🔈 What is thread ??
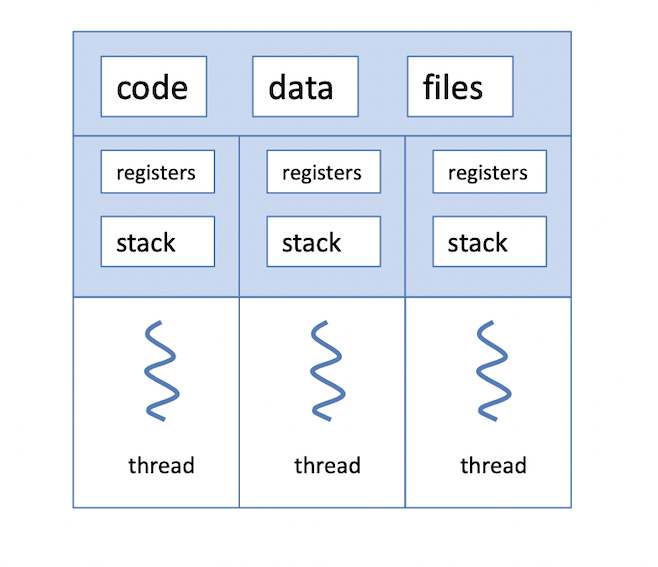
프로세스보다 작은 개념으로 실행의 가장 작은 단위다.
프로세스 간의 communication은 OS를 거쳐야해서 성능이 좋지 않은데
thread는 OS를 거칠 필요가 없어서 성능이 더 좋다.
하지만 thread들끼리 서로 메모리를 공유하기 때문에 사용 시 주의해야한다.
thread끼리는 서로 메모리를 공유하기 때문에 heap, data, text 영역들을 같이 쓸 수 있는데, 예외적으로 stack 영역은 분리되어 있고 register set도 개별적으로 가지고 있다.
❗️ 왜 process 말고 thread를 쓸까 ..?
프로세스는 생성될 때마다 메모리 copy가 필요한데, thread는 관련 정보 데이터 구조만 추가하면 되기 때문에 메모리 측면이나 속도 측면이나 thread를 병렬화해서 사용하는 것이 훨씬 좋다.
- process : fork() & exec() -> 100 ~ 200µs
- thread : pthread_create() -> 10 ~ 20µs
Multi-threading의 장점
- 반응이 빠름
- 기본적으로 system call은 한번 호출하고 나면 값이 return 될 때까지 blocking 상태로 있는데,
- thread가 여러 개면 하나의 thread가 blocking 되어 있어도 다른 thread가 다른 작업을 처리할 수 있다.
- 리소스 공유가 쉬움
- 같은 프로세스 안의 thread들은 메모리를 공유하기 때문에 IPC를 사용하지 않아도 된다.
- 효율적, 경제적
- 확장성(Scalability)이 좋음
- 동일한 환경에서 process가 thread보다 먼저 한계점에 도달한다. (메모리 소비량이 더 크기 때문에)
- thread가 더 scalable함
- 반응이 빠름
⛓ Multicore Programming
core의 개수만큼 병렬적으로 작업할 수 있는 thread의 개수도 늘어난다.
(core의 개수에 따라 병렬성이 높아진다.)
