생존 분석(Survival Analysis) 이론이란?
생존 분석은 영어로 Survival Analysis 라고 하며, 어떤 사건의 발생 확률을 시간이라는 변수와 함께 생각하는 통계 분석 및 예측 기법이다. 보통 의료계 임상 실험에서 주로 사용되는 이론이며, IT 업계에서도 사용될 수 있는데 대표적으로 서비스 고객의 이탈확률을 구하고자 할 때 사용된다. 생존 분석 이론에는 몇 가지 주요 개념들이 있는데 이는 다음과 같다.
-
시간 (time) : 생존분석을 시행할 때 주로 시간 경과에 따른 위험도나 생존도를 구하는데 이 때 두는 독립변수로 시간이 있다. 상대적 시간이며, 분석하고자 하는 대상을 관찰하기 시작한 시점부터 0으로 카운트 됨
-
사건 (event) : 보통 생존의 반대인 이탈, 죽음 등을 가리키며, 이것들이 생존 분석으로 분석하려는 대상이 되어 시간과 함께 종속 관계를 맺음. 사건은 한번만 일어나게 되며 0과 1로 보통 구분이 됨
-
중도절단 (censoring / censored)
- 우측 중도절단 (Right censored) : 어떤 특정 기간 내에도 사건이 발생을 하지 않았거나, 기타 다양한 이유로 관찰이 종료된 것을 의미
- 좌측 중도절단 (Left censored) : 대상 관찰 전에 사건이 일어났거나 (영어에서는 event occurred 또는 failed to the event 라고 표현함) 기대했던 최소한의 기간보다 생존 시간이 더 짧았던 경우
-
생존함수 (Survival function) : 어떤 관찰 대상이 특정 기준 시간보다 더 늦게 사건이 발생하거나 일어나지 않을 확률을 계산하는 함수
-
위험함수 (Hazard function) : 특정 기간 t에 대상에 사건이 발생할 확률. t 전 시간까지는 사건이 발생해서는 안됨
-
누적위험함수 ( Cumulative hazard function) : 0에서 t 시간 사이의 위험함수를 적분한 값이며, 이는 t시점까지 사건이 발생할 확률을 모두 더한 것과 같다.
생존 함수 추정법 : 단변량 추정법? 다변량 추정법?
1.Univariate method(단변량 추정법)
1.1 Terminology: Univariate
통계적 용어로 단순(simple), 다중(multiple), 단변량(univariate), 다변량(multivariate)이 있으며 어떤 결과값 Y(보통 종속변수라고 하며, 결과변수, 반응변수라고도 불린다)가 하나일 때 이를 단변량이라고 한다.이 종속변수가 두개 이상이면 다변량 분석이 된다. 공변량(covariate)으로 정의 되는 X(독립변수, 설명변수, 예측변수, 위험 인자)가 하나일 때는 단순이고 두 개 이상이면 다중이라고 한다. 이렇게 말로 해서는 단번에 이해가 잘 되지 않으니 시각 자료를 이용해 살펴보자.
