go build
go build 명령어의 사용은 프로젝트의 특정 요구 사항과 상황에 따라 다를 수 있습니다. 몇 가지 go build를 사용하는 이유는 다음과 같습니다:
- 배포: 프로젝트를 배포할 때는 보통 실행 파일을 생성하여 사용자에게 제공합니다. 실행 파일을 제공하면 사용자는 추가적인 컴파일 과정이나 개발 환경 설정 없이 프로그램을 실행할 수 있습니다.
- 이식성: 실행 파일을 생성하면 프로그램을 다른 시스템에 이식하기가 더 쉽습니다. 사용자는 프로그램을 실행하는 데 필요한 Go 환경 설정 없이도 실행 파일을 사용할 수 있습니다.
- 보안: 소스 코드를 공개하지 않고 실행 파일만 제공하는 경우 보안상의 이점이 있습니다. 실행 파일을 제공하면 소스 코드의 상세 내용을 노출하지 않고도 프로그램을 실행할 수 있습니다.
- 코드 최적화: 실행 파일을 생성하는 과정에서 Go 컴파일러는 코드를 최적화할 수 있습니다. 이러한 최적화로 인해 실행 파일은 일반적으로 소스 코드를 직접 실행하는 것보다 약간 더 효율적으로 동작할 수 있습니다.
따라서 프로젝트의 배포나 이식성, 보안 등을 고려할 때는 go build 명령어를 사용하는 것이 유용할 수 있습니다. 하지만 개발 및 테스트 단계에서는 go run 명령어를 사용하여 소스 코드를 직접 실행하여 빠르게 피드백을 받을 수 있습니다.
pointer(* Operator)
package main
import "fmt"
func main() {
var x int = 1
var y int
var ip *int // ip는 int형 메모리주소를 담아야 하고, 메모리주소를 가리켜야 하기 때문에 * 연산자와 int 를 합쳐서 표기
ip = &x
y = *ip
fmt.Println(y) // 1
}
new
package main
import "fmt"
func main() {
// new() function creates a variable and returns a pointer to the variable
ptr := new(int) // 0xc000012088
*ptr = 3
fmt.Println(*ptr) // 3
}
& Operator
Go 언어의 & 연산자는 주소 연산자로, 변수의 주소를 가져올 때 사용됩니다. 즉, 해당 변수의 메모리 주소를 반환하며, 저장 기능은 없습니다. 이 연산자를 사용하면 변수의 주소를 출력할 수 있지만, 변수의 값을 변경하거나 저장하는 기능은 없습니다.
예를 들어, &x는 변수 x의 주소를 반환하지만, 이를 사용하여 &x = &y와 같은 대입 연산은 올바르지 않습니다. 변수의 값을 변경하거나 저장하는 것은 해당 변수에 직접 접근하여 수정해야 합니다.
Heap
var x = 4 // heap
func f() {
fmt.Printf("%d", x)
}
func g() {
fmt.Printf("%d", x)
}
변수 x가 heap에 할당되는지 여부는 변수의 범위(scope)와 할당 위치에 따라 달라집니다. 여기서 x가 package-level 변수로 선언되었기 때문에, 이 변수는 프로그램의 실행 동안 메모리의 heap에 저장됩니다. package-level 변수는 프로그램이 시작될 때 할당되고 프로그램이 종료될 때까지 메모리에 유지되기 때문에, 일반적으로 heap에 할당됩니다.
Stack
package heap
import "fmt"
func f() {
var x = 4 // stack
fmt.Printf("%d", x)
}
func g() {
fmt.Printf("%d", x)
}
한편, 함수 내에서 선언된 변수는 그 함수가 호출될 때마다 새로운 메모리 공간이 할당되고 함수의 실행이 완료되면 해제됩니다. 따라서 함수 내에서 선언된 변수는 stack에 할당됩니다.
요약하면, package-level 변수는 프로그램의 전체 실행 동안 메모리에 유지되므로 heap에 할당되고, 함수 내에서 선언된 변수는 해당 함수의 실행 동안만 존재하므로 stack에 할당됩니다.
함수 외부에 변수를 선언하면 해당 변수는 함수가 호출될 때마다 메모리가 재할당되지 않습니다. 따라서 함수를 많이 호출하더라도 메모리 낭비가 없습니다. 변수가 함수 내부에 선언될 때마다 호출될 때마다 메모리가 재할당되므로, 함수 내부에서 변수를 선언하면 메모리 소모가 발생할 수 있습니다. 그러나 이러한 메모리 소모는 일반적으로 미미하며, 대부분의 경우 실제로는 큰 문제가 되지 않습니다.
따라서 메모리 효율성을 고려할 때, 함수 내부에서 변수를 선언하는 것이 아닌 함수 외부에 변수를 선언하는 것이 바람직합니다. 그러나 이는 코드의 가독성과 유지 보수성을 위해서도 중요합니다. 변수의 범위를 최소화하여 코드를 더 쉽게 이해하고 유지 보수할 수 있도록 하는 것이 좋습니다.
iota
package main
import "fmt"
func main() {
type Grades int
const (
A Grades = iota // 0
B // 1
C // 2
D // 3
F // 4
)
fmt.Println(B)
}Go 언어에서 iota는 상수를 생성하기 위한 강력한 도구입니다. iota는 상수를 정의할 때 사용되며, 0부터 시작하여 순차적으로 값을 증가시킵니다.위의 코드에서 iota는 상수를 정의하는 데 사용되었습니다. iota는 상수 그룹 내에서 사용될 때 처음에는 0부터 시작하며, 그 다음 상수부터는 자동으로 1씩 증가합니다.
예를 들어, 위의 코드에서 A는 0, B는 1, C는 2, D는 3, F는 4의 값을 갖게 됩니다(const() 가 각 변수에 숫자를 할당함).
이를 통해 코드를 더 간결하게 작성할 수 있고, 순차적으로 증가하는 일련의 상수를 정의할 때 특히 유용합니다.
Atoi, Itoa
Atoi : string(ASCII) -> Int
Itoa : Int -> string(ASCII)
fmt.Scan
fmt.Scan은 Go 언어에서 사용되는 표준 라이브러리인 fmt 패키지의 함수 중 하나입니다. 이 함수는 표준 입력에서 데이터를 읽고 지정된 형식으로 포맷하여 값을 스캔합니다.
일반적으로, fmt.Scan 함수는 사용자로부터 입력을 받아 프로그램에 사용할 수 있습니다. 사용자가 키보드로 입력한 값을 읽어오고, 이를 프로그램에서 활용할 수 있도록 값을 읽어옵니다.
fmt.Scan은 일련의 값들을 입력받고, 각 값들을 적절한 형식으로 변환하여 지정된 변수에 저장합니다. 이 함수는 공백 문자(스페이스, 탭, 엔터 등)을 기준으로 값을 분할하고 변수에 할당합니다.
예를 들어, 다음은 fmt.Scan을 사용하여 두 개의 정수를 입력받고, 그 값을 더하는 간단한 예제입니다
package main
import "fmt"
func main() {
var num1, num2 int
fmt.Println("두 개의 정수를 입력하세요:")
fmt.Scan(&num1, &num2)
sum := num1 + num2
fmt.Println("두 수의 합은:", sum)
}Array
var x [5]int
// Array literal
x := [3]int{1, 2, 3}
y := [...]int{1, 2, 3, 4}for loop, range
range와 for 문은 비슷한 역할을 하지만 사용되는 상황과 목적이 다릅니다.
for 문:
for 문은 일반적인 반복 작업에 사용됩니다.
특정 조건이 충족될 때까지 반복을 계속하거나, 무한 루프를 만들 수 있습니다.
주로 숫자를 증가시키면서 반복하는 등의 작업에 사용됩니다.
초기화 구문, 조건 구문, 후치 구문을 사용하여 반복 과정을 제어합니다.
// for loop
for i := 0; i < 5; i++ {
fmt.Println(i)
}
// 0
// 1
// 2
// 3
// 4range는 컬렉션(배열, 슬라이스, 맵, 문자열 등)을 순회할 때 사용됩니다.
컬렉션의 각 요소에 대해 반복 작업을 수행할 수 있습니다.
컬렉션의 각 요소에 접근하여 작업을 수행할 수 있습니다.
인덱스와 값 또는 키와 값 쌍을 반환합니다.
numbers := []int{1, 2, 3, 4, 5}
for index, value := range numbers {
fmt.Printf("인덱스: %d, 값: %d\n", index, value)
}
// 인덱스: 0, 값: 1
// 인덱스: 1, 값: 2
// 인덱스: 2, 값: 3
// 인덱스: 3, 값: 4
// 인덱스: 4, 값: 5unicode.IsLetter
unicode.IsLetter(char) 함수는 주어진 문자가 유니코드 문자로서 문자 (A-Z, a-z)인지를 확인하는 함수입니다. 즉, 대문자나 소문자 알파벳에 해당하는지를 판별합니다. 이 함수는 Go 언어의 unicode 패키지에 속해 있습니다.
IsLetter() 함수는 주어진 인자가 문자인 경우에는 true를 반환하고, 그렇지 않은 경우에는 false를 반환합니다.
예를 들어, 'A', 'B', 'C', ..., 'Z', 'a', 'b', 'c', ..., 'z'와 같이 알파벳 문자가 입력된 경우에는 true를 반환하고, 숫자나 특수 문자 등 다른 유니코드 문자가 입력된 경우에는 false를 반환합니다.
따라서 hasLetter() 함수는 입력된 문자열에 문자가 포함되어 있는지를 확인할 때 사용되며, 이를 위해 각 문자를 순회하면서 unicode.IsLetter() 함수를 사용하여 문자인지를 판별합니다.
func hasLetter(s string) bool {
for _, char := range s {
if unicode.IsLetter(char) {
return true
}
}
return false
}Slice 참조, 복사
x := [...]int{1, 2, 3, 4, 5}
// 새로운 슬라이스를 생성하여 기존 배열 x를 복사
y := make([]int, len(x))
copy(y, x[:]) // x[:]는 x의 전체 내용을 의미
// 또는 append 함수를 사용하여 새로운 슬라이스를 생성
// x[:]에서 [:]은 배열 x의 모든 요소를 포함하는 슬라이스를 생성하고, ...은 이 슬라이스의 모든 요소를 하나씩 풀어서 append() 함수에 전달합니다. 이렇게 함으로써 append() 함수는 x 배열의 모든 요소를 새로운 슬라이스에 추가할 수 있습니다.
z := append([]int(nil), x[:]...)