-
Concurrency / Parallelism
-
Concurrency

: 여러 개의 일들을 처리할 수 있는 능력 (반드시 동시에 할 필요 x)
-
Parallelism
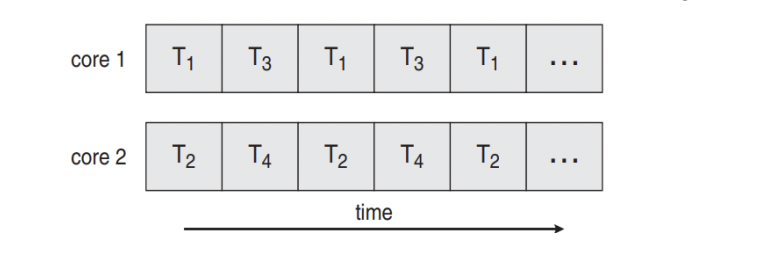
: 여러 개의 일들을 동시에 처리할 수 있는 능력
concurrent하지만 parallel하지 않을 수도 있음
-
-
Hyper-threading
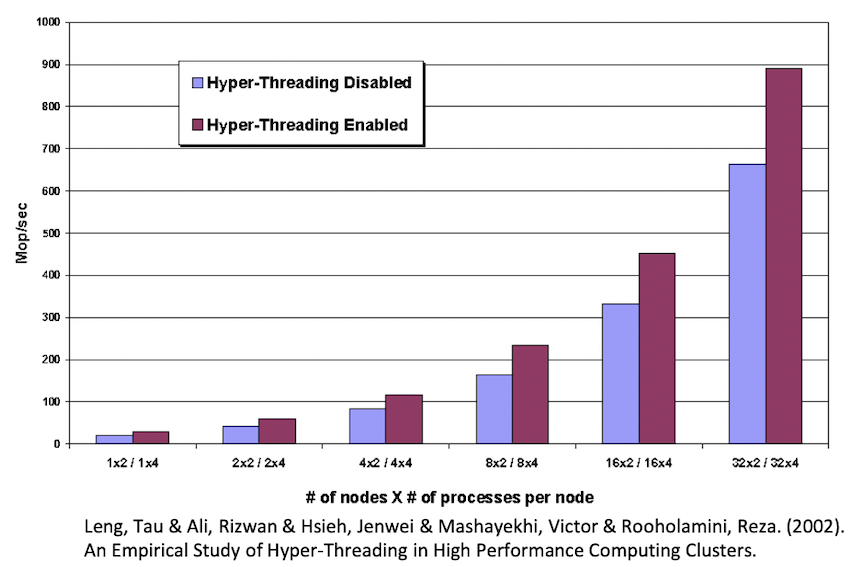
실제 물리적인 코어보다 코어가 2배 더 많게 보여주는 기술
ILP(Instruction Level Parallelism)을 통해 인스트럭션을 수행할 때 중간에 메모리 액세스 등으로 인해 쉬는 경우가 발생하면 다른 인스트럭션을 수행하도록 하는 방식이다.
원래 하나의 CPU에서 남는 시간을 잘 활용해서 마치 2개의 CPU가 동작하는 것처럼 성능을 낸다.
(실제로 core가 2배가 된 것은 아니기 때문에 성능이 2배까지 올라가지는 x)
🪜 Challenges from Multicore
Identifying tasks
- 모든 프로그램 시작부터 끝까지 병렬화 하는 것은 불가능, 일부분만 가능
- 어떤 부분을 얼마나 병렬화 할 수 있는지에 따라 benefit이 다름
Balance
- thread마다 하는 일이 비슷해야 함
- 어떤 thread는 복잡한 일을 하고, 어떤 thread는 간단한 일을 하면 쉬는 코어가 생김
- 동일한 같은 일로 나누는 것이 best
Data splitting
- 데이터도 잘 나눠줘야 함
- n등분 한다고 해결되지는 않음
(다양한 숫자의 데이터가 있는데 하나는 쉬운 숫자의 데이터고 하나는 복잡한 숫자를 계산해야 하면 차이가 있음) - 데이터 내용을 보고 잘 split 해야 함
Data dependency
- 데이터가 한 쪽에서 처리되어 끝나면 그 결과를 다른 thread에 넘겨줘야 하는 경우도 있음
- 이런 경우에는 병렬적으로 작업을 제대로 할 수가 없음
- synchronize를 통해 thread간의 통제가 필요
Testing & debugging
- 다양한 execution path로 인해 race condition에 직면할 수 있음
- 어떤 때는 실행되다가 어떤 때는 안되고 하니까 테스팅이 힘들다.
