Reactor
- 리액티브 스트림즈(Reactive Streams) 표준 사양을 구현한 구현체 중 하나
- Spring 5 버전부터 지원하는 리액티브 스택에 포함됨
- 리액티브한 애플리케이션으로 동작하는데 있어 핵심적인 역할을 담당하는 리액티브 프로그래밍을 위한 라이브러리
특징
- 리액티브 스트림즈를 구현한 리액티브 라이브러리
Non-Blocking통신을 지원
➡️ 요청 쓰레드가 차단되지 않음Non-Blocking: 리액티브 프로그래밍의 핵심적인 특징
- Publisher 타입으로
Mono[0|1]와Flux[N]타입을 제공Mono[0|1]: 0과 1의 의미는 0건 또는 1건의 데이터를 emit 할 수 있음을 의미Flux[N]: N의 의미는 여러 건의 데이터를 emit할 수 있음을 의미
- MSA 구조에 적합한 라이브러리
➡️ 서비스들 간의 통신이 잦은 MSA 기반 애플리케이션은 요청 쓰레드가 차단되는Blocking통신을 사용하기에 무리가 있음
➡️Non-Blocking통신을 완벽하게 지원하는 라이브러리여야 함 - Backpressure 전략
- 리액티브 프로그래밍에서 데이터를 적절하게 제어하기 위해 반드시 필요한 전략
- Subscriber의 처리 속도가 Publihser의 emit 속도를 따라가지 못할 때 적절하게 제어함
➡️ 리액티브 프로그래밍에서는 끊임없이 들어오는 데이터를 적절하게 처리할 수 있어야 함Publisher에서 끊임없이 들어오는 데이터를 emit하는 것과 달리 Subscriber의 처리 속도가 느리다면?
처리되지 않고 대기하는 데이터가 지속적으로 쌓이는 것을 방치한다면 오버플로우가 발생하게 되고, 시스템이 다운될 수 있다.
마블 다이어그램
Marble(마블): 구슬- 구슬 같은 동그라미는 하나의 데이터를 의미하며, 다이어그램 상에서 시간의 흐름에 따라 변화하는 데이터의 흐름을 표현한 것
- 리액티브 프로그래밍에서는 어떤 Operator를 사용하느냐에 따라서 데이터의 흐름이 다양하게 변화할 수 있음
