데이터 파이프라인과 Airflow 소개
데이터 웨어하우스에 데이터를 적재해주는 프로세스를 데이터 파이프라인
혹은 ETL -> DAG 파일
- spark, hadoop
- real time : kafka, spark stream
- ML : Nosql, kassandra
데이터 웨어하우스에는 다수의 ETL이 있다.
- 이것을 자동화 혹은 주기적으로 실행, 혹은 순서를 정해주는 프레임워크가 필요
-> 이것이 airflow
Dag = Directed Acyclic Graph in airflow
ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통 데이터 엔지니어들이 수행함
ELT : 데이터 웨어하우스 내부 데이터를 조작해서 새로운 데이터를 만드는 프로세스
- 데이터 분석가들이 많이 수행 보통 데이터 레이크위에서 이런 작업들이 벌어지기도함
- 보통 CTAS create table as selected 문법이 일반적/입출력 테스트를 많이 해봐야함. dbt를 자주 이용함
데이터 레이크
훨씬 더 scalable한 데이터 웨어하우스
구조화 데이터 + 비구조화 데이터
스토리지임 - 기한이 없는 모든 데이터를 원래 형태대로
데이터 웨어하우스보다 몇배 더 큰 스토리지
데이터 웨어하우스
보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지
보통 bi 툴들은 데이터 웨어하우스를 백엔드로 사용함
데이터 레이크에서 의미있는 데이터만 데이터 웨어하우스로
DW로부터 데이터를 읽어 다른 storage로 쓰는 ETL
데이터 파이프라인을 만들 때 고려할 점
이상 혹은 환상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것이다.
파이프라인을 관리하는 것은 어렵지 않다.
현실
- 버그
- 데이터 소스상의 이슈(네트워크, 시스템 이슈, 서버이슈)
- 데이터 파이프라인들 간의 의존도에 이해도 부족
데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
소스간의 의존도가 생기면서 더 복잡, 마케팅 채널 정보가 업데이트가 안된다면
마케팅 관련 모든 정보들이 갱신되지 않음
best practices
데이터 소스에서 데이터를 데이터웨어하우스에 복사해올 때
가능하면 데이터가 작을 경우 매번 통채로 복사해서 테이블을 만들기 (full refresh) -> 첫 번째 데이터 부터 다 읽어오기
데이터가 많아지면 불가능해짐
Incremental update 만이 가능하다면, 대상 데이터소스가 갖춰야할 몇 가지 조건이 있음(만약 full refresh가 시간상의 이유로 되지 않을 때)
데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요
created (데이터 업데이트 관점에서 필요하지는 않음)
modified
deleted
데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드를 읽어올 수 있어야함.
만약 데이터 소스가 incremental update를 지원하지 않는 다면, 데이터를 가져올 수 가 없음
best practice 2
멱등성(Idempotency)을 보장하는 것이 중요
동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함
- 예를 들면 중복 데이터가 생기지 말아야함
중요한 포인트는 critical point들이 모두 one atomatic action으로 실행이 되어야 한다는 점
SQL의 transaction이 꼭 필요한 기술
문제가 있다면 데이터의 정합성이 깨지지 않고 깔끔히 실패해야함
Best practice 3
실패한 데이터 파이프라인은 재실행이 쉬어야함
과거 데이터를 다시 채우는 과정 (Backfill)이 쉬어야함
airflow는 특히 이 부분에 강점을 가지고 있음
Full refresh 같은 경우는 파이프라인을 돌리면 다시 복구가 됨
incremental 이라면 특정 날짜가 비어져있다면, 꼭 다시 체크해야함.
앞 단이 소스쪽에서 다 바뀌었다면, 다시 다 copy가 되어야하는데, 이러한 모든 과정을 backfill이라고 한다. 운영이 정상적으로 되고, 소스와 목적지의 데이터가 동일하다. 멱등성이 보장된다.
여러가지 실패 요인이 있을 수 있고, incremental update같은 경우 더 복잡해 질 수 있음. 다시 불러와도 멱등성을 보장해야하고 이러한 것을 backfill이라 통칭한다.
Best practice 4
데이터 파이프라인의 입력과 출력을 명확히 하고 문서화
비즈니스 오너 명시 : 누가 이 데이터를 요청했는지를 기록으로 남길 것
이게 나중에 데이터 카탈로그로 들어가서 데이터 디스커버리에 사용 가능함.