- 또한 thread 순서에 따라 버그 발현이 달라짐
📂 Parallelism 종류
- Data parallelism
: data를 잘라서 처리할 수 있는 computing core에 잘 분배하는 것 - Task parallelism
: 같은 데이터를 쓰지만, 코어마다 다른 일을 나눠서 주는 것
실제로는 Data parallelism과 Task parallelism이 hybrid로 쓰임
🔎 Multithreading Models
-
User thread / Kernel thread
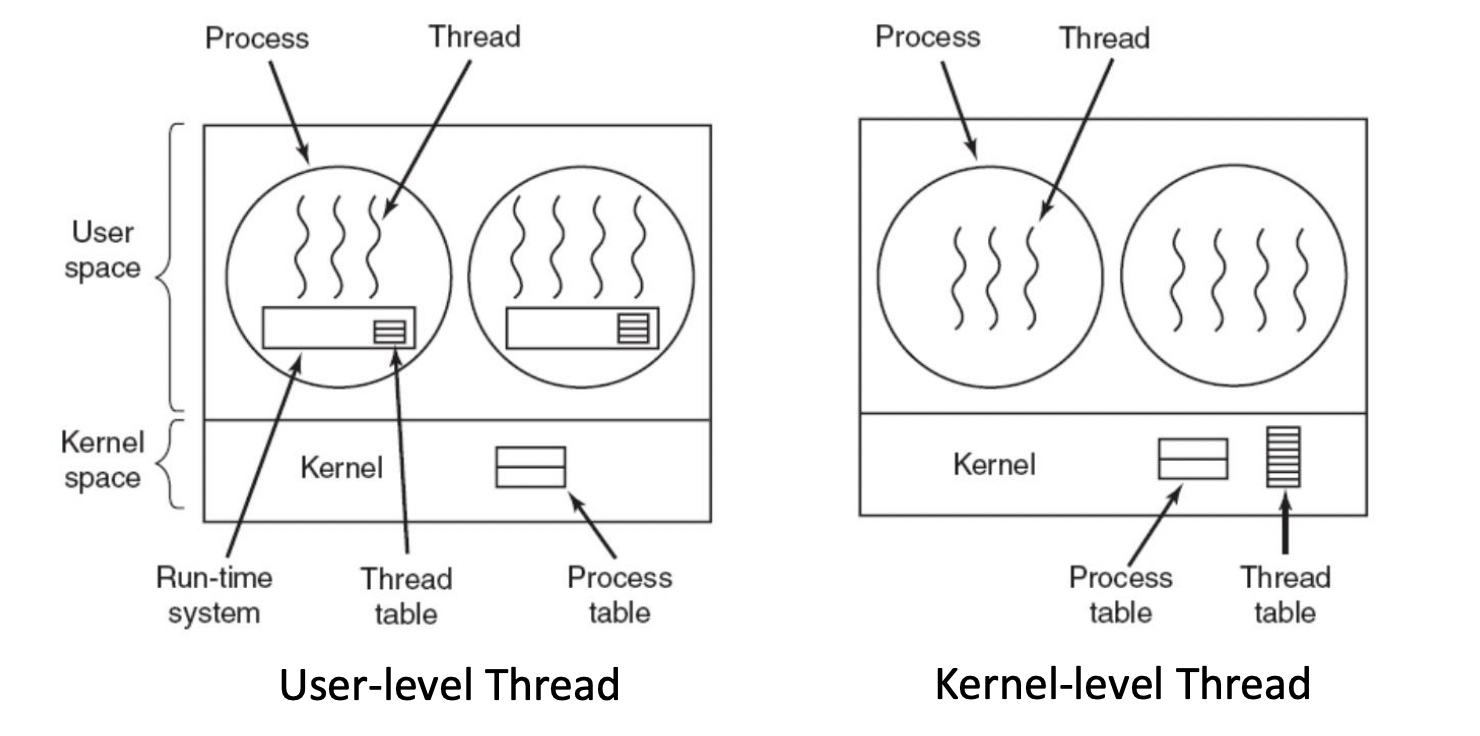
- User thread
- thread의 상태정보를 저장하는 data structure가 user level process 메모리 영역에 저장됨
- thread 관리에 필요한 함수(생성, 삭제, 스케쥴링)가 라이브러리 형태로 프로그램 내에 존재
- OS kernel 입장에서는 user thread가 몇 개 있는지 알 수 없음
- 각각의 프로세스들이 자신이 만든 user thread 목록을 자체적으로 관리
📢 User thread의 장/단점
- 장점
: 모든 thread 관련 작업들이 system call을 사용하지 않는 단순한 library call이기 때문에 비교적 빠르고 가볍다. - 단점
: kernel이 user thread의 존재를 알 수 없어서 스케쥴링을 다르게 할 수도 없고, 한 프로세스가 block 되어버리면 process 내에 있는 user thread들이 다 같이 멈추게 된다.
