Norm
- Norm 은 벡터의 크기(혹은 길이)를 측정하는 방법(혹은 함수)이다.
- 또는 두 벡터 사이의 거리를 측정하는 방법이기도 하다.
L1 Norm
L1 Norm은 벡터의 각 원소들의 차이의 절대값의 합이다.
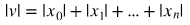
L2 Norm
L2 Norm은 벡터 p,q의 직선거리이다. q가 원점이라면 p,q의 L2 Norm은 벡터 p의 원점으로부터의 직선거리라고 할 수 있다.
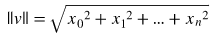
파이썬으로 L1 L2 Norm 구현 해보기
# numpy 라이브러리 필요
import numpy as np
arr = np.array([1,2,3])
#np.linalg.norm() 함수를 사용, ord = 1 인 경우가 L1 Norm, 아닌경우가 L2 Norm
print(np.linalg.norm(arr, ord=1))
print(np.linalg.norm(arr))
#출력결과
#6.0
#3.7416573867739413Error
- MSE: 평균 제곱 오차
- MAE: 절대값 제곱 오차
MSE
간단히 말하자면 오차의 제곱에 대해 평균을 취한 것이다.
-> 작을 수록 원본과의 오차가 적은 것이니까 추측한 값의 정확성이 높다고 판단할 수 있다.
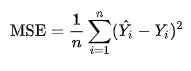
MAE
간단히 말하자면 모든 절대 오차의 평균이다.
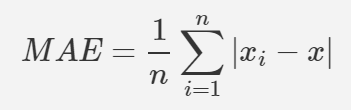
MSE 와 MAE의 차이점?
-> 둘의 사용하는 방법이 다르다.
- MSE는 회귀에서 자주 사용되는 손실 함수이다.
- 일반적인 회귀 지표는 MAE 이다.
따라서 MSE는 손실 함수로써 쓰이고, MAE는 회귀 지표로써 쓰인다.
파이썬으로 MSE MAE 구현 해보기
# MSE MAE 함수를 쓸수있는 sklearn.metrics 라이브러리 불러오기
from sklearn.metrics import mean_absolute_error as mae
from sklearn.metrics import mean_squared_error as mse
def error(x, y, type) :
MAE = mae(x,y)
MSE = mse(x,y)
if type == 'MAE':
return MAE
elif type == 'MSE':
return MSE
print(error(np.array([1, 2, 4]), np.array([3, 4, 3]), 'MSE'))
print(error(np.array([1, 2, 4]), np.array([3, 4, 3]), 'MAE'))
#출력결과
#3.0
#1.6666666666666667Inverse
역행렬
- 수에 역수가 있다면, 행렬에는 역행렬이 존재한다.
- 단위행렬 E를 나오게 하는 행렬을 행렬 A의 역행렬이라 한다.
- 역행렬이 존재하려면 n차 정사각행렬이여야 한다.
역행렬 공식

파이썬으로 역행렬 구현해보기
import numpy as np
# 행렬의 determinant값이 0인 경우에 오류 발생 -> -1 반환한다.
def myInverse(m) : # m = np.array()
try:
return np.linalg.inv(m)
except:
return -1
#출력 결과
#[[-2. 1. ]
#[ 1.5 -0.5]]

설명 너무 감사합니다. 기본 개념을 알고 싶었는데. 글 정리가 너무 잘 되어 있습니다.