✅ 영속성 컨텍스트란?
JPA에서 Entity Manager가 관리하는 엔티티 객체들이 존재하는 메모리상의 작업 공간을 말한다.
→ 다르게 말하면, 데이터베이스와 애플리케이션 사이의 객체 상태를 효율적으로 관리하는 1차 캐시이자 변경 감지 매커니즘.
→ 또 다르게 말하면, DB와의 직접 통신 없이도 엔티티의 상태를 관리할 수 있게 해주는 캐시이자 트래킹 영역.
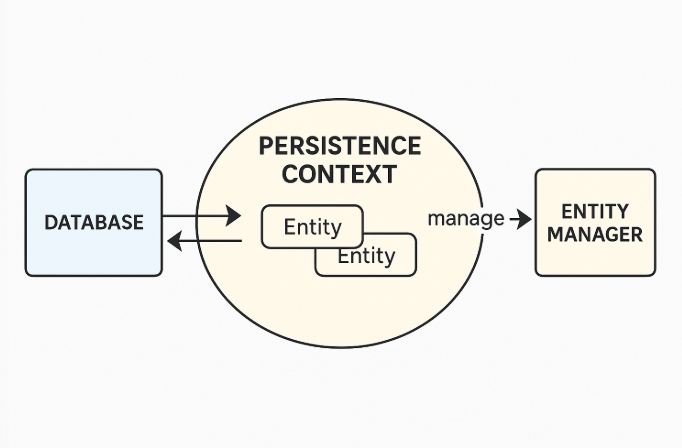
✔️ 영속성 컨텍스트(Persistence Context)의 주요 특징
- 1차 캐시
- 엔티티 동일성 보장
- 변경 감지
- 지연 쓰기
- Flush
- 지연 로딩
- 영속성 컨텍스트 생명주기
1️⃣ 1차 캐시 (First-Level-Cache)
- find() 등으로 엔티티를 조회하면 DB에서 직접 가져오는 게 아니라, 먼저 1차 캐시(Persistence Context)를 확인한다.
- 같은 엔티티를 여러 번 조회해도 쿼리는 한 번만 실행된다.
User u1 = em.find(User.class, 1L); // → DB 조회
User u2 = em.find(User.class, 1L); // → 1차 캐시에서 반환 (쿼리 없음)
System.out.println(u1 == u2); // true
2️⃣ 엔티티 동일성 보장
- 동일한 식별자(ID)를 가진 엔티티는 트랜잭션 동안 하나의 객체만 유지된다 (
==비교 가능)
3️⃣ 변경 감지 (Dirty Checking)
- 영속성 컨텍스트에 있는 엔티티의 속성을 변경하면, 트랜잭션이 커밋되는 시점에 자동으로 변경된 내용을 감지해서 SQL
update를 실행한다.
@Transactional
public void updateUserName(Long id) {
User user = em.find(User.class, id); // 1차 캐시에 로딩됨
user.setName("NewName"); // setter로 변경
// → 별도 update 호출 없이 트랜잭션 커밋 시 자동 update 쿼리 실행
}
4️⃣ 지연 쓰기 (Deferred Write)
persist()등으로 엔티티를 저장해도 즉시 DB에insert쿼리 보내지 않고, 트랜잭션 커밋 직전에 쿼리 모아서 한 번에 처리 (Flush) 한다.
5️⃣ Flush
- 영속성 컨텍스트에 있는 변경 내용을 DB에 반영하는 시점.
- 커밋 시 자동 호출되며, 수동 호출도 가능(
em.flush();)
6️⃣ 지연 로딩 (Lazy Loading)
- 연관된 엔티티를 실제로 사용하는 시점까지 DB 조회를 미루는 전략.
- 영속성 컨텍스트가 관리해야 정상 작동한다.
7️⃣ 영속성 컨텍스트 생명주기
@Transactional안에서EntityManager가 생성되고, 해당 트랜잭션이 끝나면clear()되며 엔티티들은 더 이상 영속 상태가 아니게 된다.
