
도입 배경
웨딩플래너 가격비교 컨설팅 서비스를 제공하는 Dears 팀에서는 커뮤니티에서 발생하는 웨딩 관련 질의응답이 매우 반복적이라고 판단했습니다. 매번 유입되는 사람들은 (보통) 웨딩이 처음이기 때문인데요. 때문에 저희는 반복되는 질의응답들을 Gen AI 모델에 학습시켜 웨딩을 처음 준비하는 사람들도 편하게 정보를 물어볼 수 있는 챗봇을 제작하고자 했습니다.
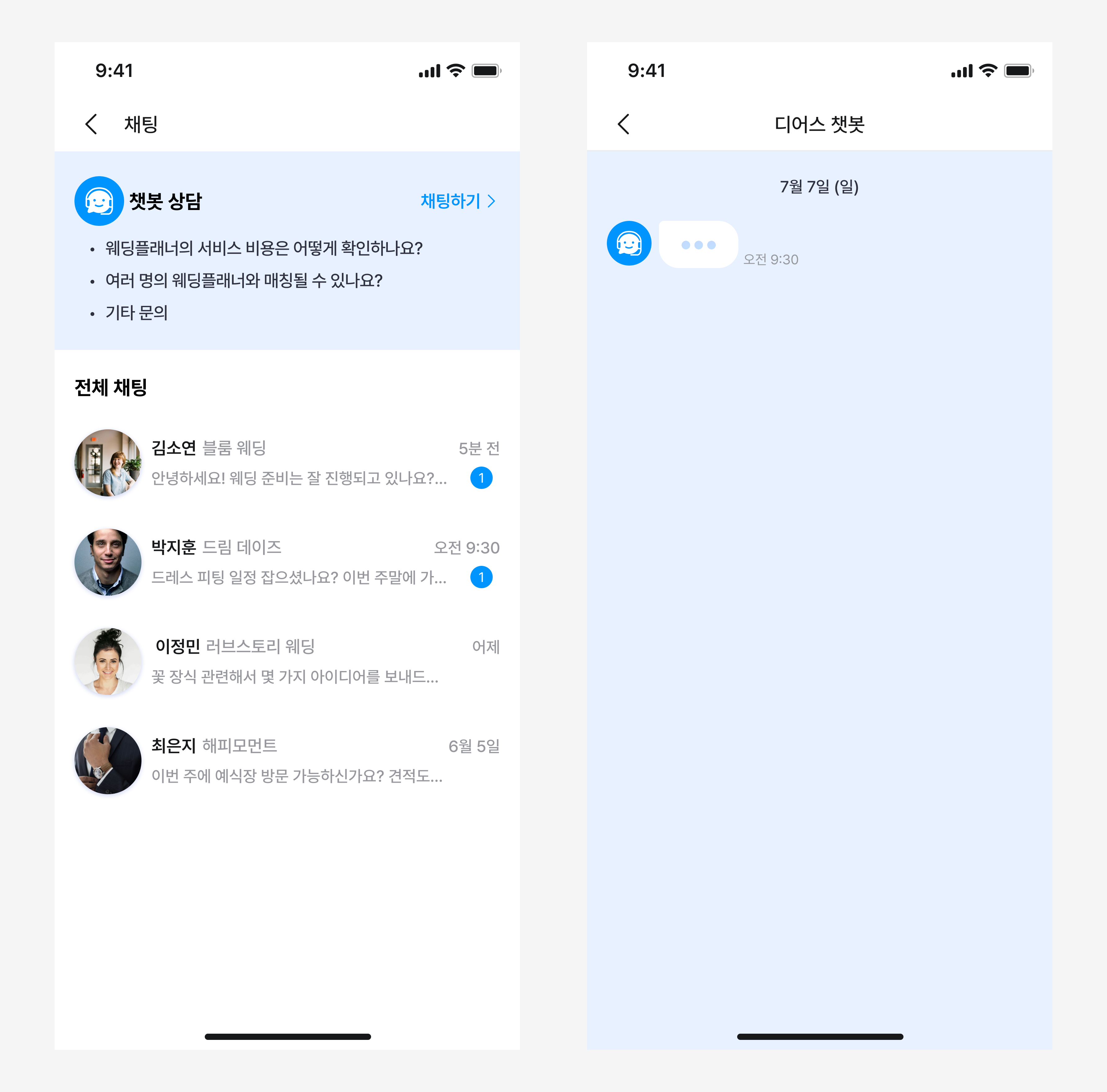
챗봇은 웨딩 도메인을 학습시킨 대화형 LLM을 이용하여 구현하는 것이 좋겠다고 생각했는데요. 먼저 웨딩 도메인 정보를 얻기 위해서 크롤링을 하고, 해당 정보를 fine-tuning으로 학습시켜 LLM 애드온으로 질문에 대한 답변을 생성하고자 했습니다.
