Kafka는 대규모 데이터 스트림을 처리하기 위한 분산형 메시징 플랫폼을 말한다.
단순한 메시지 큐가 아닌 분산 로그 시스템이기 때문에 내부 구성 요소들이 "고성능 / 장애 복구 / 확장성"을 중심으로 설계되어 있다.
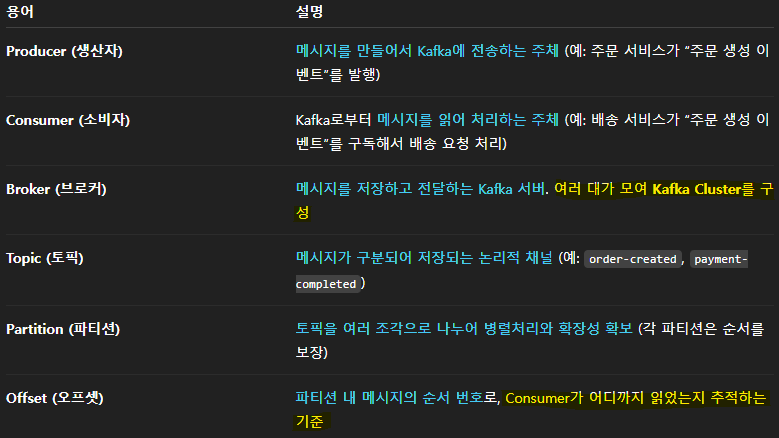
🔹 Kafka 핵심 개념 요약
 |
|---|
🔸 Producer (생산자)
- 메시지를 만들어서 Kafka에 전송하는 주체
- 예: 주문 서비스가 "주문 생성 이벤트"를 발행
🔸 Consumer (소비자)
- Kafka로부터 메시지를 읽어 처리하는 주체
- 예: 배송 서비스가 "주문 생성 이벤트"를 구독해서 배송 요청 처리
🔸 Broker (브로커)
- 메시지를 저장하고 전달하는 역할의 Kafka 서버 한 대
- 여러 대가 모여 Kafka Cluster를 구성
- 브로커 장애 시에도 데이터 유지 가능
🔸 Topic (토픽)
- 메시지가 구분되어 저장되는 논리적 분류 단위
- 예:
order-created,payment-completed
🔸 Partition (파티션)
- 토픽을 쪼갠 물리적 단위
- 토픽을 여러 조각으로 나누어 병렬처리와 확장성 확보
- 각 파티션은 파티션 내부에서만 순서를 보장한다
- Partition 수만큼 Consumer 병렬 처리 가능
- 파티션 증가 = 처리량 증가
🔸 Offset (오프셋)
- 파티션 내 메시지의 순서 번호
- Consumer가 어디까지 읽었는지 추적하는 기준
🔹 Kafka 동작 구조
Producer → [Kafka Broker] → Consumer
| Topic |
┌──────────────┐
│ Partition 0 │ → 메시지 A, B, C ...
│ Partition 1 │ → 메시지 D, E, F ...
└──────────────┘
- Producer가 특정 Topic으로 메시지를 보냄
- Kafka Broker는 그 메시지를 해당 Topic의 Partition에 저장
- Consumer는 자신이 구독한 Topic의 Partition에서 메시지를 Offset 순서대로 읽음
🔹 Kafka의 주요 특징
🔸 고성능 / 고처리량
- 초당 수십~수백만 건의 메시지 처리 가능
🔸 확장성
- 브로커와 파티션을 늘려 부하를 분산 가능
🔸 내구성 / 장애 복구
- 메시지를 디스크에 저장하고 복제하여 장애 시에도 데이터 유실 방지
🔸 실시간 처리
- 스트림 데이터를 실시간으로 처리
- 예: IoT 센서, 로그, 결제 이벤트 등
🔸 Pub / Sub 구조
- 한 Producer가 보낸 메시지를 여러 Consumer가 동시에 구독 가능
🔹 Kafka의 활용 예시
🔸 로그 수집 이벤트
- 각 서버의 로그를 Kafka에 모은 뒤 ELK(ElasticSearch, Logstash, Kibana)로 전송
🔸 주문 / 결제 이벤트 처리
- 주문, 결제, 배송 서비스를 비동기 이벤트 기반으로 연결
🔸 실시간 데이터 분석
- 클릭스트림, 트래픽 데이터, 금융 거래를 실시간 분석
🔸 IoT 데이터 스트리밍
- 수많은 센서 데이터 실시간 수집 및 처리
🔸 데이터 파이프라인 중간 버퍼
- Spark, Flink, Hadoop 등으로 데이터를 전달하는 중간 허브 역할
🔹 Kafka의 파티션 전략
Kafka에서 파티션 전략은 성능 / 순서 / 확장성 / 데이터 일관성을 동시에 결정하는 핵심 설계 요소이다.