//만약 y := x 라고 할 경우, 새로운 슬라이스가 아니라 x를 참조하는 y가 생성된다. y를 조작하면 원본인 x도 그대로 영향을 받는다.
x := [...]int{1, 2, 3, 4, 5}
y := x
y[0] = 10
fmt.Println(x) // [10 2 3 4 5]
fmt.Println(y) // [10 2 3 4 5][] 과 [...]의 차이
x := []int{1, 2, 3, 4, 5}와 x := [...]int{1, 2, 3, 4, 5}는 모두 배열을 초기화하는 방법입니다. 그러나 두 가지 중요한 차이점이 있습니다.
-
길이 지정
[]int{1, 2, 3, 4, 5}는 슬라이스를 생성합니다. 슬라이스는 가변 길이이며, 런타임에 크기가 동적으로 조정될 수 있습니다.
[...]int{1, 2, 3, 4, 5}는 고정된 크기를 갖는 배열을 생성합니다. ...은 배열의 길이를 초기화할 때 사용될 요소의 개수를 나타냅니다. 여기서는 배열의 길이가 5로 지정됩니다. -
타입
[]int{1, 2, 3, 4, 5}는 슬라이스를 생성합니다. 따라서 변수 x의 타입은 슬라이스입니다.
[...]int{1, 2, 3, 4, 5}는 배열을 생성합니다. 따라서 변수 x의 타입은 배열입니다.
따라서 []int{1, 2, 3, 4, 5}는 가변 길이의 슬라이스를 생성하고, [...]int{1, 2, 3, 4, 5}는 고정된 길이의 배열을 생성합니다.
json.Marshal(), json.Unmarshal()
json.Marshal()
json.Marshal() 함수는 Go 언어의 encoding/json 패키지에 포함되어 있으며, Go 데이터 구조를 JSON 문자열로 변환하는 데 사용됩니다. 아래는 json.Marshal() 함수의 간단한 사용 예시입니다.
먼저, Go 언어에서 사용할 구조체를 정의합니다. 예를 들어, 간단한 사용자 정보를 나타내는 구조체를 정의할 수 있습니다.
package main
import (
"encoding/json"
"fmt"
)
// User 구조체 정의
type User struct {
ID int `json:"id"`
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Email string `json:"email"`
}
func main() {
// User 구조체 인스턴스 생성
user := User{
ID: 1,
FirstName: "John",
LastName: "Doe",
Email: "john.doe@example.com",
}
// json.Marshal을 사용하여 User 구조체를 JSON 문자열로 변환
jsonData, err := json.Marshal(user)
if err != nil {
fmt.Println(err)
return
}
// 변환된 JSON 문자열 출력
fmt.Println(string(jsonData))
// 결과 : {"id":1,"first_name":"John","last_name":"Doe","email":"john.doe@example.com"}
}json.Unmarshal()
json.Unmarshal() 함수는 Go 언어의 encoding/json 패키지에 포함되어 있으며, JSON 문자열을 Go 데이터 구조로 변환하는 데 사용됩니다. 아래는 json.Unmarshal() 함수의 간단한 사용 예시입니다.
먼저, Go 언어에서 JSON 데이터를 매핑할 구조체를 정의합니다. 예를 들어, 사용자 정보를 나타내는 구조체를 정의할 수 있습니다.
package main
import (
"encoding/json"
"fmt"
)
// User 구조체 정의
type User struct {
ID int `json:"id"`
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Email string `json:"email"`
}
func main() {
// JSON 문자열
jsonData := `{
"id": 1,
"first_name": "John",
"last_name": "Doe",
"email": "john.doe@example.com"
}`
// User 구조체 타입의 변수 선언
var user User
// json.Unmarshal을 사용하여 JSON 문자열을 User 구조체로 변환
err := json.Unmarshal([]byte(jsonData), &user)
if err != nil {
fmt.Println(err)
return
}
// 변환된 User 구조체 출력
fmt.Printf("%+v\n", user)
// 결과 : {ID:1 FirstName:John LastName:Doe Email:john.doe@example.com}
}os.Open, Read, Write, Close
package main
import (
"fmt"
"os"
)
func main() {
// 파일 열기
inputFile, err := os.Open("example.txt")
if err != nil {
fmt.Println("Error opening file:", err)
return
}
defer inputFile.Close() // 함수 종료 시 파일 닫기
// 파일에서 데이터 읽기
data := make([]byte, 100) // 100바이트를 읽을 버퍼 생성
n, err := inputFile.Read(data)
if err != nil {
fmt.Println("Error reading file:", err)
return
}
fmt.Printf("Read %d bytes: %s\n", n, string(data[:n]))
// 새 파일 생성 및 데이터 쓰기
outputFile, err := os.Create("output.txt")
if err != nil {
fmt.Println("Error creating file:", err)
return
}
defer outputFile.Close() // 함수 종료 시 파일 닫기
n, err = outputFile.Write(data[:n]) // 읽은 데이터 쓰기
if err != nil {
fmt.Println("Error writing to file:", err)
return
}
fmt.Printf("Wrote %d bytes.\n", n)
}이 코드는 다음 단계를 수행합니다:
- os.Open을 사용하여 "example.txt" 파일을 읽기 전용으로 엽니다.
- make([]byte, 100)을 통해 100바이트 크기의 버퍼를 생성하고, inputFile.Read(data)를 사용하여 파일로부터 데이터를 읽습니다. 반환된 n은 실제로 읽은 바이트 수입니다.
- 읽은 데이터를 출력합니다.
- os.Create을 사용하여 "output.txt"라는 새 파일을 생성합니다. 이 함수는 파일이 이미 존재하는 경우 내용을 덮어씁니다.
- outputFile.Write(data[:n])을 사용하여 새 파일에 데이터를 씁니다.
- 두 파일 모두 defer 구문을 사용하여 함수가 종료될 때 자동으로 닫힙니다.
os.Read와 os.Write는 Read와 Write 메소드를 통해 각각 *os.File 타입의 객체에 구현되어 있습니다. 이들 메소드는 파일 작업에서 기본적인 입출력을 수행하는 데 사용됩니다.
slice contain a pointer to array
package main
import "fmt"
func foo(sli []int) []int { // slice contain a pointer to array
sli[0] = sli[0] + 1
return sli
}
func main() {
a := []int{1, 2, 3}
fmt.Print(a) // [1 2 3]
foo(a)
fmt.Print(a) // [2 2 3]
}slice는 array에 대한 포인터를 포함하기에 func foo에서 따로 *[]int라고 명시하지 않아도 main의 a 값이 foo에 의해 실제로 변한다.
슬라이스를 만들면, Go는 실제 데이터를 저장하기 위한 배열을 백엔드에서 자동으로 생성하고 관리합니다. 하지만 이 배열은 직접적으로 접근할 수 없으며, 슬라이스를 통해서만 접근할 수 있습니다. 이런 방식으로 슬라이스는 데이터 구조의 추상화를 제공하며, 배열의 복잡성을 숨기고 보다 유연한 데이터 조작을 가능하게 합니다.
strings.Fields()
strings.Fields() 함수는 Go 언어의 strings 패키지에 속해 있으며, 주어진 문자열을 공백으로 분리하여 슬라이스로 반환합니다. 여기서 '공백'이라 함은 공백문자(space), 탭(tab), 개행문자(newline) 등을 모두 포함합니다. 이 함수는 문자열을 단어 단위로 분리할 때 유용하게 사용됩니다.
package main
import (
"fmt"
"strings"
)
func main() {
// 예제 문자열
example := "The quick brown fox jumps over the lazy dog"
// strings.Fields 함수 사용
words := strings.Fields(example)
fmt.Println(words)
}
// 결과 : [The quick brown fox jumps over the lazy dog]
bufio.NewScanner() vs bufio.NewReader()
bufio.NewScanner(os.Stdin)
- 주로 사용되는 경우: 주로 줄 단위로 텍스트를 읽을 때 사용됩니다.
- 동작 방식: NewScanner는 기본적으로 줄바꿈(\n)을 기준으로 데이터를 분리합니다. 즉, 한 번에 한 줄씩 입력을 읽습니다. 스캐너는 Scan 메소드를 호출할 때마다 입력에서 다음 줄을 읽고, Text 또는 Bytes 메소드를 사용하여 그 줄의 내용을 반환합니다.
- 사용 사례: 사용자 입력, 파일에서의 줄 단위 읽기 등 텍스트 기반의 데이터를 다룰 때 유용합니다.'
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
line := scanner.Text() // 또는 scanner.Bytes()로 바이트 슬라이스를 얻을 수 있음
fmt.Println(line)
}bufio.NewReader(os.Stdin)
- 주로 사용되는 경우: 더 세밀한 제어가 필요할 때, 예를 들어 특정 크기의 바이트를 읽거나, 한 문자(character)씩 읽거나, 줄 단위가 아닌 특정 구분자로 분리된 데이터를 읽을 때 사용됩니다.
- 동작 방식: NewReader는 더 유연하게 입력 스트림을 처리할 수 있는 메소드를 제공합니다. 예를 들어, ReadString, ReadBytes, ReadLine 등의 메소드를 사용하여 데이터를 다양한 방식으로 읽을 수 있습니다.
- 사용 사례: 네트워크 통신, 바이너리 파일 읽기 등에서 더 복잡한 입력 처리가 필요할 때 사용됩니다.
reader := bufio.NewReader(os.Stdin)
line, _ := reader.ReadString('\n') // 줄바꿈 문자까지 읽고, 문자열로 반환
fmt.Println(line)주요 차이점 요약
- 사용 용도와 유연성: NewScanner는 주로 줄 단위의 텍스트 처리에 적합하며, 간단하고 직관적인 API를 제공합니다. 반면, NewReader는 더 다양한 입력 처리가 가능하며, 세밀한 제어가 필요한 경우에 유리합니다.
- 메소드와 반환값: NewScanner는 Scan 메소드를 통해 다음 입력으로 이동하고, Text 또는 Bytes로 데이터를 가져옵니다. NewReader는 ReadString, ReadBytes, ReadLine 등 다양한 메소드를 제공하여 더 많은 유형의 입력을 처리할 수 있습니다.