이 용어 설명에 관해 잘 정리해 놓은 블로그 포스트가 있어 아래 소스와 포스트 맨 마지막 reference에 출처를 남김과 동시에 인용을 하며 설명을 하려고 한다. 블로그 포스트 저자인 타고싶다 님에 따르면(2018)
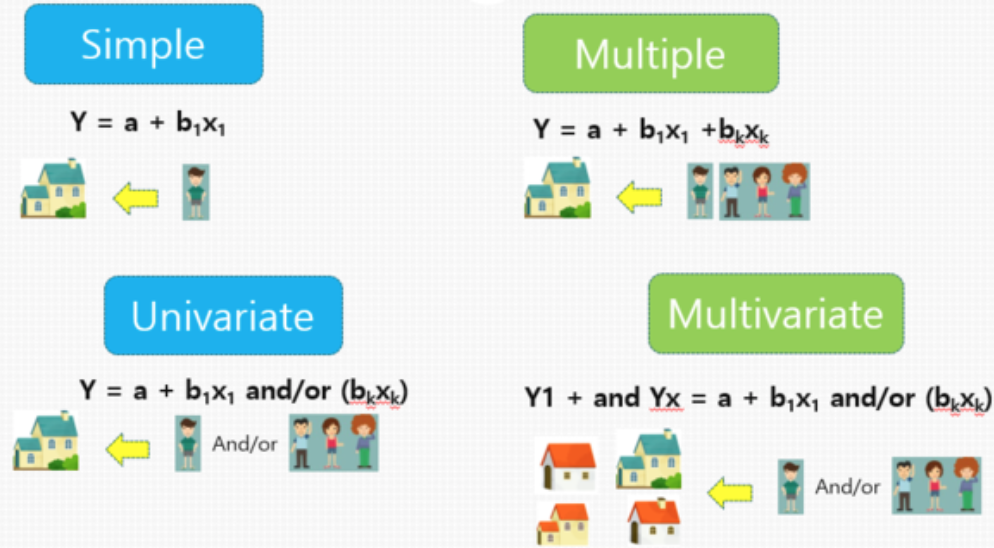
부동산을 예로 들어 가족의 수와 주택의 수를 가지고 이해해볼 수 있다. 주택은 결과값 Y라고 가정하며 가족 구성원 수는 독립변수 X라고 할 때 단순분석(simple)은 가족수 1명이 1집에 있는 것이다. 가족수 2명 이상이 하나의 집에 있으면 다중분석(multiple)이라고 할 수 있다. 변량 분석은 가족수와 관계없이 단변수 다변수 각각 집이 1개일 때와 2개 이상일 때를 지칭하는데, 즉 단변량(univariate)은 세대원이 몇 명이던 1주택자인 케이스, 다변량(multivariate)은 세대원이 몇 명이건 다주택자인 케이스를 말하는 것이다.
따라서 생존분석에서의 단변량은 시간 변화에 따라 하나의 결과 변수(종속 변수)가 생존에서 나타나는 것을 말하며, 여기에 회귀(regression) 분석이 더해져서 단순선형회귀분석으로 사용되며 대표적인 방법으로는 kaplan-Meier 추정법이 있다. 다변량과 관련한 추정법은 2번째 문단에서 다시 살펴보자.
1.2 Kaplan-Meier 추정법 (KM)
어떤 데이터가 주어졌을 때 이 데이터의 생존확률과 위험확률은 아직 구해지지 않은 미정의 truth이다. 따라서 데이터에 생존 분석 기법들을 사용하여 이 확률들을 구하기 위한 함수를 추정해야 하는데 이 때 기본적으로 사용하는 것이 미국의 통계학자 Paul Meier와 Edward L. Kaplan이 개발한 Kaplan-Meier Estimation, 우리 말로 카플란-마이어 추정이다. 이 추정법은 관찰 시간이 짧을 때 부터 긴 순서로 나열해놓고 각 사건이 발생한 시점에서의 사건이 일어날 확률을 계산하는 비모수적(non-parametric) 방법이며 각 시점마다 구간 생존율을 구하여 이들을 누적시킴으로써 생성된 empirical cumulative density function (eCDF)을 사용하여 누적 생존확률을 추정한다. 표본 수가 적을 때도 충분히 사용할 수 있어 생존분석법들 중 널리 사용되고 있다. Kaplan-Meier를 이용한 생존분석은 생존곡선들 간의 차이 비교 및 검정, 중앙값이나 평균 생존 기간의 차이 판별에 사용된다. 아래 그래프는 데이터가 주어졌을 때 이를 시간 축에 따라 사건 발생을 나타낸 것이며, 파란색 선은 (right) censored data를 의미한다.
