Target
https://arxiv.org/abs/1706.03762
- 2017년 공개 이후 NLP 분야뿐만 아니라 Vision 분야에서도 다방면으로 이용되는 Transformer (Attention is all you need) 에 대한 논문 리뷰 진행
- 해당 논문 내용 중 학습 및 학습 결과에 대한 내용은 제외함.
키워드
- Self-Attention
- Encoder, Decoder
- Transformer
배경
- seq2seq 구조인 encoder, decoder 구조와 RNN을 활용하지 않은 Attention 구조를 결합한 모델 :
https://github.com/pranoyr/seq-to-seq- 특정 시점에서 구한 hiddence state에는 이전 Sequence들의 정보를 함축하고 있음
- 이후 내용에서 언급하듯, 메모리와 컴퓨팅적 부분의 한계로 인해 embedded vector의 최대 길이를 제한해야하는 단점 존재
기본 개념
- sequence modeling (기초)
- Sequence를 가지는 데이터로부터 또 다른 Sequence를 가지는 데이터를 생성하는 과정 (Task)
ex) Chatbot, translation(machine)
- 대부분 LSTM이나 GRU를 주축으로 이용하였음.
- 하지만, 모든 데이터를 한번에 처리하는 것이 아니라, Sequence 순서에 따라 순차적으로 입력해주어야 함.
→ 이는 메모리와 컴퓨팅적 부분애서 많은 부담이 발생한다. - Attention
- Sequence modeling에서 이용되던 성능 좋은 기법
- Input 혹은 Output 데이터에서 Sequence distance와 무관하게 서로 간의 dependency를 모델링함
- 해당 논문에서 제시하는 Transformer는 해당 메커니즘을 전적으로 활용하여, 모든 아키텍쳐를 해당 Attention만을 활용하여 구축함으로써 효율성과 엄청난 성능을 실험을 통해 보여줌
모델 아키텍쳐
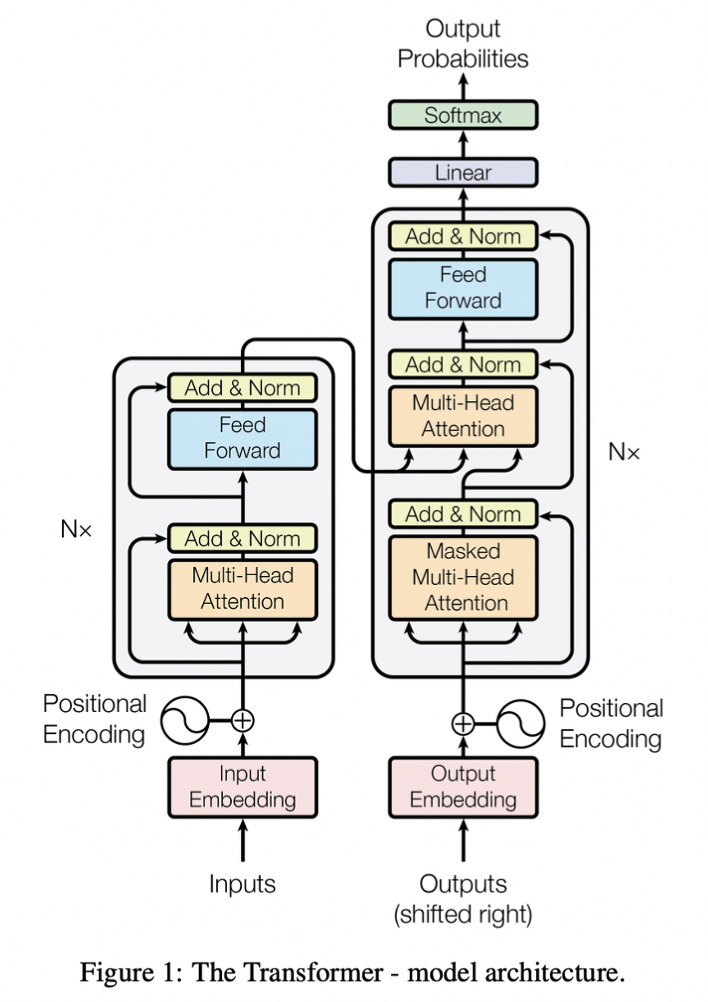
- self-attention [특정 문장이 있을 때, 자기 자신 문장 스스로에게 attention을 수행 해 학습] 구조 + Fully Connected layer 구조
- Why self-attention?
- 각 레이어별로 계산 복잡도 감소
- 회귀 (Recurrent) 과정을 줄임으로써 더 많은 양을 병렬처리 할 수 있음
- Why self-attention?
