
알고리즘이란 문제를 해결하는 최선의 선택이다.
컴퓨터를 이용해 문제 해결을 할 때는 무수히 많은 방법을 시도할 수 있다. 모든 경우의 수를 하나씩 비교해 최선을 골라내거나, 가장 좋아보이는 수를 찾았다면 다른 경우의 수를 무시하는 경우도 있다.
우리에겐 입력과 동시에 결과를 출력하는 것으로 보이지만 컴퓨터는 데이터를 비교하고 연산하는데, 그 속도가 빠르기에 우리가 볼 수 없는 것이다.
의사코드 (pseudocode)
의사코드(혹은 수도 코드)는 프로그래밍 언어로 코드를 작성하기 전, 우리가 사용하는 일상 언어로 프로그램이 작동하는 논리를 먼저 작성해보는 것이다.
문제를 이해하고 논리 문제를 풀듯 풀 수 있어야 한다. 그 후 의사코드를 작성하고 개발 언어로 코드를 작성한다.

의사코드는 구체적으로 작성해야 한다.
컴퓨터는 사람처렁 상상을 할 수 없다. 만약, 볶음밥을 만들라고 한다면 사람은 볶음밥의 이미지를 상상하며 여러 재료를 조합해 다양한 방법으로 볶음밥을 만들 수 있다.
반면, 컴퓨터는 단순히 0과 1로 이루어진 기계다. 컴퓨터에게 볶음밥을 만들라고 한다면 로직이 저장되어 있지 않는 이상 동작하지 못한다. 따라서 볶음밥을 만드는 로직을 사람이 하나하나 구체적으로 명령해야 한다.
예를 들어 컴퓨터에게 라면을 끓이라는 명령을 수도 코드로 작성해보자.
1. 라면을 가져온다.
2. 냄비에 물을 넣는다.
3. 가스렌지 위에 냄비를 올리고 물을 끓인다.
4. 만약 물이 끓는다면 면과 스프, 건더기 스프를 넣는다.
만약 물이 끓지 않는다면 끓을 때까지 기다린다.
5. 라면이 익을 때까지 3분간 끓인다.
6. 라면이 다 익었다면 라면 끓이기 완료.수도 코드는 대표적으로 두 가지 방식으로 사용된다. 위와 같이 다른 사람도 이해할 수 있는 자연어만 사용하는 경우와 자연어와 프로그래밍 언어를 조합하여 사용하는 경우가 있다.
아래는 자연어와 프로그래밍 언어의 조합으로 작성된 수도 코드다.
public void cookRamen() {
// 라면을 가져온다.
// 냄비에 물을 넣는다.
// 가스렌지 위에 냄비를 올리고 물을 끓인다.
// if (물이 끓는다면) 면과 스프, 건더기 스프를 넣는다.
// else 물이 끓을 때까지 기다린다.
// 라면이 익을 때까지 3분간 끓인다.
// 라면이 다 익었다면 라면 끓이기 완료.
}장점
-
시간 단축
수도 코드를 먼저 작성하는 것보다 처음부터 코드를 작성하면 시간이 단축되는 느낌을 받을 수 있다. 그러나 문제가 복잡해지고 코드 양이 길어지면 구체적인 로직은 잊어버릴 수 있고, 결국 작성하는 시간보다 헤매는 시간이 길어질 수 있다.
이때, 자신이 생각한 코드를 수도 코드로 남겨 놓으면 헤매는 시간이 줄어들 수 있다. -
디버깅 용이
코드 작성이 완료되고 테스트를 할 때, 오류가 발생하면 디버깅을 하게 된다. 어느 부분이 오류인지 확인할 때 쉽게 알아보기 쉬운 수도 코드를 확인하면 다른 것을 제외한 로직에만 신경쓸 수 있어 원인 파악이 쉬워진다. -
프로그래밍 언어를 모르는 사람과의 소통이 가능
프로그래밍 언어에 익숙하지 않은 사람도 수도 코드를 보며 로직을 이해하는 데 도움이 될 수 있다.
시간 복잡도 (Time Complexity)
알고리즘 문제를 풀 때 문제에 대한 해답을 찾는 것이 가장 중요하지만, 효율적인 방법으로 문제를 해결했는지도 중요하다.
문제를 풀다가 "더 효율적인 방법은 없을까?" 라는 생각을 해 본 적이 있다. 효율적인 방법을 고민한다는 것은 시간 복잡도를 고민한다는 것과 같은 말이라 한다.