웨딩 커뮤니티 크롤링
먼저 웨딩 도메인에 대한 학습이 필요했었습니다. 현재 한국에서 가장 큰 웨딩 커뮤니티는 네이버의 한 카페인데요. 해당 카페의 질의응답 게시판에 접근하여 크롤링을 진행했습니다.
라이브러리 및 환경 변수 설정
.env
NAVER_ID = "MY_ID"
NAVER_PW = "MY_PW"
CAFE_URL = "https://cafe.naver.com/{cafe-name}"민감 정보는 .env 파일로 상수화하여 관리해주었습니다.
import time
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from tqdm import tqdm
from collections import deque
import pyperclip
import json
import pickle
from dotenv import load_dotenv
from pprint import pprint라이브러리는 다음과 같이 사용했습니다.
- Selenium: 웹 브라우저를 자동으로 제어하여 특정 데이터를 가져오는 데 사용됩니다.
- webdriver-manager: Selenium 크롬 드라이버를 자동 설치 및 관리합니다.
- tqdm: 크롤링 진행 상황을 시각적으로 표시합니다.
- pyperclip: 클립보드 복사를 쉽게 지원합니다.
- dotenv: 환경 변수를 관리하여 민감한 정보(ID, PW)를 보호합니다.
- pickle: 객체를 직렬화하여 저장하거나 불러옵니다.
환경설정 및 로그인
# DB Connection
load_dotenv()
op = webdriver.ChromeOptions()
chrome_service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service=chrome_service, options=op)
# 환경 변수에서 로그인 정보 가져오기
NAVER_ID = str(os.environ.get("NAVER_ID"))
NAVER_PW = str(os.environ.get("NAVER_PW"))
# 네이버 로그인 페이지 이동
driver.get("https://nid.naver.com/nidlogin.login")
try:
driver.implicitly_wait(1)
# JavaScript를 이용해 ID와 비밀번호 입력
driver.execute_script("document.getElementsByName('id')[0].value=\'"+ NAVER_ID + "\'")
driver.execute_script("document.getElementsByName('pw')[0].value=\'"+ NAVER_PW + "\'")
driver.find_element(By.XPATH, '//*[@id="log.login"]').click()
time.sleep(1)
except:
print("로그인 요소를 찾을 수 없음")로그인 버튼을 눌러 로그인 하는 과정을 pre-setting하여 자동으로 로그인할 수 있게끔 설정해두었습니다.
크롤링 대상 게시판 설정
CAFE_URL = str(os.environ.get("CAFE_URL"))
board_dict = {"{board_name}": "{board_id}"}
board_keys = list(board_dict.keys())
driver.get(CAFE_URL)
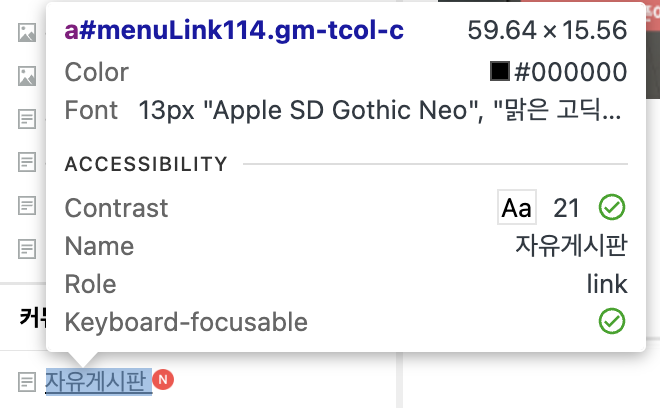
게시판의 이름과 고유 식별자를 딕셔너리로 관리하여 원하는 게시판으로 이동하도록 설정합니다. 고유 식별자는 cmd + shift + c로 개발자도구를 이용하여 버튼 위 hover했을 때 알 수 있습니다. 예시로 위의 사진에서 board_name은 자유게시판, board_id는 114가 됩니다.
