서론
학습 목표 📖
- 컴퓨가 어떻게 문자를 다루는지 알게 된다
본론
알아보게 된 계기
Buffer 객체를 다룰때에 toString()으로 변환해 사용한다.
왜 toString()을 사용해야 하는지 이는 무엇을 뜻하는지 알아보는 도중 컴퓨터는 어떻게 문자를 다루는지에 대해 알게되었다.
컴퓨터는 문자를 어떻게 다루는가?
Compute = 계산[산출]하다.
er = ~하는 것
computer = 계산하는것(계산기), 산출하는것(산출기)
먼저 컴퓨터의 사전적의미를 해석했을때 위와 같다.
애초에 컴퓨터는 무언가를 계산하기 위해서 만들어졌기 때문에 위와 같은 이름을 갖고 있다.
컴퓨터는 기본적으로 숫자만 다룰 수가 있다.
우리가 무언가를 입력하면 표준 입출력 장치를 통해 버퍼에 데이터가 입력되고 이 데이터는 최종적으로 CPU가 2진수로 바꾸어 처리하게 된다.
그럼 도대체 문자는 어떻게 숫자로 바꾸어서 처리를 하는걸까?
아스키코드의 등장
문자랑 숫자랑 1대1 대응 관계를 만들고 처리하면 되는거 아니에요?
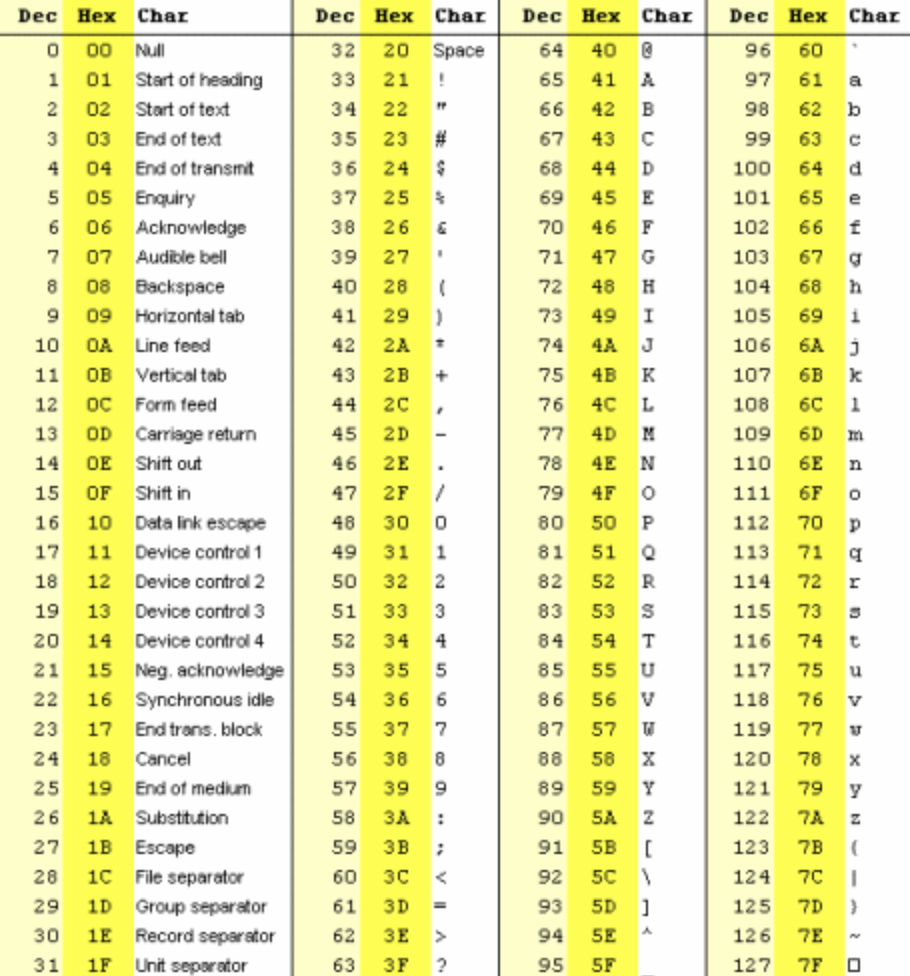
문자를 숫자로 바꾸기 위해 등장한게 아스키코드이다.
어떤 똑똑한 사람이 "문자와 숫자가 1대1로 대응하는 표를 만들어 두고 그에 따라 문자를 숫자로 취급하면 되지 않을까?" 라고 생각을 한 것이다.