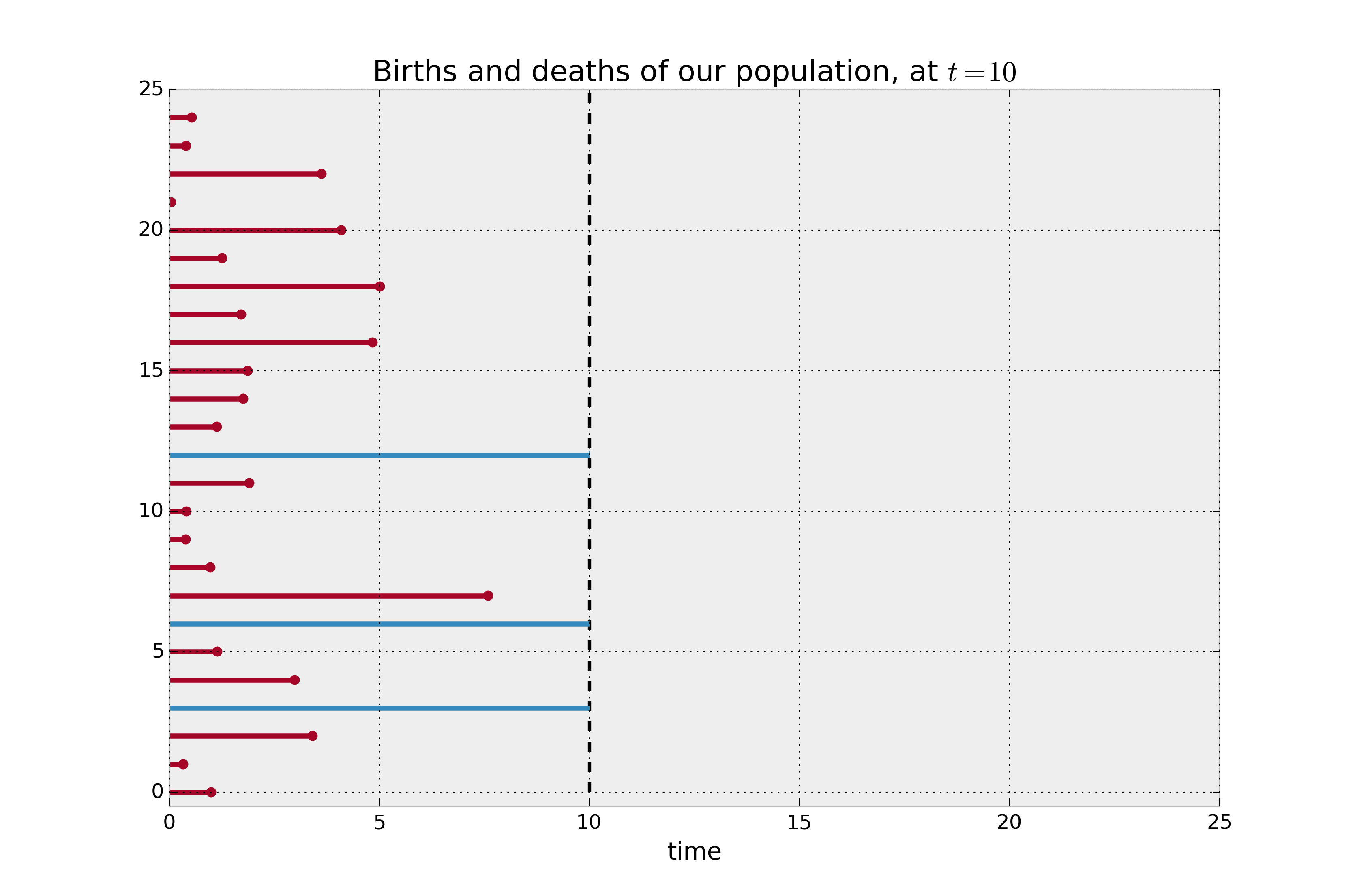
한편, 중도절단된 데이터도 다른 통계방법과 다르게 생존분석에서는 추정할 때 함께 포함하는 것이 일반적이며, 이 데이터를 제외하면 추정을 통한 추정치가 편향되고 낮게 측정될 가능성이 높아진다. 그리하여 이 중도절단 된 데이터를 포함하여 추정하는 케플란 마이어 추정법이 다른 통계 기법에 비해 두드러지는 특징을 가지고 있다. 이 추정을 통해 케플란 마이어 생존곡선(Kaplan Meier Estimate Curve)이라는 곡선을 만들 수 있으며, 곡선을 만들 때 좌표는 사건 발생 시간을 x축으로, 추정된 생존 확률을 y축으로 갖는다. 생존 확률 y는 0에서 1사이의 값을 가지며 보통 하향곡선을 그린다. 생존 곡선 두개가 있을 때 이 곡선을 비교하는 것은 임상에서 중요하다. 단순히 시각화만 하는 것이 아닌, 통계적인 유의성을 검정하기 위해 곡선간의 차이를 정량화 할 필요가 있다. 이를 위한 방법 중 하나가 로그순위법(log-rank method)이다.
