
📌 이 포스팅에서는 WetchaPedia 클론 프로젝트의 데이터 관리를 위해 CSV파일과 uploader.py를 이용하는 방법에 대해 정리하였습니다.
🌈 CSV와 uploader.py 이용하여 데이터 관리
🔥 CSV 데이터란?
🔥 uploader.py로 CSV파일 Django에서 다루기
1. CSV 데이터란?
🤔 CSV(Comma Seperated Value)를 왜 쓸까?
✔️ CSV는 데이터는 쉼표를 기준으로 항목을 구분하여 저장하는 데이터를 말한다. 우리가 알고 있는 엑셀과 유사한 형식의 파일이다. CSV는 콤마로 구분되어 있기 때문에 엑셀과 같은 프로그램으로도 읽을 수 있고, 또 생성할 수도 있다.
✔️ 이에 CSV는 주로 테이블 형태로 구성된 자료나, 텍스트 형태의 자료를 저장할 때 사용한다.
✔️ CSV 파일은 데이터의 크기가 작고, 다양한 애플리케이션에서 활용할 수 있기 때문에 장점을 가지고, 같은 데이터를 저장한다고 할 때 JSON 데이터의 비해 절반 이하의 용량을 사용한다.
✔️ 쉼표 뿐아니라 다른 문자 ($, %, etc.)를 이용하여 구분하도록 지정할 수도 있다. 이는 데이터 내에 콤마가 표현되어있을 때 이 콤마를 다음 column으로 인식할 수 있기 때문에 다른 기호로 대체하기 위함이다. 이는 delimiter를 지정하여 가능하다.
🤔 CSV(Comma Seperated Value) 파일은 어떻게 만들까?
✔️ CSV 파일은 메모장, vscode, 엑셀, numbers 등 아무곳에서나 빈 파일을 열어 콤마로 구분된 데이터를 입력하고 .csv 확장자로 저장하면 된다.
✔️ 만들 때 유의할점은 콤마 사이에 불필요한 띄어쓰기를 하지 않아야 한다.
name,password,email,sex,location testuser1,1q2w3e4r!,test1@gmail.com,male,seoul testuser2,1q2w3e4r!,test2@gmail.com,female,jeju testuser3,1q2w3e4r!,test3@gmail.com,male,busan testuser4,1q2w3e4r!,test4@gmail.com,female,seoul testuser5,1q2w3e4r!,test5@gmail.com,female,incheon
✔️ 위의 csv 파일은 사실 아래의 테이블과 같다. 콤마가 셀을 구분해주기 때문이다. 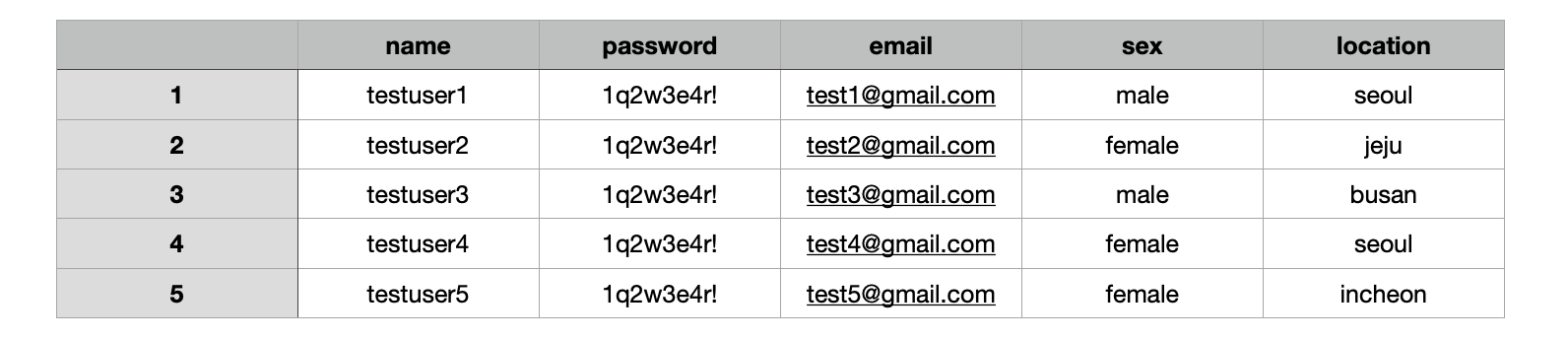
2. uploader.py로 CSV파일 Django에서 다루기
🤔 csv파일을 Django에서 다루는 방법
✔️ 환경변수에 Django 세팅을해준 뒤, django.setup을 호출합니다.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings")
✔️ 테이블을 models.py에서 import한 뒤, csv 파일을 open하여 csv 파일을 읽을 준비를 합니다.
✔️ csv파일에 첫번째 row의 column명이 존재하기 때문에 맨 첫 row를 무시하기 위해서 next함수를 이용합니다.
✔️ for문을 통해 field값에 csv의 data를 매핑해주면서 객체를 생성시킵니다.
✔️ 단, 입력한 필드가 다른 테이블의 id값을 참조하고 있다면, "필드명_id"를 필드값으로 사용합니다.
import os # 👈 os import import django # 👈 django import import csv # 👈 csv import os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings") django.setup() from users.models import User from movies.models import * CSV_PATH_USERS = "csv/users.csv" CSV_PATH_GRADES = "csv/grades.csv" CSV_PATH_MOVIES = "csv/movies.csv" with open(CSV_PATH_USERS) as in_file: data_reader = csv.reader(in_file) next(data_reader, None) for row in data_reader: User.objects.create(name=row[0], password=row[1], email=row[2], profile_image_url=row[3]) with open(CSV_PATH_GRADES) as in_file: data_reader = csv.reader(in_file) next(data_reader, None) for row in data_reader: Grade.objects.create(name=row[0]) with open(CSV_PATH_MOVIES) as in_file: data_reader = csv.reader(in_file) next(data_reader, None) for row in data_reader: Movie.objects.create( title=row[0], poster_image_url=row[1], country=row[2], description=row[3], running_time_in_minute=row[4], released_at=row[5], grade_id=row[6], )