그리고 이 체계를 캐릭터셋이라 부른다.
캐릭터셋의 정확한 정의는 "컴퓨터에서 문자를 표현하기 위해, 각 문자를 정수값에 대응시켜 놓은 체계"를 뜻한다.
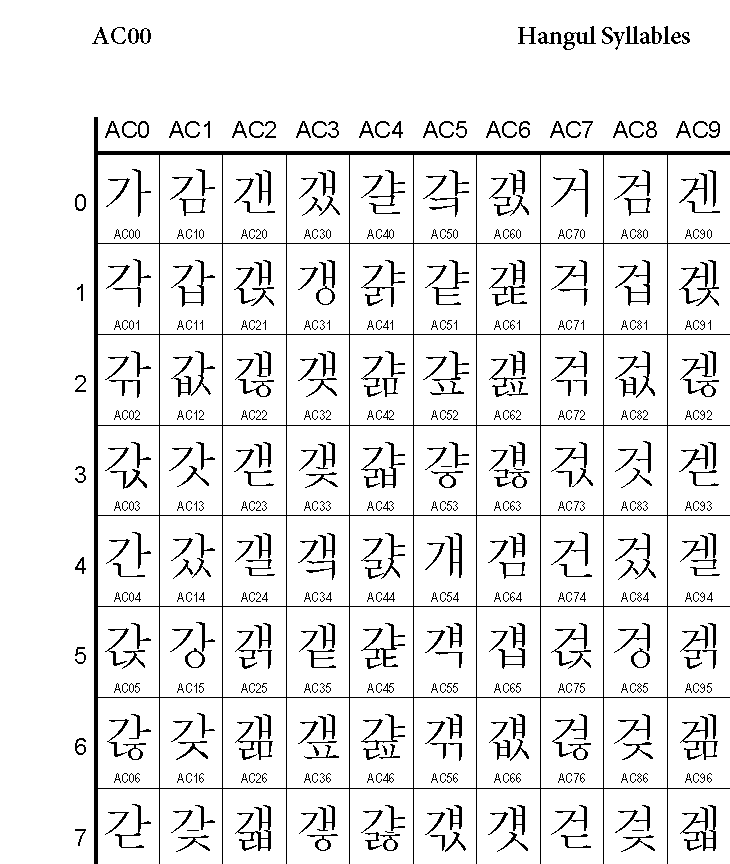
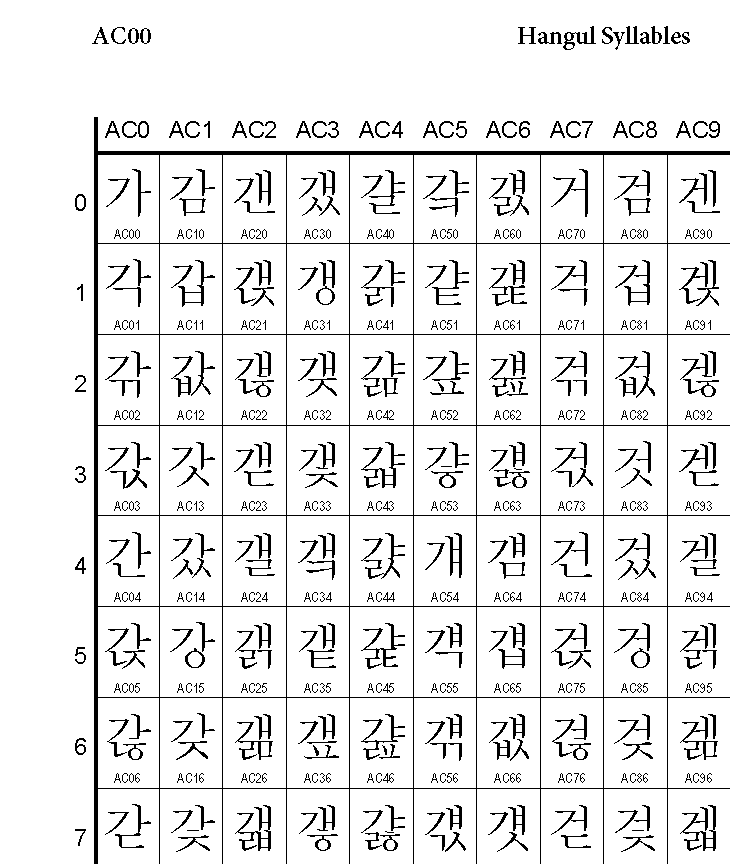
그래서 문자에 숫자를 부여하는 작업이 시작됬고 아래와 같이 완성이 된다.