1.3 로그순위법 (Log-rank method)
로그순위법의 원리는 먼저 '비교 대상간의 생존곡선에 큰 차이가 없다'라고 귀무가설을 설정하고, 실제 관측값 개수(observed count)와 사건이 일어날 법한 수(expected count)를 각 그룹별 사건 발생 시간의 카이-제곱(chi-square)을 계산하여 비교, 결과를 합산하는 방법이다.[Junyong I. 2018] 위험비(hazard ratio)를 구하는 것도 케플란 마이어 생존곡선들을 비교하는데에 도움이 된다. 그러나 위험비의 경우, 로그순위법을 사용하기 위해 조정해야 할 제약 조건 중에 하나인데, 실험 기간 동안 그 위험비는 항상 일정해야 한다. 이 조건(가정)을 "비례위험가정(Proportional hazard assumption)"이라고 하여 뒤에 나오는 내용과 연관이 되어 있다.
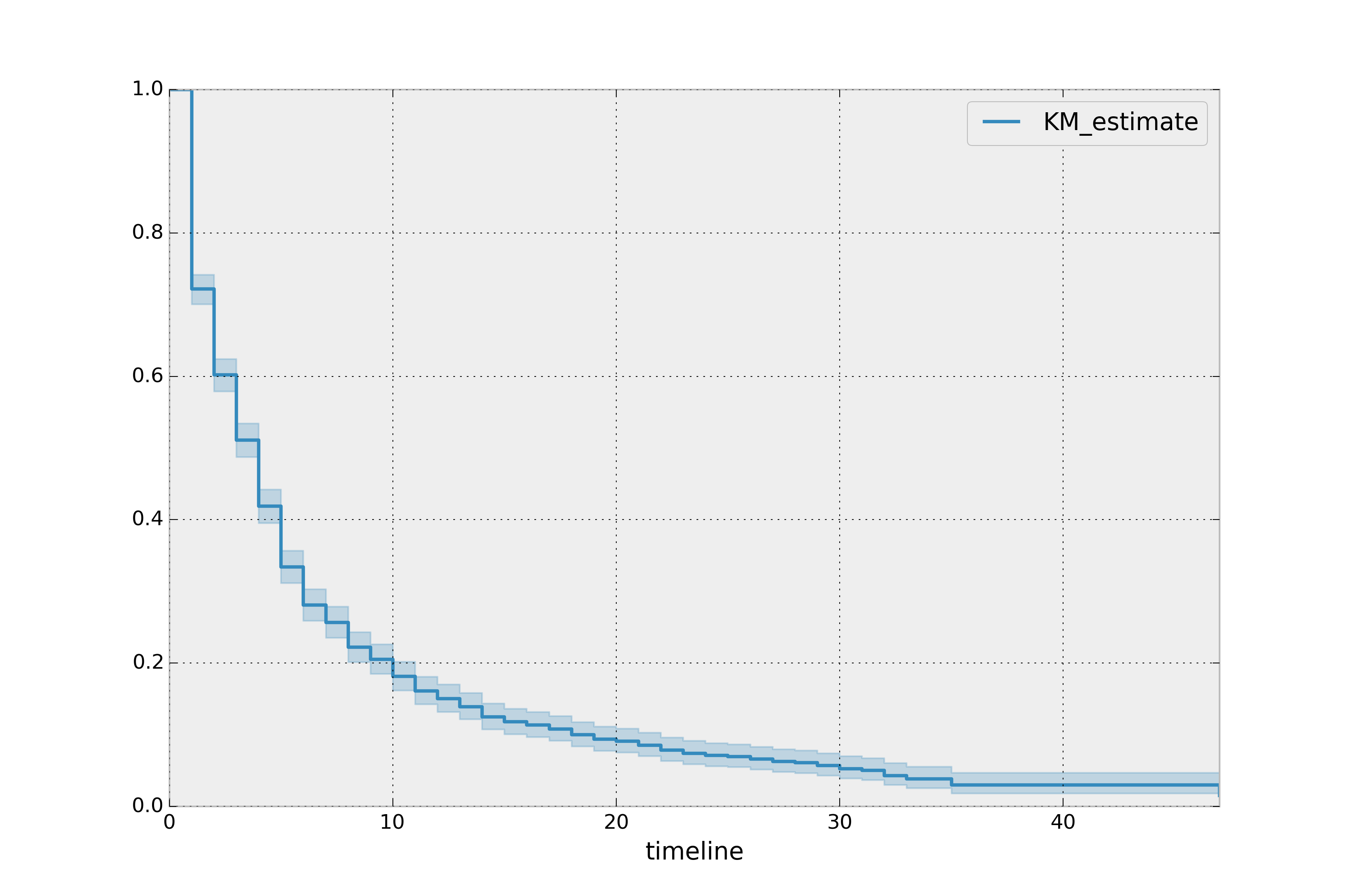
케플란 마이어 생존곡선을 분석할 때 먼저 사건과 측정 단위를 명확히 정의하고, 사망 등의 사건이 일어났음을 나타내는 계단이 많은 곡선인지, 제한된 수만을 대상으로 하여 폭이 큰 단계만 갖는 곡선인지 확인한다. 중도절단된 대상과 분포도 해석하는데에 고려해야 할 중요한 요소이다. 중도절단 된 것은 곡선에서 눈금으로 나타낸다.
어떤 모집단에서 개인의 사건까지 걸리는 시간은 전체적인 수준에서 매우 중요하다. 그러나 실제 상황에서는 사건 발생만큼 공변량(covariate, 독립변수)의 값이 중요하게 작용한다. 이 공변량 값을 미리 안다면, 개별 생존 확률을 예측하는데에 도움을 얻을 수 있다. 공변량을 고려했을 때 조건부 생존 함수를 다음과 같이 세울 수 있다.
