요즘 Chat GPT의 출시로 인해 LLM에 대한 관심이 커져가면서 LLM과 연관된 Prompt Engineering에 대한 관심도 높아지고 있다.
나는 주로 Coursera나 Udemy에서 Tech 관련된 강의를 듣는데
Prompt Engineering에 관한 강의들이 많아지고 있다.
물론 LLM 자체를 개발하는 것도 중요하지만 다양한 분야에 앞으로 LLM이 적용되면서 LLM을 어떻게 잘 활용할 것인가?가 중요한 화두가 된 것 같다.
이 글에서는 LLM과 Prompt Engineering에 대해 정리해보고자 한다.
LLM(Large Language Models)
LLM이란 무엇인가
LLM(Large Language Model)은 방대한 양의 텍스트 데이터로 훈련을 해서 자연어 이해 및 생성을 하는 모델로 다양한 언어 관련 작업을 진행할 수 있다. GPT-3, BERT, Transformer 와 같은 대규모 언어 모델의 등장 및 발전을 통해 자연어 처리 분야에서 혁신이 일어나고 있다.
현재 GPT-4 모델이 출시되었고 많은 사람들이 사용하는 Chat GPT는 해당 모델을 활용한 AI 기반 대화 시스템이다.
LLM의 동작 원리
데이터 학습
LLM의 데이터 학습 방식을 이해하기 위해서는 모델이 어떻게 텍스트 데이터를 처리하고 학습하는 지가 중요하다.
- 데이터 수집: 일반적으로 인터넷에서 수집되며, 해당 데이터를 통해 모델이 다양한 언어 패턴, 문맥, 어휘를 학습하는 데에 도움이 된다.
- 데이터 전처리: 수집된 데이터를 토큰화(Tokenization) 과정을 통해 긴 텍스트를 더 작은 단위(토큰)으로 분할하고 모델이 텍스트를 처리할 수 있도록 만든다.
- 모델 훈련: 토큰화된 데이터는 신경망 훈련에 사용된다. 모델은 다양한 언어적 패턴(텍스트의 문맥, 구문, 의미 등)을 학습한다.
- 파인 튜닝(fine-tuning): 모델이 특정 작업이나 도메인에 적합하도록 추가적으로 학습하는 과정을 의미한다.
- 지속적인 학습: 지속적으로 새로운 데이터를 학습하여 최신 정보를 반영하고 성능을 향상한다.
자연어 처리 기술
LLM이 언어를 이해하고 생성하기 위해서는 다양한 기술이 필요하다.
- Tokenization (토큰화)

출처: https://teetracker.medium.com/llm-fine-tuning-step-tokenizing-caebb280cfc2
- 정의: 토큰화는 긴 텍스트 문자열을 더 작은 단위, 즉 토큰으로 분할하는 과정. 토큰은 단어, 문자, 문장 부호 등이 될 수 있다.
- 목적: 텍스트를 모델이 처리할 수 있는 형태로 변환하는 것. 토큰화를 통해 복잡한 자연어 데이터가 구조화되고, 모델이 학습할 수 있는 형태로 만들어진다.
- Embedding (임베딩)
- 정의: 임베딩은 토큰(단어, 문자 등)을 벡터 공간에 매핑하는 과정. 각 토큰은 고차원의 벡터로 변환된다.
- 목적: 자연어의 의미적, 문맥적 정보를 수치적 형태로 표현하는 것. 단어의 의미, 문맥, 관계 등을 학습한다.
- Neural Networks (신경망)
- 정의: 신경망은 인간의 뇌를 모방한 인공지능의 핵심 구조로, 다수의 노드(뉴런)가 서로 연결되어 복잡한 계산을 수행한다.
- 종류: LLM에서 주로 사용되는 신경망은 'Transformer' 아키텍처로 Attention 메커니즘을 사용하여 입력 시퀀스의 중요한 부분에 초점을 맞춘다.
