-
멀티 레벨 피드백 큐(Multi-Level Feedback Queue, MLFQ)의 목표
- 반환 시간이 짧은 프로세스부터 실행시켜 반환 시간 최적화
- 응답 시간 최적화
-
MLFQ 기본 규칙
-
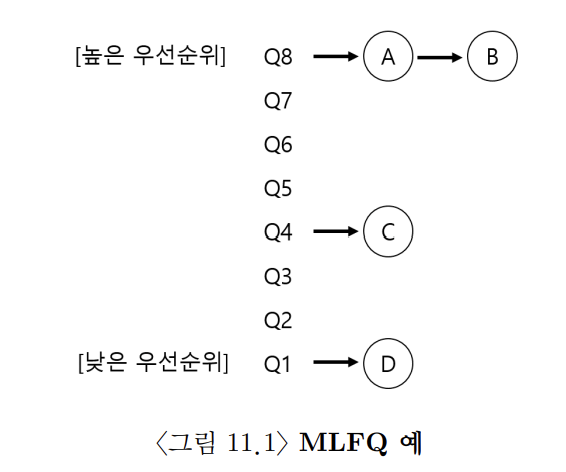
여러 개의 큐로 구성되며, 각각 다른 우선순위가 배정된다. → 각 우선순위 별로 큐가 있다.
실행 준비가 된 프로세스는 이 중 하나의 큐에 저장된다.
높은 우선순위 큐에 저장된 프로세스가 선택되어 실행된다.
-
큐에 둘 이상의 프로세스가 존재할 수 있다. → 같은 큐에 저장된 프로세스는 모두 우선순위가 같다.
같은 큐에 저장된 프로세스들에는 라운드 로빈 스케줄링 알고리즘이 사용된다.
-
프로세스가 생성되면 가장 높은 우선순위의 큐에 적재된다.
-
해당 프로세스에게 주어진 타임 슬라이스를 모두 사용하면 우선순위가 낮아진다. → 한 단계 낮은 큐로 이동한다.
-
주어진 타임 슬라이스를 전부 사용하기 전에 CPU를 해제하면 우선순위를 유지한다.
- 입출력 수행 등을 자주 수행하면 타임 슬라이스가 종료되기 전에 CPU를 반환하기 때문에 동일한 우선순위를 유지하게 한다.
- 입출력 수행 등을 위해 타임 슬라이스 종료 전에 CPU를 반환하면 운영체제는 필요한 작업을 수행하고 CPU를 반환했다고 여기고 우선순위를 유지시킨다.
- 만약 유지시키지 않고 프로세스의 우선순위를 낮춘다면 CPU를 할당받을 기회를 점점 잃게 되어 시스템 전체의 응답성이 떨어지거나 작업을 완료하지 못하는 상황이 발생한다.
-
-
MLFQ의 핵심 - 각 프로세스에 고정된 우선순위를 부여하지 않고 동적으로 우선순위를 부여한다.
예를 들어, 키보드 입력을 기다리며 반복적으로 CPU를 양보하는 프로세스가 있다면 MLFQ는 해당 프로세스의 우선순위를 높게 유지한다.
긴 시간 동안 CPU를 점유하고 있는 프로세스를 MLFQ는 우선순위를 낮게 유지한다.
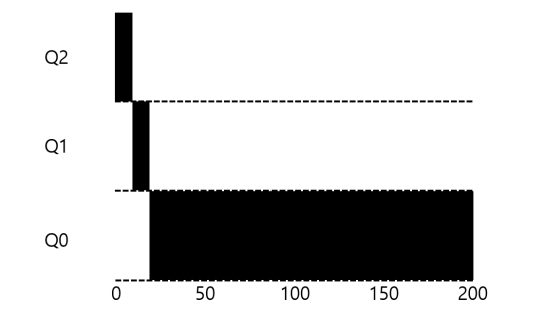
MLFQ가 SJF와 비슷한 이유
- 프로세스의 반환 시간이 얼마나 되는지 스케줄러는 모르기 때문에 우선 짧다고 가정해 높은 우선순위를 부여한다.
- 만약 진짜 짧은 반환 시간을 가졌다면 금방 종료될 것이다.
- 그렇지 않다면, 타임 슬라이스가 지날 때마다 낮은 우선순위의 큐로 이동하게 되고 이것은 긴 반환 시간을 가진 프로세스임을 증명한다.
이러한 방식이 최단 시간을 가진 프로세스부터 처리하는 SJF와 비슷하게 동작하는 이유가 된다.
