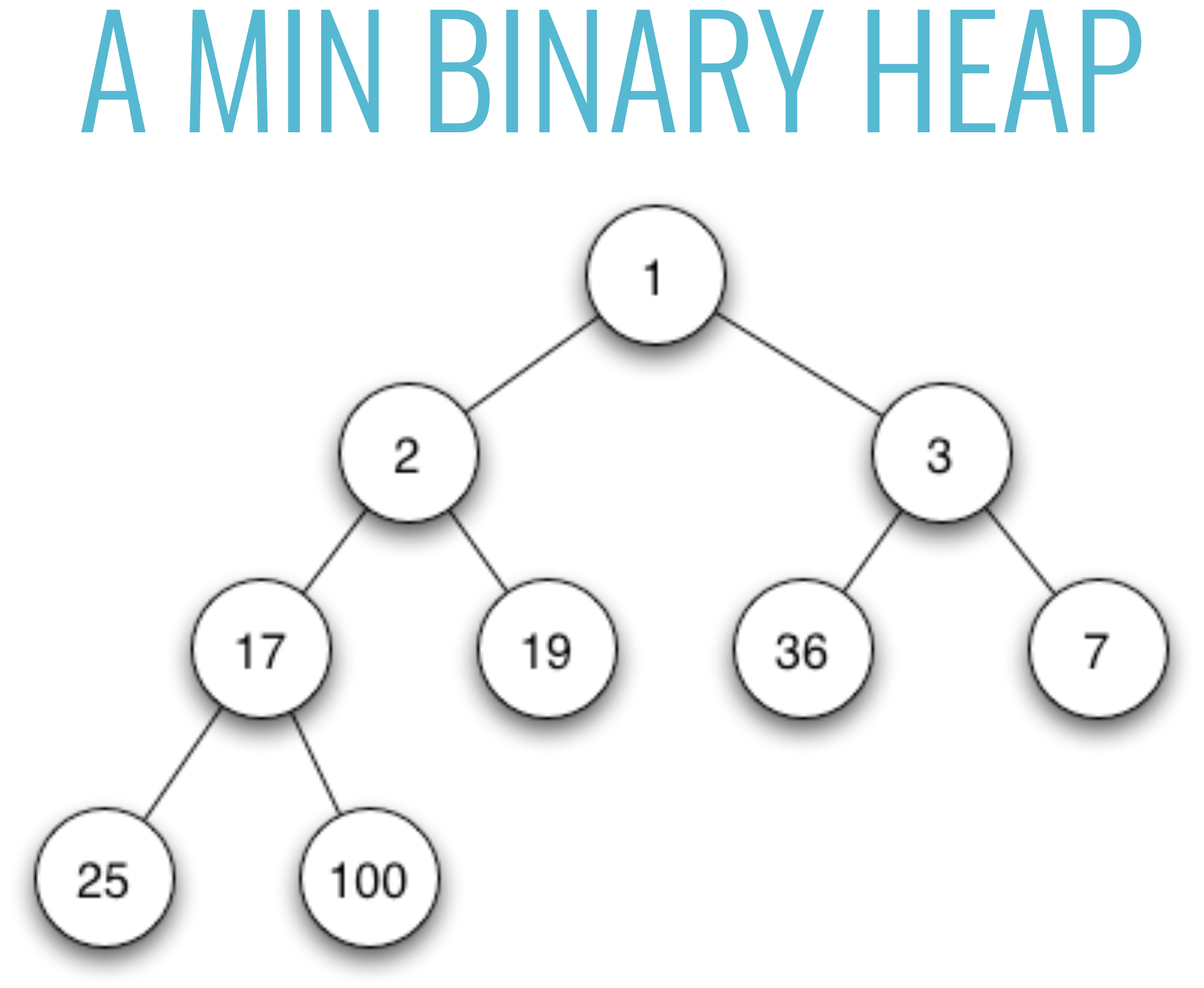
[2] 최소 이진 힙(Min Binary heap)
- 최소 이진 힙에서는 부모가 언제나 자식보다 작다.
- 마찬가지로, 형제 노드 사이에는 관계가 정의되지 않는다.