그렇기 때문에 단순히 "많이 나누면 좋다"가 아니라, 비즈니스 특성과 소비 패턴을 고려해 설계해야 한다.
🔸 Key가 없는 경우
kafkaTemplate.send("order-topic", value);
- Kafka가 자동으로 Round Robin
- 메시지 균등 분산
- 순서 보장 없음 (전체 단위로)
- 예: 로그 수집, 클릭 이벤트, 순서 의미가 약한 데이터 등
🔸 Key 기반 파티셔닝
kafkaTemplate.send("order-topic", userId, value);
"이 단위 안에서는 순서를 반드시 보장해야 한다" → 그 단위를 key로 사용
 |
|---|
🔸 key 기반 파티셔닝 예시
- 사용자별 순서 중요 → userId
- 주문별 순서 중요 → orderId
- 상품 재고 중요 → productId
- 전체 순서 중요 → Partition 1개
🔸 Hot Partition 문제
-
예: userId 기준으로 분산했는데 특정 user가 트래픽 80% 차지
→ 결과:Partition 0 → 80% 부하 나머지 → 한가함이를 Hot Partition이라고 한다.
-
Hot Partition 문제에 대한 해결 전략으로 3개 정도 서술하자면,
- Key 세분화
- Composite Key 전략
- Custom Partitioner 사용
🔸 1. Key 세분화
userId + randomSuffix
단점: 순서 보장 깨질 수 있음
🔸 2. Composite Key 전략
userId + orderDate
시간 단위로 분산
🔸 3. Custom Partitioner 사용
public class CustomPartitioner implements Partitioner {
@Override
public int partition(...) {
// 직접 분산 로직 작성
}
}
특정 로직 기반 분산 가능
🔸 Partition 개수 설계 기준
파티션 수는 늘릴 수는 있지만 줄일 때는 위험(순서 보장 깨질 수 있음, 데이터 분산 재정렬)이 따르기 때문에 처음 설계가 매우 중요하다.
-
파티션 전략 설게 시 고려할 점:
- 어디까지 순서를 보장해야 하는가?
- 최대 트래픽은 얼마나 되는가?
- 특정 key에 트래픽이 몰릴 가능성은 없는가?
-
목표 처리량을 기반으로 계산해서 설계할 때는:
목표 TPS ÷ 파티션당 처리 가능 TPS = 최소 파티션 수
-
Consumer 수 고려해서 설계할 때는
- Consumer Group 내 Consumer 수 <= Partition 수
- 향후 확장 고려해서 여유 두기
🔸 Partition 너무 많으면 생기는 문제
| 문제 | 설명 |
|---|---|
| 파일 핸들 증가 | OS 리소스 증가 |
| 메모리 사용 증가 | 브로커 부하 |
| Rebalance 시간 증가 | 장애 시 지연 |
| 관리 복잡도 증가 | 운영 비용 증가 |
일반적으로 수십~수백 개는 흔함. 수천 개 이상은 신중해야 함
🔹 Kafka Outbox 패턴 적용
Kafka + Outbox 패턴 설계는 데이터 정합성과 확장성을 동시에 만족시키기 위한 핵심 설계이다.
특히 주문/결제/재고처럼 정합성이 중요한 도메인에서 거의 표준에 가깝다고 생각한다.
Outbox 패턴의 핵심은:
이벤트를 DB 트랜잭션 안에서 함께 저장하고 나중에 별도 프로세스가 Kafka로 발행하는 것에 있다.