- 복잡한 데이터의 흐름을 마블 다이어그램을 통해 쉽게 이해할 수 있음
✅ Mono의 마블 다이어그램
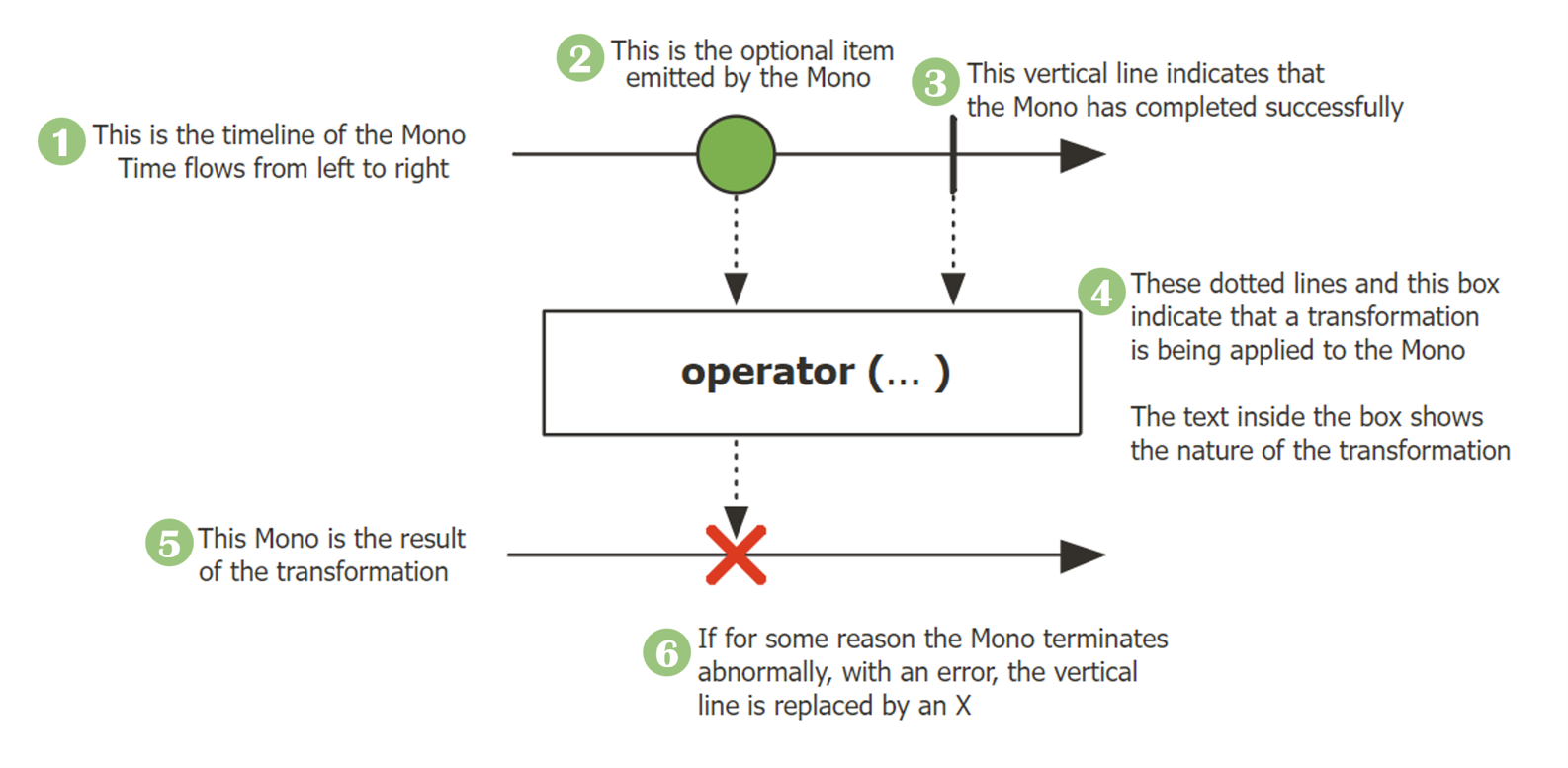
Reactor의 데이터 타입 중 하나인 Mono를 마블 다이어그램으로 표현한 것이다.
- 위 아래로 두 개의 타임 라인은 모두 데이터가 흘러가는 시간의 흐름을 표현한 것
- 시간은 왼쪽에서 오른쪽으로 흘러가므로 시간 상 왼쪽이 빠른 시간임 (
왼쪽 ➜ 오른쪽)
- 시간은 왼쪽에서 오른쪽으로 흘러가므로 시간 상 왼쪽이 빠른 시간임 (
① 원본 Mono(Original Mono)에서 Sequence가 시작되는 것을 타임라인으로 표현한 것
⠀
② Mono의 Sequence에서 데이터가 emit 되는 것을 표현함
➜ 그림에서 데이터 하나가 emit 되는 것을 확인할 수 있는데, Mono는 0 또는 1건의 데이터만 emit하는 Reactor 타입이기 때문에 이를 표현하고 있음
⠀
③ 수직 막대 바는 Mono의 Sequence가 정상 종료됨을 의미
⠀
④ Mono에서 지원하는 어떤 Operator에서 입력으로 들어오는 구슬 모양의 데이터가 가공 처리되는 것을 표현
⠀
⑤ Operator에서 가공 처리된 데이터가 Downstream으로 전달될 때의 타임라인
⠀
⑥ Mono에서 emit된 데이터가 처리되는 과정에 에러가 발생한다면 X로 표시
⚠️|는 정상 종료,X는 에러로 인한 비정상 종료
✅ Flux의 마블 다이어그램
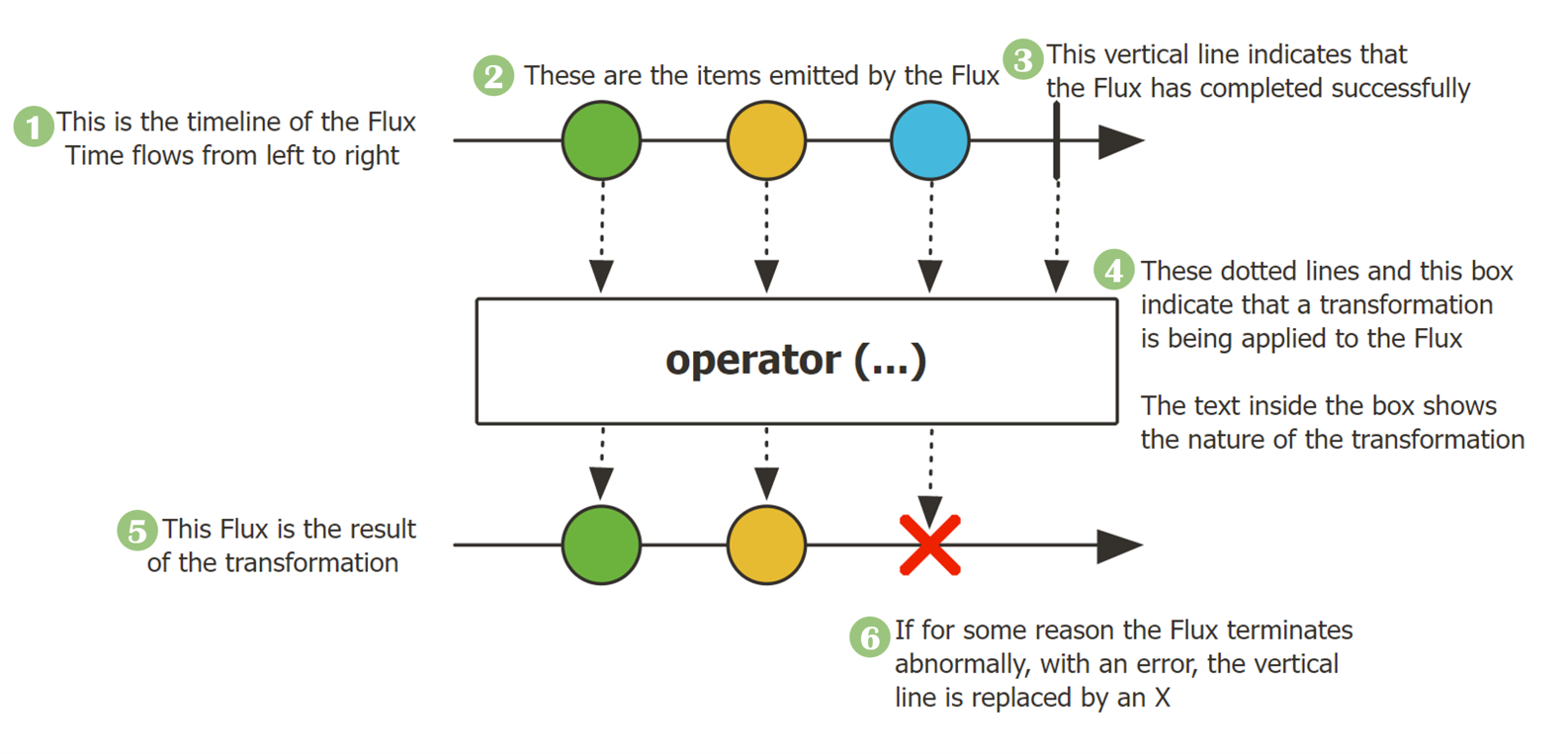
Flux의 마블 다이어그램이다.
- Mono와는 달리 Flux는 여러 개(0 ~ N)의 데이터를 emit하는 Reactor 타입임을 표현
스케줄러
- 쓰레드를 관리하는 관리자 역할
➡️ 여러 쓰레드를 관리, 복잡한 멀티쓰레딩 프로세스를 단순하게 함 - Reactor Sequence 상에서 처리되는 동작들을 하나 이상의 쓰레드에서 동작하도록 별도의 쓰레드를 제공해줌
💡Reactor의 Scheduler는 복잡한 멀티쓰레딩 프로세스를 단순하게 해준다.
