
[SB 3기] 코드잇 스프린트 위클리페이퍼 3주차
Q. HashSet의 내부 동작 방식과 중복 제거 메커니즘을 설명하고, HashSet이 효율적인 중복 체크를 할 수 있는 이유를 설명해주세요.
1. HashSet
- HashSet이란, Set 인터페이스의 구현 클래스로 Hash 함수를 이용하여 요소를 저장하며 중복을 허용하지 않는 집합(Set) 자료구조이다.
import java.util.HashSet;
HashSet<타입> hashSet = new HashSet<>();
// 다형성 적용
Set<타입> set = new HashSet<>();
⭐️ 특징
- 중복된 값을 허용하지 않는다.
- 데이터의 순서를 보장하지 않는다.
- null 값을 허용한다. (
HashMap의 key에null을 허용하기 때문)
2. HashSet의 내부 동작 방식
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map; // 백업용 HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object(); // 더미 객체
public HashSet() {
map = new HashMap<>();
}- Java에서의 HashSet 클래스는 내부적으로
HashMap을 기반으로 동작한다. - HashSet의 내부 저장소로 백업용 HashMap을 사용한다.
- 요소는 map의 key로 저장되며, value는 모두 같은 더미 객체(PRESENT)를 사용한다.
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}- 즉, HashSet.add(x)는 내부적으로 map.put(x, PRESENT)와 동일하게 동작한다.
3. 중복 제거 메커니즘
- HashSet은 해시 함수를 통해 생성한 해시값을 기준으로 데이터의 저장 위치를 결정한다.
HashSet에서 요소가 추가되는 순서
hashCode()로 해시값을 계산한다.- 같은 해시값을 가진 요소가 있다면,
equals()로 완전히 같은 객체인지 비교한다.- 이때, true값이 반환되면, 중복된 요소라 판단하고 추가하지 않는다.
❗️ HashSet이 중복을 제거하지 못하는 경우
- 추가하려는 요소(ex. 사용자 정의 객체)에
equals(),hashcode()메서드를 오버라이딩 하지 않은 경우- 이 두 메서드가 오버라이딩 되어있지 않으면 완전히 같은 객체여도, 서로 다른 객체로 판단되어 중복이 허용될 수 있다.
4. HashSet이 효율적인 중복 체크를 할 수 있는 이유
- 해시 함수를 통해 생성한 해시 코드를 기반으로 데이터를 저장,접근시 평균 O(1)의 시간 복잡도로 수행한다.
HashMap기반으로 동작하며 Key에 요소를 저장하기 때문에, 중복여부 판단시 Key의 중복 여부만 확인하므로 빠르고 효율적으로 중복 체크가 가능하다.
Q. O(n)과 O(log n)의 성능 차이를 실생활 예시를 들어 설명하고, 데이터의 크기가 1백만 개일 때 각각 대략 몇 번의 연산이 필요한지 비교해주세요.
1. Big O 표기법
- Big O 표기법이란, 알고리즘에서 입력 크기(n)에 따라 최악의 경우 어느정도의 시간(공간)을 사용하는지를 나타내는 표현이다.
- 일반적으로 시간 복잡도와 공간 복잡도를 나타낼 때 사용한다.
