디스코드 서버 내 스터디 관리용으로 개발하는 간단한 토이 프로젝트입니다.
추가 된 기능
BOJ 문제 검색 (난이도, 알고리즘 분류)
BOJ 문제 검색 기능
아이디어
매 주 스터디를 위한 문제를 선정해야할 때, 직접 고르기도 귀찮고 스터디원들과 문제를 공유할 때 디스코드 게시판에 url를 난사하게 되면 보기 매우 지저분하다는 문제가 있었습니다.
봇을 이용해서 깔끔하게 문제를 정리해줍시다.
solved.ac에 이미 훌륭한 BOJ 검색 엔진이 구현되어있습니다. 당장은 solved.ac에 query를 넣고 가져와서 이쁘게 보여주는 쪽으로 구현하였습니다.
구현
1. crawler.py
solved.ac에 가서 이리저리 검색기능을 써보고 사이트도 개발자 도구로 확인해보며 대충 구조를 파악합니다.
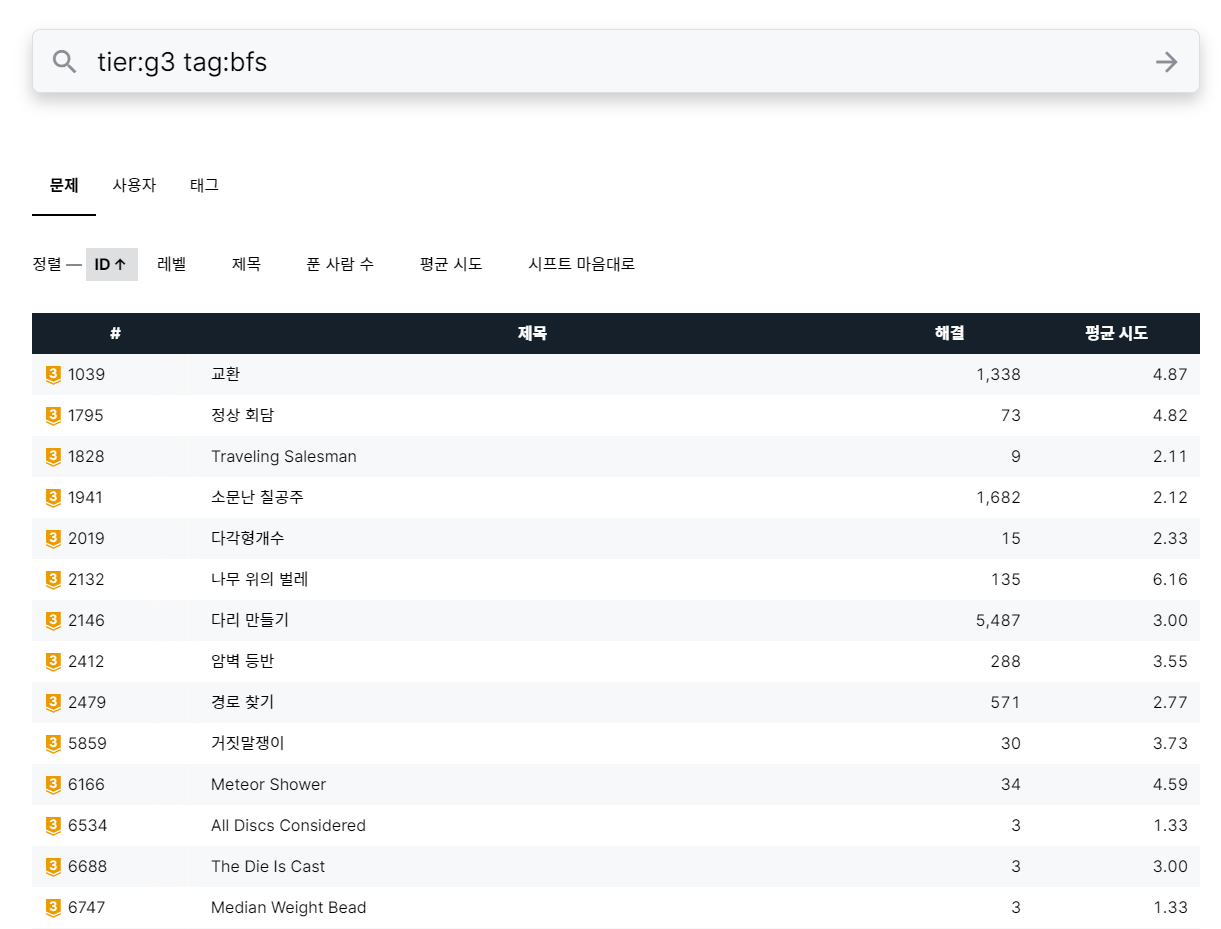
모든 검색 기능을 쓰는 것은 포기하고, 단일 tier와 단일 tag 하나에 대해서만 검색하도록 하겠습니다. 크롤러 인풋으로 tier와 tag에 대한 스트링이 오면 적절하게 url을 만들어서 requests로 긁어오도록 하였습니다. url 마지막에 sort=random을 더해 무작위 문제가 나오도록 하겠습니다.
