ECS ADOT를 활용하여 외부 Prometheus로 시스템 지표 수집하기 (2) - Grafana 대시보드 생성
서론
그라파나는 오픈소스로, 메트릭데이터 대시보드가 다양하게 공유되고 있습니다. 하지만, ecs의 경우 엔터프라이즈에 종속적인 서비스인 이유 때문인지, 대시보드 템플릿 공유가 활발하지 않습니다. 따라서 adot를 활용한 ecs 대시보드를 처음부터 생성할 필요가 있었습니다.
ADOT에서 저장되는 ECS의 Metrics 정보 확인
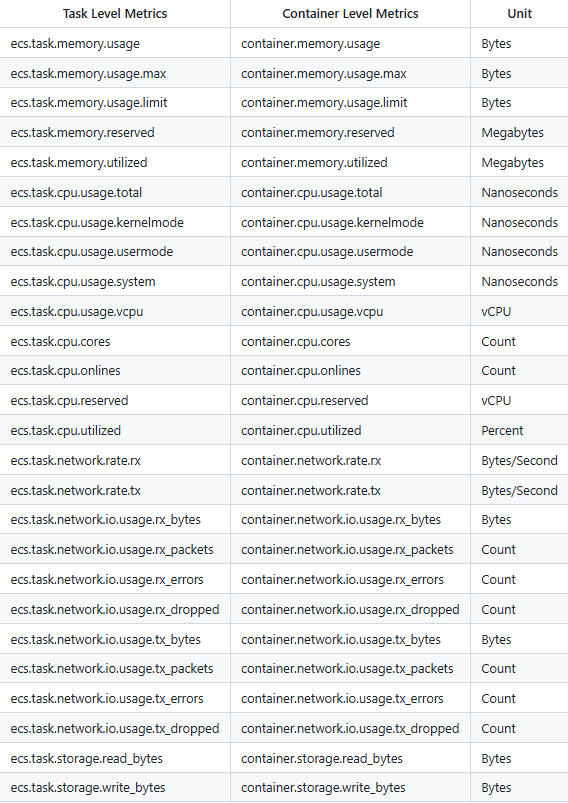
https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/awsecscontainermetricsreceiver
커스텀하게 Grafana에서 지표로 대시보드를 생성하기 위해, 지표가 의미하는 것들에 대해 확인해볼 필요가 있었습니다. 링크 참조 시 간략하게 사진과 같이 메트릭 정보에 대해 확인을 할 수 있습니다.
하지만, 디테일하게 어떤 데이터가 어떤 의미를 가지고 있고, 관련해서 어떻게 쿼리를 만들어야할지에 대한 명세가 적혀있지 않았습니다. 따라서 각 값이 의미하는 것을 분석할 필요가 있었습니다.
공식문서에서는 ecs는 메트릭에 대한 정보를 제공할 때, docker stats와 task metadata를 사용한다는 사실은 작성되어 있었으나, 정확하고 디테일하게 지표를 제공해주기 위해서는 조금 더 자세하게 분석이 필요했습니다. 따라서 opentelemetry collector 부분에 awsecsrecevier의 데이터 수집 코드를 확인해봤습니다.
### 링크: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/awsecscontainermetricsreceiver/receiver.go
mds := awsecscontainermetrics.MetricsData(stats, metadata, aecmr.logger)
### 링크: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/awsecscontainermetricsreceiver/internal/awsecscontainermetrics/stats_provider.go
taskMetadata, err := p.metadataProvider.FetchTaskMetadata()
taskStats, err := p.rc.GetResponse(TaskStatsPath)
### 링크: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/awsecscontainermetricsreceiver/internal/awsecscontainermetrics/docker_stats.go
const TaskStatsPath = "/task/stats"
// ContainerStats defines the structure for container stats
type ContainerStats struct {
Name string `json:"name"`
ID string `json:"id"`
Read time.Time `json:"read"`
PreviousRead time.Time `json:"preread"`
Memory *MemoryStats `json:"memory_stats,omitempty"`
Disk *DiskStats `json:"blkio_stats,omitempty"`
Network map[string]NetworkStats `json:"networks,omitempty"`
NetworkRate *NetworkRateStats `json:"network_rate_stats,omitempty"`
CPU *CPUStats `json:"cpu_stats,omitempty"`
PreviousCPU *CPUStats `json:"precpu_stats,omitempty"`
}
메타데이터 Endpoint에서 container, task 둘에 대한 stats 데이터를 가져옴.