First-Class functions. 인자로 함수 전달
함수를 다른 함수의 인자로 전달.
package main
import "fmt"
func applyOperation(a, b int, operation func(int, int) int) int {
return operation(a, b)
}
func main() {
add := func(a, b int) int {
return a + b
}
result := applyOperation(2, 3, add)
fmt.Println(result) // 출력: 5
}
Variable Argument Number. 다중인자
다중인자(...) 예시
func getMax(vals ...int) int {
maxV := -1
for _, v := range vals {
if v > maxV {
maxV = v
}
}
return maxV
}
// getMax에 slice를 인자로 전달하는 것으로 ... 를 적용시킬 수도 있음
func main() {
fmt.Println(getMax(1, 3, 6, 4))
vslice := []int{1, 3, 6, 4}
fmt.Println(getMax(vslice...))
}
Deferred Function Calls. 지연 함수
defer 키워드는 Go 언어에서 함수의 실행을 지연시키기 위해 사용됩니다. defer로 지정된 함수나 메서드는 해당 함수의 나머지 부분이 실행되고 나서, 바로 직전에 호출되는 함수가 리턴되기 직전에 실행됩니다. 이는 리소스를 해제하거나, 파일을 닫거나, 잠금을 해제하는 등의 정리 작업에 매우 유용합니다.
package main
import "fmt"
func main() {
i := 1
defer fmt.Println(i + 1)
i++
fmt.Println("hello")
}
// hello
// 2- i는 1로 초기화됩니다.
- defer fmt.Println(i + 1)가 호출되며, 이 시점에서 i + 1의 계산이 이루어져 2가 fmt.Println 함수로 전달되는 인자로 고정됩니다.
- i의 값이 1에서 2로 증가됩니다.
- "hello"가 출력됩니다.
- main 함수가 종료되려고 할 때, 지연되었던 fmt.Println 함수가 호출되고, 이미 계산되어 고정된 인자값 2를 사용하여 2가 출력됩니다.
Closure
package main
import "fmt"
func incrementGenerator() func() int {
i := 0 // 클로저에 의해 캡처될 변수
return func() int {
i++
return i
}
}
func main() {
increment := incrementGenerator()
fmt.Println(increment()) // 출력: 1
fmt.Println(increment()) // 출력: 2
fmt.Println(increment()) // 출력: 3
}예제에서, incrementGenerator 함수는 i 변수를 캡처하는 클로저를 반환합니다. 반환된 클로저는 호출될 때마다 i의 값을 1씩 증가시킵니다. 이 클로저는 i 변수의 상태를 "기억"하기 때문에, increment를 호출할 때마다 이전 상태에 기반하여 동작합니다.
이처럼 클로저는 함수와 그 함수가 선언된 스코프의 환경을 "결합"하여, 함수가 자신의 외부 환경과 상호작용할 수 있도록 해줍니다. 이는 Go를 포함한 많은 프로그래밍 언어에서 강력한 프로그래밍 패턴을 가능하게 합니다.
구조체(Structs) & 메서드(Methods) & 인터페이스(Interfaces)
Structs
구조체는 여러 필드(데이터)를 그룹화하여 하나의 복합 데이터 타입을 정의합니다. 객체 지향 프로그래밍에서 클래스가 하는 역할과 유사한 부분이 있지만, Go의 구조체는 메서드를 내부에 포함하지 않고 별도로 정의합니다.
type Person struct {
Name string
Age int
}Methods
Go에서 메서드는 특정 타입(struct 또는 interface)에 연결된 함수입니다. 메서드를 정의할 때는 함수 정의 앞에 (name receiver_type) 을 명시하여, 해당 메서드가 어떤 타입에 속하는지를 지정합니다. 이렇게 정의된 메서드는 해당 타입의 인스턴스(또는 포인터)를 통해 호출될 수 있습니다.
func (p Person) SayHello() {
fmt.Println("Hello, my name is", p.Name)
}위 예시에서 SayHello 메서드는 Person 타입에 연결되어 있으며, Person 타입의 인스턴스를 통해 호출될 수 있습니다.
Interfaces
인터페이스는 메서드 시그니처의 모음으로, 어떤 타입이 특정 메서드들을 구현하고 있는지를 정의합니다. 구조체와 함께 인터페이스를 사용하면, 다형성을 비롯한 객체 지향 프로그래밍의 여러 개념을 구현할 수 있습니다.
특정 구조체가 Greeter 인터페이스의 모든 메서드를 구현하면, 그 구조체는 Greeter 인터페이스를 구현한 것으로 간주됩니다.
먼저, Greeter 인터페이스를 정의합니다.
type Greeter interface {
SayHello()
Goodbye()
ThankYou()
}그리고 이 인터페이스를 만족시키는 구조체 Person을 정의하고, SayHello 메서드를 구현합니다.
type Person struct {
Name string
}
func (p Person) SayHello() {
fmt.Println("Hello, my name is", p.Name)
}
func (p Person) Goodbye() {
fmt.Println("Goodbye from", p.Name)
}
func (p Person) ThankYou() {
fmt.Println("Thank you, says", p.Name)
}여기서 Person 구조체는 SayHello 메서드를 구현함으로써 Greeter 인터페이스의 요구사항을 만족시킵니다. 따라서 Person 타입의 인스턴스는 Greeter 인터페이스 타입으로 사용될 수 있습니다.
이를 활용하는 예시 코드는 다음과 같습니다
func greet(g Greeter) {
g.SayHello()
g.Goodbye()
g.ThankYou()
}
func main() {
p := Person{Name: "John"}
greet(p) // "Hello, my name is John", "Goodbye from John", "Thank you, says John" 출력
}greet 함수는 Greeter 인터페이스를 매개변수로 받습니다. 이 함수 내에서는 매개변수 g가 SayHello 메서드를 가지고 있음을 알고 있으며, 이 메서드를 호출할 수 있습니다. main 함수에서 Person 인스턴스 p를 생성하고 greet 함수에 전달함으로써, Person이 Greeter 인터페이스를 구현했음을 확인할 수 있습니다. 이 예시는 Go 언어가 인터페이스를 구현하는 타입을 명시적으로 선언할 필요가 없이, 해당 인터페이스의 모든 메서드를 구현하기만 하면 자동으로 그 인터페이스를 만족한다는 타입 추론 기능을 보여줍니다.
Encapsulation
Go 언어에서 캡슐화(Encapsulation)는 대상 객체의 세부 구현 내용을 숨기고, 객체와 상호작용하는 데 필요한 인터페이스만을 외부에 노출시키는 방법을 의미합니다. Go에서는 패키지를 기반으로 캡슐화를 구현합니다. 특히, 변수나 함수(메서드 포함)의 이름이 대문자로 시작하면 해당 요소는 외부 패키지에서 접근할 수 있는 exported 상태가 되며, 소문자로 시작하면 패키지 내부에서만 접근 가능한 unexported 상태가 됩니다.
package main
import (
"fmt"
"math"
)
// Circle 구조체에서는 radius 필드를 소문자로 시작해 패키지 외부에서의 직접 접근을 제한합니다.
type Circle struct {
radius float64
}
// NewCircle 함수는 새로운 Circle 인스턴스를 생성하는 생성자 함수 역할을 합니다.
func NewCircle(initialRadius float64) *Circle {
return &Circle{radius: initialRadius}
}
// SetRadius 메서드는 Circle의 radius를 설정합니다. 이 메서드를 통해 캡슐화를 유지하면서 radius 값을 변경할 수 있습니다.
func (c *Circle) SetRadius(radius float64) {
if radius > 0 {
c.radius = radius
}
// radius가 0보다 작거나 같은 경우에는 radius를 변경하지 않습니다. 필요하다면 에러 처리를 추가할 수 있습니다.
}
// Area 메서드는 Circle의 면적을 계산하여 반환합니다.
func (c *Circle) Area() float64 {
return math.Pi * c.radius * c.radius
}
func main() {
circle := NewCircle(5.0) // 반지름이 5.0인 원을 생성합니다.
fmt.Println(circle.Area()) // 원의 면적을 출력합니다.
circle.SetRadius(10.0) // 반지름을 10.0으로 변경합니다.
fmt.Println(circle.Area()) // 변경된 원의 면적을 출력합니다.
}^ func NewCircle에서 return type을 포인터(*Circle)로 설정한 이유
-
메모리 효율성: 구조체가 큰 경우, 그 구조체의 값을 직접 반환하는 것은 메모리 복사를 발생시켜 비효율적일 수 있습니다. 포인터를 사용하면 구조체의 실제 데이터를 복사하지 않고 그 위치만을 전달하기 때문에 메모리 사용을 줄일 수 있습니다.
-
데이터 일관성: 포인터를 통해 구조체 인스턴스를 반환하면, 이후에 이 인스턴스의 필드를 수정할 때 원본 데이터가 수정됩니다. 즉, 여러 곳에서 동일한 구조체 인스턴스를 참조하고 있을 경우, 어느 한 곳에서의 변경이 모든 참조지점에 반영되어 데이터의 일관성을 유지할 수 있습니다 (구조체 인스턴스에 대한 포인터를 여러 곳에서 참조할 때, 해당 인스턴스의 필드 변경이 모든 참조 지점에 반영되어 데이터의 일관성을 유지하는 것은 패키지 내부뿐만 아니라 외부에서도 해당됩니다. 중요한 것은 접근 가능성과 데이터의 일관성은 서로 다른 개념입니다).
-
메서드에서의 변경 가능성: 구조체 포인터를 사용하면, 해당 구조체의 메서드 내에서 구조체의 필드를 수정할 수 있습니다. 값 타입(구조체 인스턴스 자체)을 사용할 경우, 메서드 내에서 구조체의 필드를 수정해도 그 변경 사항이 호출 지점에 반영되지 않습니다. 반면, 포인터 타입을 사용하면 메서드에서 구조체의 필드를 변경했을 때 그 변경사항이 원본 인스턴스에 적용되어, 예상대로의 동작을 할 수 있습니다.
따라서, NewCircle 함수에서 *Circle를 반환 타입으로 사용하는 것은 이러한 이유들 때문입니다. 이는 Go에서 일반적인 패턴으로, 구조체를 다룰 때 메모리 효율성을 높이고, 구조체의 상태 변경을 용이하게 하며, 데이터의 일관성을 유지하기 위해 널리 사용됩니다.
