SQL Fundamental6 (Group by, Rollup, Cube, With)
CASE WHENData AnalysisGroup by CubeGroup by RollupPostgreSQLdata engineeringdbeavergroup bysql데이터 분석데이터 엔지니어링
SQL
목록 보기
8/9
emp 테이블
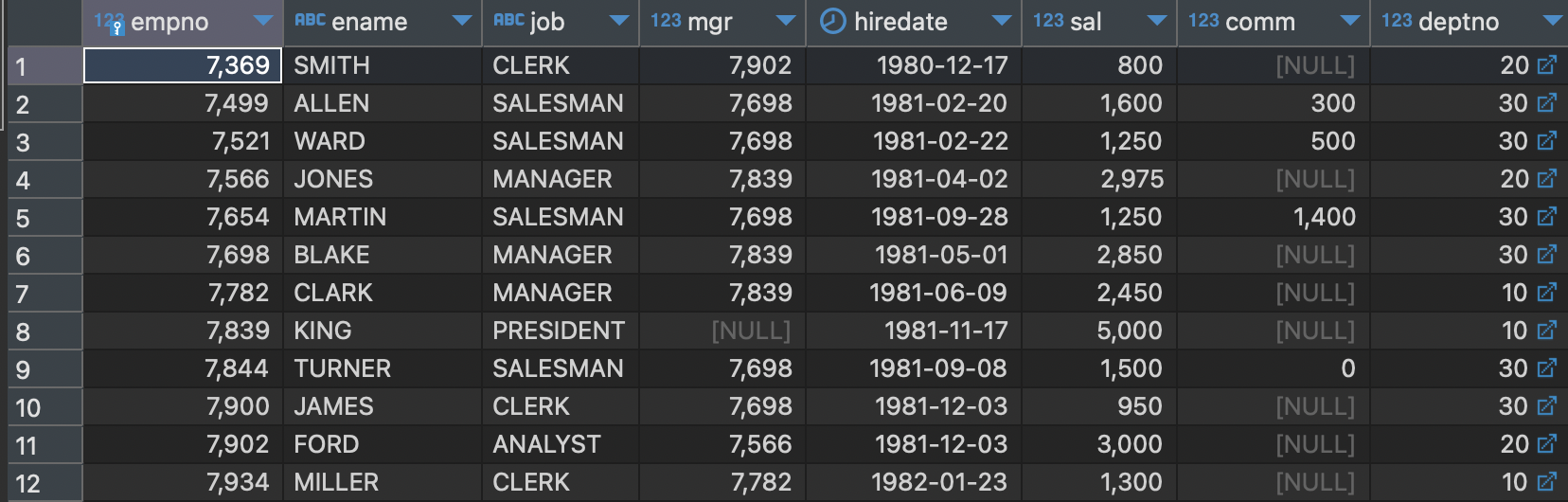
hiredate는 입사일의 데이터인 Date타입이다. 여기에서 입사년도. 즉 1981이란 년도만 추출하고 싶으면 다음과 같이 한다.
select *, to_char(hiredate, 'yyyy') as hire_year from emp그렇다면 다음과 같이 문자열 형식으로 추출할 수 있다.
emp 테이블에서 입사년도 별 평균 급여 구하기.
select to_char(hiredate, 'yyyy') as hire_year, avg(sal), count(*) as cnt
from emp a
group by to_char(hiredate, 'yyyy')
order by 1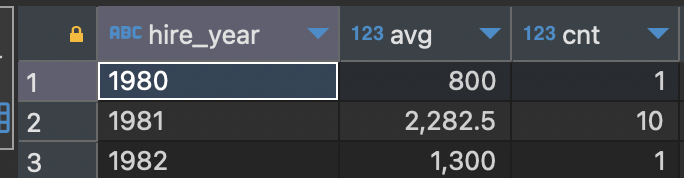
Case When

Cases When은 조건에 따라서 값을 지정해 주는 문법이다.
CASE 문의 형식은
CASE 컬럼
WHEN 조건1 THEN 값1
WHEN 조건2 THEN 값2
ELSE 값3
END job이 SALESMAN인 경우와 그렇지 않은 경우만 나누어서 평균/최소/최대 급여를 구하기.
-- job이 SALESMAN인 경우와 그렇지 않은 경우만 나누어서 평균/최소/최대 급여를 구하기.
select case job
when 'SALESMAN' then 'SALESMAN'
else 'OTHERS'
end as job_category, min(sal), max(sal), round(avg(sal), 2)
from emp
group by job_category
Group by rollup
rollup은 group by로 나누어진 소그룹간의 계산을 하는 함수이다.