https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/internal/aws/ecsutil/endpoints/metadata.go
func (md *ecsMetadataProviderImpl) FetchTaskMetadata() (*TaskMetadata, error) {
resp, err := md.client.GetResponse(endpoints.TaskMetadataPath)
if err != nil {
return nil, err
}
taskMetadata := &TaskMetadata{}
err = json.NewDecoder(bytes.NewReader(resp)).Decode(taskMetadata)
if err != nil {
return nil, fmt.Errorf("encountered unexpected error reading response from ECS Task Metadata Endpoint: %w", err)
}
return taskMetadata, nil
}
위 코드 참조시, ${ECS_CONTAINER_METADATA_URI_V4}/task/stats의 도커 stats 정보, ${ECS_CONTAINER_METADATA_URI_V4}/task를 통해 task의 메타데이터를 그대로 가져와 파싱하여 사용함을 알 수 있습니다. 또한 /task/stats 데이터는 Docker Engine API에서 수집한 구조체와 매우 유사하였습니다. 따라서, 지표 그래프를 구성할때, Docker Engine API에서 지표 그래프를 구성하는 방식을 참조하여 대시보드를 구성하면 될 것이라고 판단했습니다. 따라서 우선 태스크의 stats 정보를 추출한 뒤, 이를 바탕으로 기존 방식과 비교 및 대조하여 대시보드를 설계하였습니다.
# 태스크 stats 정보
root@123456789:/# curl ${ECS_CONTAINER_METADATA_URI_V4}/task/stats
{
"32fb778c8332fb778c8332fb778c8332fb778c8332fb778c8332fb778c83": {
"read": "2025-04-18T02:05:55.805602974Z",
"preread": "2025-04-18T02:05:54.797976927Z",
"pids_stats": {"current": 7},
"blkio_stats": {
"io_service_bytes_recursive": [
{"major": 202, "minor": 0, "op": "Read", "value": 1727139840},
{"major": 202, "minor": 0, "op": "Write", "value": 13565952},
{"major": 202, "minor": 0, "op": "Sync", "value": 1740705792},
{"major": 202, "minor": 0, "op": "Async", "value": 0},
{"major": 202, "minor": 0, "op": "Discard", "value": 0},
{"major": 202, "minor": 0, "op": "Total", "value": 1740705792}
],
"io_serviced_recursive": [
{"major": 202, "minor": 0, "op": "Read", "value": 29502},
{"major": 202, "minor": 0, "op": "Write", "value": 2302},
{"major": 202, "minor": 0, "op": "Sync", "value": 31804},
{"major": 202, "minor": 0, "op": "Async", "value": 0},
{"major": 202, "minor": 0, "op": "Discard", "value": 0},
{"major": 202, "minor": 0, "op": "Total", "value": 31804}
],
"io_queue_recursive": [],
"io_service_time_recursive": [],
"io_wait_time_recursive": [],
"io_merged_recursive": [],
"io_time_recursive": [],
"sectors_recursive": []
},
"num_procs": 0,
"storage_stats": {},
"cpu_stats": {
"cpu_usage": {
"total_usage": 15013685997076,
"percpu_usage": [15013685997076, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"usage_in_kernelmode": 28340000000,
"usage_in_usermode": 14866000000000
},
"system_cpu_usage": 1114444630000000,
"online_cpus": 1,
"throttling_data": {"periods": 0, "throttled_periods": 0, "throttled_time": 0}