- Outbox가 해결하는 것:
- DB와 Kafka 간 원자성
- Kafka 전송 실패 시 재시도 가능
- 메시지 유실 방지
- 하지만, Kafka 레벨에서 중복은 발생 가능
- 따라서 Consumer는:
- 멱등성 처리 필요
- 이벤트 ID 기반 중복 제거
🔸 알아두면 좋은 실무에서 무난하고 안전한 설계 공식
- Outbox 테이블에 event_id 포함
- Kafka key = aggregate_id
- Consumer는 event_id로 멱등 처리
- Partition 수는 예상 TPS 기반 설계
[Order Service]
├─ Order 저장
└─ Outbox 저장 (aggregate_id 포함)
[Outbox Publisher]
└─ Kafka 전송 (key = aggregate_id)
[Kafka]
└─ 같은 aggregate는 같은 Partition
[Consumer]
└─ event_id 기반 멱등 처리
🔸 Kafka 장애 시 Outbox 재처리 전략
Kafka 장애 시 Outbox 재처리 전략의 핵심은:
1. 데이터 유실 없이
2. 중복은 허용하되 멱등으로 해결한다
3. 무한 재시도는 막는다
4. 락 전략을 명확히 한다
🔸 전체 장애 대응 흐름
DB TX 성공
↓
Outbox 저장
↓
Kafka 장애 발생
↓
Outbox 재시도
↓
Kafka 복구
↓
정상 전송
↓
Consumer 멱등 처리
🔸 장애 시나리오별 분석
🔸 시나리오 1. Kafka 브로커 일시적 다운
[상황]
- DB 저장 성공
- Outbox 저장 성공
- Kafka 전송 시도 → 실패
[해결 전략]
- Outbox row는
status = READY상태 유지 → Publisher가 재시도
🔸 시나리오 2. Kafka 전송 성공했지만 응답 받기 전 장애
[상황]
- Kafka에 실제로 메시지는 저장됨
- 네트워크 문제로 응답 못 받음
- 애플리케이션은 실패로 인식
- 재전송 발생
→ 중복 이벤트 발생 가능
[해결 전략]
- Consumer는 반드시 멱등 처리
🔸 시나리오 3. Outbox Publisher 장애
[상황]
- 애플리케이션 정상
- Outbox 쌓임
- Publisher 프로세스 다운
[해결 전략]
- 재기동 후 미처리 row 재전송 필요
🔸 Outbox 재처리 흐름
1. READY 조회
2. PROCESSING 변경 (락 확보)
3. Kafka 전송 시도
4. 성공 → SENT
5. 실패 → READY (retry_count++)
🔸 outbox의 동시성 제어 전략
멀티 인스턴스 환경에서는 같은 row를 여러 Publisher가 가져가면 안 된다.
해결방법 1. DB Row Lock (Pessimistic Lock)
SELECT *
FROM outbox
WHERE status = 'READY'
ORDER BY created_at
FOR UPDATE SKIP LOCKED
LIMIT 100;
동시에 여러 인스턴스가 실행해도 중복 처리 방지
- 조회와 동시에 row-level lock 획득
- 다른 트랜잭션은 해당 row 접근 불가
SKIP LOCKED→ 이미 잡힌 row는 건너뜀
장점
- 구현이 직관적
- 멀티 인스턴스 환경에서 안전
- 충돌 시 자동 회피
단점
- DB 락 경합 가능
- 처리 시간이 길면 lock 유지 시간 증가
- 트랜잭션 관리 신중해야 함
해결방법 2. 상태 전이 기반 Lock (Optimistic 방식)
UPDATE outbox
SET status = 'PROCESSING'
WHERE id = ?
AND status = 'READY';
update count == 1 이면 성공적으로 점유
- READY row 조회
- UPDATE로 상태 변경 시도
- 성공한 인스턴스만 처리
장점
- DB lock 유지 시간 짧음
- 대량 처리에 유리
- 확장성 좋음
단점
- 충돌 시 재시도 로직 필요
- 상태 꼬임 가능 (예: 장애 중단)
🔹 RabbitMQ와 비교
| 항목 | Kafka | RabbitMQ |
|---|---|---|
| 구조 | 로그 기반 분산 스트리밍 | 큐 기반 메시지 브로커 |
| 메시지 순서 | 파티션 단위 순서 보장 | 큐 단위로 메시지 순서 보장 |
| 처리 목적 | 대규모 데이터 스트림 (실시간 분석) | 트랜잭션성 메시징 (요청-응답, 워크큐 등) |
| 저장 방식 | 디스크 로그에 저장 (내구성 높음) | 메모리 중심 (빠름, 하지만 유실 가능성 있음) |
| 소비 방식 | Consumer Group 단위로 병렬 처리 | 각 큐에 한 소비자 그룹만 처리 |
| 사용 예 | 로그, 이벤트, IoT, 데이터 파이프라인 | 주문 처리, 이메일 발송, 알림 등 |
