.png)
Semantic Web
과거에는, 인터넷이 발전하면서 생기는 무분별한 정보의 축적으로 컴퓨터가 스스로 정보를 해석, 가공 할 수 없어 모든 정보를 사용자가 직접 개입해서 처리해야만 했다.
따라서 의미없는 로드를 줄이기 위해 기계가 읽고 처리 할 수 있는 웹을 개발하고자 탄생한것
Semantic tag
semantic? 의미가 있는, 의미론적
"중요한 이유"
SEO(Search Engine Optimization)
마케팅 도구를 사용하여 검색엔진이 본인의 웹사이트를 검색하기 알맞은 구조로 웹사이트를 조정함.
검색 엔진이 웹 사이트의 정보를 어떻게 찾을까?
검색엔진은 로봇(Robot)이라는 프로그램을 이용해 매일 전세계의 웹사이트 정보를 수집한다.
(이것을 크롤링이라 하며 검색엔진의 크롤러가 이를 수행한다.)
그리고 검색 사이트 이용자가 검색할 만한 키워드를 미리 예상하여 검색 키워드에 대응하는 인덱스(색인)을 만들어 둔다.(이것을 인덱싱이라 하며 검색엔진의 인덱서가 이를 수행한다.)
인덱스를 생성할 때 사용되는 정보는 검색 로봇이 수집한 정보인데 결국 웹사이트의 HTML 코드이다. 즉, 검색 엔진은 HTML 코드 만으로 그 의미를 인지하여야 하는데 이때 시맨틱 요소(Semantic element)를 해석하게 된다.
ACCESSIBILLITY(웹 접근성)
시각적인 경우 뿐만 아니라 음성으로만 읽어주는 screen reader를 이용하거나 키보드만을 이용해서 웹사이트를 이용하는 경우 잘 만들어진 웹사이트라면 문제 없이 잘 작동할 수 있는 좋은 접근성을 가질 수 있다.
FOR US, Maintainabillity(우리를 위해!)
:개발자들이 html 태그를 봤을 때 한 눈에 보고 유지 보수를 하는데 가장 큰 장점이 있음.
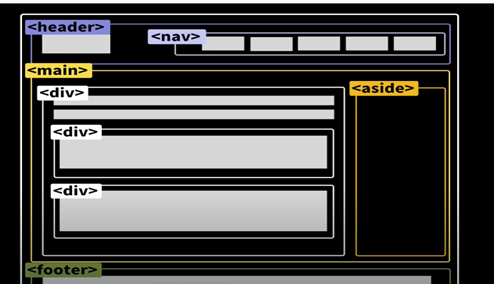
"웹 사이트 구조를 이루는 태그들"
1.header: 웹 사이트 브랜드 로고, 사용자를 위한 중요한 메뉴 아이템
- 1-1.nav: (네비게이션)header안에 여러 가지 메뉴들 작성
2.footer: 필수는 아니지만 웹사이트 바로 아래 부가적인 정보나 링크가 있다면 사용
3.main: 중요한 핵심 내용
- aside: 사이드에 위치하는 공간으로, main안에서도 page 컨텐츠와 직접적으로 상관없는 부가적인 내용이 필요하다면 사용
- article:블로그 포스터에서 포스터 하나, 신문 기사에서 기사 하나 그 자체를 묶어 줄 때 사용한다. 자체만으로도 독립적이며 다른 페이지에 보여줬을 때 다른 문제가 없을 때 사용한다. 즉, 그말은 메인 안에 있는 다른 내용들과 전혀 상관없이 고유한 정보를 나타낼 때 사용 가능하다.
- section: article안에 연관있는 내용들을 묶어줄 수 있다.` section안에서도 article로 구성할 수 있다
- article과 section: main내 에서도 div로만 구조하기보다는 article과 section을 추가해서 더욱더 구조적으로 완성화시키면 훨씬 보기 좋은 구조적 웹 사이트가 된다.
[출처]
https://poiemaweb.com/html5-semantic-web
https://www.youtube.com/watch?v=T7h8O7dpJIg
<youtube:드림코딩>