데이터 리니지가 중요해짐 -> 이걸 이해하지 못하면 온갖 종류의 사고 발생
-> 누가 필요했는지, 데이터가 불필요하면 삭제!!
Best practice 5
주기적으로 쓸모 없는 데이터들을 삭제
데이터 레이크 혹은 스토리지
Best practice 6
데이터 파이프라인 사고시 마다 사고 리포트 쓰기 post-mortem
목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
사고 원인 root-cause을 이해하고 이를 방지하기 위한 액션 아이템들의 실행이 중요해짐
기술 부채의 정도를 이야기해주는 바로미터
Best practice 7
중요 데이터 파이프라인의 입력과 출력을 체크하기
아주 간단하게 입력 레코드 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
써머리 테이블을 만들어내고 primary key가 존재한다면 uniqueness가 보장되는지 체크하는 것이 필요함
중복 레코드 체크 (인풋 아웃풋 모두)
-> 데이터 대상 유닛 테스트
간단한 ETL
데이터 웨어하우스는 기본적으로 primary key uniquness를 지원하지 않음.
이것을 어떻게 지키느냐 -> 데이터 엔지니어가 할 일, 멱등성도 보장
대부분 E,T,L 을 함수로 세분화 시켜 진행하는 듯
Airflow
파이썬으로 작성된 데이터 파이프라인 프레임 워크
airbnb 오픈소스 프로젝트
데이터 파이프라인 스케쥴링 지원
ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
backfill이 airflow를 쓰는 가장 큰 이유
데이터 파이프라인이 많아지면 조회하기 힘들어짐.
그래서 중요도 나 팀으로 태그를 달아서 dag에 assign함.
dag의 수가 많아지고 더 많이 실행되면 airflow의 용량이 부족해짐
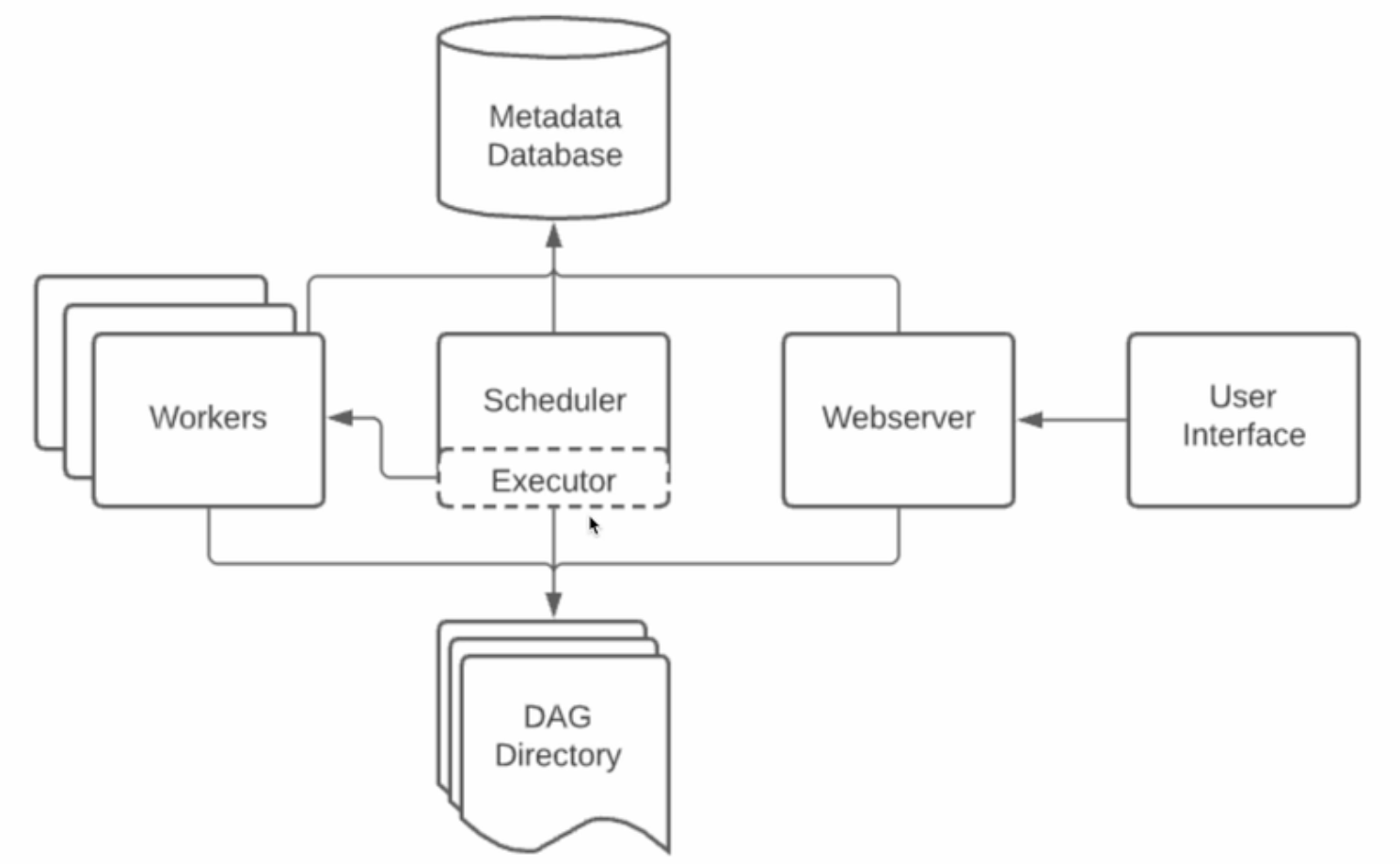
5개의 component
- 웹서버
- 스케쥴러
- 워커
- 메타 데이터 데이터베이스
- sqlite(default) 상황 기록 용도 대부분 mysql,postgres
5.큐(다수서버 구성인 경우에만 사용됨)
- 이 경우 executor가 달라짐
다수의 서버로 airflow를 운영할 때, 워커의 수로 결정됨. 서버의 수를 늘렸을 때, 워커의 용도로 쓰임. 태스크를 어떤 워커가 미리 태스크를 진행할지 정할 수 없기 때문에, 큐에 태스크를 저장하고 워커를 배정
executor가 어떤 것을 쓰냐에 따라서 단일 서버에서도 큐를 사용함