Point Receivers
포인터 리시버는 Go 언어에서 메서드가 연결될 구조체의 인스턴스를 가리키는 포인터를 사용하는 방식을 말합니다. 이 방법을 사용하면, 메서드 내에서 구조체의 필드 값을 변경할 수 있으며, 모든 변경사항이 원본 인스턴스에 반영됩니다. 즉, 메서드가 해당 구조체 인스턴스의 복사본이 아닌 실제 인스턴스를 수정하게 됩니다.
포인터 리시버를 사용하는 이유는 주로 두 가지입니다:
-
구조체 인스턴스의 변경: 메서드 내에서 리시버로 전달된 구조체의 필드를 변경하고자 할 때 사용합니다. 포인터를 통해 원본 구조체에 접근하기 때문에, 메서드 내에서 이루어진 변경사항이 호출자에게 반영됩니다.
-
성능 최적화: 큰 구조체를 다룰 때, 값 리시버를 사용하면 메서드 호출 시마다 구조체의 복사본이 생성됩니다. 포인터 리시버를 사용하면, 구조체의 복사본을 생성하지 않고 원본 구조체에 대한 포인터만 전달되므로, 메모리 사용량이 감소하고 성능이 향상됩니다.
type Person struct {
Name string
Age int
}
// 포인터 리시버를 사용하여 Person 구조체의 메서드를 정의합니다.
// 이 메서드는 Person 인스턴스의 Age 필드를 1 증가시킵니다.
func (p *Person) Birthday() {
p.Age += 1
}위 예시에서 Birthday 메서드는 *Person 타입의 리시버를 사용합니다. 이는 Birthday 메서드가 Person 타입의 포인터, 즉 Person 구조체의 인스턴스를 가리키는 포인터를 리시버로 받는다는 의미입니다. 따라서, Birthday 메서드를 호출할 때 해당 Person 인스턴스의 Age 필드를 직접 변경할 수 있으며, 이 변경은 메서드 호출 후에도 유지됩니다.
포인터 리시버와 값 리시버 중 어느 것을 사용할지는 주로 위의 두 가지 기준(인스턴스의 변경 필요성과 성능 고려사항)에 따라 결정됩니다.
Referencing & Dereferencing
Go 언어에서, pointer receiver는 특정 타입의 포인터를 메서드의 수신자(receiver)로 사용하는 것을 의미합니다. 이를 통해 메서드 내에서 수신자가 가리키는 값에 대해 직접적인 수정이 가능하게 됩니다. 이와 관련하여, referencing과 dereferencing은 포인터를 다룰 때 기본적인 개념들입니다.
- Referencing (&): 변수의 주소를 얻어내는 행위입니다. 예를 들어, var a int가 있을 때, &a는 a의 메모리 주소를 반환합니다.
- Dereferencing (): 포인터가 가리키는 메모리 주소에 저장된 값을 얻어내는 행위입니다. 예를 들어, var a int가 있을 때, *a는 a 포인터가 가리키는 메모리 주소에 있는 실제 정수 값을 반환합니다.
package main
import "fmt"
type Circle struct {
Radius float64
}
// 포인터 리시버를 사용하는 메서드
// 이 메서드는 Circle의 Radius 값을 변경할 수 있습니다.
func (c *Circle) SetRadius(r float64) {
c.Radius = r // dereferencing을 통해 값에 접근하여 변경
}
func main() {
c := Circle{Radius: 5.0}
fmt.Println("Before:", c.Radius) // 변경 전 Radius 값 출력
c.SetRadius(10.0) // SetRadius 메서드 호출
fmt.Println("After:", c.Radius) // 변경 후 Radius 값 출력
}이 예시에서 SetRadius 메서드는 포인터 리시버 *Circle을 사용하여 Circle 인스턴스의 Radius 필드 값을 변경합니다. 메서드를 호출할 때, Circle 인스턴스의 주소를 넘겨주어 (&c) 해당 인스턴스의 Radius 값을 직접 수정할 수 있습니다. 실제로는 c.SetRadius(10.0)처럼 직접 인스턴스에 메서드를 호출하는 방식으로도 Go 언어가 내부적으로 주소를 넘겨주는 방식을 처리합니다 (&를 명시적으로 사용하지 않아도 됨).
이렇게 포인터 리시버를 사용하면 메서드 내에서 호출한 객체의 실제 값을 변경할 수 있어, 상태를 가지는 객체를 다룰 때 유용합니다. 반면, 값 리시버(value receiver)를 사용한 메서드는 호출 시 객체의 복사본을 생성하므로 원본 객체에 대한 변경이 불가능합니다.
Polymorphism
Go언어에서의 다형성(polymorphism)은 인터페이스를 사용하여 구현됩니다. Go는 객체지향 프로그래밍 언어의 전통적인 클래스 기반 상속 대신 인터페이스를 통한 다형성을 지원합니다. 이를 통해 서로 다른 타입의 객체가 동일한 인터페이스를 구현함으로써 같은 방식으로 처리될 수 있습니다.
Go에서 인터페이스는 메서드 시그니처(메서드의 이름, 메서드가 받는 매개변수(parameter)의 타입, 메서드가 반환하는 결과(result)의 타입들을 의미)의 집합으로 정의됩니다. 어떤 타입이든 이 인터페이스의 모든 메서드를 구현한다면, 해당 인터페이스를 구현한 것으로 간주됩니다. Go의 인터페이스는 명시적으로 구현을 선언할 필요가 없어, 다른 언어들에 비해 유연합니다.
다형성의 주요 이점은 코드의 유연성과 재사용성을 증가시킨다는 것입니다. 예를 들어, 서로 다른 구조체 타입이 같은 인터페이스를 구현하고 있다면, 이 인터페이스 타입을 매개변수로 받는 함수는 어떤 구조체의 인스턴스든 받아들일 수 있습니다. 이를 통해 다양한 타입에 대해 동일한 작업을 수행할 수 있는 범용적인 함수나 알고리즘을 작성할 수 있습니다.
package main
import "fmt"
// Shape 인터페이스는 Area와 Perimeter 메서드를 정의합니다.
type Shape interface {
Area() float64
Perimeter() float64
}
// Triangle 구조체 타입은 삼각형을 나타냅니다.
// 삼각형의 둘레 계산을 위해 세 변의 길이를 나타내는 필드를 추가합니다.
type Triangle struct {
base, height, side1, side2 float64
}
// Triangle 타입에 대한 Area 메서드 구현
func (t Triangle) Area() float64 {
return 0.5 * t.base * t.height
}
// Triangle 타입에 대한 Perimeter 메서드 구현
func (t Triangle) Perimeter() float64 {
return t.side1 + t.side2 + t.base
}
// Rectangle 구조체 타입은 사각형을 나타냅니다.
type Rectangle struct {
width, height float64
}
// Rectangle 타입에 대한 Area 메서드 구현
func (r Rectangle) Area() float64 {
return r.width * r.height
}
// Rectangle 타입에 대한 Perimeter 메서드 구현
func (r Rectangle) Perimeter() float64 {
return 2 * (r.width + r.height)
}
func main() {
t := Triangle{base: 3, height: 4, side1: 5, side2: 5}
r := Rectangle{width: 5, height: 6}
shapes := []Shape{t, r}
for _, shape := range shapes {
fmt.Printf("Area: %.2f, Perimeter: %.2f\n", shape.Area(), shape.Perimeter())
}
}
이 예제에서는 Shape 인터페이스에 Perimeter 메서드를 추가하여 각 도형의 둘레를 계산하는 기능을 구현합니다. Triangle과 Rectangle 구조체는 이제 Area와 Perimeter 메서드를 모두 구현하여 Shape 인터페이스를 만족합니다. main 함수에서는 두 도형의 넓이와 둘레를 계산하여 출력합니다. 이 방식으로 다형성을 활용하여 다양한 형태의 도형을 동일한 인터페이스를 통해 처리할 수 있음을 볼 수 있습니다.
Interface vs Concrete Types
type Speaker interface {Speak ()}
type Dog struct {name string}
func (d Dog) Speak() {
fmt.Println(d.name)
}
func main() {
var s1 Speaker
var d1 Dog{"Brian"}
s1 = d1
// d1은 Dog 타입의 인스턴스이며, concrete type 에 해당. d1 인스턴스를 s1 변수에 할당. 이 때, d1은 Speaker 인터페이스를 구현하고 있으므로, 이러한 할당이 가능
// s1의 'Dynamic type'은 'Dog', 'Dynamic value'는 'd1'
s1.Speak()
}코드에서 var s1 Speaker는 Speaker 인터페이스 타입의 변수 s1을 선언합니다. 이어서 var d1 Dog{"Brian"}으로 Dog 타입의 인스턴스 d1을 생성하고, s1 = d1을 통해 d1 인스턴스를 s1 변수에 할당합니다. 이 때, d1은 Speaker 인터페이스를 구현하고 있으므로, 이러한 할당이 가능합니다. 마지막으로 s1.Speak() 호출을 통해, d1 인스턴스에 저장된 Dog의 Speak() 메서드를 실행합니다.
여기서 var s1 Speaker는 Speaker 인터페이스 타입의 변수를 선언합니다. 이때 s1은 아직 어떠한 구체적인 타입도 가리키지 않기 때문에, 동적 타입과 동적 값은 nil입니다. 하지만 s1 = d1이 실행될 때, s1은 Dog 타입의 d1 인스턴스를 가리키게 됩니다. 이 순간부터 s1의 동적 타입은 Dog이 되고, 동적 값은 d1 인스턴스가 됩니다.
즉, 이 코드에서 s1은 인터페이스 타입의 변수이며, 실행 시점에 Dog 타입의 d1 인스턴스를 가리키므로, s1의 동적 타입은 Dog이고, 동적 값은 d1입니다.
Interface with Nil Dynamic Value
type Speaker interface {Speak ()}
var s1 Speaker
var d1 *Dog
s1 = d1
s1.Speak()s1의 'Dynamic type'은 *Dog, 그러나 'Dynamic value'는 'nil'이다 . 그 이유는 d1이 'Dynamic value'가 없기 때문. d1은 pointer이고 실제 값을 직접 가진게 아니기 때문에 정보를 가지고 있지 않음. 즉 'Dynamic type'은 있지만 'Dynamic value'는 없는 상태. 그렇기에 여전히 s1의 메서드를 호출할 수 있음. 'Dynamic type'만 있어도 메소드 호출이 가능하다.
