
이 글에서는 데이터베이스의 동시성 문제와 자바 스프링과 JPA를 사용하여 동시성 문제를 해결하기 위한 방법들에 대해 비교분석해보고, 실제 구현 방법에 대해 다뤄본다.
데이터 베이스 동시성 문제의 발생
데이터베이스에 동시에 여러 사용자가 접속해, 동일한 데이터를 읽거나 쓰기작업을 수행할 때 예상하지 못한 결과가 발생하는것을 말한다.
동시성 문제에는
- lost update
- dirty read
- non-repeatable read
- phantom read
- dead lock
등이 있다.
각 동시성 문제에 대해 간단하게 알아보자.
lost update - 갱신 손실
두 트랜잭션이 하나의 데이터를 수정할때 먼저 수정한 트랜잭션의 변경사항이 나중에 변경한 트랜잭션에 의해 덮어써지며 변경사항이 손실되는 문제다.
두명의 사용자가 동시에 같은 물건을 구매해, 데이터베이스에서 재고가 감소되는 상황을 가정해보자.
- 두 사용자는 주문을 처리하기 위해 데이터베이스에서 각각 트랜잭션을 열게 된다.
- 이때 상품의 재고는
10이다.
- 이때 상품의 재고는
- 두 사용자는 자신의 트랜잭션에서 상품의 재고를 감소시키게 된다.
- 이때 각 트랜잭션에서 상품의 재고는
9이다.
- 이때 각 트랜잭션에서 상품의 재고는
- 두 트랜잭션이 끝나도 상품의 재고는
9로 남아있다.
그림으로 보면 다음과 같다.
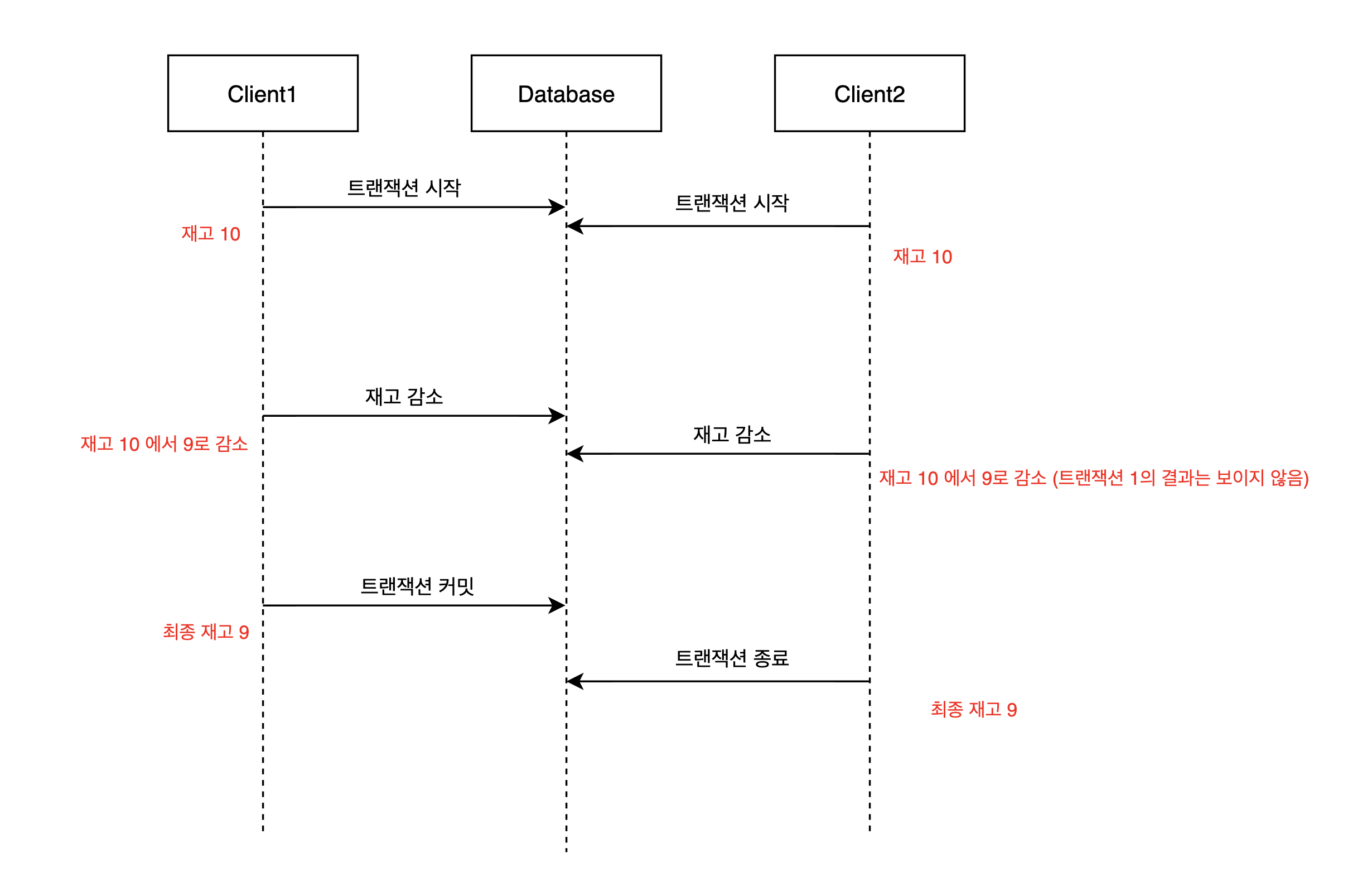
두 사용자가 각각 재고를 감소시키더라도, 결국 재고는 9가 되게 된다.
dirty read - 더티 리드
트랜잭션이 커밋되기전 트랜잭션의 변경 사항을 보게되어 데이터의 일관성이 깨지는 문제다.