는 사건이 발생했을 때의 시간을 나타내며, 가 공변량(covariate) 에 해당한다.
2.Multi-variate method(다변량 추정법)
2.1 Terminology : Multivariate
앞서 통계 용어들인 단변량과 다변량에 관해 간단하게 언급했었다. 다시 복습하자면, 단변량은 종속변수가 한 개인 것을 말하며, 다변량은 종속변수가 2개 이상이 것을 말한다. 다변량 분석은 보통 종속변수가 2개 이상일 때 독립변수도 2개 이상이 되는 회귀분석을 가리키며 이는 다변량 다중회귀분석(multivariae multiple regression)이라 하는데, 타고싶다 님의 블로그 글에 따르면(2018) 의학논문에서 다변량 분석을 시행했다고 하는 대다수의 논문 방법이 단변량 다중분석을 잘못 해석한 것이라고 한다. 슬슬 헷갈리기 시작한다. 무슨 말이냐 하면,
사실 대부분의 생존분석을 다루는 의학논문에서는 multiple과 multivariate을 명확히 구분하지 않고 혼용해서 쓰고 있다. 종속변수는 명확히 '시간' 하나이고 독립변수가 여럿인데 그냥 관례적으로 혼용하니 통계학자들도 그냥 그러려니 하고 받아들인다는 것이다.
IMG source from : meta-analyis naver blog post
다변량 분석, 정확히는 다항(multinorminal) 분석의 예시는 위 사진과 같다.