개발자 분이 봇 차단을 잘 해놓셨는지 요청이 잦을 시 요청 결과가 비어서 옵니다. 원활한 사용을 위해서 백준 사이트를 db화 하는 것으로 리펙토링할 생각을 해야할 것 같습니다.
일단 급하게 쓸 것이니 flag로 결과가 왔는지 안왔는지 구분합니다.
import requests
from bs4 import BeautifulSoup
import re
def BOJCrawler(args:dict):
...
ret = []
h = re.compile('[가-힣]+')
if Object:
flag = url
for item in Object[1:]:
rank = #문제난이도
num = #문제넘버
name = #문제이름
link = #문제링크
if h.search(name):
ret.append([rank,num,name,link])
else:
flag = False
ret = url
return ret, flag
정규식을 사용해서 문제 제목에 한글이 있는 경우에만 ret에 담읍시다. 응답이 비어서 왔다면 ret으로 url만 넘깁니다.
2. main.py
main에서 args를 받으면 크롤러로 넘겨주어 데이터를 받고, discord에 전송해줍니다. 데이터가 오지 않았다면, url이라도 보여줍시다.
from utils.crawler import *
from utils.embed import *
@client.command(
name="BOJ",
brief = "난이도 태그(math, .. , backtraking, bfs, dfs ..)"
)
async def reprBOJ(ctx,*args):
input_args = {'tier':args[0],'tag':args[1]}
data, flag = BOJCrawler(input_args)
await ctx.send(embed=embed_print_BOJ(input_args,data,flag))데이터가 잘 왔을 시 이쁘게 보여줄 embed 함수를 만듭니다.
3. embed.py
def embed_print_BOJ(query,data,flag):
title = f'(난이도:{query["tier"]}, 분류:{query["tag"]})'
embed = Embed(title="추천 문제" + title, url=flag or data, color=0x00ff00)
if flag:
rank_text = '\n'.join(f'{x[0]}' for x in data[:10])
number_text = '\n'.join(f'[{x[1]}]({x[3]})' for x in data[:10])
name_text = '\n'.join(f'[{x[2]}]({x[3]})' for x in data[:10])
embed.add_field(name="Rank", value=rank_text, inline=True)
embed.add_field(name="Numbers", value=number_text, inline=True)
embed.add_field(name="Name", value=name_text, inline=True)
else:
embed.add_field(name="요청이 잦습니다", value="링크에서 확인하세요 ㅜ")
return embedembed는 그냥 이쁘게 보여주기 용이라 data에 담은 걸 잘 나열해주기만 하면 됩니다. 시간이 나면 rank를 이미지로 표현해야겠습니다. embed가 너무 길면 에러가 뜹니다.
10개까지만 보여주도록 하였습니다.
디스코드 embed에서 [text](url) 표기로 하이퍼링크를 달 수 있습니다.
시연
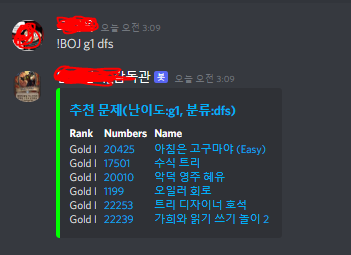
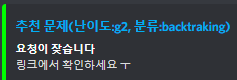
크롤링이 안될 때 아쉽지만 링크에 들어가서 확인해도 되고, 추후 리펙토링 여지가 많으니 여기까지..
그래도 랜덤으로 찝어준단 점에서 맘에 듭니다.
개선 여지
크롤러 초보라 요청이 잦을 시에 막히는 것을 예상 못했습니다. 차단 회피 쪽으로 개선할 것인지 아니면 백준 사이트에서 분류 별로 검색한 뒤 난이도로 필터링을 해서 아싸리 다 저장을 할지 고민중입니다.
디스코드에서 tag를 쓸 때 오타가 조금이라도 나면 크롤링이 안됩니다. aliases 테이블을 만들어서 오타를 보정해주면 좋겠습니다.
느낀 점
뭔가 로아 봇 개발 때보다 뭔가 더 실력이 퇴보한 느낌. 아마 기능 자체가 없으면 불편하다 느낌이 아니라서 그런지 의욕이 없나... 뭐 사람들이 열심히 써주면 기분 좋아서 열심히 하겠징...
웹훅을 사용해서 스터디 공용 깃허브의 업데이트 로그를 디스코드에 띄울 수가 있다. 이 데이터를 봇에서 가져다가 일일 숙제 체크용으로 쓰고 벌금 데이터 관리까지 하면 매우 좋을 것 같다.

ㄷㄷ,, 저도 얼른 채팅봇들 만들고 싶네요