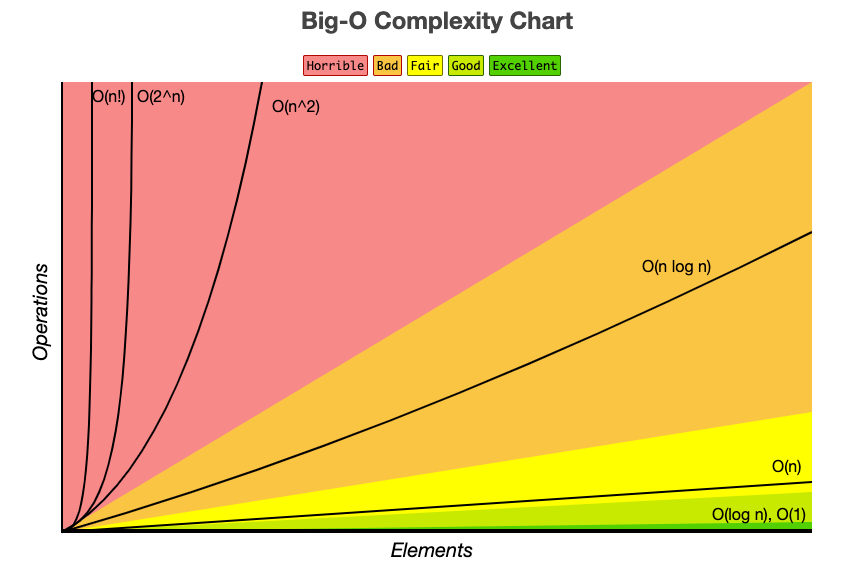
문제를 해결하기 위한 알고리즘 로직을 구현할 때, 시간 복잡도를 고려한다는 것은 무엇일까? 한 문장으로 정리하자면 다음과 같다.
입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마나 걸리는가?
효율적인 알고리즘을 구현한다는 것은 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성한다는 말이다.
- Big-O(빅-오) : 최악의 경우
- Big-Ω(빅-오메가) : 최선의 경우
- Big-θ(빅-세타) : 중간(평균)의 경우
시간 복잡도를 표기하는 방법은 위와 같은데, 이 중에서 Big-O 표기법을 가장 많이 사용한다.
Big-O 표기법은 최악의 경우를 고려하는데, 프로그램이 실행되는 과정에서 소요되는 최악의 시간까지 고려한다. "이 정도 시간까지 걸릴 수 있더."를 고려해야 이에 맞는 대응이 가능하다.
⠀
예를 들어, 결과를 반환하는데 최선의 경우 1초, 평균적으로 1분, 최악의 경우 1시간이 걸리는 알고리즘을 구현했다고 가정해보자.
최선의 경우를 고려하는 경우, 알고리즘을 100번 실행하면 최선의 경우 100초가 걸린다. 만일 3시간이 넘는 시간이 걸렸다면 "어디서 문제가 발생한걸까?"라는 의문이 생길 것이다. 최선의 경우만을 고려했으니 문제가 발생한 지점을 알아내기 위해서 많은 로직을 파악해야 하므로 많은 시간이 필요하다.
그럼 평균값을 기대하는 시간 복잡도를 고려했다면 어떻게 될까? 같은 알고리즘을 실행했을 때, 3시간이 넘게 걸렸다면 최선의 경우를 고려한 것과 같은 고민을 하게 될 것이다.
위와 같이 시간을 계산하기 보다는 최악의 경우도 고려해 대비하는 것이 바람직하다. 따라서 다른 표기법보다 Big-O 표기법을 많이 사용하는 것이다.
Big-O 종류
O(1)

O(1)는 입력값이 증가하더라도 시간이 늘어나지 않는다. 즉, 입력값의 크기와 상관없이 즉시 출력값을 얻어낼 수 있다는 의미다.
public int Algorithm(int[] arr, int index) {
return arr[index];
}
int[] arr = new int[]{1,2,3,4,5};
int index = 1;
int results = O_1_algorithm(arr, index);
System.out.println(results);arr의 길이가 100만이어도 즉시 해당 index에 접근해 값을 반환할 수 있다.