현재 MLFQ의 문제점
- 기아 상태 발생 가능 - 너무 많은 대화형 프로세스가 존재하면 그것들이 모든 CPU 시간을 소모해 긴 반환 시간을 가진 프로세스는 CPU를 할당받지 못하게 된다.
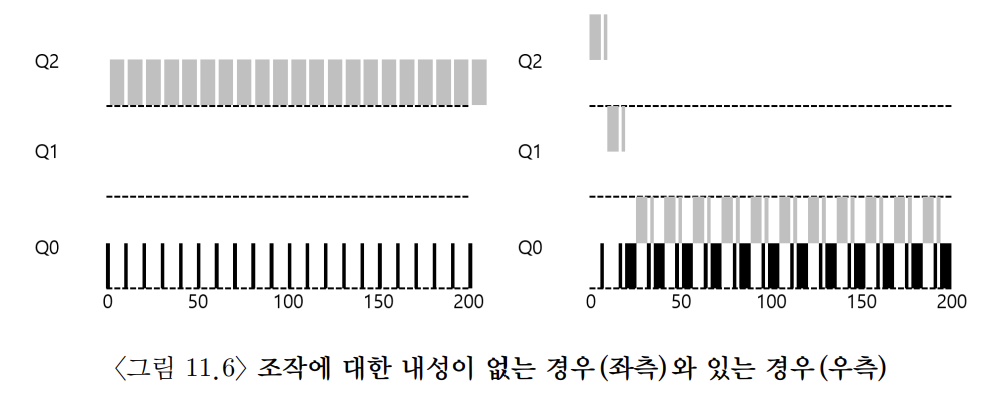
- 스케줄러가 자신에게 유리하게 동작하도록 작성된 프로세스로 인한 CPU 독점 문제 - 타임 슬라이스가 끝나기 전, 아무 파일 대상으로 입출력 등을 수행해 CPU를 반환해서 동일한 우선순위를 유지시키고 이걸 반복해 CPU를 독점할 수 있다.
- 프로세스는 시간 흐름에 따라 CPU 위주 프로세스에서 대화형 프로세스로, 그 반대로 전환된다.
문제점을 해결하기 위한 새로운 MLFQ의 규칙
- 일정 시간이 지나면, 시스템의 모든 프로세스를 최상위 우선순위 큐로 이동시킨다.
- 기아 문제 발생 문제, 프로세스 특성 전환 문제 해결 방법
- 최상위 큐에 존재하는 동안 모든 프로세스는 다른 프로세스들과 라운드 로빈 방식으로 CPU를 공유하기 때문에 기아 문제를 해결할 수 있다.
- CPU 위주의 작업에서 대화형 작업으로, 대화형 작업에서 CPU 위주의 작업으로 전환될 경우 우선순위 상향으로 스케줄러가 변경된 특성에 적합한 스케줄링을 적용시킬 수 있다.
- CPU 위주 작업으로 전환될 경우, CPU를 오랫동안 사용해야 하기 때문에 우선순위를 낮춘다.
- 대화형 작업으로 전환될 경우, 우선순위를 높여 대화가 끝나자마자 바로 CPU를 재할당 받을 수 있게 한다.
- 이 일정 시간을 정해야 하는데 이 시간을 부두 상수라고 하고 정확히 결정할 수 없기 때문에 너무 크거나 너무 작지 않게 설정해야 한다. → 너무 크면 기아를 발생시키고 너무 작으면 대화형 프로세스가 적절한 양의 CPU 시간을 사용할 수 없다.
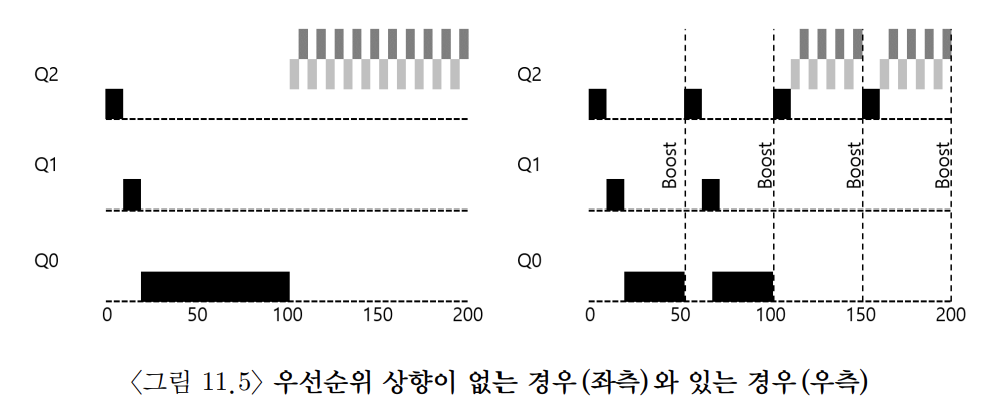
- CPU를 얼마나 양도했는지와 상관없이 타임 슬라이스를 전부 소진하면 우선순위를 낮춘다. → 아래 우선순위 큐로 이동시킨다.