},
"precpu_stats": {
"cpu_usage": {
"total_usage": 15013685002187,
"percpu_usage": [15013685002187, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"usage_in_kernelmode": 28340000000,
"usage_in_usermode": 14866000000000
},
"system_cpu_usage": 1114443630000000,
"online_cpus": 1,
"throttling_data": {"periods": 0, "throttled_periods": 0, "throttled_time": 0}
},
"memory_stats": {
"usage": 59834368,
"max_usage": 134217728,
"stats": {
"active_anon": 135168,
"active_file": 23416832,
"cache": 40280064,
"dirty": 0,
"hierarchical_memory_limit": 134217728,
"hierarchical_memsw_limit": 268435456,
"inactive_anon": 14057472,
"inactive_file": 16953344,
"mapped_file": 2973696,
"pgfault": 1078077,
"pgmajfault": 16401,
"pgpgin": 1293831,
"pgpgout": 1280584,
"rss": 14057472,
"rss_huge": 0,
... 중략 ...대시보드 생성
https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/receiver/awsecscontainermetricsreceiver/internal/awsecscontainermetrics/docker_stats.go
위 코드의 파싱방식을 참조해 보았을때, 어림잡아 어떤 metric 지표명이 어떤 데이터에 대응되는지 확인할 수 있었습니다. 예를 들어,
# GO 코드
type CPUUsage struct {
TotalUsage *uint64 `json:"total_usage,omitempty"`
}# task stats json
"cpu_stats": {
"cpu_usage": {
"total_usage": 76684969505,
"percpu_usage": [76684969505, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"usage_in_kernelmode": 4660000000,
"usage_in_usermode": 69180000000
},위 코드를 확인해보았을때, container_cpu_usage_total은 cpu_stats.cpu_usage.total_usage에 대응되는 것을 확인할 수 있었습니다.
CPU(%) 대시보드를 위한 쿼리 구성
container에 대한, reserved cpu, memory를 설정하지 않는 경우 아래 쿼리의 값이 나오지 않을 수 있습니다
cpu_stats 구조체의 경우, 보통 CPU Percentage를 계산할때, 보통 아래 식으로 계산하게 됩니다
(Δtotal_usage / Δsystem_cpu_usage)
* number_of_cpus
* 100그렇다면 ecs에서 cpu 비율을 실제로 계산해보도록 하곘습니다.
먼저, ecs에서 cpu_usage_total을 ns 단위로 계산하게 되는데, 이를 1e9값인 1_000_000_000로 나눠 초당 단위로 변경해줘야했고, total이기 떄문에 rate 함수를 사용해야했습니다.
또한 ecs에서 보통 number_of_cpus값을 1천 단위인 container_cpu_reserved(리퀘스트값)로 표시했습니다. 따라서 1000을 나눠서 사용해야 했습니다.
이 경우, 계산식은 다음과 같습니다.
CPU % = (rate / 1_000_000_000) / (reserved / 1000) * 100
= rate / reserved / 10_000즉 아래 형태로 쿼리를 날리면 됩니다.
(rate(container_cpu_usage_total[2m]) / (container_cpu_reserved) / 10000)메모리(%) 대시보드를 위한 쿼리 구성
메모리의 사용량(%)를 구하는 경우는 크게 고려할 부분이 많지 않았습니다. 메모리 사용량(container_memory_usage)는 byte로, 메모리 최대치(container_memory_reserved)는 MB로 표시되기 때문에, 간단하게 ((container_memory_usage)/(container_memory_reserved10241024 )* 100) 로 계산하게 되면, mem 사용량을 구할 수 있었습니다.

이렇게 구성하게 되면, AWS에서 제공하는 container insights와 거의 유사하게 대시보드를 구성할 수 있었습니다.
최종 대시보드
또한 위와 같은 방법을 반보갛여 비슷한 방식으로, task에 대한 대시보드를 아래와 같이 쿼리를 날려 구성할 수 있었습니다.