- 아래는 Dynamic value가 없을 때를 대비해 조건문을 추가한 코드
type Speaker interface {Speak ()}
func (d *Dog) Speak() {
if d == nil { // 'Dynamic value'가 존재하는지 체크. 만약 nil 체크를 안하면 값이 없음에도 출력하려고 해서 런타임에 오류 발생할 수 있다.
fmt.Println("<noise>")
} else {
fmt.Println(d.name)
}
}
var s1 Speaker
var d1 *Dog
s1 = d1
s1.Speak()Nil Interface Value
Dynamic value가 없을 뿐만 아니라 Dynamic Type도 없다.
type Speaker interface {Speak ()}
var s1 Speaker // s1 = d1같은 할당이 없어서 dynamic type도 없는 상태이 상태에선 호출할 실제 메서드가 없음. 관련된 메서드가 하나도 없는 상태. 위 예시에선 s1과 관련된 Speak 메소드가 구현된 게 없기 때문에 에러 발생 가능.
Interface Use Case
type Shape2D interface {
Area() float64
Perimeter() float64
}
type Triangle{...}
func (t Triangle) Area() float64 {...}
func (t Triangle) Perimeter() float64 {...}
type Rectangle{...}
func (r Rectangle) Area() float64 {...}
func (r Rectangle) Perimeter() float64 {...}
func FitInYard(s Shape2D) bool {
if(s.Area() > 100 && s.Perimeter() > 100) {
return true
}
return false
}여러 type의 인자(ex string, number...)를 함수에서 받아들이고 사용하기 위해서 interface를 활용할 수 있다. 위의 코드에서 'Shape2D' interface를 만족하는 type이라면 그게 무엇이든 FitInYard 함수의 인자로서 사용될 수 있다.
Empty Interface
빈 인터페이스는 미리 정의된 표준 인터페이스이며 메서드를 지정하지 않는다. 즉, 어떤 유형이든 해당 인터페이스를 실제로 만족시킬 수 있다는 뜻이다. 함수 인자가 어떤 유형이든 받아들여지도록 할 때 주로 사용.
func PrintMe (val interface{}) {
fmt.PrintIn(val)
}val은 어떤 type이든 될 수 있다.
Interface type, Concrete type, dynamic type, dynamic value
package main
import "fmt"
// 'Interface type'
// Animal 인터페이스는 Speak 메서드를 가지고 있습니다.
type Animal interface {
Speak() string
}
// 'Concrete type'
// Dog 구조체는 Animal 인터페이스를 구현합니다.
type Dog struct{}
// Dog 타입을 위한 Speak 메서드 구현입니다.
func (d Dog) Speak() string {
return "Woof!"
}
// Cat 구조체도 Animal 인터페이스를 구현합니다. Cat 역시 'Concrete type'입니다.
type Cat struct{}
// Cat 타입을 위한 Speak 메서드 구현입니다.
func (c Cat) Speak() string {
return "Meow!"
}
func main() {
var animal Animal // animal 변수는 Animal 'Interface type'입니다.
// '이 시점에서 animal의 'Dynamic Type'은 Dog입니다.
animal = Dog{} // animal에 Dog 인스턴스를 할당합니다. 이 시점에서 animal의 'Dynamic Type'은 Dog입니다.
fmt.Println(animal.Speak()) // 출력: Woof!
// 이 시점에서 animal의 'Dynamic Type'은 Cat입니다.
animal = Cat{} // animal에 Cat 인스턴스를 할당합니다. 여기서 Cat{}는 'Dynamic value'입니다.
fmt.Println(animal.Speak()) // 출력: Meow!
}
Type Assertion
Go 언어에서 타입 어설션(type assertion)은 인터페이스 값을 구체적인 타입의 값으로 변환하는 기능입니다. 이를 통해 동적 타입을 가진 인터페이스 변수에서 더 구체적인 타입의 값을 추출할 수 있습니다. 타입 어설션은 주로 인터페이스가 여러 타입의 값을 받아들일 수 있을 때, 그 값의 실제 타입을 확인하거나 변환하기 위해 사용됩니다.
타입 어설션이 성공하면, 변환된 값과 true가 반환되고, 실패하면 두 번째 값으로 false가 반환됩니다. 만약 타입 어설션을 단언문 형태로 사용할 경우 (예: value := interfaceValue.(Type)) 어설션이 실패하면 패닉(panic)이 발생합니다.
func DrawShape (s Shpae2D){...} // DrawShape() will draw any shape
func DrawRect (r Rectangle){...}
func DrawTriangle (t Triangle){...}
func DrawShape(s Shape2D) bool {
rect, ok := s.(Rectangle) // Type Assertion
if ok {
DrawTriangle(rect)
}
tri, ok := s.(Triangle)
if ok {
DrawRect(tri)
}
}타입 어설션이 성공하면, 변환된 값과 true가 반환되고, 실패하면 두 번째 값으로 false가 반환됩니다. 만약 타입 어설션을 단언문 형태로 사용할 경우 (예: value := interfaceValue.(Type)) 어설션이 실패하면 패닉(panic)이 발생합니다.
Type Switch
func DrawShape(s Shape2D) bool {
switch:= sh := s.(type) {
case Rectangle:
DrawRect(sh)
case Triangle:
DrawTriangle(sh)
}
}Error Interface
기본 에러 인터페이스 구조
type error interface {
Error() string
}예시
// 예시 1
func doSomething() error {
// 에러 상황 발생
return errors.New("an error occurred")
}
func main() {
err := doSomething()
if err != nil {
fmt.Println(err.Error())
// 에러 처리
}
}
// 예시 2
f, err := os.Open("/harris/test.txt")
if err != nil {
fmt.Println(err)
return
}사용자 정의 에러 예시
type MyError struct {
Msg string
Code int
}
func (e *MyError) Error() string {
return fmt.Sprintf("Code: %d, Msg: %s", e.Code, e.Msg)
}
func doSomething() error {
// 사용자 정의 에러 반환
return &MyError{Msg: "Something bad happened", Code: 400}
}
func main() {
err := doSomething()
if err != nil {
fmt.Println(err.Error())
// 여기서 err는 MyError 타입입니다.
}
}
Concurrency(동시성) vs Pararell(병렬성)
Golang에서 "parallel"과 "concurrency"는 다른 개념을 나타냅니다.
- Parallelism (병렬성):
- 병렬성은 여러 작업이 동시에 실행되는 것을 의미합니다.
- 이것은 다중 CPU 또는 CPU 코어에서 작업을 분할하여 동시에 처리함으로써 달성됩니다.
- Go에서는 go 키워드를 사용하여 고루틴을 시작하여 병렬성을 구현할 수 있습니다.
- Concurrency (동시성):
- 동시성은 동시에 여러 작업이 진행되는 것을 의미합니다.
- 단일 CPU 또는 CPU 코어에서 여러 작업이 번갈아가면서 실행될 수 있습니다.
- Go의 채널(channel) 및 고루틴(goroutine)과 같은 기능을 사용하여 동시성을 구현할 수 있습니다.
- Go의 동시성은 I/O 작업이나 동시성 문제를 다룰 때 특히 유용합니다.
즉, 병렬성은 물리적인 동시성을 가리키며, 동시성은 논리적인 동시성을 의미합니다. Go에서는 이러한 두 가지 개념을 모두 지원하여 복잡한 작업을 효과적으로 처리할 수 있습니다.
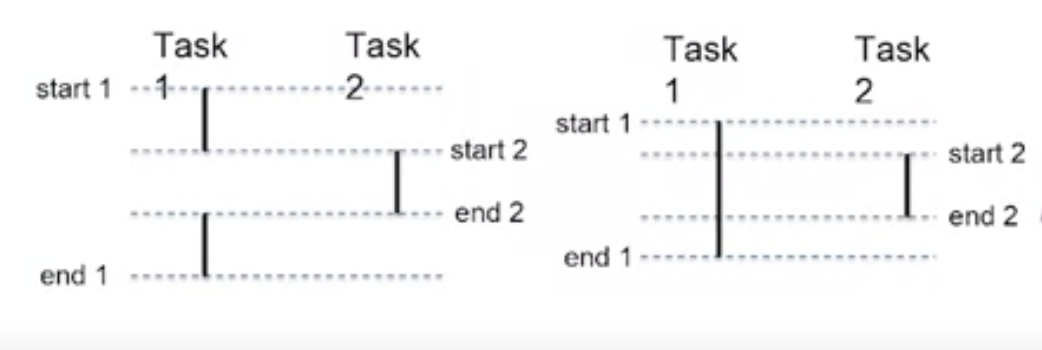
*좌측 : Concurrency 우측 : Pararell
Interleaving
parallel로 작동하는 코드를 처리하는 과정에서 처리 과정이 교차로 처리되는 현상.
기계어 처리 과정에서 명령을 처리하는 순서는 하드웨어나 운영체제에 따라 다를 수 있습니다. 그러나 동시성을 다루는 경우, 여러 명령이 교차로 처리될 수 있습니다. 이것이 interleaving의 개념입니다.
간단한 예시로, CPU는 여러 명령을 동시에 처리하기 위해 파이프라인(pipeline)이라는 메커니즘을 사용합니다. 이 파이프라인에서는 여러 명령이 동시에 실행되는 것처럼 보이지만, 사실은 여러 명령이 교차로 처리됩니다. 이것이 interleaving의 일종으로 볼 수 있습니다.
또 다른 예로는 멀티코어 프로세서가 여러 스레드를 동시에 처리하는 경우를 들 수 있습니다. 이러한 경우에도 각각의 코어는 여러 작업을 동시에 처리하고, 작업들은 서로 교차하여 실행될 수 있습니다. 이 또한 interleaving의 개념을 따릅니다.
따라서 interleaving은 동시성을 다룰 때 발생하는 명령의 교차 처리를 나타내는 개념으로, 여러 작업이 동시에 진행되는 것처럼 보이게 합니다.