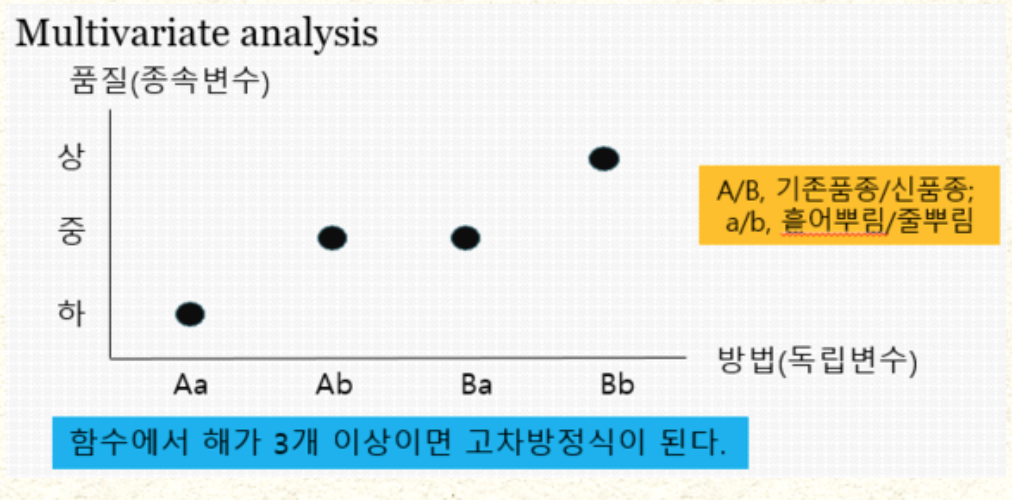
보통 이 두 가지 이상의 함수 해(근)를 해석하기 힘들기 때문에 결과 변수(종속변수)를 시간 하나로 두고 여러 독립변수들에서 결과 변수에 미치는 영향을 분석하는 방법을 쓰고 이를 생존분석에서는 다변량이라고 주로 칭하며, 대표적으로 시간과 사건 사이의 예측 회귀모형을 만드는 통계법인 콕스 비례위험모형(Cox Proportional Hazard model)이 있다.
2.2 Cox PH Model (CPH)
KM 분석은 하나의 타겟 특성 이외의 다른 factor들을 통제할 수 없다는 점에서 한계를 지녔다. 이를 보완하는 것이 cox 모형이며, 다양한 관측치들을 동시에 통제하여 사건 발생에 미치는 영향을 분석한다. David Cox가 제안한 Cox 비례 위험 모형(Cox Proportional Hazard model) 은 공변량과 생존 함수를 결합한 모델이며, 특정 분포만을 고려하지 않고 데이터의 변량(변수) 여러개가 사건 발생에 영향을 미치는 다변량(Multivariate) 생존 회귀분석법이라고 하나, 정확히는 시간이라는 종속 변수 하나만을 갖는 단변수 생존 분석법이다. 시간 종속 변수에서 어떤 시점 t까지 생존한 사람이 직후에 사망할 조건부확률은 다음과 같이 나타낼 수 있다.
여기서 β 는 각 공변량들의 계수(coefficient)로 구성된 벡터이고 는 공변량들이 0일 때 기저위험함수(baseline hazard function) 이다. 그렇게 해서 나온 위험함수 Cox의 비례위험 모형은 특별한 가정(assumption) 두 가지를 지니는데 앞서 로그순위법에서 언급하였듯 위험비가 일정하다는 비례위험가정과, 관측치(observed data)는 서로 독립적이며, 공변량이 위험 함수에 선형 곱셈 효과를 갖는 지수함수를 따라 특정 시점의 생존함수가 위험비에 대한 지수함수로 나타난다는 것이다.[Junyong I. 2018]
지수함수를 따른다는 Cox PH assumption은 개인의 위험을 로그로 만든 로그 위험이 정적인 공변량의 선형 함수여서 위험함수와 변수사이에 로그-선형관계를 가진다는 말과 같고, 시간이 지남에 따라 변하는 모집단 수준의 기저 위험이라는 것, Hazard Ratio(위험비, HR)는 시간이 경과해도 일정하다 것은 비례 위험 가정을 강조한다. 여기서 비교되는 두 실험군간의 HR=1이라는 귀무가설을 설정하고, HR이 1보다 크면 사망 위험이 증가한다는 것, 1보다 작으면 사망 위험이 감소함을 뜻하며 이 때는 대립가설을 채택한다. HR은 수식으로 나타낼 때 보통 기호 람다()를 많이쓴다.