[3] 힙의 특성
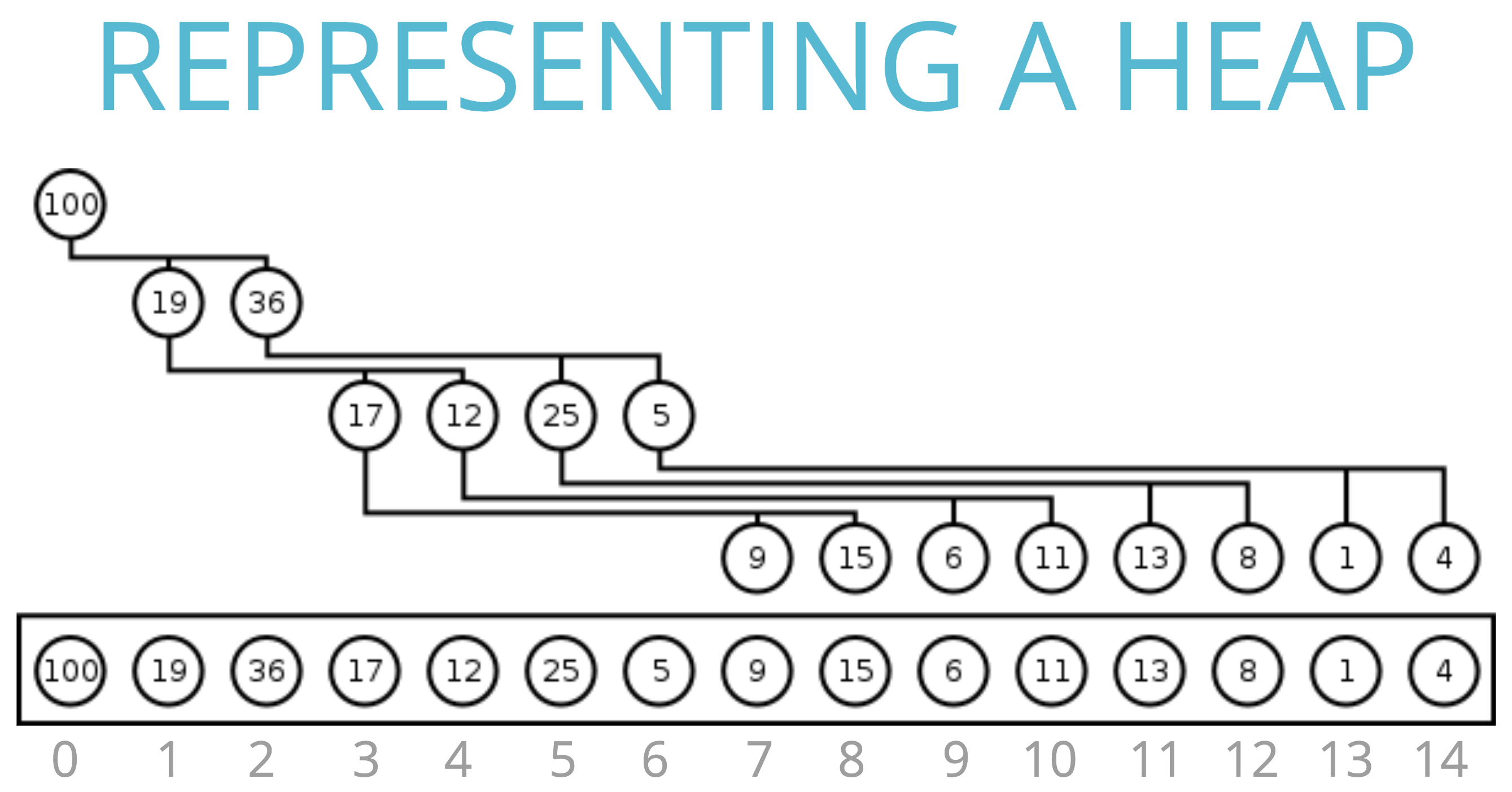
위 사진과 같이 힙이 배열에 저장되어 있으면, 부모 노드의 인덱스가 N일 때 왼쪽 자식 노드의 인덱스는 2N+1, 오른쪽 자식 노드는 2N+2가 된다.
반대로 자식 노드의 인덱스가 N일 경우, 부모 노드의 인덱스는 floor((n-1)/2)가 된다.
4. DB특강
DB란?
좁은 의미로는 데이터의 저장소, 포괄적인 의미로는 데이터베이스 + DBMS
DBMS란?
데이터를 운영하고 관리하는 소프트웨어
관계형 데이터베이스(RDBMS)란?
관계형 데이터베이스는 데이터가 열과 행으로 저장되어 데이터 구조를 쉽게 파악하고 이해할 수 있도록 사전에 정의한 관계로 데이터를 구성하는 데이터베이스 시스템.
NoSQL이란?
SQL을 사용하는 RDBMS를 제외한 다른 데이터베이스를 NoSQL이라고 합니다.
5. 내일 할 것
- 우선 순위 큐 정리
- 그래프 정리
- 캠프에서 지급해준 퍼블리싱강의, 깃 강의 듣기

핵심만 깔끔하게 정리하셨네요 ㅎㅎ좋습니다!