O(n)
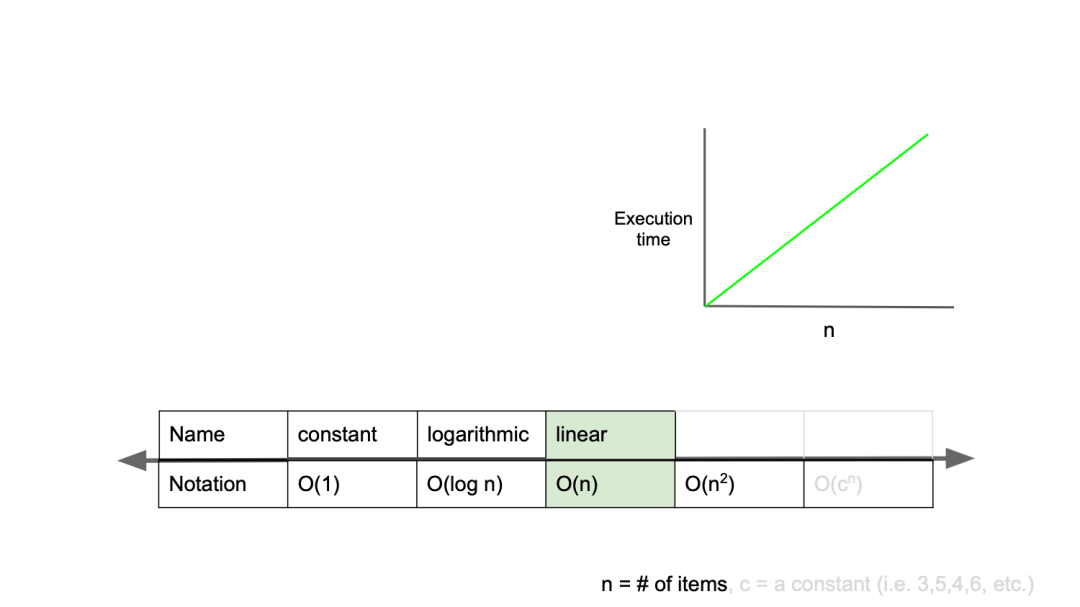
O(n)은 입력값이 증가함에 따라 시간도 같은 비율로 증가하는 것이다.
입력값이 1일 때 1초의 시간이 걸리고, 입력값을 100배 증가시켰을 때 100초가 걸리는 알고리즘을 구현했다면, 이 알고리즘은 O(n)의 시간 복잡도를 갖는다고 할 수 있다.
public void Algorithm1(int n) {
for(int i = 0; i < n; i++) {
}
}
public void Algorithm2(int n) {
for(int i = 0; i < n * 2; i++) {
}
}Algorithm1은 입력값 n이 1 증가할 때마다 코드의 실행 시간이 1초씩 증가한다.
Algorithm2은 입력값 n이 1 증가할 때마다 코드의 실행 시간이 2초씩 증가한다. 이를 보고 O(2n)이라 생각할 수 있지만, Algorithm1과 같이 O(n)으로 표기한다.
입력값이 커질 수록 n 앞에 있는 계수의 의미가 퇴색되므로 같은 비율로 증가하고 있다면 O(n)으로 표기한다.
O(log n)
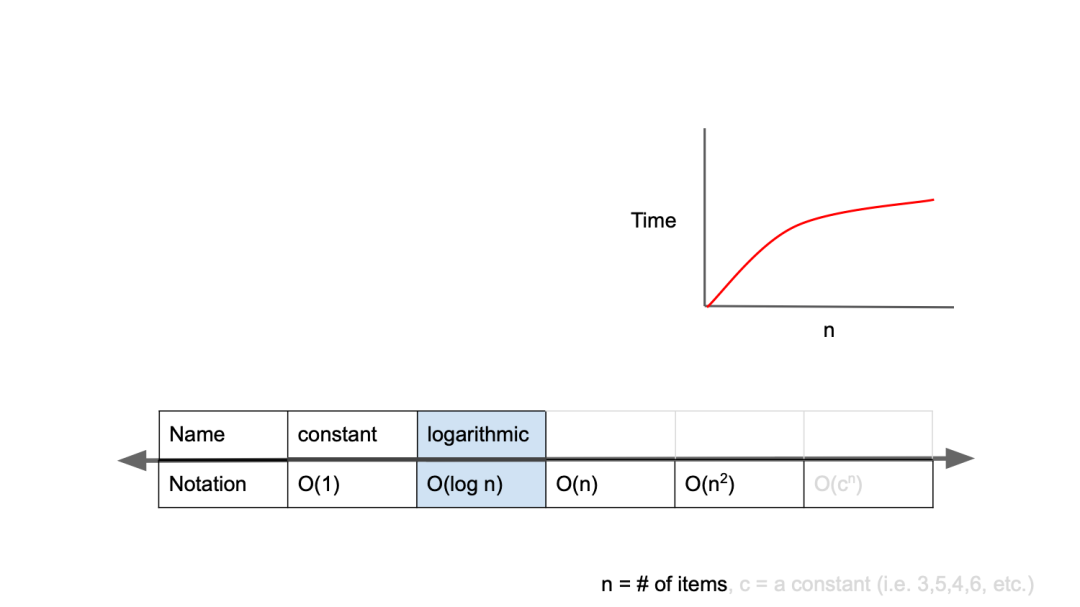
O(log n)은 O(1) 다음으로 빠른 시간 복잡도를 갖는다.