Go Routine
package main
import (
"fmt"
"time"
)
func add(a, b int) {
sum := a + b
fmt.Printf("%d + %d = %d\n", a, b, sum)
}
func subtract(a, b int) {
diff := a - b
fmt.Printf("%d - %d = %d\n", a, b, diff)
}
func main() {
go add(1, 2) // 첫 번째 고루틴: 덧셈 연산
go subtract(5, 3) // 두 번째 고루틴: 뺄셈 연산
// 고루틴들이 실행되기에 충분한 시간을 주기 위해 메인 고루틴을 잠깐 멈춥니다.
// 실제 프로그램에서는 이 방법 대신 채널(channel)이나 sync 패키지의 기능을 사용해 동기화를 해야 합니다.
time.Sleep(1 * time.Second)
}
// 결과
// 5 - 3 = 2
// 1 + 2 = 3Race condition
Race condition(경쟁 상태)은 프로그램이 여러 스레드 또는 고루틴에서 동시에 접근할 때 발생하는 문제입니다. 특히, 두 개 이상의 스레드나 고루틴이 동시에 공유된 자원에 접근하고 수정하는 경우 발생합니다. 이때 실행 결과가 예측할 수 없게 되는 것을 의미합니다.
Golang에서도 race condition은 중요한 이슈입니다. 고루틴은 동시에 실행되므로, 공유된 데이터나 자원에 대한 접근을 조심스럽게 해야 합니다. 예를 들어, 하나의 변수를 동시에 읽고 쓰는 경우에는 race condition이 발생할 수 있습니다.
예를 들어, 다음과 같은 코드에서 race condition이 발생할 수 있습니다:
package main
import (
"fmt"
"sync"
)
var (
counter int
wg sync.WaitGroup
)
func increment() {
defer wg.Done()
for i := 0; i < 1000; i++ {
counter++
}
}
func main() {
wg.Add(2) // 2개의 goroutine을 실행할 예정
go increment() // 첫 번째 goroutine으로 counter 증가
go increment() // 두 번째 goroutine으로 counter 증가
wg.Wait() // 모든 goroutine이 완료될 때까지 기다림
fmt.Println("Final counter:", counter)
}
두 개의 goroutine이 반복적으로 공유 변수를 수정하는 경우입니다. 이 경우 race condition이 발생하기 쉬워집니다. 이 코드에서는 counter++ 연산이 각 goroutine에서 1000번 반복되므로, 두 goroutine이 동시에 counter를 수정하려고 시도할 때 race condition이 발생하기 쉽습니다. 그 결과, counter의 최종 값이 예상치 못한 값으로 나올 수 있습니다. Go의 -race 플래그를 사용하여 이러한 상황을 감지할 수 있습니다.
Race condition 방지
'sync' 패키지는 Go에서 동시성 제어와 관련된 기능을 제공합니다. 주로 공유 자원에 대한 안전한 접근을 보장하고, race condition을 방지하기 위해 사용됩니다. sync 패키지 안에는 여러 유용한 도구들이 있으며, 가장 대표적인 것들은 'sync.Mutex'와 'sync.WaitGroup'입니다.
sync.Mutex
- sync.Mutex는 상호 배제(mutual exclusion)를 제공합니다. 즉, 한 시점에 단 하나의 고루틴만이 코드의 특정 부분을 실행할 수 있게 합니다. 이는 공유 자원에 대한 동시 접근을 막아 race condition을 방지하는 데 사용됩니다.
- 공유 자원을 수정하기 전에 Lock 메서드를 호출하여 락을 획득하고, 수정이 끝난 후에는 Unlock 메서드를 호출하여 락을 해제합니다.
package main
import (
"fmt"
"sync"
)
var (
total int
mutex sync.Mutex
wg sync.WaitGroup
)
func add(value int) {
mutex.Lock() // 공유 자원에 대한 접근을 위해 락을 획득
total += value
mutex.Unlock() // 작업 완료 후 락 해제
wg.Done()
}
func main() {
wg.Add(3) // 3개의 고루틴을 기다림
go add(100)
go add(200)
go add(300)
wg.Wait() // 모든 고루틴이 종료될 때까지 기다림
fmt.Printf("Total: %d\n", total) // 최종 결과 출력
}
// Total: 600sync.WaitGroup
- sync.WaitGroup은 고루틴이 작업을 완료할 때까지 기다리는 데 사용됩니다. 이는 고루틴이 비동기적으로 실행되는 경우, 주 실행 흐름(main 함수 등)에서 고루틴들의 작업 완료를 기다리고 싶을 때 유용합니다.
- Add 메서드로 기다려야 할 고루틴의 수를 설정하고, 각 고루틴의 작업이 끝날 때 Done 메서드를 호출하여 고루틴의 완료를 알립니다. 모든 고루틴이 Done을 호출하면, Wait 메서드에서 대기하고 있던 블록이 해제됩니다.
이러한 동기화 메커니즘을 통해 여러 고루틴이 동일한 자원에 접근할 때 발생할 수 있는 문제들을 효과적으로 해결할 수 있습니다. 따라서 sync 패키지는 Go에서 동시성을 안전하게 관리하는 데 필수적인 역할을 합니다.
package main
import (
"fmt"
"sync"
)
var (
total int
wg sync.WaitGroup
mutex sync.Mutex
)
func add(value int) {
mutex.Lock() // 공유 자원 접근 전 락 획득
total += value // 공유 자원에 대한 연산
mutex.Unlock() // 락 해제
wg.Done() // WaitGroup 카운터 감소
}
func main() {
numbers := []int{100, 200, 300} // 더할 숫자들
wg.Add(len(numbers)) // 고루틴의 수를 설정
for _, number := range numbers {
go add(number) // 각 숫자를 더하는 고루틴 실행
}
wg.Wait() // 모든 고루틴의 완료를 기다림
fmt.Printf("Total: %d\n", total) // 최종 결과 출력
}time.Sleep()
package main
import (
"fmt"
"time"
)
func main() {
go fmt.Printf("New routine")
time.Sleep(100 * time.Millisecond)
fmt.Printf("main routine")
}WaitGroup
WaitGroup 은 고루틴들의 동기화를 위한 일종의 동기화 메커니즘입니다. 이를 사용하여 특정 고루틴이 완료될 때까지 다른 고루틴들을 기다릴 수 있습니다. 이를 통해 메인 고루틴이 일찍 종료되는 상황을 방지하고, 모든 고루틴이 완료될 때까지 기다릴 수 있습니다. WaitGroup은 내부적으로 카운터를 사용하며, 각 고루틴이 시작될 때 카운터를 증가시키고, 종료될 때 카운터를 감소시킵니다. 메인 고루틴은 위트그룹의 카운터가 0이 될 때까지 대기하며, 모든 고루틴이 종료될 때까지 기다립니다. 이러한 방식으로 고루틴들 간의 순서를 제어하고, 모든 고루틴이 완료될 때까지 대기할 수 있습니다.
package main
import (
"fmt"
"sync"
)
func foo(wg *sync.WaitGroup) {
fmt.Printf("New routine")
wg.Done()
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
go foo(&wg)
wg.Wait()
fmt.Printf("Main routine")
}
// New routineMain routine%
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // 고루틴이 종료될 때마다 WaitGroup의 카운터를 감소시킵니다.
fmt.Printf("Worker %d 시작\n", id)
time.Sleep(time.Second) // 임의의 작업을 수행하는 시간 대신 sleep을 사용합니다.
fmt.Printf("Worker %d 완료\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
wg.Add(1) // 고루틴을 시작하기 전에 WaitGroup의 카운터를 증가시킵니다.
go worker(i, &wg)
}
wg.Wait() // 모든 고루틴이 종료될 때까지 메인 고루틴을 대기시킵니다.
fmt.Println("모든 작업 완료")
}
// kimjingyeong@gimjingyeong-ui-iMac Golang_coursera % go run main.go
// Worker 3 시작
// Worker 2 시작
// Worker 1 시작
// Worker 1 완료
// Worker 2 완료
// Worker 3 완료
// 모든 작업 완료
// kimjingyeong@gimjingyeong-ui-iMac Golang_coursera % go run main.go
// Worker 3 시작
// Worker 1 시작
// Worker 2 시작
// Worker 3 완료
// Worker 2 완료
// Worker 1 완료
// 모든 작업 완료이 코드는 3개의 고루틴을 시작하고, 각각의 고루틴이 종료될 때까지 대기합니다. Add 메서드는 WaitGroup의 카운터를 증가시키고, Done 메서드는 각 고루틴이 종료될 때마다 카운터를 감소시킵니다. 마지막으로 Wait 메서드는 모든 고루틴이 종료될 때까지 대기합니다.
만약 wg.Add(1)을 호출하지 않으면 WaitGroup은 아무런 동작을 수행하지 않고 대기하거나, 모든 고루틴이 완료될 때까지 대기하는 데 사용할 수 없습니다.
Channel
채널은 스레드 간 데이터 교환을 가능하게 하며, 기본적으로는 동기화도 수행합니다. 기본 채널은 용량이 없어서 데이터를 전달하는 경우 보내는 스레드와 받는 스레드가 서로 기다려야 하는데, 이를 블록킹이라고 합니다. 용량이 있는 버퍼드 채널은 데이터를 임시로 보관할 수 있어서 블록킹 없이 보내고 받는 작업을 수행할 수 있습니다. 이를 통해 스레드 간의 속도 불일치를 조정할 수 있고, 채널은 데이터 통신뿐만 아니라 동기화도 제공한다는 것을 알 수 있습니다.
package main
import (
"fmt"
)
func prod(v1, v2 int, c chan int) {
c <- v1 * v2
}
func main() {
c := make(chan int)
go prod(1, 2, c)
go prod(3, 4, c)
a := <-c
b := <-c
fmt.Println(a * b)
}
// 24위 예시 코드는 일반적인 채널입니다. 즉, 용량이 없는(unbuffered) 채널입니다. 채널을 생성할 때 make(chan int)와 같이 용량을 지정하지 않으면, 기본적으로 용량이 0인 채널이 생성됩니다. 이 경우 데이터를 전송할 때 송신자는 수신자가 준비될 때까지 블록됩니다.
따라서 주어진 코드에서 사용된 채널은 용량이 없으므로 일반적인 채널입니다.
prod(1, 2, c)와 prod(3, 4, c) 고루틴이 실행되는 순서는 코드의 순서와는 독립적이며, 런타임 스케줄러에 의해 결정됩니다.
c <- v1 * v2로 채널에 값을 보내는 순서가 고정되어 있지 않기 때문에, a := <-c에서 받는 값이 항상 같다고 보장할 수 없습니다. 따라서 어떤 경우에는 prod(1, 2, c)의 결과인 2가 a에 저장될 수 있고, 다른 경우에는 prod(3, 4, c)의 결과인 12가 a에 저장될 수 있습니다.