Airflow rntjd
스케쥴러는 DAG를 워커들에게 배정하는 역할을 수행
웹 ui는 스케쥴러와 DAG의 실행 상황을 시각화해줌
워커는 실제로 DAG를 실행하는 역할을 수행
- dag를 구성하는 태스크를 수행
스케쥴러와 각 Dag의 실행결과는 별도 db에 저장됨
웹서버 자체는 Flask로 구현되어 있음
단일 서버로 가면 cpu의 제한이 있다보니깐, 태스크의 가능 양이 정해져 있고, 파이프라인은 더 많아 지기 때문에, worker를 여러개 만들면서 서버를 더 추가해야함. -> scailing 이 필요함.
scale up - 더 좋은 서버
scale down - 관리는 어렵지만 서버 추가 -> 다른 서버는 워커 서버로 추가
다수서버
여러개의 워커 <- 큐 <- 스케쥴러(excutor), webserver -> metadata db
통신은 큐와 함. 스케쥴러가 태스크를 바로 워커로 넘기는 것이 아닌 excutor를 이용함. excutor의 종류에 따라, 큐를 쓰기도 안쓰기도 함.
excutor 종류

단일 서버라면 local excutor를 많이 씀
장점
데이터 파이프라인을 세밀하게 제어 가능
다양한 데이터 소스와 데이터 웨어하우스를 지원
백필이 쉬움
단점
배우기 쉽지 않음
상대적으로 개발환경을 구성하기가 쉽지 않음
직접 운영이 쉽지 않음. 클라우드 버전 사용이 선호됨
aws - managed workflows for apache airflow
gcp - cloud composer
azure - data factory managed airflow
DAG는 무엇인가
directed acyclic graph의 줄임말
airflow의 ETL
DAG는 태스크로 구성됨
3개의 태스크로 구성된다면, E,T,L로 구성
태스크란 - airflow의 오퍼레이터로 만들어짐
airflow에서 이미 다양한 종류의 오퍼레이터를 제공함
경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
redshift writing, postgres query, s3 read/write, hive query, spark job, shell script
airflow 코딩은 DAG 인스턴스를 만들고 -> 스케쥴러, 이름등을 정의해주고 -> 다양한 태스크가 무엇인지 오퍼레이터 형태로 만듬.
DAG 구성 예제
ex)
t1 -> t2 -> t3
3개의 task로 구성된 DAG
순서대로 실행
ex2)
t1 -> t2
-> t3
병렬 구조 실행 t1이 실행되고 2,3가 동시에 실행, 다끝나면 DAG의 실행 완료