다음 코드와 같이 deptno, job으로 group by를 해보자.
select deptno, job, sum(sal)
from hr.emp
group by rollup(deptno, job)
order by 1, 2;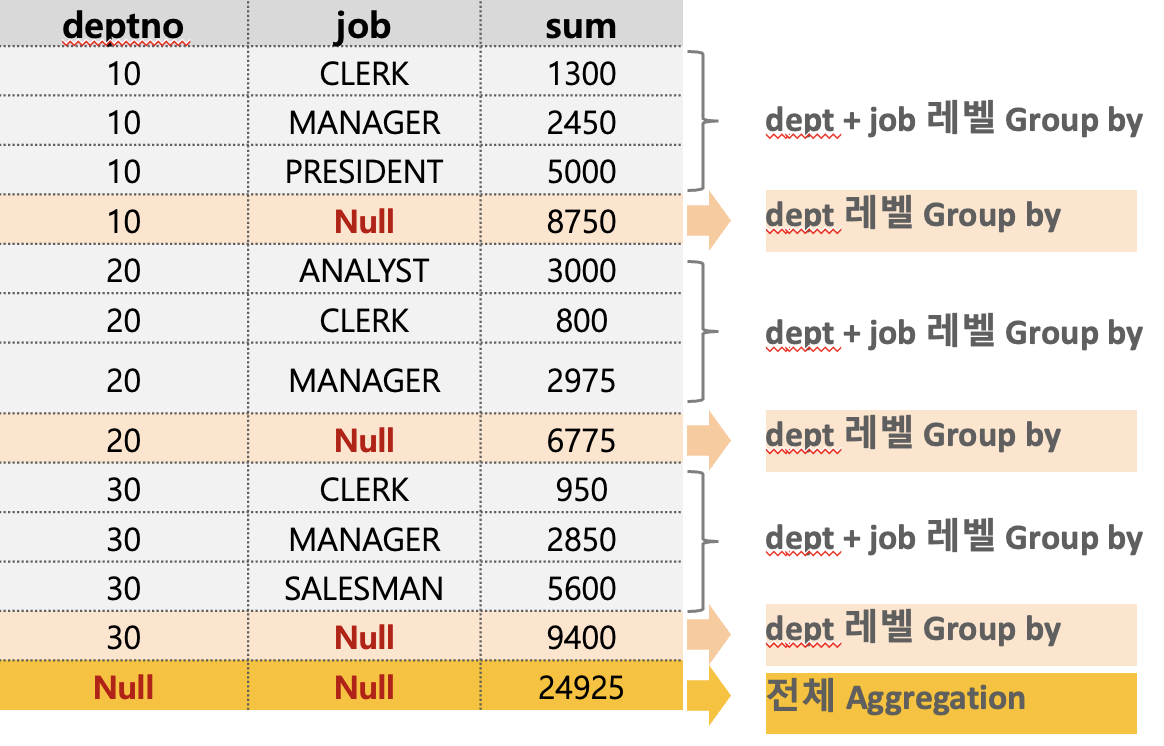
다음과 같이 deptno의 합계를 계산해준다. deptno가 10인 sum. deptno가 20인 sum, deptno가 30인 sum. 후에 전체 카테고리에 대한 Aggregation을 진행한다.
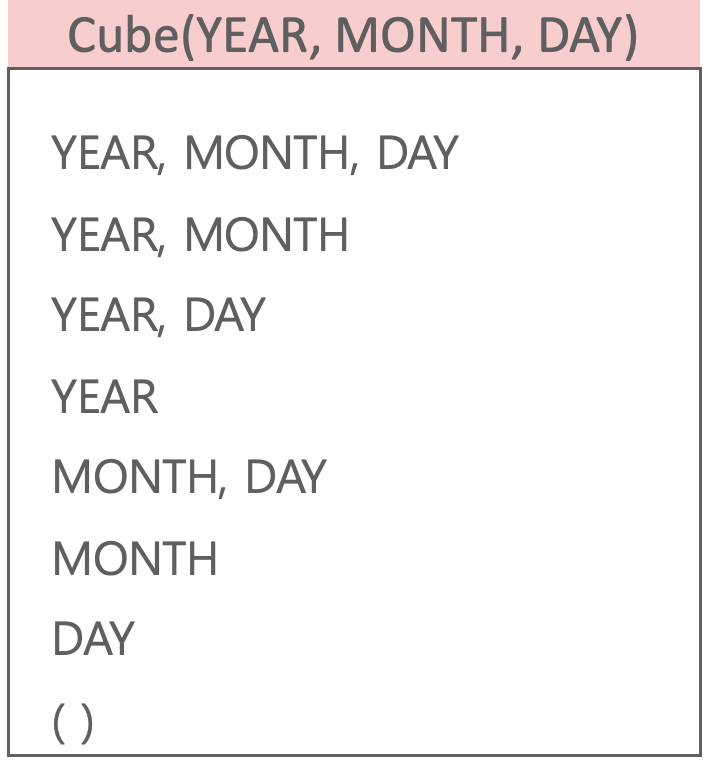
Group by Cube
Group by 시 Rollup을 함께 사용하면 Rollup에 적용된 컬럼의 순서대로 계층적인 Group by 를 추가적으로 수행.
