딥러닝에서 손실 함수(loss function)는 모델의 예측값과 실제값 사이의 차이를 측정하여 모델이 얼마나 잘 작동하는지를 평가하는 데 사용됩니다.
대표적인 손실 함수들을 살펴보겠습니다.
1. 평균 제곱 오차 (Mean Squared Error, MSE)
회귀 문제
설명: 예측값과 실제값 사이의 차이의 제곱을 평균한 값입니다. 차이의 제곱을 사용하므로 큰 오류가 더 크게 반영됩니다.
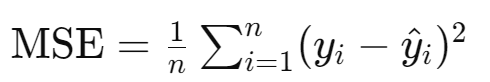
2. 평균 절대 오차 (Mean Absolute Error, MAE)
회귀 문제
설명: 예측값과 실제값 사이의 절대 차이를 평균한 값입니다. MSE와 달리 큰 오류에 덜 민감합니다.
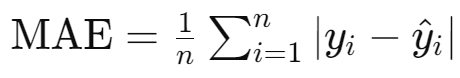
3. 교차 엔트로피 손실 (Cross-Entropy Loss)
분류 문제
설명: 예측 확률 분포와 실제 클래스의 분포 사이의 차이를 측정합니다. 주로 이진 분류와 다중 클래스 분류에 사용됩니다.
이진 교차 엔트로피
- 이진 분류 문제에 사용되며, 두 클래스 간의 교차 엔트로피를 계산합니다.
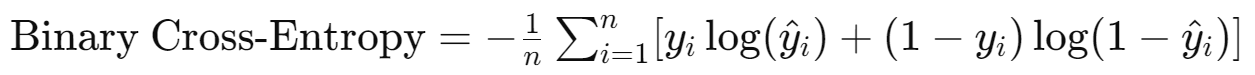
범주형 교차 엔트로피
- 다중 클래스 분류 문제에 사용됩니다.
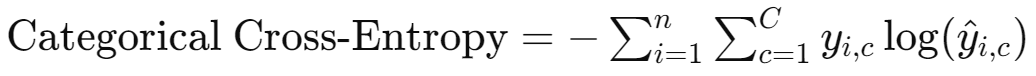
4. 후버 손실 (Huber Loss)
회귀 문제
설명: MSE와 MAE의 장점을 결합한 손실 함수입니다. 작은 오류에 대해서는 MSE처럼 동작하고, 큰 오류에 대해서는 MAE처럼 동작합니다.
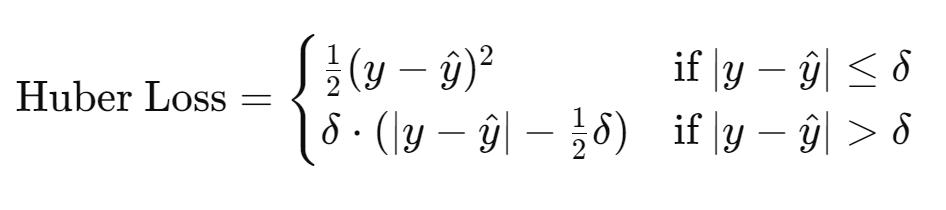
5. Hinge Loss
서포트 벡터 머신(SVM)에서 주로 사용
설명: 분류 문제에서 사용되며, 올바른 클래스의 예측 점수가 충분히 크도록 유도합니다.
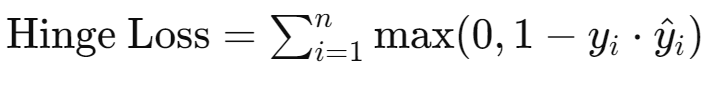
6. Kullback-Leibler Divergence (KL Divergence)
확률 분포 비교
설명: 두 확률 분포 사이의 차이를 측정합니다. 주로 분포의 유사성을 평가할 때 사용됩니다.
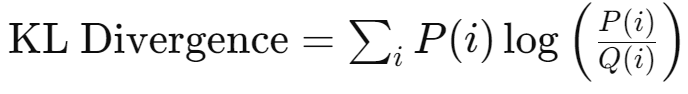

데이터사이언티스트