📌 이 포스팅에서는 배열과 연결리스트의 차이를 비교하는 포스팅입니다.
🌈 배열과 연결리스트 비교
🔥 메모리가 동작하는 방법
🔥 Create : 배열 vs 연결 리스트
🔥 Read : 배열 vs 연결 리스트
🔥 Delete : 배열 vs 연결 리스트
1. 메모리가 동작하는 방법
🤔 물건을 맡긴다고 가정해봅시다.
✔️ 배열이나 연결리스트에 값을 저장하는 방법은 마치 사물함에 짐을 맡기는 방법과 같다.
✔️ 물건 1개를 1개의 사물함에 맡길 수 있다고 했을 때, 2개의 물건이 있다면 2개의 사물함 칸을 빌리면 된다.
✔️ 컴퓨터의 메모리의 동작 방식도 이와 같다. 메모리는 엄청나게 많은 서랍을 가지고 있고, 각 서랍에는 주소가 붙어 이는데, 메모리에 무언가 저장해야할 때마다 컴퓨터에게 공간을 요청하게 된다.
✔️ 배열에 3개의 원소가 있다고 가정하면, 연이은 3개의 메모리 주소를 사용하면 빌리면 된다.
✔️ 이에 여러 개의 원소를 저장해야 한다면 배열 또는 연결리스트라는 두 가지 방법 중 하나를 사용해야 한다.
2. Create : 배열 vs 연결 리스트
🤔 배열의 메모리 동작 방식
✔️ 할일 목록을 메모리에 어딘가 저장해야한다고 가정했을 때, 3개의 할일 목록을 배열에 저장한다면 할 3개의 빈 공간이 있는 곳에 할 일들을 차례데로 저장하면된다.
✔️ 그런데 2개의 할일 이 더 생겨 저장해야 하는데, 이미 연이은 메모리 주소에는 다른 것이 차지하고 있다면 어떻게 할까.
✔️ 마치, 친구들과 영화관에 가서 좌석을 예매하는 것과 같다. 배열은 이처럼 연이어 함께 저장하기 때문에 그 만한 공간이 필요하고, 원소가 추가되었을 때, 연이은 공간이 없다면 전체가 이동해야하는 작업이 필요하다. 즉, 배열에 원소를 추가하는 방법은 느리다.
✔️ 그렇다면, 배열이 많은 공간을 사전에 갖고 있다면 어떨까? 3명이 영화를 보면 되는데, 혹시 누가올 까바 10개의 자리를 빌리는 꼴과 같다. 하지만 추가될 친구가 없다면 이 비용은 모두 낭비가 되는 것이다. 
🤔 연결 리스트의 메모리 동작 방식
✔️ 이런 문제가 발생되는 것을 해결해주는 것이 연결 리스트다. 연결리스트를 사용하면 원소를 메모리 어느 곳이나 둘 수 있다.
✔️ 연결리스트는 각 원소에는 값(할일) 뿐만아니라 다음 원소에 대한 주소가 저장되어 있기 때문이다.
✔️ 따라서 값과 함께 다음 값이 존재하는 위치를 저장해두기 때문에 저장된 공간은 서로 떨어져있지만 서로 하나의 목록으로 연결되어 있는 것이다.
✔️ 연결리스트에 원소가 추가된다는 것은 어떻게 이루어 질까? 그냥 아무 빈 메모리 공간에 원소를 넣고, 그 주소를 바로 앞 원소의 저장해두면 끝이다.
✔️ 이처럼, 연결리스트를 이용하면 불필요한 메모리를 확보하면서 낭비를 일으킬 일도없고, 원소를 다 같이 옮기는 작업이 필요하지 않다.
3. Read : 배열 vs 연결 리스트
🤔 그렇다면 연결리스트가 항상 좋은 걸까?
✔️ 연결리스트에서 3번째 원소의 값이 궁금하다고 할 때, 세번째 원소의 값을 확인하는 방법은 맨 처음 원소를 통해 두번째 원소의 위치를 알아내고, 두번째 원소를 통해 세번째 원소의 위치를 찾아내서 그 값을 확인해야 한다. 이를 순차 접근(sequential access)이라 한다.
✔️ 만약 알고 싶은 값이 연결리스트의 100번째의 값이 있다면, 그 만큼 원소를 통해 이동해야만 한다.