게시판 크롤링 및 데이터 수집
data = {}
for board in board_keys:
# 게시판으로 이동
board = driver.find_element(By.CSS_SELECTOR, f"#menuLink{board_dict[board]}")
driver.implicitly_wait(3)
board.click()
# 게시물 읽기 및 데이터 수집
driver.switch_to.frame("cafe_main")
for i in tqdm(range(1, num_counts)):
try:
cont_url = driver.find_element(By.XPATH, '//*[@id="spiButton"]').get_attribute('data-url')
cont_title = driver.find_element(By.CLASS_NAME, 'title_text').text
cont_text = driver.find_element(By.CLASS_NAME, 'se-module-text').text
cont_comments = driver.find_elements(By.CLASS_NAME, 'text_comment')
comments = '\n'.join([comment.text for comment in cont_comments])
# 데이터 저장
data["messages"] = [
{"role": "system", "content": "웨딩 관련 Q&A 챗봇 학습용 데이터"},
{"role": "user", "content": f"제목: {cont_title}, 본문: {cont_text}"},
{"role": "assistant", "content": f"댓글 목록: {comments}"}
]
except:
pass게시판 내의 각 게시물을 탐색하며 제목, 본문, 댓글 등의 데이터를 추출합니다. 데이터는 아래와 같이 JSONL 형식으로 저장됩니다.

{
"messages": [
{
"role": "system",
"content": "너는 웨딩 관련 정보를 알려주는 Q&A 챗봇이야. 웨딩 커뮤니티 질문 게시판에서 가져온 질문과 응답을 학습해서 답변해줘야 해."
},
{
"role": "user",
"content": "제목: 성혼선언 다들 하시나ㅏ요??, 본문: 신부 아버지가 하는걸까요"
},
{
"role": "assistant",
"content": "댓글 목록: 저는 꼭 필요한가 싶은데\n최근에 몇 번 하객으로 갔는데 사회자분들이 다들 하더라구요\n아버님이 해주셨는데 사회자가 하기도 하더라구요\n저는 식순이 너무 비어보여서 그냥 했어요. 보통 사회자분이 해주시더라구요."
}
]
},
...해당 형식은 GPT 3.5-turbo 모델에 대한 fine-tuning을 위한 형식이기 때문에, 다른 모델을 사용한다면 해당 모델 학습에 적합한 format으로 저장해야 합니다.
감사하게도 이 커뮤니티에서는 방대한 정보가 오고 갔습니다. 커뮤니티 활성화가 잘 되어 있어서 디테일한 질문이 많았고, 평균 5개에서 20개의 답변이 달리는 양상이었습니다. 덕분에 지엽적인 부분에도 양질의 데이터를 얻어낼 수 있었습니다.
full-script는 아래 dears-ai/crolling.py에서 확인할 수 있습니다.
크롤링 주의점
우선 웹 크롤링 행위 자체는 불법이 아닙니다. 웹 크롤링 자체는 브라우저를 조작하여 웹사이트 데이터를 요청하고 받아내는 것을 자동화하는 것에 불과합니다. 그럼에도 하기의 경우 문제가 될 수 있다는 것을 참고해야 합니다.
- 수집한 데이터를 상업적으로 사용하는 경우
- 크롤링을 통해 상대 서버에 문제를 일으킨 경우
저희는 현재 비상업적 프로젝트이기도 했고, 봇 의심 회피 및 request 과부하 방지를 위해 time.sleep()으로 delay fetching 했기 때문에 문제가 없었습니다. 꼭 소개한 2가지 경우에 해당하지 않는 경우 크롤링을 시도하기를 권장드립니다.
fine-tuning
이제 지금까지 모은 jsonl 데이터를 바탕으로 모델을 학습시켜야 합니다. OpenAI 모델의 경우 OpenAI api 웹사이트에서 fine-tuning 할 수 있습니다.