Scheduler 전용 Operator
- Reactor에서는 Scheduler를 위한 별도의 Operator를 제공함
➡️ 적절한 상황에 맞는 쓰레드를 추가로 생성하는 Operator
✅ subscribeOn() Operator
- 데이터 소스에서 데이터를 emit하는 원본 Publisher의 실행 쓰레드를 지정하는 역할
- 구독 직 후 실행되는 Operator 체인의 실행 쓰레드를 Scheduler로 지정한 쓰레드로 변경
💡
subscribeOn()Operator 내부에Schedulers.boundedElastic()같은 Scheduler를 지정하면, 구독 직후에 실행되는 쓰레드가 main 쓰레드에서 Scheduler로 지정한 쓰레드로 바뀜
✅
doOnSubscribe()Operator
- 구독 발생 직 후에 트리거 되는 Operator
- 구독 직 후에 실행되는 쓰레드와 동일한 쓰레드에서 실행됨
- 구독 직 후에 어떤 동작을 수행하고 싶다면
doOnSubscribe()에 로직을 작성하면 됨
✅ publishOn() Operator
- 전달 받은 데이터를 가공 처리하는 Operator 앞에 추가해서 실행 쓰레드를 별도로 추가하는 역할
publishOn()을 추가할 때 마다, 추가한publishOn()를 기준으로 Downstream 쓰레드가publishOn()에서 Scheduler로 지정한 쓰레드로 변경
✅
doOnNext()Operator
doOnNext()바로 앞에 위치한 Operator가 실행될 때, 트리거 되는 Operator
❗
publishOn()은 Operator 앞에 여러번 추가할 경우 별도의 쓰레드가 추가로 생성되지만,subscribeOn()은 여러 번 추가해도 하나의 쓰레드만 추가로 생성됨
Operators
- Reactor에서 가장 중요한 구성요소
💡 Reactor에서 지원하는 Operator는 너무 많은데, Reactor 공식 사이트에 적절한 상황에 맞게 사용할 수 있도록 Operator가 상황별로 분류가 되어 있다.