Channel blocks a race condition
채널을 사용할 때는 race condition 문제가 발생하지 않습니다. 채널을 통해 값을 전송하면, 해당 값이 다른 고루틴에 의해 읽힐 때까지 보내는 고루틴은 블록(대기 상태) 됩니다. 마찬가지로, 채널에서 값을 읽으려는 고루틴도 해당 채널에 값이 쓰여질 때까지 블록됩니다. 이 메커니즘은 고루틴 간의 실행이 서로에게 영향을 주지 않도록 합니다.
위 예시 코드에서 prod 함수를 고루틴으로 두 번 실행하고, 각 고루틴은 c 채널을 통해 계산 결과를 전달합니다. 첫 번째 prod 호출의 결과가 c 채널에 먼저 도달할지, 두 번째 호출의 결과가 먼저 도달할지는 실행 때마다 달라질 수 있습니다. 하지만, 각각의 결과는 안전하게 전달되며, 메인 고루틴은 채널에서 두 값 모두를 순서대로 안전하게 받아 처리합니다. 따라서, 이 과정에서 race condition은 발생하지 않습니다.
If channel blocks go routine, isn't it synchronous?
Go에서는 고루틴과 채널을 사용하여 비동기 실행과 동기 통신을 조화롭게 결합합니다. 고루틴은 비동기적으로 실행되어 프로그램의 병렬 처리 능력을 향상시키고, 채널은 필요한 지점에서 고루틴 간의 동기화와 안전한 데이터 교환을 보장합니다. 이러한 설계는 동시성 프로그래밍에서 발생할 수 있는 문제들을 효과적으로 해결할 수 있도록 도와줍니다.
따라서, 고루틴과 채널의 사용은 프로그램의 일부분을 동기적으로 만들 수 있지만, 전체 프로그램의 비동기 실행 구조를 유지합니다. 이것은 Go의 동시성 모델이 제공하는 유연성과 강력함의 핵심입니다.
위 코드의 prod 함수를 예로 들어볼 때, go prod(1, 2, c)와 go prod(3, 4, c) 호출은 거의 동시에 시작되며, 어느 것이 먼저 실행될지는 예측할 수 없습니다. 이 두 호출은 병렬적으로 실행되며, 각각의 고루틴은 자신의 작업을 독립적으로 진행합니다.
고루틴 내에서 채널을 사용해 데이터를 주고받는 부분은 고루틴 간의 동기화와 안전한 데이터 교환을 보장합니다. 이것은 채널의 블로킹 메커니즘 때문입니다. 한 고루틴이 채널에 데이터를 보내면, 다른 고루틴이 그 데이터를 받을 때까지 대기하게 됩니다. 반대로, 데이터를 받으려는 고루틴은 채널에 데이터가 도착할 때까지 대기합니다. 이 과정에서 고루틴 간의 실행 순서가 자동으로 조정되어, 고루틴 간에 안전하게 데이터를 주고받을 수 있게 됩니다.
따라서, 고루틴과 채널을 사용하는 Go의 동시성 모델은 비동기적인 고루틴의 실행과 고루틴 간 동기적인 데이터 교환을 가능하게 하여, 동시에 안전성과 효율성을 모두 확보합니다. 이러한 특징은 Go 언어가 동시성 프로그래밍을 용이하게 하는 중요한 이유 중 하나입니다.
Channel with buffered
package main
import (
"fmt"
)
func main() {
// 용량이 3인 버퍼드 채널 생성
c := make(chan int, 3)
// 고루틴에서 채널을 통해 숫자 전송
go func() {
c <- 1
c <- 2
c <- 3
}()
// 채널에서 숫자를 받아 출력
fmt.Println(<-c)
fmt.Println(<-c)
fmt.Println(<-c)
}
// kimjingyeong@gimjingyeong-ui-iMac Golang_coursera % go run main.go
// 1
// 2
// 3
// kimjingyeong@gimjingyeong-ui-iMac Golang_coursera % 위 코드에서는 채널을 생성할 때 용량이 3인 버퍼드 채널을 만들었습니다. 따라서 고루틴에서 채널에 숫자를 전송할 때 채널이 꽉 차지 않아도 즉시 반환됩니다. 그리고 메인 함수에서 숫자를 받을 때까지 대기하지 않아도 됩니다. 버퍼가 가득 찬 상태에서는 첫 번째 데이터가 버퍼에 들어온 순서대로 읽히게 되어서 1이 먼저 출력되고, 그 다음에 2가 출력됩니다. 이는 채널의 특성상 순서가 보장되기 때문입니다. 동시에 여러 데이터를 읽기 위해서는 별도의 처리가 필요합니다.
Channel with go routine(iterable)
package main
import (
"fmt"
"time"
)
func main() {
// channel은 goroutine과 메인함수, 혹은 goroutine 간의 커뮤니케이션을 하는 방법이다.
// channel(chan)을 isSexy로 보내고, 그로 인해 isSexy는 메인함수랑 커뮤니케이션 할 수 있게 된다.
// 채널 만드는 법
// 변수 := make(chan 채널을통해보낼타입)
c := make(chan bool)
people := [2]string{"nico", "flynn"}
// 채널을 두 함수(isSexy nico, isSexy flynn)로 보냄.
for _, person := range people {
go isSexy(person, c)
}
// time.Sleep()이 없어도 메인함수가 바로 종료되지 않고 기다린다.
// 채널로부터 뭔가를 받을 때, 메인함수는 뭔가 답을 받을때까지 기다린다.
fmt.Println(<-c)
fmt.Println(<-c)
// fmt.Println(<-c) 이런식으로 goroutine을 초과해서 실행하려 하면 deadlock이 뜬다. 이미 모든 goroutine이 끝났기 때문.
}
func isSexy(person string, c chan bool) { // 채널을 통해 보낼 타입이 bool이기에 같이 적어줌(c chan bool).
time.Sleep(time.Second * 5) // 두 함수(isSexy nico, isSexy flynn)는 5초 후에 true 라는 메시지를 나에게 2개 보낸다.
fmt.Println(person)
c <- true // goroutine으로부터 return을 받는 대신에 채널을 통해 메시지를 전달한다.
}
// 결과 :
// nico
// true
// flynn
// true
// OR
// flynn
// nico
// true
// true
<-channel
package main
import (
"fmt"
"time"
)
func main() {
done := make(chan bool)
// 다른 고루틴에서 일정 시간 후에 done 채널에 신호를 보내는 예제
go func() {
time.Sleep(2 * time.Second)
done <- true
}()
fmt.Println("Waiting for the signal...")
// 채널에서 신호를 기다리며, 해당 신호를 변수에 저장하지 않고 그냥 버림
<-done
fmt.Println("Received the signal!")
}
// Waiting for the signal...
// Received the signal!이 코드에서는 done 채널을 통해 고루틴 간의 동기화가 이루어집니다. 고루틴은 2초 후에 done 채널에 true 값을 보내며, 메인 고루틴은 <-done을 통해 이 신호를 기다립니다. 신호가 도착하면 메인 고루틴은 계속해서 실행을 재개하고, "Received the signal!"을 출력합니다. 이 예제는 채널에서 값이 도착할 때까지 대기하되, 실제로 도착한 값을 사용하지 않는 패턴을 보여줍니다.
Mutex
package main
import (
"fmt"
"sync"
)
var i int = 0
var wg sync.WaitGroup
var mut sync.Mutex // 뮤텍스 변수 선언
func inc() {
mut.Lock() // 뮤텍스로 변수 i의 접근을 잠금. 한번에 하나의 go routine만 접근 가능
i = i + 1
mut.Unlock() // 잠금 해제
wg.Done()
}
func main() {
wg.Add(2)
go inc()
go inc()
wg.Wait()
fmt.Println(i) // 예상 결과는 항상 2가 출력
}sync.Once
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
var on sync.Once
func setup() {
fmt.Println("Init")
}
func dostuff() {
on.Do(setup) // 'dostuff' 함수에서 setup 함수가
fmt.Println("hello")
wg.Done()
}
func main() {
wg.Add(2)
go dostuff()
go dostuff()
wg.Wait()
}
// Init
// hello
// hellosync.Once 타입의 on 인스턴스를 사용하여 setup 함수를 Do 메소드로 감싸는데, 이 구조는 setup 함수가 프로그램 실행 도중 딱 한 번만 호출되도록 보장합니다. 여러 Goroutine에서 on.Do(setup)을 호출하더라도, 실제로 setup 함수가 실행되는 것은 처음 on.Do(setup)이 호출된 때뿐입니다. 이후의 호출에서는 setup 함수가 실행되지 않고 바로 넘어갑니다. 따라서, 출력에서 "Init"은 처음 setup 함수가 실행될 때만 나타나고, 그 이후에는 나타나지 않습니다.
Deadlock
// deadlock example
package main
import (
"sync"
)
var wg sync.WaitGroup
func dostuff(c1 chan int, c2 chan int) {
<-c1
c2 <- 1
wg.Done()
}
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
wg.Add(2)
go dostuff(ch1, ch2)
go dostuff(ch2, ch1)
wg.Wait()
}
// 결과 : fatal error: all goroutines are asleep - deadlock!이 코드 예제에서 <-c1 표현은 Go 언어의 채널(channel)에서 값을 받아오는 연산입니다. 채널은 Go에서 고루틴 간에 데이터를 주고받기 위해 사용하는 통신 메커니즘입니다. <-c1 은 채널 c1에서 값을 하나 받을 때까지 기다리라는 의미이며, 채널에 값이 들어올 때까지 해당 고루틴의 실행이 블로킹(정지)됩니다.
위의 코드에서는 dostuff 함수가 두 채널 c1과 c2를 매개변수로 받아, 첫 번째 채널 c1에서 값을 기다리고(<-c1), 값을 받은 후 두 번째 채널 c2에 값을 보내는(c2 <- 1) 로직을 포함하고 있습니다. 이 함수는 main 함수에서 두 고루틴에 의해 동시에 호출되며, 각 고루틴은 서로 다른 순서로 채널을 매개변수로 받습니다.