OpenAI fine-tuning은 지금까지 모은 jsonl 파일을 넣어주기만 하면 되므로, 매우 간단한 것이 장점입니다.
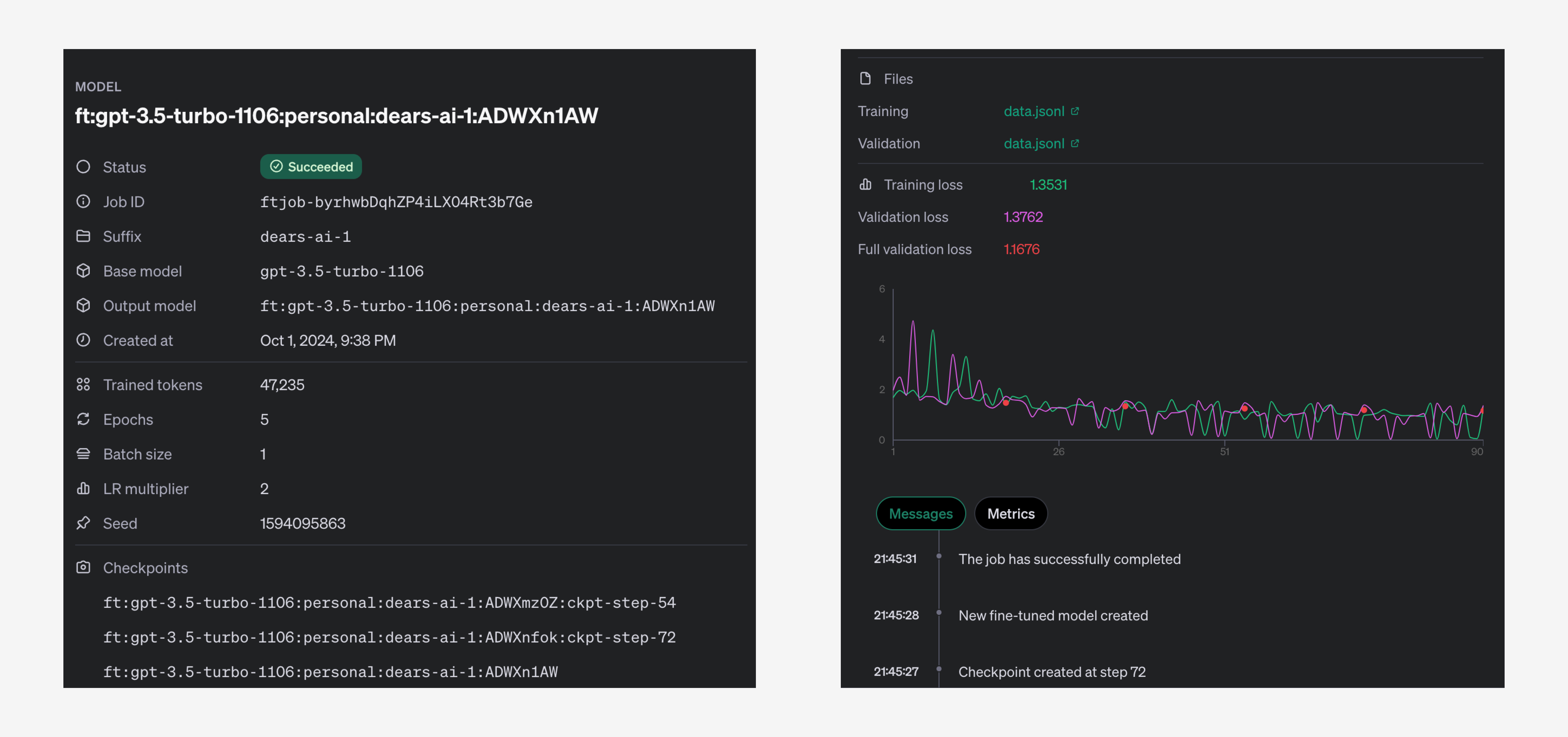
다음과 같이 기존 3.5-turbo 모델을 바탕으로 학습을 진행했으며, 학습 완료된 fine-tuned 모델에 추가로 jsonl 데이터를 넣어 강화된 모델을 만드는 것도 가능합니다.
