- JPA는 영속성 컨텍스트를 가지고 있다.
- JPA는 DB와 OPP의 불일치성을 해결하기 위한 방법론을 제공한다.
- JPA는 OPP의 관점에서 모델링을 할 수 있게 해준다. (상속, 콤포지션, 연관관계)
- 방언 처리가 용이하여 Migration하기 좋다. 유지 보수에도 좋다.
JPA는 영속성 컨텍스트를 가지고 있다.
영속성이란 어떤 데이터를 영구적으로 저장하게 해주는 것을 말한다.
컨텍스트란 어떤 대상에 대한 모든 정보를 가지고 있는 것이다.
영속성 컨텍스트는 자바가 데이터베이스의 데이터를 저장해야되는 모든 것들을 알고있다. 즉, 자바 프로그램과 데이터베이스 사이에서 왕래하는 데이터들의 정보를 영속성 컨텍스트가 가지고있다.
예를 들어 자바프로그램이 데이터베이스에 '동물 데이터'를 저장하고자 한다면 먼저 자바프로그램에서 영속성 컨텍스트에 '동물 데이터'를 넣는다. 그 뒤에 영속성 컨텍스트에 들어있는 '동물 데이터'를
데이터베이스에 넣는다. 그러면 영속성 컨텍스트에 있는 '동물 데이터'와 데이터베이스에 존재하는 '동물 데이터'는 동기화된다. 그래서 만약, 영속성 데이터의 '동물 데이터'를 삭제하면 데이터 베이스의 '동물 데이터'도 삭제된다.
또한 자바프로그램이 데이터베이스에 저장하거나, 데이터베이스로부터 데이터를 SELECT해서 가져오고 하는 일련의 모든 정보를 영속성 컨텍스트를 통해 확인 할 수 있다. 영속성 컨텍스트에서 일어난 모든 일들은 자동으로 처리가된다.
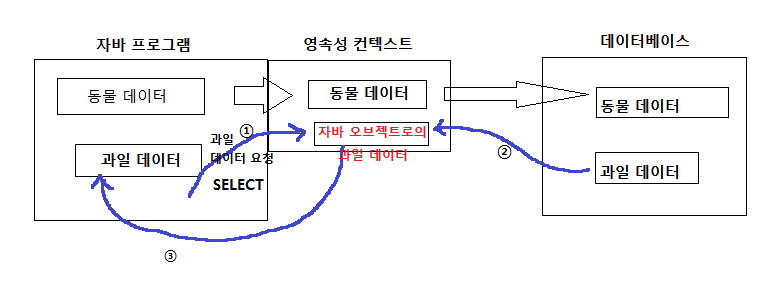
만약 자바 프로그램에서의 '과일데이터'가 사과였는데 딸기로 바꾼다면 그에 따라 영속성컨텍스트의 '과일데이터'가 딸기로 변한다. 그리고 데이터베이스 커밋해서 변경된 데이터('딸기')를 넣으면 원래 데이터베이스의 '과일 데이터'는 사과이므로 이때 INSERT가 아니고 Update가 발생한다. 데베의 데이터와 영속성 컨텍스트의 데이터가 같은데 내용이 다르므로 UPDATE문이 자동으로 호출된다.
JPA는 DB와 OPP의 불일치성을 해결하기 위한 방법론을 제공한다.
우선 다음과 같이 데이터베이스 테이블 Team과 Player가 있다고 가정하자.
Team
| ID | NAME | YEAR |
|---|---|---|
| 1 | 롯데 | 1990 |
| 2 | NC | 2005 |
Player
| ID | NAME | TEAM_ID(foreignkey) |
|---|---|---|
| 1 | 이대호 | 1 |
| 2 | 공필성 | 1 |
| 3 | 홍길동 | 1 |
| 4 | 가득영 | 2 |
이 두 테이블들을 자바 클래스로 만들면 다음과 같이 나타낼 수 있다.
Class Team{ Class Player{
int id; int id;
string name; string name;
string year; int teamId;
} }근데 클래스 Player에서 teamId만 보고서는 정확히 아이디(1,2,3,..)만 알지 팀에 대한 정보를 직접적으로 알지 못한다. 알기위해서는 Player에서 SELECT하고 Team에서 한 번 더 SELECT하거나 Player와 Team을 조인하는 방법이 있다.
하지만 다행히도 실제로 Java 프로그램에서는 이렇게 번거롭게 안 해도 된다! Java에서는 기본 자료형이 아닌 Object를 저장 할 수 있기 때문이다.
위에서 표현된 Player클래스에서 다음과 같이 객체를 저장할 수 있다.
Class Player{
int id;
string name;
Team team; /*Team 오브젝트를 저장*/
}이렇게 클래스를 작성하면 데이터베이스 테이블의 Player와 다른 것이 문제가 된다고 생각이 들 수 있다.
하지만 ORM을 하게되면 모델 생성 시 자바프로그램이 주도권을 갖고있기 때문에 위와 같이 구현이 가능한 것이다. 데이터베이스와 OPP의 불일치성을 해결해준다는 것이다. Team객체와 같은 데이터를 INSERT,SELECT할 때 JPA가 자동으로 넣어준다.
결론: DB는 객체 저장이 불가능하지만 JAVA프로그램은 객체 저장이 가능하다. JAVA에서 프로그래밍할 때는 객체를 저장하고 이 객체를 DB에 넣을 때는 JPA가 자동으로 외래 키를 넣어준다.
JPA는 OPP의 관점에서 모델링을 할 수 있게 해준다
데이터베이스를 먼저 만들고 그 데이터베이스로 만들어진 테이블을 통해서 클래스를 모델링하는 것이 아니다.
먼저 만들고자하는 클래스를 만들고 그 클래스를 토대로 자동 생성해서 데이터베이스 테이블을 만들어주는 기법이다. OPP의 관점에서 테이블이 생성된다.
JPA는 방언 처리가 용이하여 Migration하기 좋다.
일반적으로 스프링을 하는데 JPA를 이용해서 데이터베이스에 접근한다.
이 때 만약 JPA가 mysql만 지원한다면 데이터베이스는 mysql밖에 못 쓴다.
하지만 JPA는 mysql뿐만 아니라 수 많은 방언들을 지원한다.(오라클, 마리아, mysql, 등) 많은 방언들이 있기 때문에 한 가지로 딱 정해 쓰지 않는다. '추상화 객체'를 두고 (추상화 객체가 데이터베이스에 붙어있다) 오라클을 쓰고 싶다면 추상화 객체를 오라클로 변경하고 mysql이 쓰고 싶다면 오라클을 삭제하고 mysql로 변경하면 된다. 예를들어 오라클을 쓰다가 중간에 mysql로 변경해서 쓰면 문법, 함수 등의 문제로 코드가 엄청 바껴야하지만 추상화 객체를 기반으로 JPA를 사용하면 상관없다. Migration에 용이한 것이다. 그러한 덕분에 유지보수에도 용이하다.
유튜브 출처: 데어프로그래밍,데어프로그래밍