rate(ecs_task_cpu_usage_total[2m]) / ecs_task_cpu_reserved / 10000
(ecs_task_memory_utilized / ecs_task_memory_reserved) * 100
rate(ecs_task_network_io_usage_tx_bytes[2m])
rate(ecs_task_network_io_usage_rx_bytes[2m])
ecs_task_storage_read_bytes
ecs_task_storage_write_bytes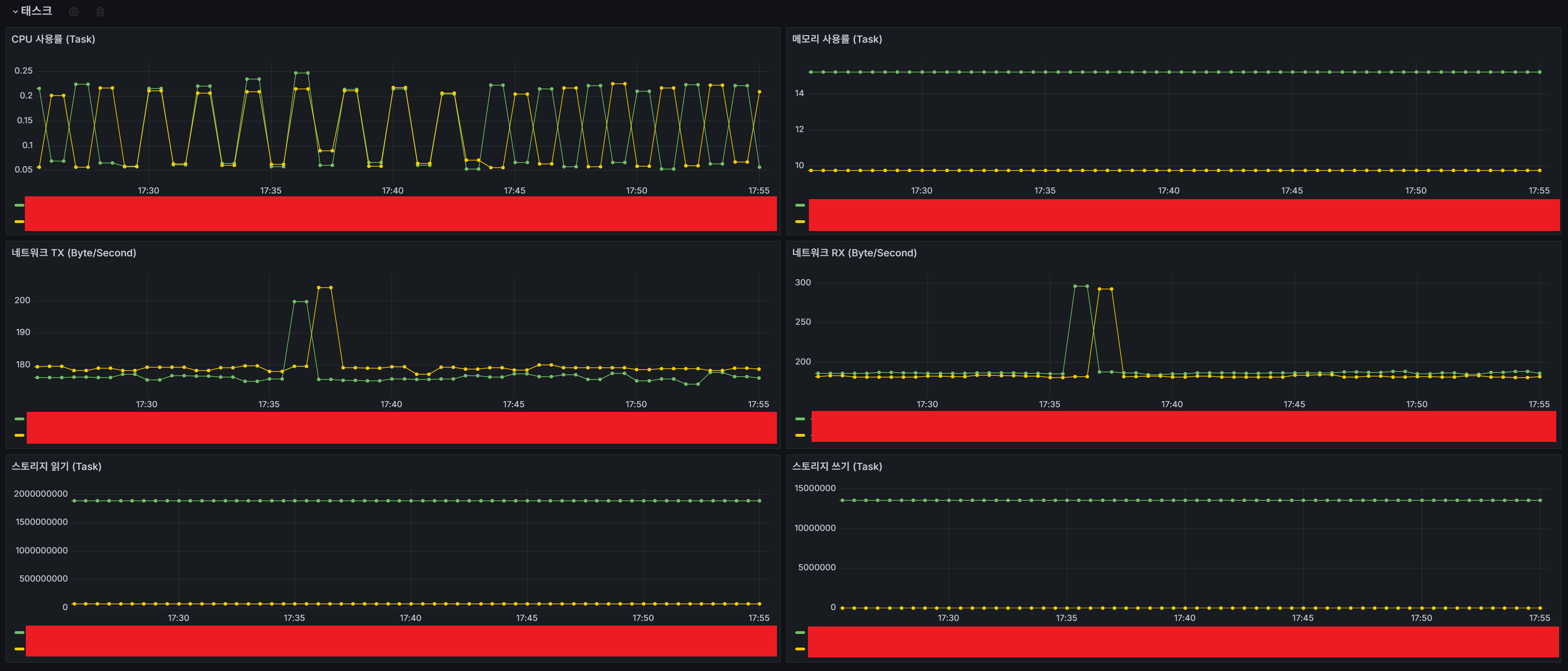
또한, 태스크 단위 뿐만 아니라, 프로메테우스의 GROUPING 쿼리 기능을 사용하게 되면, Task Family, Service, Cluster 단위로 대시보드를 생성할 수 있습니다.
마무리
ECS 환경에서 ADOT를 활용한 메트릭 수집은 처음엔 다소 생소하고 복잡하게 느껴질 수 있지만, 내부 구조와 수집 방식만 이해하면 충분히 원하는 대시보드를 구성할 수 있습니다. 특히 Docker Stats와 Task Metadata를 기반으로 구성된다는 점을 알게 되면, 오히려 로우 데이터를 기반으로 더욱 유연한 시각화를 할 수 있는 기회가 되기도 합니다.
이번 포스팅이 ECS에서의 메트릭 이해와 Grafana 대시보드 구성에 작은 도움이 되었기를 바랍니다