✔️ 이에 반해, 배열은 index만 알고있다면, 100번째에 index의 값을 바로 확인할 수 있다. 100번째 값의 index는 99이기 때문이다. 이를 임의 접근(random access)이라 한다.
✔️ 이 처럼 Read에 있어서는 배열이 연결리스트보다 효율을 갖고 있다. 이를 시간 복잡도로 나타내면 아래와 같다.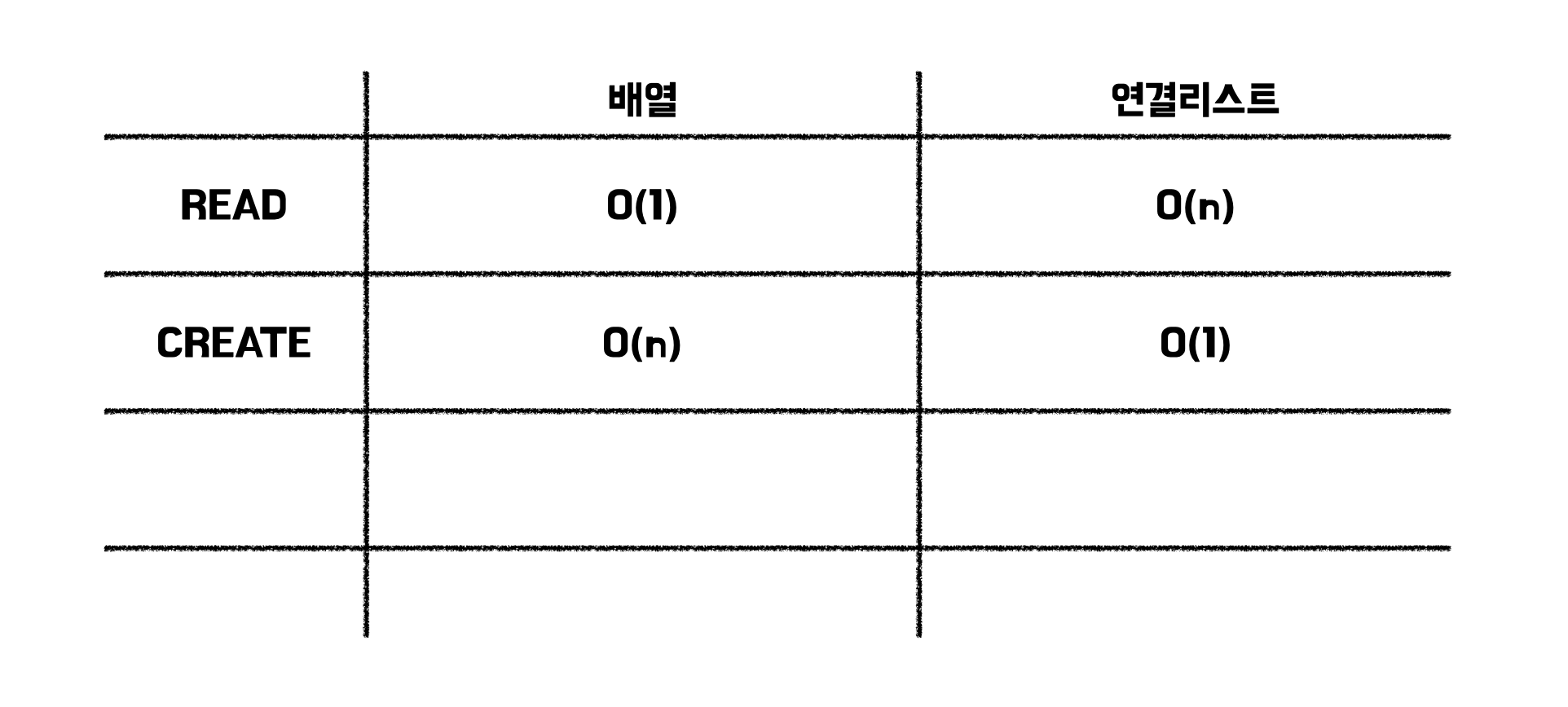
4. Delete : 배열 vs 연결 리스트
🤔 삭제할 때는 어떻게 될까?
✔️ 원소의 삭제도 삽입과 같다. 연결리스트의 경우 이전 원소가 가르키는 위치만 바꾸면 되기 때문에 연결리스트가 훨씬 빠르다.