✔️ JPA에서 영속성 컨텍스트가 중요한 이유
-
트랜잭션 내에서 객체처럼 다뤘는데, 자동으로 DB에 반영된다 → 생산성↑
-
성능 최적화 → 1치 캐시, 지연 쓰기, 지연 로딩
-
상태 추적 기능 → Dirty Checking
-
DB 중심이 아닌 객체 중심으로 개발 가능 → JPA 핵심 철학
✅ 영속성 컨텍스트의 성능 최적화 과정에서 일어날 수 있는 N+1 문제
✔️ N+1 문제란?
하나의 쿼리를 실행해 하나의 데이터를 가져올 때, 연관된 엔티티를 가져오기 위해 추가로 N개의 쿼리를 실행하는 문제를 말한다.
예를 들어, 여러 Order를 조회한 뒤에 각 Order에 연결된 Member의 이름을 출력하고 싶을 때 :
Member엔티티 구조
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
private String name;
}
Order엔티티 구조
@Entity
public class Order {
@Id
@GeneratedValue
private Long id;
private String product;
@ManyToOne(fetch = FetchType.LAZY)
private Member member;
}
- N+1 문제 발생 예제
public void showOrders() {
List<Order> orders = orderRepository.findAll(); // 📌 쿼리 1번
for (Order order : orders) {
System.out.println("상품: " + order.getProduct());
System.out.println("주문자: " + order.getMember().getName()); // 📌 쿼리 N번 추가 발생!
}
}
orderRepository.findAll()
→ SELECT * FROM orders로 쿼리 1번 실행
getMember() 호출 시마다
→ SELECT * FROM member WHERE id = ?로 쿼리 N번 실행
✔️ N+1 문제 해결 방법
- Fetch join
- Entity Graph
- Batch Size 설정
1️⃣ Fetch join
- 연관 엔티티를 한 번에 조회해서 한 번의 쿼리로 처리하는 가장 기본적인 방법.
- 기본 설정은 Lazy Loading으로 해놓고, Fetch join을 통해 필요한 필드에서만 즉시 로딩으로 적용한다고 생각하기
@Query("SELECT o FROM Order o JOIN FETCH o.member")
List<Order> findAllWithMember();
→ Order와 Member를 하나의 SQL로 조인해서 가져온다
2️⃣ Entity Graph
- JPA 표준 방식으로 fetch join 설정하는 방법
- SQL에 조인 추가하지 않고도 즉시 로딩으로 설정하는 방법
@EntityGraph(attributePaths = "member")
@Query("SELECT o FROM Order o")
List<Order> findAllWithMember();
→ 특정 쿼리 실행 시점에만 임시로 즉시 로딩을 적용하는 도구
→ fetch join의 대안(JPQL 복잡하게 작성하지 않아도 되는)으로 생각하기
3️⃣ Batch Size 설정 (Hibernate 전용)
- N+1을 완전히 제거하지 못하지만, N개의 쿼리를 1개의
IN쿼리로 줄여 성능을 개선하는 방법
spring.jpa.properties.hibernate.default_batch_fetch_size=100
→ SELECT * FROM member WHERE id IN (?, ?, ?, ...)와 같은 방식으로 N -> 1 쿼리로 줄여준다.
✏️ 요약
영속성 컨텍스트는 JPA에서 엔티티를 관리하는 1차 캐시로, 엔티티의 동일성 유지, 변경 감지, 성능 최적화 등을 가능하게 해주는 핵심 매커니즘이다.
➡️ JPA가 객체 중심 개발을 가능하게 하는 핵심 기반이라고 생각한다.
또한, 성능 최적화 과정에서 JPA의 연관관계는 기본적으로 Lazy Loading으로 설정되는 경우가 많아 연관된 엔티티는 필요한 시점에 쿼리를 날리게 되는데,
➡️ 이게 루프 안에서 발생할 경우 N개의 추가 쿼리가 실행되는 N+1 문제가 생길 수 있다.
이에 대한 해결책으로
1. Fetch Join
2. Entity Graph
3, Batch Size 설정
등의 방법으로 쿼리 수를 줄이고 성능을 개선할 수 있다.

영속성 컨텍스트 이걸로 마스터 하신것같습니다 대단하십니다