비례위험모형을 추정한 이후로는 비례위험가정을 제대로 충족하는지 검정할 필요가 있는데, 이 가정을 검정하기 위한 방법으로는 세 가지가 있다. 첫번째로는 케플란 메이어 곡선을 통해 위험비를 비교하는 것이고, 다른 하나는 cumulative hazard function으로 martingale residual을 구하여 log minus log(LML) plot을 그려서 log-linear 관계를 검정하는 것이다. LML plot 방법은 추정된 생존함수를 두 번 로그로 변환을 한다는 것인데, 생존함수의 값이 0과 1사이의 확률이다보니 로그를 씌웠을 때 음수가 되어 여기에 minus를 취하고 다시 로그 변환을 실시하는 아이디어에 근거한다. 마지막 방법은 적합도 검정(Goodness of fit test)으로, 관측값과 추정된 생존함수에 의한 값의 차이를 비교하여 가정을 확인할 수 있다.[Junyong I. 2019 ] 이러한 검정들을 거쳐 비례위험가정을 만족하는 Cox Proportional Hazard function은 다변수 처리가 가능하다는 것과, 지수적인 회귀 생존 모형을 사용한다는 것, 상대 위험을 도출해낸다는 것과 범주형 변수, 연속형 변수 둘 다 처리가 가능하다는 특징을 지니게 된다.
만약 언급한 비례위험가정들을 만족하지 않는 다면, CoxPH model로 접근해서는 정확한 예측값을 얻기 어려우므로, 대신 time-dependent CoxPH model 이나 층화된(stratified) 콕스 모델, Gehan's generalized Wilcoxon test 등의 non-proportional hazard model을 사용해야 한다.
파이썬의 lifelines 모듈은 데이터에 관한 생존분석을 도와주는 툴인데, lifelines의 documentation을 아래와 같이 예로 들어보겠다.
# lifelines 모듈로 부터 CoxPHFitter라는 모델을 import한다.
from lifelines import CoxPHFitter
# 데이터는 다음과 같이 'T:시간'과 'E:사건'이 주어지고, weight, age 같은 연속적 변수가 주어진다고 가정하자.
df = pd.DataFrame({
'T': [5, 3, 9, 8, 7, 4, 4, 3, 2, 5, 6, 7],
'E': [1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0],
'var': [0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2],
'weights': [1.1, 0.5, 2.0, 1.6, 1.2, 4.3, 1.4, 4.5, 3.0, 3.2, 0.4, 6.2],
'month': [10, 3, 9, 8, 7, 4, 4, 3, 2, 5, 6, 7],
'age': [4, 3, 9, 8, 7, 4, 4, 3, 2, 5, 6, 7],
})
cph = CoxPHFitter()
cph.fit(df, 'T', 'E', strata=['month', 'age'], robust=True, weights_col='weights')