Spring-AI
이제 크롤링으로 데이터도 모았고, fine-tuning으로 학습도 시켰으니 API로 답변을 전달해줘야겠죠.
보통은 python 서버를 하나 더 구축해서 Spring 서버에 연결하는 방식이 무난한 방법이겠지만, Spring AI의 지원으로 간단한 LLM 애드온을 붙일 수 있었습니다.
Spring AI는 Spring 생태계에 추가된 LLM 핸들링 패키지입니다.
보통 파이썬에서 LangChain이 선호되듯, Java 서버 엔지니어들은 가능한 많은 것을 Spring 생태계에서 해결하고 싶어 합니다. 저 역시 그랬기 때문에, Spring AI를 도입하는 것이 빠르게 기능을 개발할 수 있겠다고 판단했습니다.
의존성 추가
build.gradle
//spring ai - openai
implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter:1.0.0-SNAPSHOT'application.yml
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-3.5-turbo
temperature: 0.5그리고 OPENAI_API_KEY와 사용할 model, 응답에 대한 temparture를 지정해줍니다.
temperature : 얼마나 일관된 답변을 반환하는지 정도
일관됨(0) ~ 창의적(1)
저희의 경우에는 OpenAI 3.5 turbo model을 사용했기 때문에 관련 의존성을 설치해주었습니다. Lamma, Claude 등 OpenAI 이외의 진영 역시 사용가능하기 때문에 적합한 의존성을 설정해주면 됩니다.
Prompt engineering
private static final String PERSONA_PROMPTING =
"넌 한국의 웨딩플래너 전문가야. 질문자의 의도를 분석해서 제안하는 답변을 해줘.";
private static final String CHAIN_OF_THOUGHT =
"우선 지금까지 학습된 커뮤니티 질의응답 데이터를 바탕으로 비슷한 질문이 있는지 찾아보고, " +
"댓글 중 적절한 답변을 정리해서 추려줘.";
private static final String RULE_BASED_PROMPTING =
"비속어는 무조건 필터링 혹은 순화해서 표현해야 해. " +
"웨딩과 너무 연관 없는 질문은 '웨딩에 대한 질문이 아닌 것 같아요. 다른 질문이 있으신가요?'와 같은 답변으로 대화를 이어가야 해.";
private static final String ADDITIONAL_INFORMATION =
"질문자가 원하는 답변을 찾지 못했을 경우에는 '질문을 이해하지 못 했어요. 다시 질문해주세요.'라고 말해줘. " +
"혹은 사용자가 '고마워요' 등 대화를 종료하는 말을 하면, " +
"'도움이 필요할 때 언제든지 말씀해주세요!' 와 같은 답변으로 대화를 자연스럽게 끝맺어줘.";
public String getAnswer(String message) {
String answer = chatClient.prompt()
.system(
PERSONA_PROMPTING + "\n" +
CHAIN_OF_THOUGHT + "\n" +
RULE_BASED_PROMPTING + "\n" +
ADDITIONAL_INFORMATION
)
.user(message)
.call()
.content();
Question question = Question.builder()
.question(message)
.answer(answer)
.build();
questionRepository.save(question);
return answer;
}

가독성을 위해서 코드를 담은 이미지를 첨부했습니다. 저는 아래와 같은 4가지 Prompt Engineering 기법을 적용했습니다.
