Indexing(인덱싱)은 데이터베이스에서 검색 속도를 빠르게 하기 위한 핵심 기술이다.
간단히 말하면, 책의 목차와 같은 역할을 한다.
✅ 인덱스(Index)란?
테이블의 특정 컬럼에 대한 검색을 빠르게 하기 위한 자료구조
- 마치 책의 목차처럼, 원하는 데이터를 빠르게 찾아갈 수 있도록 도와준다.
- 주로 WHERE, ORDER BY, JOIN, LIKE 등에 쓰이는 자주 검색되는 컬럼에 인덱스를 생성힌다.
- 인덱스는 "접두사 검색"일 때만 B-Tree 인덱스를 활용한다.
✔️ 인덱스가 없으면?
- DB는 데이터를 행(row) 단위로 모두 훑는 전체 탐색(Full Table Scan)을 한다.
- 데이터가 수천~수백만 건이면 검색이 느려짐.
✔️ 인덱스를 만들면?
- 인덱스를 먼저 조회 → 해당 위치의 행(row)을 바로 찾아감 → 속도 향상
1️⃣ 예시_MySQL console에 직접 입력하는 방법
-- 예: title 컬럼에 인덱스를 생성
CREATE INDEX idx_post_title ON post(title);- 위 코드는
post테이블의title컬럼에 인덱스를 추가한 것이다.
➡️ 언제든지 DB에 바로 적용 가능하기 때문에 → 운영 환경 / 성능 튜닝 시 권장된다.
2️⃣ 예시_Spring JPA에서 인덱스 생성 방법
✔️ 엔티티에서 인덱스 명시하기
@Entity
@Table(name = "post", indexes = {
@Index(name = "idx_post_title", columnList = "title")
})
public class Post {
@Id
private Long id;
private String title;
// ...
}- 이렇게 하면 DDL 자동 생성 시 인덱스도 같이 생성된다.
- 단,
spring.jpa.hibernate.ddl-auto=create또는update옵션이 켜져 있어야 동작한다.
➡️ JPA 자동 스키마 생성 시 함께 적용되기 때문에 → 개발 초기 / 테스트용으로 권장 된다.
✔️ 인덱스가 잘 걸렸는지 확인하는 법 (MySQL 기준)
SHOW INDEX FROM post;✅ 인덱스 남용 주의
인덱스는 조회 성능을 높이지만 단점도 있다:
| 장점 | 단점 |
|---|---|
| 빠른 검색 속도 | 인덱스가 많아질수록 INSERT/UPDATE 성능 저하 |
| 정렬이 빠름 | 디스크 공간 사용량 증가 |
| 특정 조건에만 도움 | 조건이 모호하면 인덱스 무시될 수 있음 |
✅ 그럼 언제 쓰나?
- WHERE 조건 자주 쓰이는 컬럼
- 정렬/필터링 자주 하는 컬럼
- JOIN 조건으로 자주 쓰이는 외래 키 컬럼
- LIKE 'abc%' 패턴 (접두사 기반 검색)
LIKE '%abc'← 이런 건 인덱스를 사용 못할 수도 있음 (접미사는 인덱스 미적용 가능)
✅ 정리
| 항목 | 설명 |
|---|---|
| 정의 | 특정 컬럼에 대해 빠르게 검색할 수 있게 만든 데이터 구조 |
| 생성 방법 (JPA) | @Index 사용 or DB 직접 생성 |
| 효과 | 검색 성능 향상 |
| 주의 | 너무 많은 인덱스는 오히려 성능 저하 |
📍 검색 API 개선 방식으로 인덱스 더 이해하기
게시글 제목(title)을 기반으로 하는 검색 API를 개선하는 케이스를 전제로 인덱싱을 더 이해해보았다.
검색 기능은 유저 경험에 직접적인 영향을 주는 핵심 요소이기 때문에 검색 기능에 인덱스를 적용해보았고,
이번 인덱스 최적화를 통해 실시간 검색 처리 속도를 획기적으로 향상시킬 수 있었다.
1. 개선 대상 쿼리
SELECT * FROM post WHERE title LIKE '롤%';
선텍 이유:
/api/v1/posts/search?keyword=롤형태로 사용자가 게시글 제목 검색을 자주 수행함post테이블의title컬럼에 대해LIKE조건으로 검색이 자주 발생- 전체 테이블 스캔(full scan) 발생 → 대용량 데이터에서 성능 저하
2. 인덱스 설정 DDL 쿼리
CREATE INDEX idx_post_title ON post(title);
idx_post_title: 제목(title) 컬럼에 대한 일반 인덱스- 접두사 검색(
LIKE '롤%')에 B-Tree 인덱스가 활용됨
➡️ Sprin JPA에서는 어노테이션으로 DDl 생성 시점에 이 쿼리를 이미 인덱스도 자동 생성되기 때문에 쿼리를 작성할 필요 없다.
3. 쿼리 성능 비교
테스트 환경 : 데이터 100만건 삽입할 때
| Before(인덱스❌) | After(인덱스⭕) |
|---|---|
EXPLAIN SELECT * FROM post WHERE title LIKE '롤%'; | EXPLAIN SELECT * FROM post WHERE title LIKE '롤%'; |
type: ALL | type: range |
key: NULL | key: idx_post_title |
rows: 1000000 | rows: 50 (예시) |
| ➡️ Full Table Scan 발생 | ➡️ 인덱스 스캔 → 검색 속도 향상 |
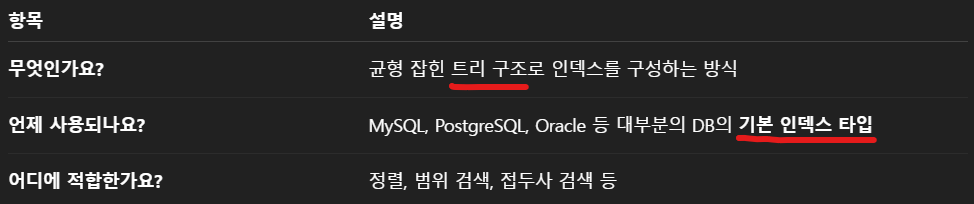
✅ B-Tree 인덱스란?
B-Tree 인덱스는 MySQL을 포함한 대부분의 RDBMS(관계형 데이터베이스)에서 기본적으로 사용하는 인덱스 방식을 말한다.
-
데이터를 정렬된 상태로 트리 구조에 저장하는 방식 → 데이터 검색, 삽입, 삭제가 빠르다.
-
"Balanced" → 트리의 높이가 균형을 유지해서 탐색 성능이 일정하게 유지됨
-
"Tree" → 이진 탐색보다 더 많은 자식을 가질 수 있어서 대용량 데이터 처리에 적합
 |
|---|
- 쓰면 좋은 상황:
WHERE,ORDER BY,LIKE 'abc%',BETWEEN등
✔️ 예시
title 컬럼 값이 아래와 값다고 했을 때
Apple, Banana, Cherry, Dog, Elephant, Fox
이걸 그냥 저장하면 검색 시 순차적으로 전부 훑어야 한다 → 느림
하지만 B-Tree 인덱스를 걸면, 다음과 같이 저장된다
Dog
/ \
Banana Fox
/ \ /
Apple Cherry Elephant
- Dog을 기준으로 왼쪽에는 더 작은 값, 오른쪽은 큰 값
- 검색 시 Fox를 찾고 싶으면 → Dog → 오른쪽 → Fox → 끝!
