CLIP의 Contrastive Loss에서의 Similarity
HuggingFace 및 공식 코드의 Loss는 아래와 같다.
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0
class CLIP(...):
def __init__():
...
self.visual_projection = nn.Linear(self.visual_hidden_size, self.projection_dim, bias=False)
self.text_projection = nn.Linear(self.text_hidden_size, self.projection_dim, bias=False)
self.logit_scale = nn.Parameter(torch.tensor(self.logit_scale_init_value))
...
def forward(..):
# image & text embeds == (Batch_size, Linear Hidden size)
image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits -> (Batch_size, Batch_size)
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clip_loss(logits_per_text)위 코드에서 생기는 의문은 다음과 같다.
cosine similarity를 구한다고 하는데, 각 임베딩 벡터들의 내적을 계산한다. (각 임베딩 벡터의 크기로 나누어주지 않음)
- 이는 위에서 L2-normalization을 거쳤기 때문에 dot-product나 Euclidian distance나 똑같은 순서(랭킹)이 생성된다고 함. (https://github.com/filipradenovic/cnnimageretrieval-pytorch/issues/40)
contrastive_loss에서 label이 왜 torch.arange(len(logits)로 구현되는지?
-
torch.arange(len(logits))는 positive pair의 position을 나타낸다.-
예를 들어,
torch.arange(5)라면[0, 1, 2, 3, 4]가 될 것이고 이는 one-hot labels로 바뀌게 되어 각각, 0행의 0번째, 1행의 1번째... 를 나타내므로 즉, 행렬의 주대각선의 위치를 나타내준다. -
정리하면, cross entropy 계산을 할 때 positive pair에 대해 label이 1이고 나머지는 0으로 계산될 것
-
clip의 전체 loss를 보면, text loss와 image loss를 둘 다 이용하는데 이것은 무슨 뜻이며, image loss에서 similarity를 transpose하여 사용하는 것은 왜 그런 것인지
-
text loss의 경우 아래 사진의 주황색 부분처럼, 각 행에 대해 cross entropy를 구하는 것이고, image loss의 경우 파란색 부분처럼, 각 열에 대해 cross entropy를 구하는 것이다.
- 이를 들여다보자면, 행에 대한 것은 하나의 이미지에 대한 여러 캡션들 중에 맞는 캡션을 가지도록 하는 것이고 열에 대한 것은 하나의 텍스트 캡션에 대한 여러 이미지 중에 맞는 이미지를 가지도록 하는 것이다.
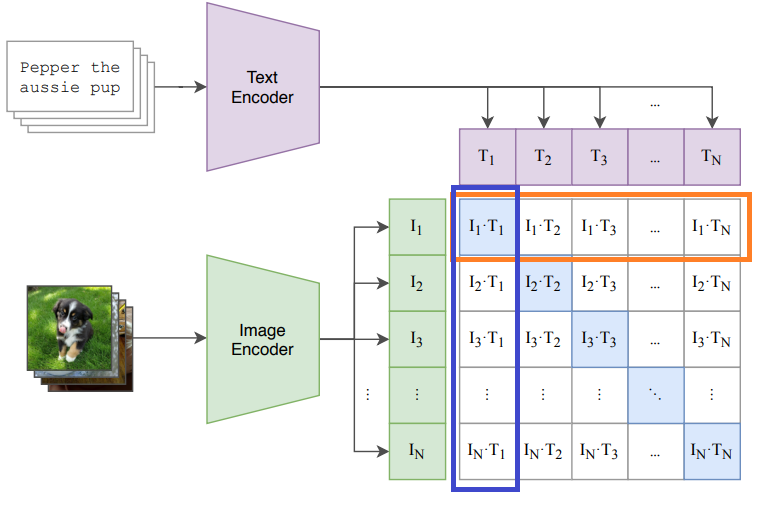
CLIP의 InfoNCE Loss
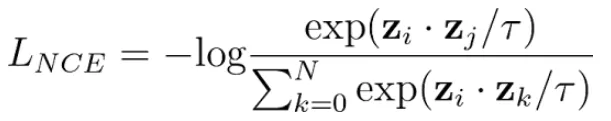
- 는 temperature 하이퍼파라미터