컴퓨터 입장에서 해석해보자.
'A'가 쓰여진 파일을 읽을때에 41(hex)로 읽고 아스키코드의 내용물들은 1byte로 표현이 가능하니 크기는 1byte가 되며 CPU가 최종적으로는 2진수 형태로 다루며 화면에는 대응관계에 따라 A가 출력되게 된다.
각나라별 캐릭터셋의 등장
아니, 우리나라는 한글쓰는데 한글은 어떻게 표현해요 그럼?
아스키코드는 영어 알파벳만 표현이 가능하였으며 다른 나라의 언어는 표현이 불가능했다.
각나라에서 자기 나라의 언어를 표현하고 싶어했고 이 작업을 각 나라별로 따로 하였다.
우리나라도 진행하였는데 여기서 나온 캐릭터셋이 euc-kr이다.
유니코드의 등장
캐릭터셋 어떤걸로 설정해야되요?
각 나라별 캐릭터셋이 등장하면 끝날 줄 알았더니 또 문제가 생겼다.
나라별로 캐릭터셋에 대응되는 숫자가 겹치는 것이다.
예를들어 우리나라에서 '꿻'이 FF0A인데 아랍어의 한 문자또한 FF0A로 대응표로 작성한 것이다.
어떤 캐릭터셋을 쓰느냐에 따라서 문자가 바뀌는 이러한 문제는 점점 심각해졌고 각 나라별로 모여서 회의를 하였다.
모든 나라의 문자를 담는 하나의 캐릭터셋을 만들고 그것을 사용합시다
이렇게 등장한 것이 유니코드이다.
문자인코딩의 등장
문자가 다 깨지는데요?
이러면 끝날줄 알았는데... 문제가 또 발생했다!
하나의 캐릭터셋에 문자들을 모두 담으려하니까 양이 엄청나게 방대해진 것이다.
한국어, 중국어, 일어, 프랑스어, 독일어, 스페인어 어림잡아도 엄청나다는 것을 알 수 있다.
아스키코드가 0~127이고 1 byte로 표현 가능한 범위는 0~255까지인데 모든 문자들을 담으면 특정 문자를 출력할때에 1byte는 당연히 넘게 된다.
예를들어 8BC2103CE1(hex)를 표현한다고 가정하자.
인코딩이라는게 없다면 어디까지 끊어야될지가 애매하게 된다.
더 쉽게 설명하자마면 "벨로그입니다"를 입력했을때에 ABCDEF0123456789가 입력되었다면 AB/CD/EF 이런식으로 끊어가야 하는지 ABC/DEF/012 이런식으로 끊어가야하는지가 애매하고 어떻게 끊냐에 따라서 "벨로그입니다"는 "꿻뷁쎵쯐뾷쓪"으로 출력되게 된다.
이래서 나온게 문자인코딩이다.
UTf-32는 모든 문자를 4바이트로 잡고 그렇게 끊읍시다.
UTF-16le는 리틀엔디언이고 모든 문자를 2바이트로 잡고 그렇게 끊읍시다.
UTF-16be는 빅엔디언이고 모든 문자를 2바이트로 잡고 그렇게 끊읍시다.
라는 뜻이다.
리틀엔디언, 빅엔디언이 뜻하는 바는 컴퓨터 아키텍쳐를 공부하면 알 수 있다.
UTF-8의 등장
??? : 우리나라는 아스키코드만 써도 되는데 왜 용량 잡아먹게 UTF-32 같은걸 써야됨?
미국입장에서보면 아스키코드로 다 해결이 되는데 UTF-32를 사용하면 4바이트로 끊게되니 용량에서 문제가 생기게 된다.
또한 CPU처리 속도도 1바이트로 표현될것을 4바이트식으로 표현하니까 속도 또한 느려진다.
이래서 등장한것이 UTF-8이다.
UTF-8은 기본은 1byte로 하되 넘어가는 문자는 1byte씩 특정 규칙을 갖고 추가시키는 가변 형태를 의미한다.
위의 유니코드에서 '가'는 'AC00'이므로 2바이트임을 알 수 있다.
결론
컴퓨터가 문자를 표현하기 위해 수많은 과정을 거쳤다는 것을 알 수 있었다.
중요한건 현재 지금 읽고 있는 문자도 사람 눈으로만 문자일 뿐이지 사실 숫자라는 것이다(애초에 숫자를 입력한다고 생각하면 편하다).
따라서 버퍼객체를 확인할때 toString()을 하지 않으면 유니코드에 대응하는 숫자가 나오는 것을 알 수 있다.