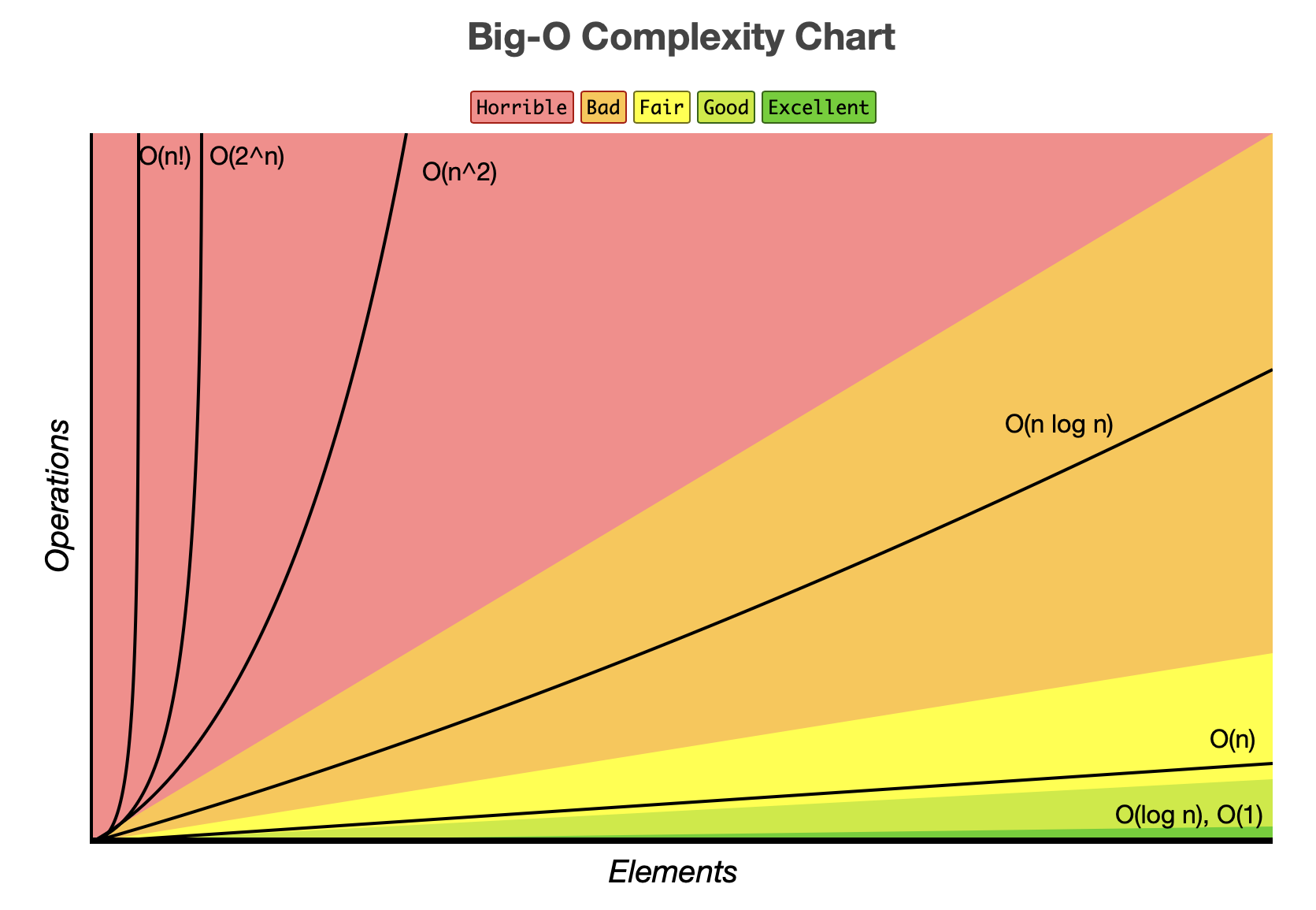
2. O(n)과 O(log n)
개념
- O(n) : 선형 시간, 입력 데이터 전체를 한 번씩 순회하며 연산하는 경우로 입력의 크기에 연산 횟수도 정비례한다.
- O(log n) : 로그 시간, 매 연산마다 입력을 절반씩 나누며 처리하는 경우로 이진 탐색(binary search)이 대표적이다.
실생활 예시 & 성능 차이
-
O(n) : 100명의 사람들에게 사과를 나누어주는 상황 -> 사과를 한명씩 차례로 나누어주는 방식으로 총 100번 나눠주어야 한다.
-
O(log n) : 사전에서 특정 단어를 찾는 상황 -> 데이터가 정렬된 상태에서 대략적으로 절반씩 범위를 좁히며 원하는 단어를 빠르게 찾을 수 있다.
데이터의 크기가 1백만 개일 때 연산 횟수
- O(n) : 1,000,000회
- O(log n) : 약 20회
➡️ 이처럼 입력 크기가 커지면 커질수록 O(log n)이 O(n)보다 훨씬 빠르고 효율적이다.
📃 참고 문서

개발자로 성장하기