
📌 이 포스팅에서는 Database의 기본 개념과 테이블 간의 관계를 나타내는 one-to-one, one-to-many, many-to-many에 대해 정리하였습니다.
🌈 Database 기본 개념 정리
🔥 데이터베이스(Database) 이란?
🔥 테이블 간의 관계의 종류
🔥 ERD 구성도로 데이터 관계를 모델링하기
1. 데이터베이스(Database) 이란?
🤔 데이터베이스(Database) & 데이터베이스 관리 시스템(DBMS)
✔️ 데이터베이스는 데이터라는 단어와 베이스라는 단어의 합성어이다. 여기서 데이터란 컴퓨터 안에 기록되어 있는 숫자를 의미하며, 이러한 데이터의 집합을 데이터베이스라고 한다.
✔️ 즉, 데이터베이스라는 개념은 특정 데이터를 확인하고 싶을 때 간단하게 찾아낼 수 있도록 정리된 데이터의 집합을 말한다.
✔️ 또한 데이터베이스 관리 시스템(Database Management System, DBMS)은 데이터베이스를 효율적으로 관리하는 소프트웨어를 의미한다. 저장장치 내에 저장된 데이터의 집합인 데이터베이스와는 다른 개념이다.
✔️ 데이터베이스 관리 시스템(DBMS)을 사용하는 이유는 데이터 보존, 데이터의 체계적 관리, 생산성, 기능성, 신뢰성을 위해 사용한다.
🤔 관계형 데이터베이스(RDBMS) 란?
✔️ 데이터베이스 관리 시스템(DBMS) 중 관계형 데이터베이스를 RDBMS라 부르고, 대표적인 RDBMS는 Oracle, PostgreSQL, MySQL 등이 있다.
✔️ 여기서 관계형이라는 의미는 DB를 구성하고 있는 각 테이블들이 서로 상호관련성을 가지고 연결되어 있다는 것을 의미한다. 즉, 각 각의 테이블들은 독립적인 경우도 있지만, 대부분 서로 연관성을 가지고 저장되어 있다.
🤔 관계형 데이터베이스와 비관계형 데이터베이스의 차이
✔️ SQL 문법을 사용하는 관계형 데이터베이스와 반대되는 접근 방식을 가진 데이터베이스를 비관계형 베이스라하고, SQL을 사용하지 않는 다는 의미로 NoSQL이라 한다.
✔️ NoSql은 Not Only SQL의 약자로, 관계형 데이터 베이스(RDBMS)의 한계를 극복하기 위한 새로운 형태의 데이터 베이스 시스템이다.
✔️ SQL은 데이터를 저장하기 위해서 컬럼을 기준으로 데이터를 삽입하기 때문에 새로운 항목의 데이터가 발생하면 테이블을 수정해야하지만, NoSQL은 고정된 스키마 및 JOIN이 존재하지 않고 분산처리가 비교적 쉽다는 장점이있다.
✔️ 이로 인해 최근 빅데이터 등에서 주목 받는 데이터 베이스 시스템(DBMS) 기술이며, 정해진 규격(schema, table-clumn)이 없어도 데이터 저장이 가능하다는 특징이 있다.
🤔 Table & Column & Row
✔️ RDBMS에서는 모든 데이터들을 2차원 테이블(Table)로 표현할 수 있다. 여기서 Table이라는 것은 엑셀의 1개의 시트를 생각하면 이해하기 쉽다.
✔️ 이 중, 열을 의미하는 Column과, 행을 의미하는 Row라는 개념이 존재한다. 컬럼은 테이블의 각 항목이고, 로우는 각 항목들의 실제 값이다.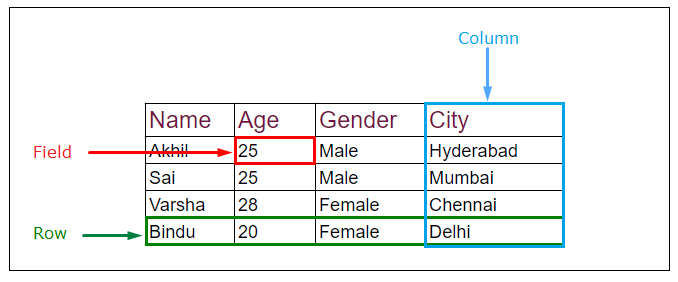
🤔 Primary Key 와 Foreign Key 의 관계
✔️ Primary Key는 각 로우가 다른 로우와 겹치지 않는, 하나의 데이터만 정확하게 지칭할 수 있게해주는 고유한 번호를 의미한다.