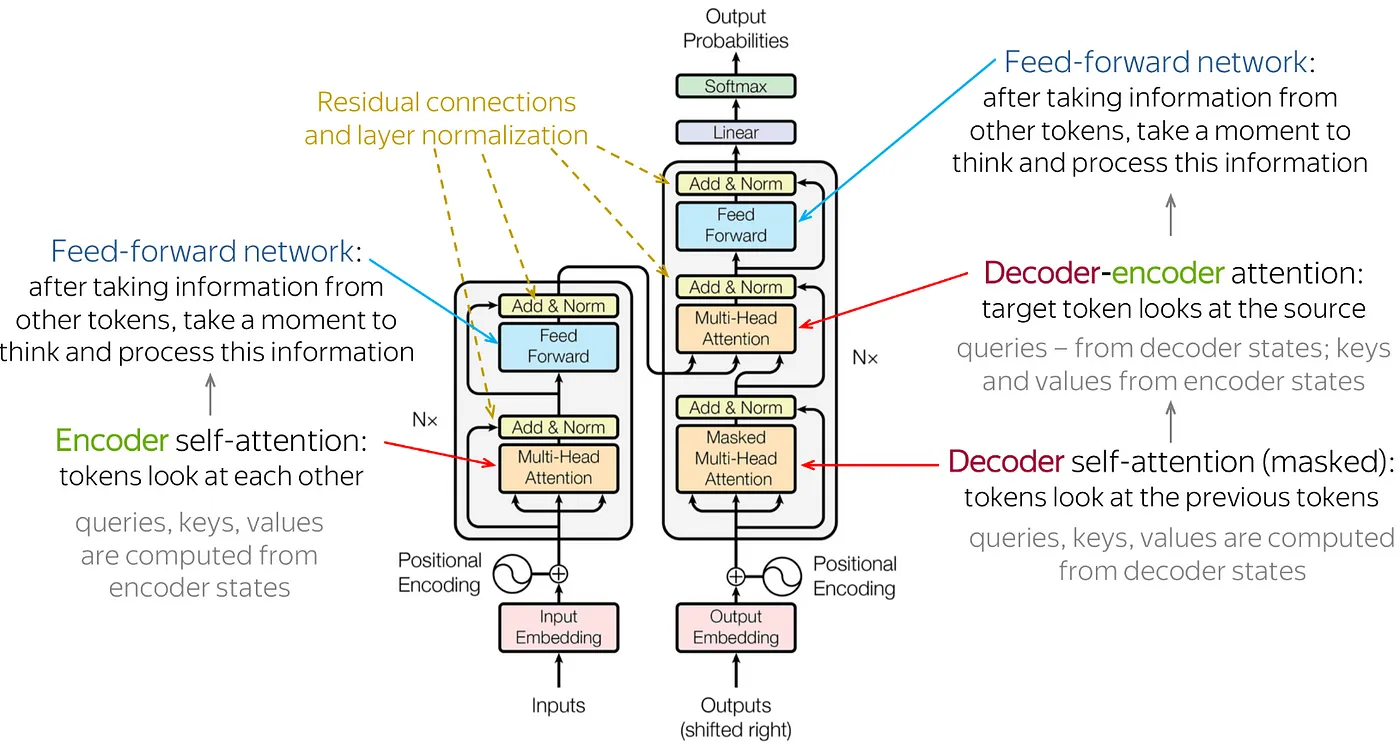
출처: https://pub.aimind.so/summary-of-transformer-achitecture-c2cef6dcaca6 - 목적: 신경망은 텍스트 데이터에서 패턴을 학습하고, 이를 바탕으로 문장 생성, 질문에 대한 답변, 텍스트 요약 등의 작업을 수행한다.
Prompt Engineering
Prompt Engineering이란?
LLM에게 특정한 출력을 유도하기 위해 입력(Prompt)를 설계하는 일이다.
LLM의 성능은 입력되는 프롬프트에 의해 크게 좌우된다.
같은 내용을 질의하더라도 얼마나 상세하게, 어떤 형식으로 질문하냐에 따라 답변의 질이 달라지게 된다.
이러한 중요성이 강조되면서 Prompt Engineering이라는 분야가 주목받게 되었다.
LLM과 Prompt Engineering
LLM과 Prompt의 상호작용
LLM은 입력된 프롬프트에 따라 출력값이 다르다.
효과적은 Prompt Engineering을 통해 LLM이 보다 정확한 결과를 제공하도록 할 수 있다.
LLM의 활용성 높이기
Prompt Engineering을 통해 LLM의 성능 최적화 및 다양한 산업에 맞춤형 LLM 모델로 만들 수 있다.
Prompt Engineering 관련 강의
https://www.coursera.org/specializations/prompt-engineering
https://www.udemy.com/course/chatgpt-ai-masterclass/
추후에 관련 강의를 수강하면서
AI 시대에 어떻게 LLM을 활용할 것인지 공부해보고자 한다.
