
문제풀이를 먼저하고 python list cloning, copying에 대해 이야기하고자 한다. 문제풀이에 관심없는 분은 바로 아래로!
문제 캡쳐

문제를 내게된 경위를 잘 읽어보면 굉장히 열이 받았다. 하지만 바로 문제에대한 이해를 할 수 있었다. 일부러 저런 식으로 했나 싶었다.

문제 핵심
1 . 1000~9999까지의 숫자 중 소수가 필요하다.
2 . 한번에 한자리수만 변경할 수 있다.
3 . 소수에서 소수로만 변경할 수 있다.
4 . 최소 변환 회수를 출력해야 한다.
나의 생각
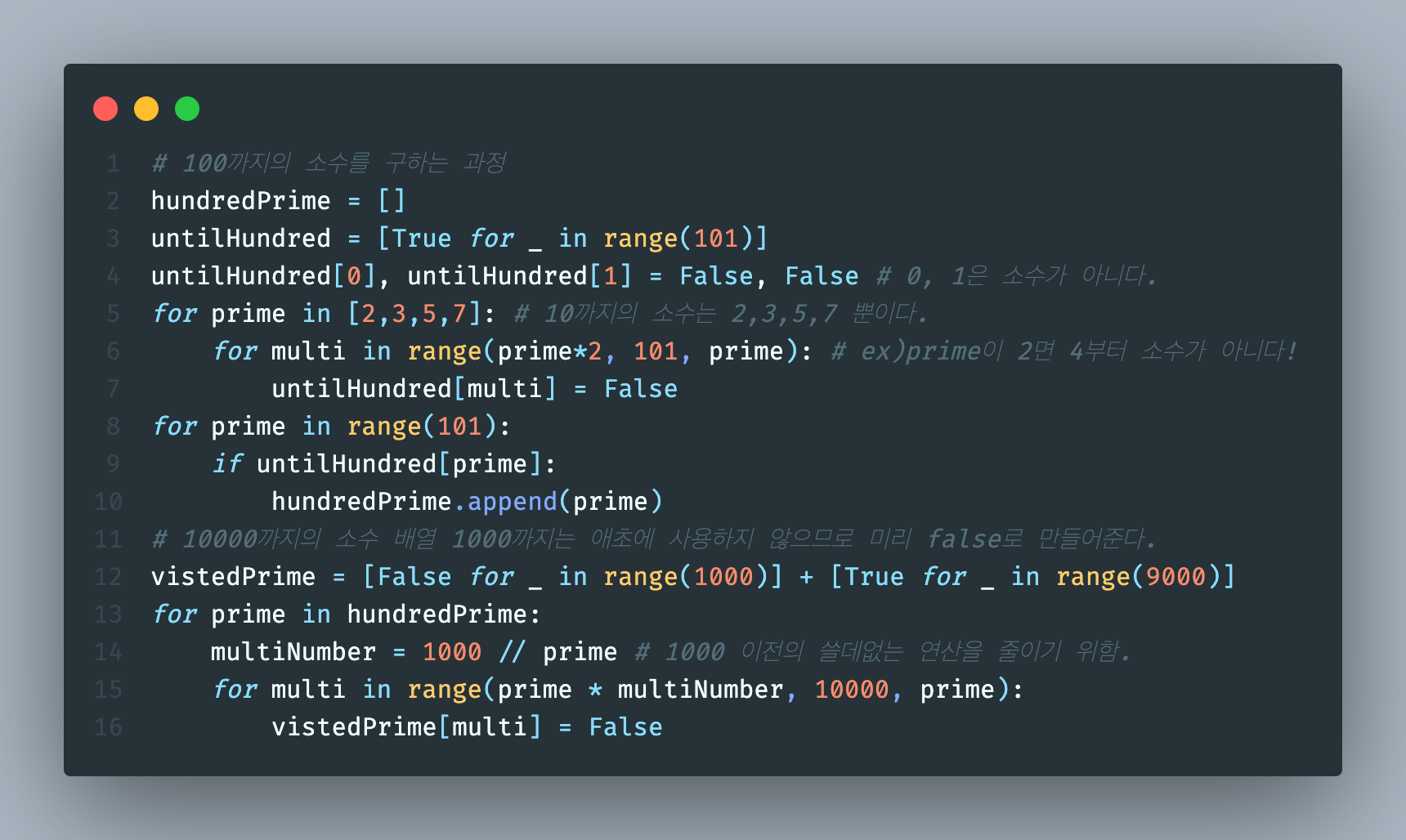
1 . 소수를 구할 때
소수를 구할 때 에라토스테네스의 체를 이용하기로 했다. 에라토스테네스의 체는 많이들 알고 계신 알고리즘이기 때문에 여기서는 자세히 설명하지 않도록 하겠다. 간단히 설명하면 N까지의 소수를 구할 때 N의 제곱근까지를 갖고 배수를 삭제하는 알고리즘이다. 