처음 상태에서는 ch1과 ch2 모두 비어 있기 때문에 각 고루틴은 상대방이 값을 보내기를 기다리게 됩니다. 그러나 각각의 고루틴은 자신의 첫 번째 채널에서 값을 기다리는 상태이므로, 어느 쪽도 다음 단계로 진행하여 c2 <- 1을 실행할 수 없습니다. 이렇게 서로가 서로의 다음 행동을 기다리게 되므로 데드락이 발생하고, 아무 것도 진행할 수 없게 됩니다.
따라서, 문제의 핵심은 두 고루틴이 각각의 시작 지점에서 상대방의 채널에 값이 입력되기를 기다리는데, 이 값이 결코 입력되지 않기 때문에 발생하는 데드락입니다.
Dining Philosophers
이 문제는 다이닝 철학자(Dining Philosophers) 문제라고 불리는 유명한 동시성 문제입니다. 원래 이 문제는 5명의 철학자가 원형 테이블에 앉아 있고, 각 철학자 사이에 하나씩 젓가락이 놓여 있어 총 5개의 젓가락이 있는 설정입니다. 철학자들은 생각하고, 배가 고프면 음식을 먹으려 합니다. 그러나 음식을 먹기 위해서는 자신의 왼쪽과 오른쪽에 있는 두 개의 젓가락이 필요합니다.
철학자들의 저녁 식사 문제에서는 다음과 같은 상황이 발생할 수 있습니다:
모든 철학자가 동시에 왼쪽 젓가락을 집어들면, 오른쪽 젓가락을 집기 위해 서로를 기다려야 합니다. 이 경우 모든 철학자가 자신의 오른쪽 젓가락을 기다리는 상태가 되며, 이것이 데드락의 상태입니다.
이 문제를 해결하기 위한 방법 중 하나는 철학자들이 젓가락을 집는 순서를 조정하는 것입니다. 예를 들어, 모든 철학자가 먼저 왼쪽 젓가락을 집고, 다음에 오른쪽 젓가락을 집도록 하거나, 마지막 철학자만 순서를 바꿔 먼저 오른쪽 젓가락을 집고 왼쪽 젓가락을 집도록 할 수 있습니다.
이 문제는 동시성 제어, 자원 할당, 동기화 메커니즘의 복잡성을 이해하고 설계하는 데 중요한 교훈을 제공합니다. 철학자들의 저녁 식사 문제는 컴퓨터 과학에서 동시에 여러 작업을 처리하는 시스템을 설계할 때 발생할 수 있는 데드락과 교착 상태를 피하는 방법을 연구하는 데 자주 사용되는 사례입니다.
package main
import (
"fmt"
"sync"
)
type ChopS struct {
sync.Mutex
}
type Philo struct {
leftCS, rightCS *ChopS
}
func (p Philo) eat() {
for {
p.leftCS.Lock()
p.rightCS.Lock()
fmt.Println("eating")
p.rightCS.Unlock()
p.leftCS.Unlock()
}
}
func main() {
CSticks := make([]*ChopS, 5)
for i := 0; i < 5; i++ {
CSticks[i] = new(ChopS)
}
philos := make([]*Philo, 5)
for i := 0; i < 5; i++ {
philos[i] = &Philo{leftCS: CSticks[i], rightCS: CSticks[(i+1)%5]}
}
for _, philo := range philos {
go philo.eat()
}
// 주의: 이 코드는 고루틴이 영원히 실행되므로 프로그램이 종료되지 않습니다.
// 실제 사용 시에는 고루틴을 적절히 종료할 수 있는 로직을 추가해야 합니다.
}
제공된 Go 코드는 유명한 "철학자들의 저녁 식사" 문제를 해결하기 위한 모델입니다. 이 코드는 철학자들이 식사를 하고자 할 때 발생할 수 있는 데드락을 시뮬레이션하기 위해 작성되었습니다. 각 철학자는 식사를 하기 위해 자신의 왼쪽과 오른쪽에 있는 두 개의 젓가락(ChopS)을 동시에 사용해야 합니다.
구조체 정의
-
ChopS 구조체
- sync.Mutex를 내장하여 젓가락 하나를 나타냅니다. Mutex는 고루틴 간에 상호 배제를 보장하므로, 한 철학자가 젓가락을 사용하고 있을 때 다른 철학자는 해당 젓가락을 사용할 수 없습니다.
-
Philo 구조체
- 두 개의 필드 leftCS와 rightCS를 가지며, 이는 각각 철학자의 왼쪽과 오른쪽 젓가락을 나타냅니다. 이 필드들은 *ChopS 포인터 타입으로, 각 철학자가 두 개의 젓가락에 대한 참조를 갖게 됩니다.
철학자의 행동 (eat 메서드)
- eat 메서드는 Philo 구조체의 메서드로, 철학자가 식사를 하는 행동을 나타냅니다.
- 한 루프 내에서 철학자는 먼저 왼쪽 젓가락(leftCS)을 잠그고(Lock()), 이어서 오른쪽 젓가락(rightCS)을 잠급니다.
- 두 젓가락을 모두 잠그면 "eating"을 출력하고, 식사가 끝난 후에는 오른쪽 젓가락부터 해제(Unlock())하고 그 다음 왼쪽 젓가락을 해제합니다.
main 함수
- main 함수에서는 5개의 젓가락(ChopS)과 5명의 철학자(Philo)를 생성합니다.
- 각 젓가락은 new(ChopS)를 통해 생성되며, 이는 각 젓가락이 고유의 Mutex를 갖게 합니다.
- 철학자들은 각자 자신의 왼쪽 젓가락과 오른쪽에 위치한 젓가락을 참조하도록 초기화됩니다. 예를 들어, 철학자 0은 젓가락 0(왼쪽)과 젓가락 1(오른쪽)을 사용하고, 철학자 4는 젓가락 4(왼쪽)과 젓가락 0(오른쪽)을 사용합니다 ((i+1)%5를 사용하여 인덱스를 순환).
이 구조와 동작을 통해 철학자들은 식사를 시도하고, 젓가락을 사용하기 위해 경쟁하는 과정에서 발생할 수 있는 데드락 상황을 시뮬레이션할 수 있습니다.
Select
Go 언어에서 select 구문은 다중 채널(Channels) 간의 통신을 처리할 때 사용됩니다. 이 구문은 여러 채널의 I/O 작업 중 하나가 준비될 때까지 대기하고, 준비된 작업을 실행하게 해줍니다. 이는 비동기 프로그래밍에서 매우 유용하며, 동시성 관리를 용이하게 해줍니다.
select 구문의 기능과 사용법은 다음과 같습니다:
- 다중 채널 대기: select는 여러 채널에 대한 send 및 receive 작업을 동시에 대기할 수 있습니다. 이는 어떤 채널이 준비되는지를 감지하고 해당 채널의 작업을 수행하게 해줍니다.
- 비동기적 선택: select는 동시에 여러 채널을 확인하고, 사용 가능한 채널에서 작업을 수행합니다. 만약 여러 채널이 동시에 준비된 경우, Go 런타임은 무작위로 하나를 선택해 작업을 수행합니다.
- 기본 케이스(Default case): select 구문에는 default 케이스를 포함할 수 있습니다. 이는 어떤 채널도 준비되지 않았을 때 즉시 실행됩니다. 이를 통해 프로그램이 블로킹 없이 계속 실행될 수 있도록 합니다.
예제 코드를 통해 select 구문의 사용법을 보여드리겠습니다
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string)
c2 := make(chan string)
go func() {
time.Sleep(1 * time.Second)
c1 <- "one"
}()
go func() {
time.Sleep(2 * time.Second)
c2 <- "two"
}()
for i := 0; i < 2; i++ {
select {
case msg1 := <-c1:
fmt.Println("Received", msg1)
case msg2 := <-c2:
fmt.Println("Received", msg2)
case <-time.After(3 * time.Second):
fmt.Println("timeout")
}
}
}
// Received one
// Received two
위 코드에서는 두 개의 고루틴(Goroutine)이 각각 다른 채널(c1, c2)에 값을 보내고 있습니다. 메인 함수에서는 select 구문을 사용하여 두 채널 중 어느 것이든 준비가 되면 그 값을 받아 출력합니다. 만약 3초 동안 어떤 채널에서도 값이 오지 않으면 timeout 케이스가 실행됩니다. 이런 방식으로 select는 효율적인 동시성 관리와 타임아웃 로직 구현에 매우 유용합니다.
빈 구조체 struct{}
struct{}는 빈 구조체의 타입을 나타내고, struct{}{}는 빈 구조체 타입의 새로운 인스턴스를 생성합니다. 즉, 뒤에 붙는 {}는 구조체의 인스턴스를 초기화하는 구문입니다.
- 빈 구조체 타입 선언: struct{}는 필드가 없는 구조체 타입을 정의합니다. 이 타입 자체는 단지 구조의 정의일 뿐, 실제 메모리에 할당된 구조체가 아닙니다.
- 인스턴스 생성: struct{}{}는 해당 타입의 구조체를 실제로 생성합니다. 두 번째 {}는 생성자(constructor) 역할을 하며, 필드가 없기 때문에 비어 있습니다. 이렇게 생성된 인스턴스는 실제 코드 내에서 사용될 수 있는 객체입니다.
예를 들어, 채널을 통해 이벤트를 신호할 때, 실제로 전달할 데이터가 필요하지 않고 신호의 발생 자체만 중요할 경우, 빈 구조체 인스턴스를 전송합니다:
signal := make(chan struct{})
// 고루틴에서 신호를 보낼 때
go func() {
// 무언가 작업을 수행하고
signal <- struct{}{} // 신호를 보냄, 새로운 빈 구조체 인스턴스를 채널에 전달
}()
// 신호를 기다림
<-signal
이 코드에서 signal <- struct{}{}는 새로운 빈 구조체 인스턴스를 생성하고 이를 signal 채널로 보냅니다. 이 방식은 데이터 전송 없이 동기화 이벤트만을 목적으로 합니다.
이러한 패턴은 특히 동시성을 다룰 때 Go에서 자주 사용되며, 효율적인 메모리 사용과 명확한 의도 표현이 가능합니다. 따라서, struct{}{}는 "데이터를 전송하지 않고 신호만을 전달하겠다"는 의도를 코드상에서 명시적으로 보여줍니다.
