0. 요구사항
{
"b": {
"count": 1,
"total": 5
},
"c": {
"count": 4,
"total": 5
},
"e": {
"count": 3,
"total": 6
},
"h": {
"count": 1,
"total": 8
},
"j": {
"count": 3,
"total": 6
},
"... 이하 생략"
}분석해서 사용자에게 전달해줘야 했던 데이터 중 하나가, 글쇄 별로 사용자가 얼마나 틀렸는지 알려주는 부분이었다. 예를 들어, 사용자가 타자 연습 중 "ㄱ"이라는 글쇄를 많이 실수한다면, 이를 알려줄 수 있도록 데이터를 분석하려고 했다. UserId를 기준으로 모든 위의 테이블인 Typing_History를 불러와 이와 관련하여 자바 코드로 분석로직을 생성하려고 하였다. 이 과정에서 성능향상을 시켰던 과정을 적어보았다.
1. 인덱스를 사용하여 SELECT 속도 향상
create table typing_history
(
id int auto_increment
primary key,
typing_id int not null,
user_id int not null,
content_type bit default b'1' null,
mode varchar(255) null,
typing_accuracy double null,
wpm int null,
wrong_keys json null,
before_mmr int null,
page int null,
increased_value int null,
start_time datetime(6) null,
end_time datetime(6) null,
created_date datetime(6) null,
updated_date datetime(6) null
) ENGINE = InnoDB;
create index user_index on typing_history(user_id);1) 인덱스를 걸어 where문에 user_id를 통해 접근할 경우, 빠르게 접근할 수 있도록 했다.
데이터를 약 300만개를 넣어놨는데,
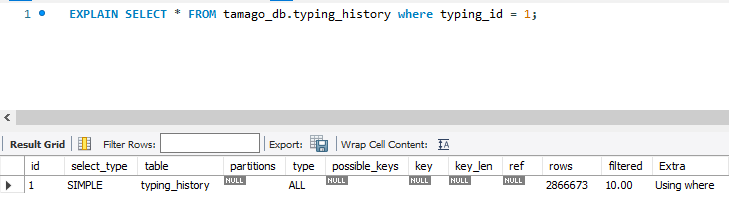
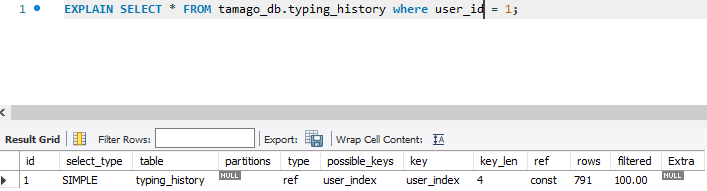
영향을 미치는 rows가 현저히 적은 것을 알 수 있다.

또한 시간 차이를 보면, Duration이 쿼리 실행 시간이므로, 이를 비교해보면 약 0.28초와 0.016으로 차이가 있다는 것을 알 수 있다. 현재 데이터양이 300만개여서 큰 차이가 없는 것으로 보인다. (또한 LIMIT를 300으로 걸었기 때문에) 하지만 천만개 이상의 데이터가 추가된다면, 더 좋은 결과를 보여줄 수 있을 것이다. 또한 이 테스트 케이스를 실행한 위치는 로컬 컴퓨터이다. 따라서 성능이 좋은 컴퓨터이기 때문에 버퍼 풀을 좀 더 효율적으로 사용할 수 있었지만, 실제 운영 서버는 RDS Free Tier이기 때문에 인덱스를 거는 것이 더 긍정적인 영향을 미칠 것으로 판단된다.
또한 이후에 사용할 집계 쿼리를 비교해보자.

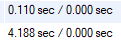
Index가 걸리지 않은 typing_id의 경우는 4초가 걸렸고, indexing이 걸린 User_id의 경우는 0.1초가 걸렸다.
2. 테이블 단에서의 캐싱
UserId를 기준으로 모든 위의 테이블인 Typing_History를 불러와 이와 관련하여 자바 코드로 분석로직을 생성하였다.
문제점 1
- 이 분석로직을 실행하는 것은 Cost가 큰 행동인데 (특히 위의 JSON의 크기가 정말 컸고, 데이터가 많았기 때문에 Cost가 굉장히 많이 드는 행위였다), 계산했던 로직을 다시 한 번 계산하는 문제가 발생하였다. 따라서 이 결과값을 어딘가 캐시해두고 싶었다. 다양한 방법이 존재하였다.
- 스프링 캐시 : 스프링 캐시는 문제가 무조건 생길 것으로 판단됐다. 먼저 EC2가 Free Tier라 메모리가 부족하다는 점이 있었고, 결과값이 변경되거나 서버를 다시 띄우는 경우, 결과가 날아가므로 이를 선택하지 않았다.
- Redis : MySQL, Redis 둘 중 결과 저장을 고민하였는데, 결국 MySQL을 선택하였다. 먼저 너무 많은 시스템을 둔다면 관리가 힘들 것으로 판단되었다.
현재, 약 500-600개의 데이터인데, 700ms의 시간이 걸린다. 아래의 테스트 코드로 실험을 해보았다.
long startTime = System.currentTimeMillis();
StatisticsAllResDto statisticsAllResDto = statisticService.totalStatisticsAll(build);
long stopTime = System.currentTimeMillis();
System.out.println(stopTime - startTime);
하지만, statistics_all이라는 테이블에 저장된 이후로 이 곳에서 데이터를 꺼내와, 절반의 시간인 361ms가 걸렸다.

create table statistics_all
(
id int auto_increment
primary key,
created_date datetime(6) null,
updated_date datetime(6) null,
accuracy_average double not null,
length int not null,
wpm_average double not null,
wrong_key_info json null,
user_id int null
);문제점 2
데이터에 변화가 생기더라도, 모든 데이터에 대해 다시 계산을 하고 싶지는 않았다. 따라서, typing_history의 CreatedDate와 statistics_all UpdatedDate를 비교하여, 갱신되지 않은 정보들만을 취합하여 처리하였다. (자바의 Spring Data JPA를 활용하여 아래와 같이 TypingHistory를 가져왔다.)
typingHistoryRepository.findAllByUserAndCreatedDateIsAfter(user, statisticsAll.getUpdatedDate());