100까지의 소수를 구하고 싶으면 10까지의 소수인 2,3,5,7의 배수를 모조리 삭제시키면 100까지의 소수를 모두 구할 수 있게된다. 나는 방금 예시에서 착안하여 100까지의 소수를 먼저 구한 뒤 그 소수를 가지고 10000까지의 소수를 구하는 방식으로 최대한 연산을 줄였다.
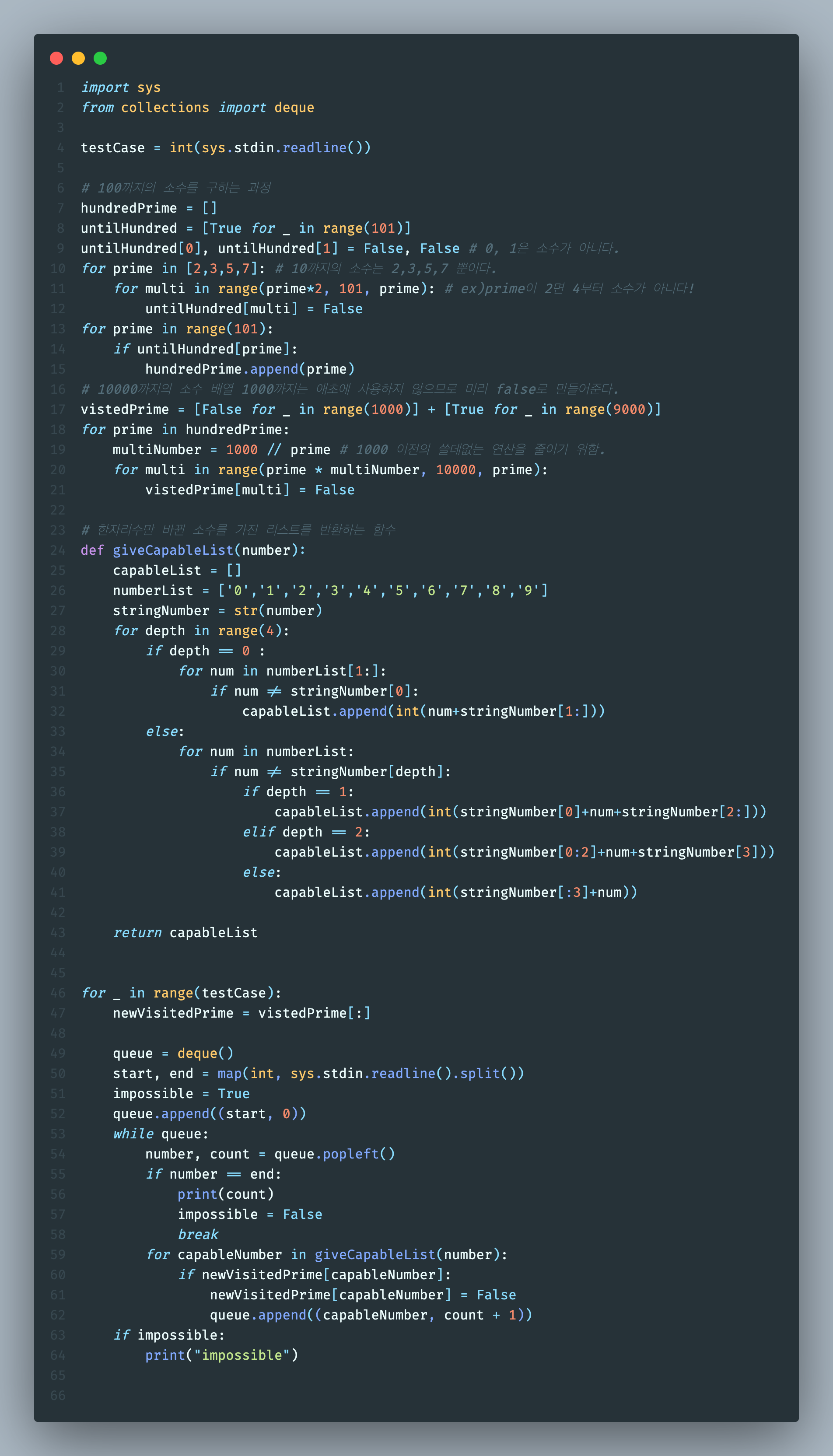
2 . 최소 변환 회수를 구할 때
최단거리를 구하는 문제와 같으므로 BFS를 사용했다.
전체 코드
list 실험
실험을 하게된 이유
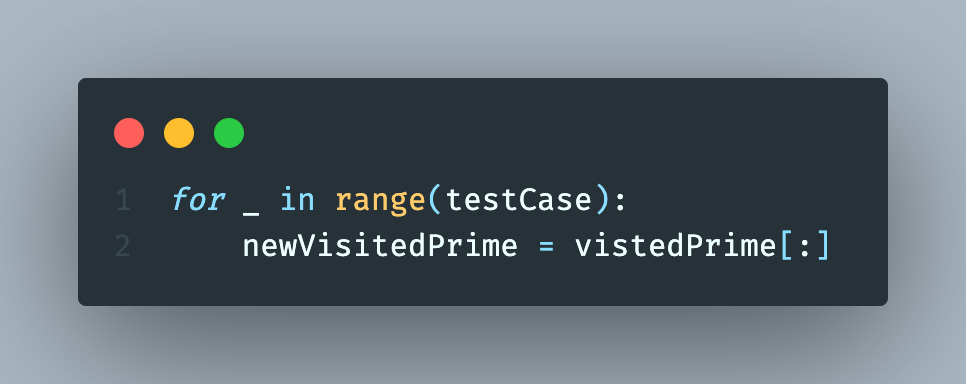
바로 이 부분 때문이다. visitedPrime을 deepcopy했을 때보다 그냥 for문 안에서 세번 visitedPrime을 만드는게 더 빠른 속도가 나왔다.
1 . deepcopy를 했을 때