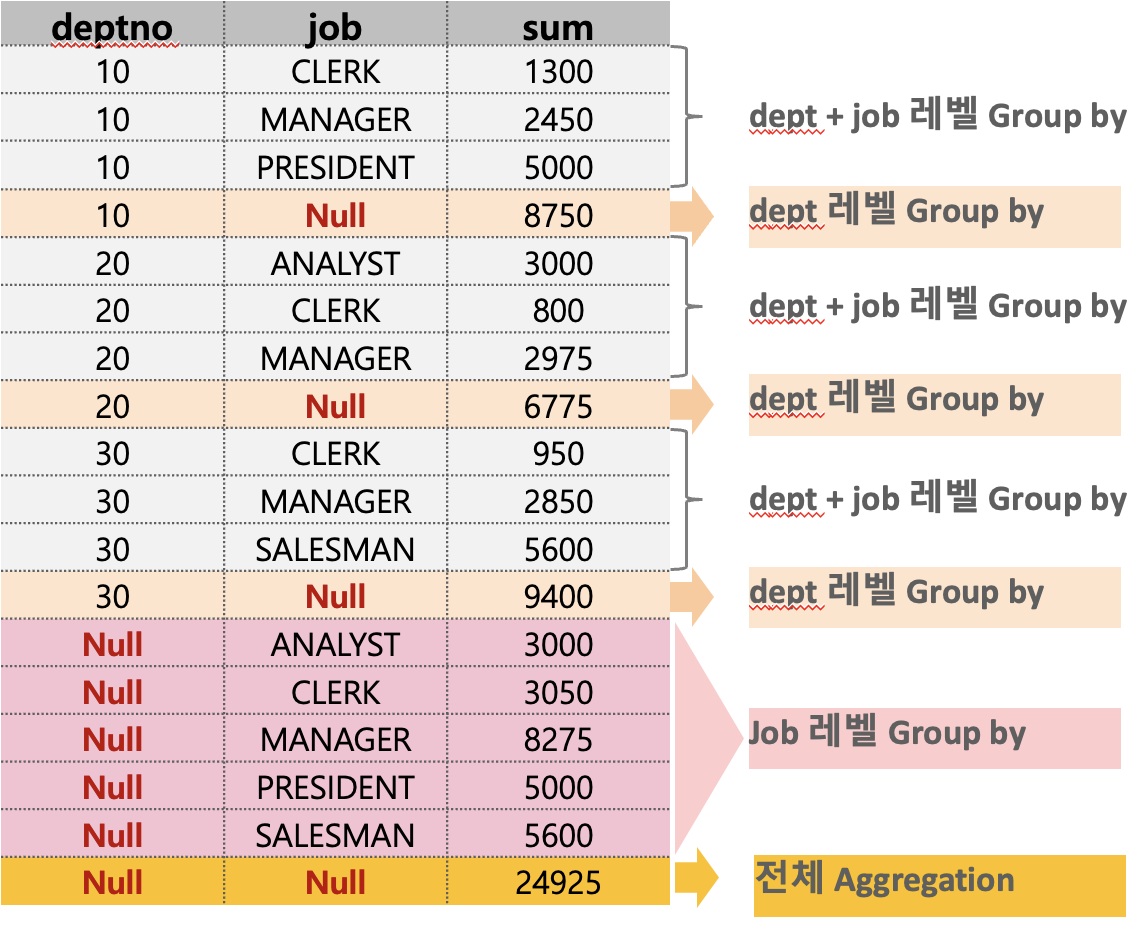
위의 rollup과 달리 추가적으로 job 컬럼마다 Aggregation을 진행한다.
 |  |
|---|
Rollup은 계층적으로, Cube는 가능한 경우의 수에 대한 Aggregation을 진행한다.

노력하는 개발자