- Sequential한 데이터가 input으로 들어왔을 때, transformer를 통과해서 output이 나오는데, RNN 구조 (encoder → Decoder) 와 비슷하지만, transformer는 encoder, decoder가 각각 컴포넌트 구조로 이루어져 있음
- 작동 구조
-
Input Embedding- input 들어오면 Input Embedding을 통해 Vector로 변환하는 작업 수행
- 첫 번째 encoder의 입력으로만 이용, 두 번째 encoder부터의 입력은 이전 encoder의 output을 이용
-
Position Encoding- transformer가 한번에 전체 Sequence를 입력받기때문에
위치 정보를 담을 수 없어각각의 단어가 가지고 있는 위치 정보를 보존하기 위한 목적으로 이용
- transformer가 한번에 전체 Sequence를 입력받기때문에
-
Input Embedding + Position Encoding을 합하여 새로운 512차원의 백터를 생성함
- pos = 위치, i = 차원 (해당 위치의 Embedding)
- 두 단어의 거리가 멀어지면, Position encoding 사이의 거리도 멀어짐 = Value가 커짐 -
Encoder
- Selt-attention → Feed Forward 순서
- Self-attention layer : 하나의 단어를 처리 시도 시, 함께 주어진 input sequence의 다른 단어들의 중요도를 어떻게 설정할 것인가에 대한 Layer
- Attention 메커니즘 (Self-attention)
- 특정 출력 단어를 예측하는 매 시점마다, encoder의 전체 문장 중 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀더 집중하도록 함.
- Query, key-value 집합 쌍을 query, keys, values, output이 모두 벡터인 output에 매핑
- Query (Q) : 영향을 받는 벡터 = 대상 단어(대상 표현)
- Key (K) : 영향을 주는 벡터 = Query 기준으로 찾는 대상
- Value (V) : 주는 영향의 가중치 벡터 = Key가 가지고 있는 실제 값
- Output은 Values 결과의 weighted sum으로 계산
- 각 value에 할당된 weight는 query와 해당 Key의 Compatibility function에 의해 계산
- 1) 각 Encoder의 input vector에 대한 Query, key, value 벡터 생성
- 512 차원으로 이루어져 있었던 벡터들을 64차원의 Q, K, V로 변환
- 이후 Decoder (Multi-head attention) 단계에서, 해당 변환된 값들을 모두 concatenation, 이후 Encoder 및 Decoder의 Output으로 이용 → 추후 512차원으로 다시 변환
- 2) 현재 진행중인 대상의 input과 유사도가 높은 정보를 찾기 위해 현재 보고 있는 Query 벡터와 Key 벡터를 곱
- 3) Softmax 함수를 통해 정규화 → 문장 내 각 단어가 해당 문장 내 전체 단어와 얼마나 연관되어있는지 확인
- 4) 가지고 있는 단어들의 Value와 Softmax 값을 곱한 뒤 현재 진행 중인 대상의 최종 Output으로 사용
- Attention 메커니즘 (Self-attention)
- Self-attention layer : 하나의 단어를 처리 시도 시, 함께 주어진 input sequence의 다른 단어들의 중요도를 어떻게 설정할 것인가에 대한 Layer
- Multi-head attention
- 해당 논문에서는 8개의 attention head를 이용
하나의 경우의 수만 보는것이 아니라, 여러개의 경우의 수를 고려한다라고 이해하기- 각 단어별로 개별적인 attention을 만든 뒤, 전부 concatenation
- W0 (가중치 - Weight)
- Q, K, V별로 각각의 Weight Matrix 생성
- 최종적으로 원래 input embedding 과 같은 차원의 행을 같은 Matrix를 설계함.
- Add & Normalize Block
- Residual connection [H(x) = x + F(x)]
- 계산 과정 중 미분 진행 시, f’(x)+1 이기에, f’(x) 값이 작더라도 최소 1만큼은 증가하기에 학습 진행 시 유리함.
- Layer Normalization
- 각 레이어의 값이 크게 변화하는 것을 방지
- 해당 과정은 각각의 block 마다 진행함.
- Residual connection [H(x) = x + F(x)]
- 이후 feed-forward network 통과함.
- Selt-attention → Feed Forward 순서
-
Masked multi-head attention
- Encoder 단계에서는
순차적으로 처리할 필요없이 한번에 들고오기에, 모든 Sequence를 masking 하지 않는 unmasked 방식을 차용 - Decoder 단계에서는
현재 시점의 예측에서, 현재 시점보다 미래에 있는 단어를 참고할 수 없도록 -inf 값으로 masking, 이후 softmax 계산 시 0이 되도록하면서 attention score가 오르지 않도록 함.
- Encoder 단계에서는
-

성장 += 지식