🔗 Appendix A: Which operator do I need?
🔗 Reactor 언제 어떤 Operator를 써야 할까?
상황별로 분류된 Operator 목록
-
새로운 Sequence를 생성(Creating)하고자 할 경우
-
just() -
⭐
fromStream()
➡️ Java의 Stream을 입력으로 전달 받아 emit하는 Operator -
⭐
fromIterable()
➡️ Java의Iterable을 입력으로 전달 받아 emit하는 Operator
List, Map, Set 등의 컬렉션을fromIterable()의 파라미터로 전달 가능 -
fromArray() -
range() -
interval() -
empty() -
never() -
defer() -
using() -
generate() -
⭐
create()
➡️ 프로그래밍 방식으로 Signal 이벤트를 발생시키는 Operator
한 번에 여러 건의 데이터를 비동기적으로 emit할 수 있음
-
-
기존 Sequence에서 변환 작업(Transforming)이 필요한 경우
-
⭐
map()
➡️ 안에서 가공처리 해줌 -
⭐
flatMap()
➡️flatMap()내부로 들어오는 데이터마다 하나의 새로운 Sequence가 생성됨
Sequence 하나가 들어오는데, 내부에서 작동되는 Sequence는 여러 개
➡️ flatMap() 내부에서 정의하는 Sequence = Inner Sequece
❗각 쓰레드의 작업 처리 순서를 보장하지 않음 -
⭐
concat()
➡️ 입력으로 전달하는 Publisher의 Sequence를 하나로 이어붙여서 차례대로 데이터를 emit
❗순서대로 emit -
collectList() -
collectMap() -
merge() -
⭐
zip()
➡️ 입력으로 전달되는 여러 개의 Publisher Sequence에서 emit된 데이터를 결합하는 Operator
➡️ 각각의 Sequence에서 emit되는 데이터 중 같은 차례(index)의 데이터들이 결합됨
⚠️ 두 Sequence의 emit 시점이 매번 달라도, emit 시점이 늦은 데이터가 emit될 때까지 대기하여 두 개의 데이터를 전달 받아 결합함💡 결합?
각 Publisher가 emit하는 데이터를 하나씩 전달 받아서 새로운 데이터를 만든 후에 Downstream으로 전달한다는 의미 -
then() -
switchIfEmpty() -
and() -
when()
-
-
Sequence 내부의 동작을 확인(Peeking)하고자 할 경우
-
doOnSubscribe -
⭐
doOnNext()
➡️ 데이터 emit 시 트리거 되어 부수 효과(side-effect)를 추가할 수 있는 Operator
➡️ 리턴값 X
➡️ 주로 로깅(로그를 기록 또는 출력하는 작업)에 사용하나, 데이터를 emit하면서 필요한 추가 작업이 있다면 doOnNext()에서 처리💡 부수 효과(side-effect)
어떤 동작을 실행하되, 리턴 값이 없는 것 -
doOnError() -
doOnCancel() -
doFirst() -
doOnRequest() -
doOnTerminate() -
doAfterTerminate() -
doOnEach() -
doFinally() -
⭐
log()
➡️ Publisher에서 발생하는 Signal 이벤트 마다 로그로 출력해주는 역할
➡️ 원하는 만큼 추가 가능
-
-
Sequence에서 데이터 필터링(Filtering)이 필요한 경우
-
⭐
filter()
➡️ 들어오는 데이터를 어떤 조건에 맞춰서 필터링 -
ignoreElements() -
distinct() -
⭐
take()
➡️ 파라미터에 처리하고싶은 데이터의 수가 들어감 -
next() -
skip() -
sample() -
single()
-
-
에러를 처리(Handling errors)하고자 할 경우
-
⭐
error()
➡️ Reactor Sequence 상에서 의도적으로 예외를 던져서 onError Signal 이벤트를 발생시키는데 사용 (throw와 같음) -
⭐
timeout()
➡️ 입력으로 주어진 시간동안 emit되는 데이터가 없으면 onError Signal 이벤트 발생 시킴
➡️retry()Operator와 함께 사용하는 경우가 많음 (➜ 일정한 시간에 오지 않으면 재시도) -
onErrorReturn() -
onErrorResume() -
onErrorMap() -
doFinally() -
⭐
retry()
➡️ Sequence 상에서 에러가 발생할 경우, 입력으로 주어진 숫자만큼 재구독하여 Sequence를 다시 시작
➡️ 파라미터에 재시도할 수 있는 횟수가 들어감
➡️ timeout() Operator와 함께 사용하는 경우가 많음
-