✔️ 배열에서는 원소 하나만 삭제하고 싶을 때도 모든 것을 다 옮겨야하기 때문에 생성, 삽입과 같이 느리다.
✔️ 단, 배열에서 삭제할 때는 삽입할 때와는 다르게 공간이 없어서 모두를 옮기는 경우는 없다.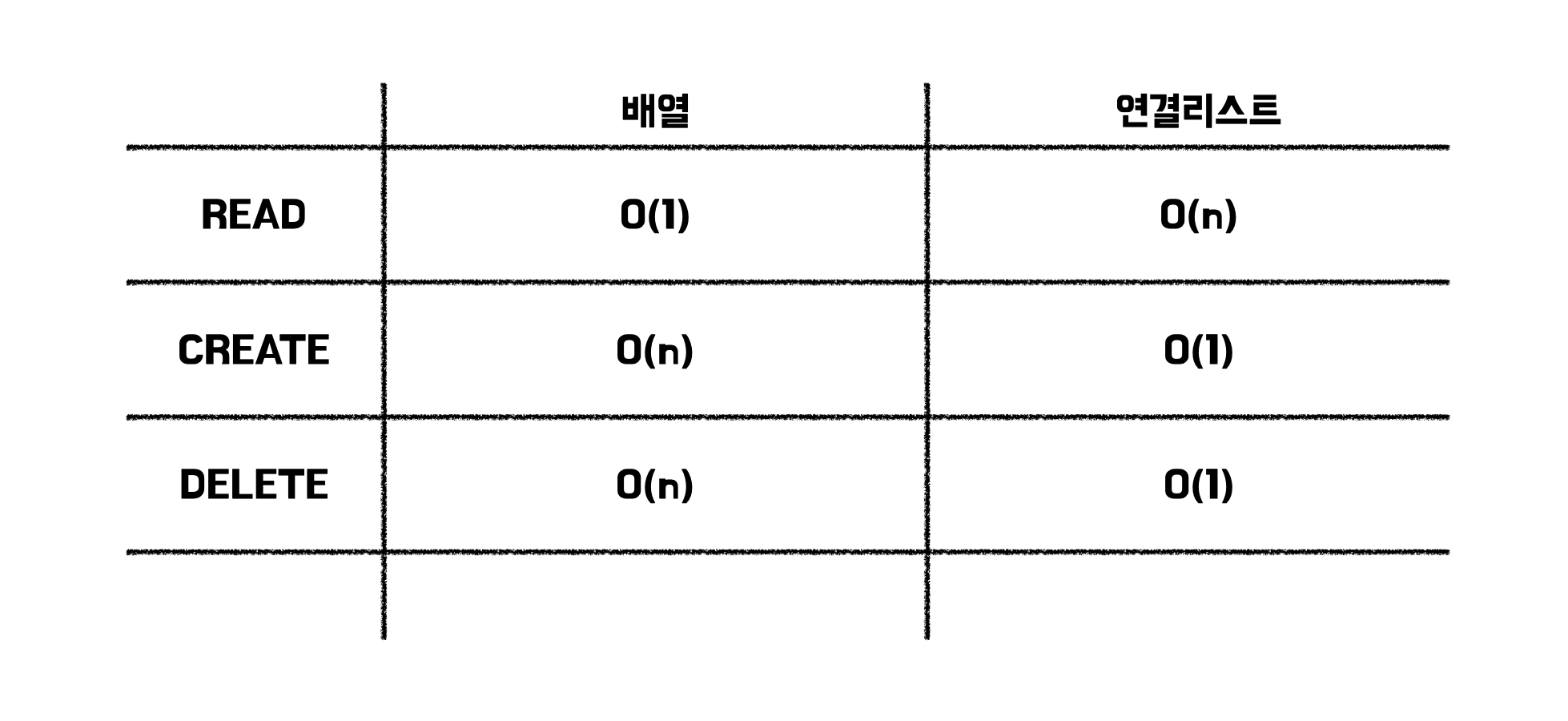
🤔 연결리스트 보다 배열을 더 자주 사용하는 이유가 뭘까?
✔️ 배열은 임의 접근 방식이고, 연결 리스트는 순차 접근 방식이다. 배열의 읽기 속도가 매우 빠른 이유 또한 임의 접근이 가능하기 때문이다.
✔️ 보통 임의 접근을 필요로한 경우가 많이 때문에 배열을 사용하는 경우가 비교적 많다.