자료구조에서 배웠던 BST(Binary Search Tree)의 값 탐색도 같은 로직으로 O(log n)의 시간 복잡도를 가진 알고리즘이다.
BST에서 원하는 값을 탐색할 때 노드를 이동할 때마다 경우의 수가 절반으로 줄어든다. 게임으로 예시를 들자면, up & down과 같다.
1. 1~100 중 하나의 수를 고른다. -> 60을 골랐다고 가정
2. 가운데 수인 50을 제시하면, 60은 50보다 크므로 up을 외친다.
3. 50~100 중의 수이므로, 또다시 가운데 수인 75를 제시한다.
4. 75보다 작으므로 down을 외친다.
5. 위와 같이 반복하며 경우의 수를 절반으로 줄여나가며 정답을 찾는다.O(n^2)
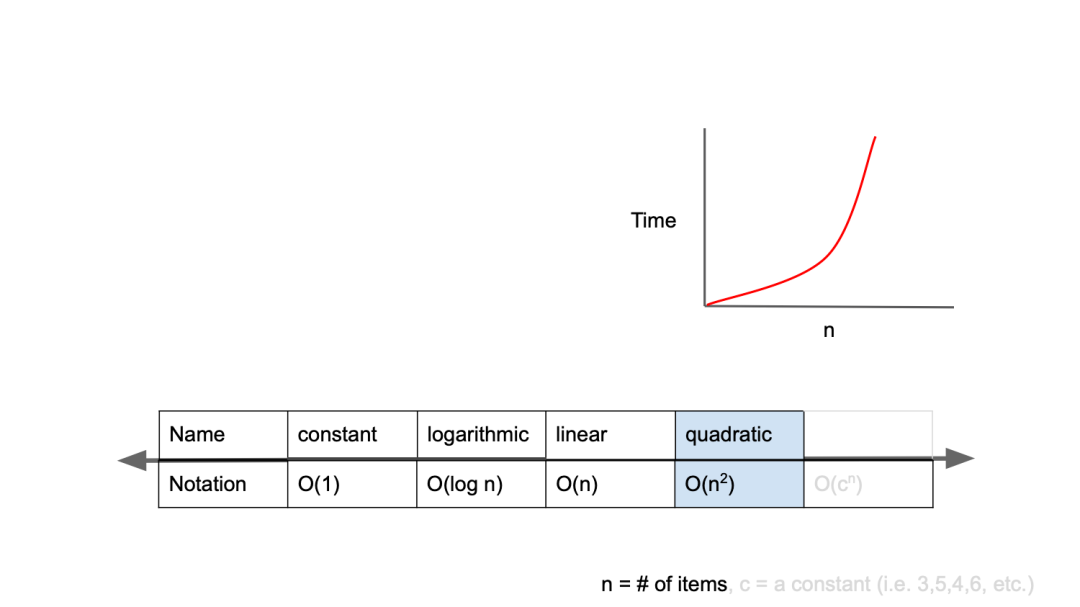
O(n^2)은 입력값이 증가함에 따라 시간이 n의 제곱수의 비율로 증가하는 것이다.
입력값이 1일 경우 1초가 걸리던 알고리즘에 5라는 값을 주었더니, 25초가 걸리게 된다면, 이 알고리즘의 시간 복잡도는 O(n^2)라고 표현할 수 있다.
O(2^n)

O(2^n)은 가장 느린 시간 복잡도를 갖는다.
종이를 42번 접으면 그 두께가 지구와 달까지의 거리보다 커진다는 이야기가 있다. 42번 만에 종이가 그만한 두께를 가질 수 있는 이유는, 접을 때마다 두께가 2배로 늘어나기 때문이다.