✔️ Primary Key를 통해 특정 로우를 찾거나, reference 할 수 있다.
✔️ Foreign Key는 한 테이블 내에서 다른 테이블의 특정 row를 식별하게 해주는 컬럼으로 주로 다른 테이블의 Primary Key를 참조하는 Key를 의미한다.
✔️ Foreign Key가 있는 테이블을 '자식 테이블(child table)'이나 '참조하는 테이블(referencing table)'이라고 하고 Foreign Key에 의해 참조당하는 테이블을 '부모 테이블(parent table)', '참조당하는 테이블(referenced table)'이라고 한다.
✔️ 또한 Foreign key 는 두 테이블 간의 참조 무결성을 지키기 위해 사용된다. 여기서 참조 무결성이라함은 두 테이블 간 참조 관계가 있을 때 각 데이터 간에 유지되어야 하는 정확성과 일관성을 의미한다.
2. 테이블 간의 관계의 종류
🤔 One-to-One 관계
✔️ 하나의 테이블 데이터(row)는 오직 하나의 B 테이블의 데이터(row)와 1:1로 매칭되는 관계가 One-to-One 관계이다.
✔️ 예를 들어, 담임 테이블과 학급 테이블이 있을 때, 각 담임이 한 학급만 담당하고, 한 학급도 한명의 담임만 주어진다면 담임과 학급 간의 관계는 1:1 관계로 이뤄진다.
🤔 One-to-Many 관계
✔️ 하나의 A테이블(row)의 데이터는 B 테이블의 여러 데이터(row)와 연결되나, B테이블의 한 데이터(row)는 A테이블의 여러 테이블과 연결되지 않을 때, 1대 N관계가 성립된다.
✔️ 저자 테이블과 댓글 테이블이 있을 때, 각 저자는 여러 댓글을 작성할 수 있으나, 각 댓글은 하나의 저자만 생성할 수 있을 때 1대 N 관계로 연결지을 수 있다.
🤔 Many-to-Many 관계
✔️ 하나의 A테이블 데이터(row)는 B테이블의 여러 데이터(row)와 연결될 수 있고, 반대로 B테이블의 하나의 테이터(row)는 A테이블의 여러 데이터(row)와 연결될 수 있다면 다대다 관계를 의미한다.
✔️ 예를들어, 저자 테이블과 게시글 테이블이 있을 때, 각 저자는 여러 글을 작성할 수 있고, 각 글도 여러 저자의 의해 공동으로 작성될 수 있다고 가정해보자. 즉, 각 저자는 여러 글과 관계를 맺고, 각 글 또한 여러 저자가 존재하는 것과 같다. 이럴 때는 N대 N관계로 테이블 간 관계를 맺어 표현한다.