2 . for문 안에서 세번 리스트를 생성했을 때(소수 구하는 과정이 세번)

deepcopy는 얼마나 시간복잡도가 높은 것일까? 하는 생각이 들었고 다른 방법은 없을까 고민했다.
3 . slice
newVisitedPrime = visitedPrime[:]가장 쉽고 빠르게 리스트를 클론할 수 있는 방법이다. 이 방법은 original 리스트는 보존하면서 복제할 수 있는 방법이다. cloning이라고 부른다. 6개의 숫자를 가진 list기준(앞으로 계속 이 기준으로 비교하겠습니다) 0.039 초가 걸리는 가장 빠른 방법이다.

4 . extend method
newVisitedPrime = []
newVisitedPrime.extend(visitedPrime)extend() 함수를 이용한 방법으로 list의 끝에 다른 리스트를 붙임으로서 새로운 리스트를 만드는 방법이다. 같은 기준으로 0.053초가 걸린다.

5 . list method
newVisitedPrime = list(visitedPrime)list() 함수를 이용한 방법이다. 0.075초가 걸린다.

이상하게도 더 빨라졌다. 백준 채점 머신의 작은 실행오차가 아닐까 생각해본다.
6 . list comprehension
newVisitedPrime = [i for i in visitedPrime]list comprehension 메소드를 이용해서 한개씩 요소를 복사했다. 0.217초가 걸린다.

사실 복제하는 리스트가 10000개도 안되기 때문에 다들 그렇게 차이는 나지 않는다 🤣
하지만 실험은 멈출 수 없다.
7 . apppend method
newVisitedPrime = []
for item in visitedPrime: newVisitedPrime.append(item)append로 하나씩 더한다. 0.325초가 걸린다.