- 장점
- Kernel thread
- thread의 data structure, 관련 함수들이 kernel 영역에 존재
- kernel이 각각의 모든 thread 관리
- kernel 내부에 현재까지 만들어진 thread들의 table이 있어서 어떤 thread가 어느 프로세스에 속해 있는지에 대한 정보도 가지고 있음
📢 Kernel thread의 장/단점
- 장점
: kernel이 thread를 인식할 수 있어서 하나의 thread가 block 되어버리면 다른 thread를 스케쥴링해서 CPU가 쉬지 않을 수 있다.
또한, 프로세스 내의 thread 개수를 바탕으로 스케쥴링 할 수 있다. - 단점
: 생성하는데 비교적 시간이 더 걸리고, user thread의 data structure보다 field가 더 많고 크다.
- 장점
- User thread
-
Multiplexing User Threads
user thread는 실제 일을 수행하는 thread가 아니다.
application 쪽에서 병렬성의 정도가 어느 정도 되어야 한다는 필요한 병렬성 정도를 자료구조로 만들어 놓은 것이다.
실제로 일을 할 수 있는 것은 kernel thread로 kernel thread 자체가 kernel에 의해 스케쥴링 되어 사용된다.
=> 그래서 user thread를 kernel thread에 mapping 해줘야 kernel thread가 스케쥴링 되면서 user thread가 의도한 일을 진행할 수 있다.❗️mapping 방법은 어떻게 될까 ??
- user thread 내에 있는 thread의 상태 정보를 kernel thread의 data structure 내부로 옮겨준다.
- kernel thread 안의 pointer가 user thread 구조체를 가리키게 한다.
-
N-to-one model
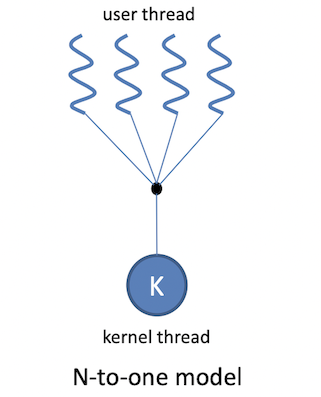
- 장점
- system call이 호출되지 않기 때문에 비교적 빠르다.
- Portable함 (다른 OS에서도 똑같이 user thread를 만들어서 사용 가능)
(user thread 자체는 kernel의 도움을 받아서 생성되는 게 아니라 application process가 자체적으로 관리하기 때문)
- 단점
- kernel thread 1개만 스케쥴링 가능
- 프로세스가 block 되면 모든 thread가 block 된다.
- 장점
-
1-1 model
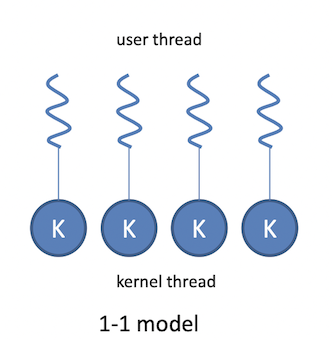
- 장점
- 하나가 block 되어도 다른 thread를 스케쥴링 해서 동작시키면 된다.
- pararell하게 수행 가능 (여러 thread들이 빠르게 time-sharing하면서 concurrent하게 수행되어 병렬적으로 수행되는 것처럼 보이는 방식 말고 진짜 병렬적으로 수행)
- 단점
- user thread에 비해 thread 생성이 느림
- user thread가 많아질수록 kernel thread도 많아지고 그럴수록 kernel 메모리를 많이 쓰게 되어서, user thread를 많이 만들 수 없다. (thread 개수에 한계가 있음)
- 장점
-
Many-to-many model
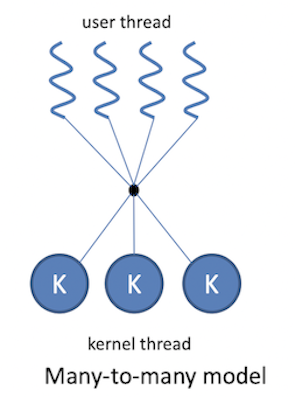
- 장점
- user thread (application이 필요한 만큼)와 kernel thread (물리적으로 가능한 만큼) 둘 다 서로 자신에게 맞는 개수 만큼만 생성하면 되기 때문에 Flexible 함
- 단점
- 동적으로 관리가 이루어지기 때문에 복잡함
- 장점