✔️ Many-to-Many 관계는 다이어그램으로 표현할 때 두 테이블만 가지고 현실의 모델을 표현할 수 없기 때문에 이 둘을 매개해주는 연결 테이블을 생성한 뒤, 서로 1대 다 관계를 맺는다.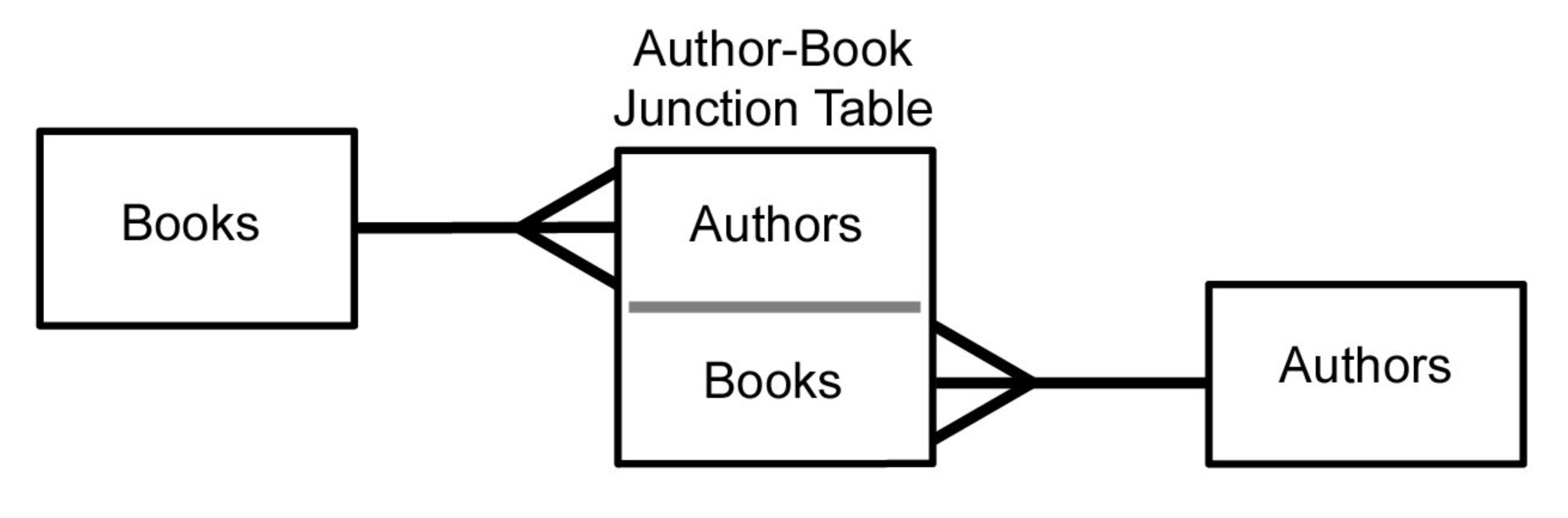
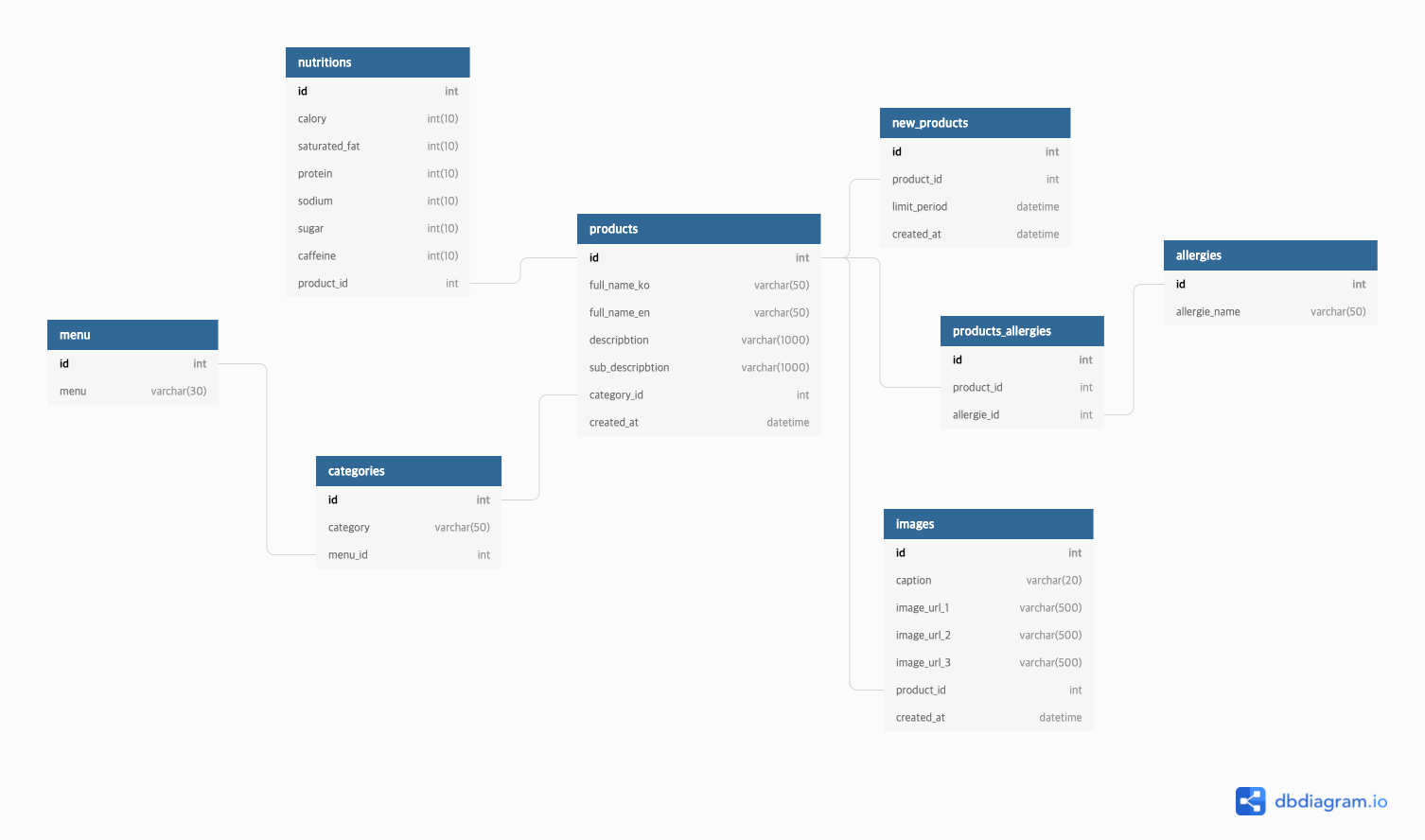
3. ERD 구성도로 데이터 관계를 모델링하기
🤔 ERD 구성도로 모델링 도전!
✔️ 제작 도구 : https://dbdiagram.io/
✔️ 모델링 대상 : https://www.starbucks.co.kr/menu/drink_list.do
- 📍 필수 구현 사항 : 음료, 카테고리, 영양 정보, 알러지, 음료 이미지, 음료 설명, 신상 여부
- 📍 구현 제외 사항 : 프로모션, 음료 사이즈
🤔 어려웠던 점.
✔️ 1대 N 관계를 ERD 구성도로 설계할 때 어느쪽이 1이고, *인지 머리속에서 정리가 되지 않았다. 차근히 생각해보면, primary key가 참조되는 테이블이 1이고, 이를 foreign key가 생성된 테이블이 * 이 된다. 왜냐하면 하나의 게시글이 여러개의 댓글을 보유할 수 있는 것 처럼 하나의 primary key가 foreign key가 존재하는 테이블에서 여러번 등장할 수 있기 때문이다.
✔️ 더 한가지는,, N대 N관계를 형성할 때 중간에서 매개해주는 연결 테이블과 나머지 2개의 테이블의 관계가 1:1이라고 착각했다. N대 N 관계를 형성할 때 연결 테이블과 각 테이블을 foreign key로 연결되기 때문에 1대 N 관계로 연결시켜줘야 한다.
✔️ 마지막으로 필요한 컬럼에 대해서 모두 테이블에 만들고, 분리시키는 정규화 과정을 거치면 ERD 구성도를 구축하기 훨씬 편하다. 이 생각을 못하고 처음부터 여러 관계를 함께 고려하다보니 정리하는데 복잡함을 느꼈다. 이에 앞으로 모델링을 설계할 때 우선 필요한 컬럼을 다 넣고, 거기에 포함되는 데이터의 특징들을 살펴보며 테이블을 분리하는 편이 좋을 것 같다.