- 스케줄러를 자신에게 유리하게 동작시키는 문제 해결 방법
- 해당 프로세스의 총 CPU 사용 시간을 측정해 타임 슬라이스를 모두 소진했다면 우선순위를 낮춘다. → 한 단계 낮은 우선순위 큐에 저장한다
MLFQ 사용 시 고려해야 할 점
- 몇 개의 우선순위의 큐가 존재해야 하는가?
- 큐 당 타임 슬라이스의 크기를 얼마로 정해야 하는가?
- 큐 별로 타임 슬라이스를 정할 수 있고 보통 높은 우선순위 큐일수록 타임 슬라이스가 짧다.
- 대화형 프로세스로 구성되어 있을 확률이 높고 이런 프로세스들은 빠른 전환이 의미 있기 때문
- 낮은 우선 순위 큐는 대부분 CPU 중심 프로세스들로 구성되어 있다.
- 기아를 피하고 변화된 특성을 반영하기 위해 얼마나 자주 우선순위가 상향되어야 하는가?
→ 워크로드에 대해 충분히 경험하고 조정해 나가면서 균형을 찾아야 한다…
Solaris는 프로세스의 우선순위가 어떻게 바뀌는지, 타임 슬라이스의 길이는 얼마인지, 우선순위가 얼마나 자주 상향되는지 결정하는 테이블을 제공하고 관리자가 이 테이블을 수정해 스케줄러의 동작 방식을 변경할 수 있도록 한다.
FreeBSD는 우선순위 계산을 위해 프로세스가 사용한 CPU 시간을 기초로 한 공식을 사용한다.(Lef+89) CPU 사용은 시간이 지남에 따라 감쇠되고 다른 방식으로 우선순위 상향을 제공하는데 자세한 동작 방식은 감쇠-사용(decay-usage) 알고리즘을 공부해야 한다…
일부 스케줄러는 가장 높은 우선순위를 운영체제 작업에 할당한다. 일반적인 사용자 프로세스는 시스템 내에서 가장 높은 우선순위를 받을 수 없다.
또, 일부 시스템은 사용자가 우선순위를 변경할 수 있도록 한다.
→ nice : 사용자가 프로세스의 우선순위를 조절할 수 있도록 하는 명령어
요약
- 여러 우선순위를 나타내는 멀티 레벨 큐를 가지고 있다.
- 프로세스의 우선순위를 결정하기 위해 피드백을 사용한다. → 과거의 행동이 우선순위 지정에 영향을 준다.
- MLFQ의 규칙
- 우선순위가 높은 프로세스부터 실행된다.
- 우선순위가 같다면 라운드 로빈 방식으로 프로세스를 실행시킨다.
- 프로세스가 생성되면 가장 높은 우선순위 큐에 저장된다.
- CPU를 양보한 횟수와 관계 없이 타임 슬라이스를 모두 소모한 프로세스는 우선순위가 한 단계 낮아진다.
- 일정 주기 S가 지난 후, 모든 프로세스를 최상위 우선순위의 큐에 저장한다.
- 프로세스 특성에 대한 정보 없이 실행 동작을 확인한 후 우선순위를 지정한다.
- 대화형 프로세스에 대해 우수한 평균 성능을 제공한다.(SJF/STCF와 유사)
- CPU 집중 프로세스는 공정하게 실행시키고 조금이라도 진행될 수 있도록 한다.
4BSD : 프로세스의 CPU 사용량을 주기적으로 측정해 우선순위를 계산
- CPU를 많이 사용할수록 우선순위를 낮추고 입출력 작업을 많이 하면 우선순위를 높임
nice : 프로세스의 우선순위를 조절하는 데 사용되는 명령어
- 시스템이 자동으로 우선순위를 조정하는 MLFQ에서, 프로그래머가 자동 조정에 개입하는 데 사용된다.
- 스케줄러가 계산하는 동적 우선순위에 더해져 최종 우선순위를 결정하는 데 영향을 줌.
→ 4BSD는 MLFQ의 실제 동작 방식을, nice는 MLFQ의 우선순위 결정에 프로그래머가 개입하는 방식을 이해하는 데 중요한 키워드.