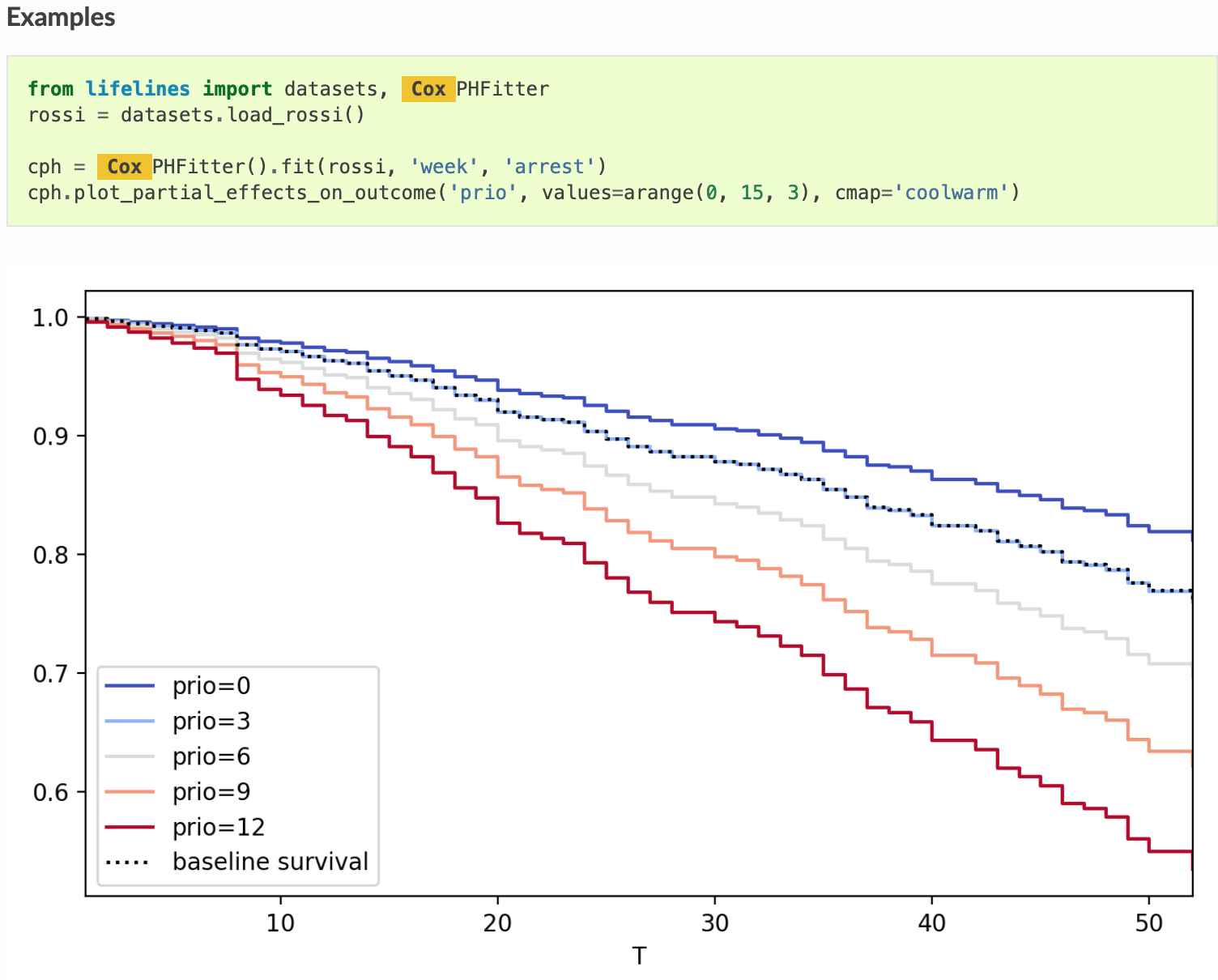
cph.print_summary()python에서는 다음과 같이 데이터에 생존분석을 적용시킨다고 이해하면 되겠다. 데이터가 위 형태와 같이 시간 변수와 사건 변수가 존재 하여야 하고, categorical 변수들은 dummy value 처리하여 위 코드의 와 같이 범주에 따른 숫자로 나타낸다. 이렇게 하였을 때 Cox PH model을 적용한 다변량 생존 함수는 아래 그래프와 같이 나타나게 된다.
1부를 마치며....
1부에서는 생존분석을 간단히 맛보는 식으로 다룰려고 했는데 쉽지 않은 것 같다. 특히 이론만 가지고 어디까지 다루고 숨을 골라야 할지가 어려웠다. 실전 코드 위주로 설명하면 더욱 잘 설명할 수 있을 텐데 분량과 블로그 포스팅 시간을 신경쓰느라 그것도 잘 엄두도 못 내겠고... 생존 분석 개념들이 이 외에도 워낙 많은데다 개인적으로 진행했던 프로젝트에서 이를 머신러닝과 딥러닝을 적용하여 다뤄보았기 때문에.. 틈틈히 차근차근 작성해 나가봐야 겠다.
References
-
타고싶다.(Jul 19, 2018). 단순, 다중, 단변량, 다변량 회귀분석. meta-analysis blog post. Retrieved from
https://m.blog.naver.com/PostView.nhn?blogId=ryul01&logNo=221322235531&proxyReferer=https:%2F%2Fwww.google.com%2F -
Choonoh,L.(2019) Survival analysis(1/3). Hyperconnect tech blog post. Retrieved from
https://hyperconnect.github.io/2019/07/16/survival-analysis-part1.html -
Junyong I, Dongkyu L.(June 2018) Survival analysis:Part I - analysis of time-to-event. Korean journal of anesthesiology. Vol.71, no. 3. pp.182-191
-
Junyong I, Dongkyu L.(Oct 2019) Survival analysis:Part II - applied clinical data analysis. Korean journal of anesthesiology. Vol.72, no. 5. pp.441-457
-
CoxPHFitter, KM.(2021) lifelines. Retrieved from
https://lifelines.readthedocs.io/en/latest/fitters/regression/CoxPHFitter.html?highlight=cox -
N. Breslow.(Mar, 1974) Covariance Analysis of Censored Survival Data. Biometrics. Vol. 30. No 1. pp. 89-99