그럼 deepcopy는? 10.59초가 걸린다고 한다. cloning중에 가장 느린 방법이라고 한다.
실험 결론
단순 cloning을 위해서는 deepcopy는 자제하는 것이 좋겠다.
그럼 언제 deepcopy를 쓰나?
[:]로 리스트를 cloning하는 것은 nested list까지는 적용이 안된다. 하지만 deepcopy의 경우에는 nested list까지 완벽히 복사를 해낸다.
* nested list란? list안에 list를 뜻한다.
결론
단순한 리스트 복사에도 수많은 방법이 있고 저마다의 장단점을 가지고 있다. 프로그래밍을 할 때 그냥 한번 해결했다고 끝내지 않고 더 좋은 방법을 찾는 프로그래머가 되자.
추가(21.04.29)
피드백을 받고 내용이 추가되었습니다.
cloning과 copying의 차이
cloning과 copying의 차이에 대해서는 명확한 정의가 없다고 합니다. 보통 생각하는 개념으로 차이점을 밝히려고 합니다.
- cloning - 존재하는 것을 기반으로 새로운 것을 만드는 것. 새 인스턴스로 복제하는 것(항상 deep)
- copying - 존재하는 것에서 다른 것(이미 존재하는 것)으로 복사하는 것. 존재하는 인스턴스로 복제하는 것(shallow or deep)
위 내용에 대해서는 추가 피드백해주시면 감사하겠습니다.🤣
deepcopy의 원리(shallow vs deepcopy)
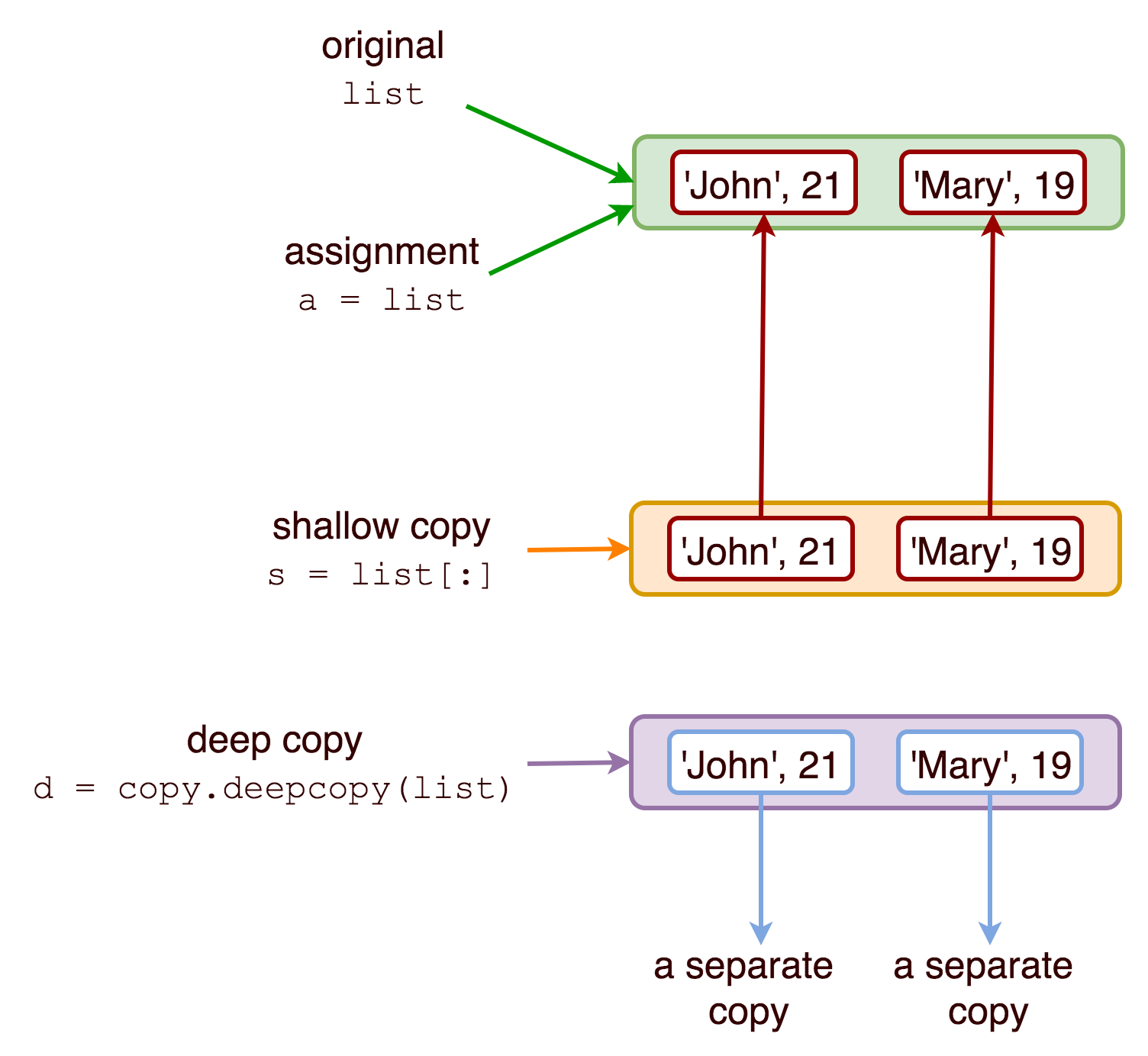
deepcopy의 원리
deepcopy를 하게 되면 고유한 메모리에 새 리스트를 만들어둔 뒤에 원래 element를 재귀적으로 복사를 한다. 따라서 원본에는 변경사항이 반영되지 않는다.
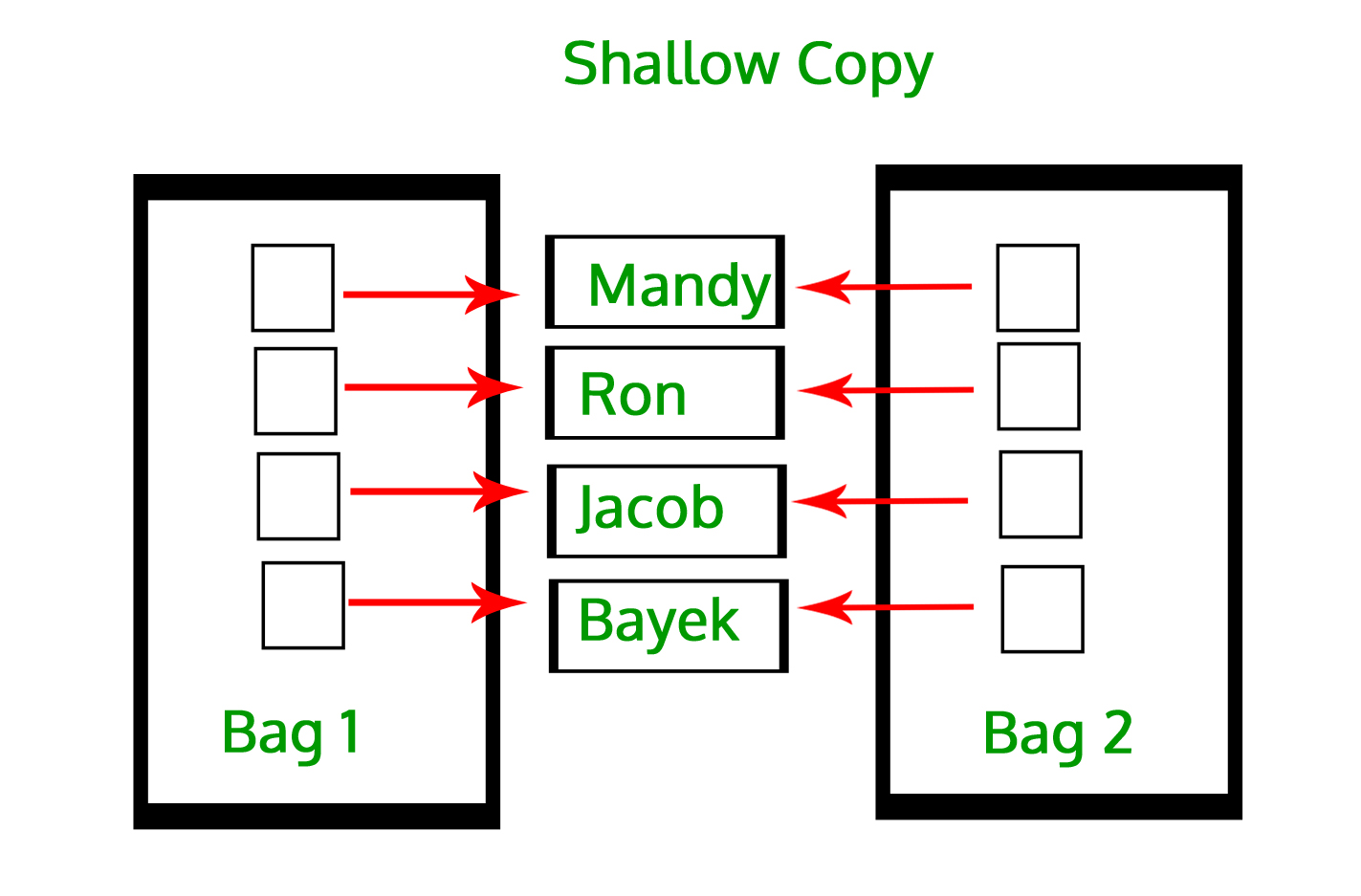
그럼 shallow copy는?
마찬가지로 새 리스트를 만들기는 하지만 element를 복사하지 않고 element의 메모리 주소에 대한 참조만 복사한다. 따라서 원본개체의 변경이 있을 시 반영이 된다. 서로 종속된 관계라고 볼 수 있다.

쉽게 지나치던 list의 clone과 copy에 대해서 다시 한 번 고민하게 되었습니다. 감사합니다!!! 😉