- Persona Prompting : 웨딩플래너 전문가로서 질문자의 의도를 분석하고 최적의 답변을 제공하도록 설계
- Chain of Thought : 커뮤니티 데이터를 바탕으로 비슷한 질문을 검색하고, 적절한 답변을 정리
- Rule-Based Prompting : 비속어를 순화하고 웨딩과 무관한 질문은 대화 방향을 재조정
- Additional Information : 답변 실패 시 다시 질문을 요청하거나 대화를 자연스럽게 종료하도록 설계
Result
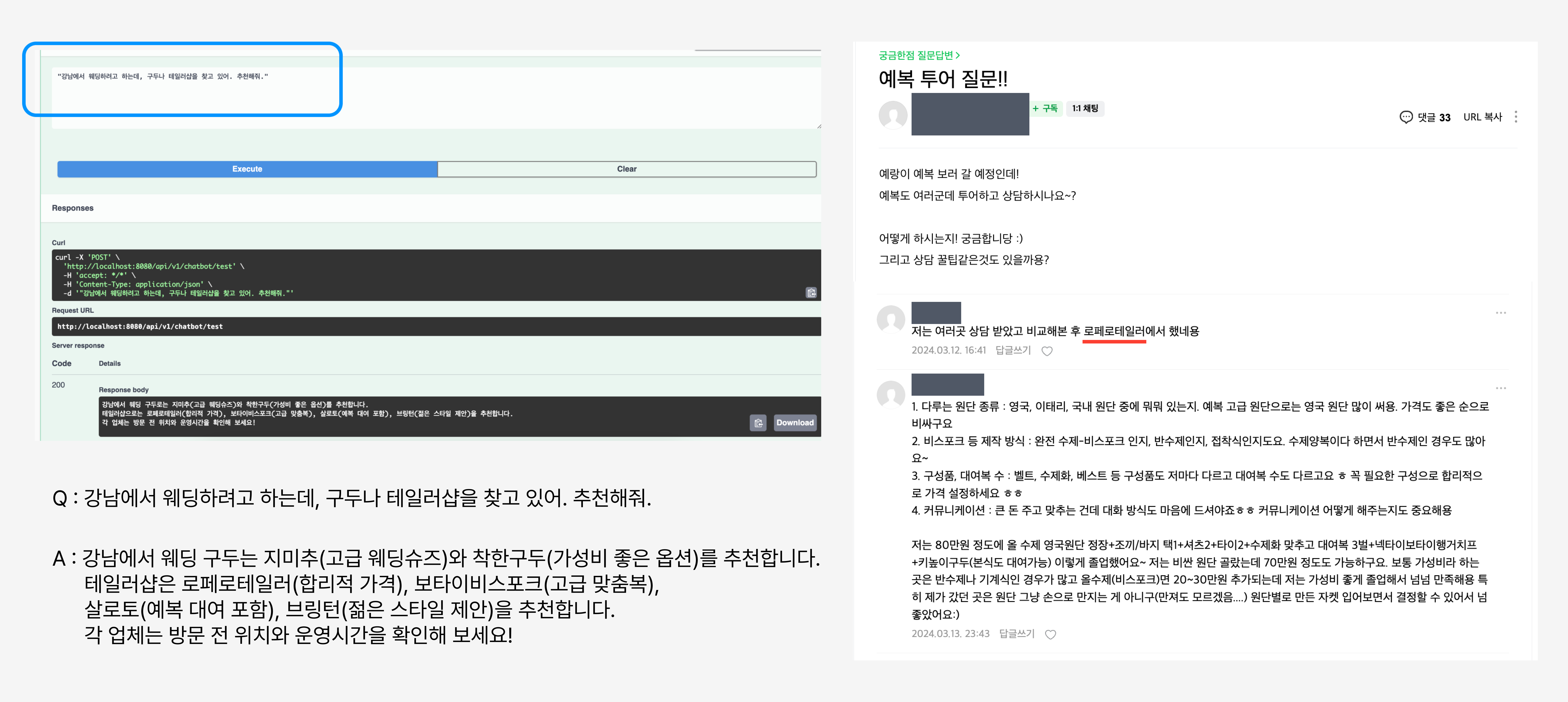
다음과 같이 강남에서 웨딩하려고 하는데, 구두나 테일러샵을 찾고 있어. 추천해줘. 라는 지엽적인 프롬프트임에도, 지미추, 로퍼로테일러, 보타이비스포크 등 실제 커뮤니티에서 많이 추천되는 업체를 추천해주는 것을 확인할 수 있습니다.
References