만약 두 사용자가 동일한 데이터로 작업을 하고 있는데 한 사용자의 작업이 끝나기 전에 작업의 변경내역이 다른 사용자에게 보이면 어떻게 될까??
예를들어 두명의 사용자가 같은 물건을 동시에 구매할때 한 사용자가 재고를 감소시켰지만, 잔고부족등으로 트랜잭션이 롤백되는 상황을 가정해보자.
- 두 사용자는 주문을 처리하기 위해 데이터베이스에서 각각 트랜잭션을 열게 된다.
- 이때 상품의 재고는
10이다.
- 이때 상품의 재고는
- 한 사용자가 재고를 감소시킨다.
- 이때 상품의 재고는
9다.
- 이때 상품의 재고는
- 다른 사용자가 재고를 감소시킨다.
- 이떄 상품의 재고는
8이다.
- 이떄 상품의 재고는
- 먼저 감소시킨 사용자의 트랜잭션이 임의의 이류로 롤백된다.
- 이때 상품의 재고는
10이다.
- 이때 상품의 재고는
- 나중에 감소시킨 사용자의 트랜잭션이 커밋된다.
- 이떄 상품의 재고는
8이다.
- 이떄 상품의 재고는
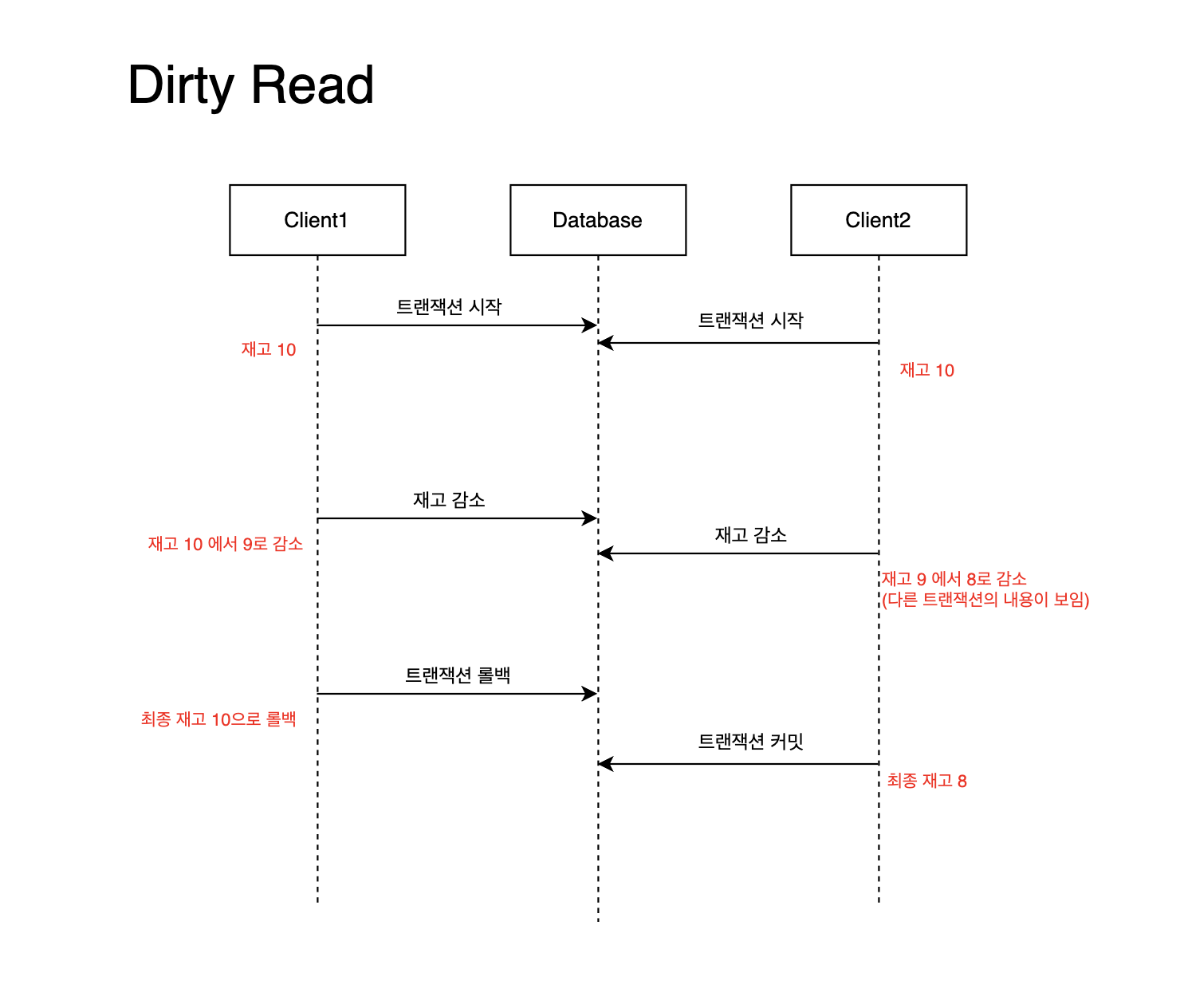
즉 구매는 한명이 했지만, 재고 감소는 2 가 이루어지게 된다.
non-repeatable read - 비반복적 읽기
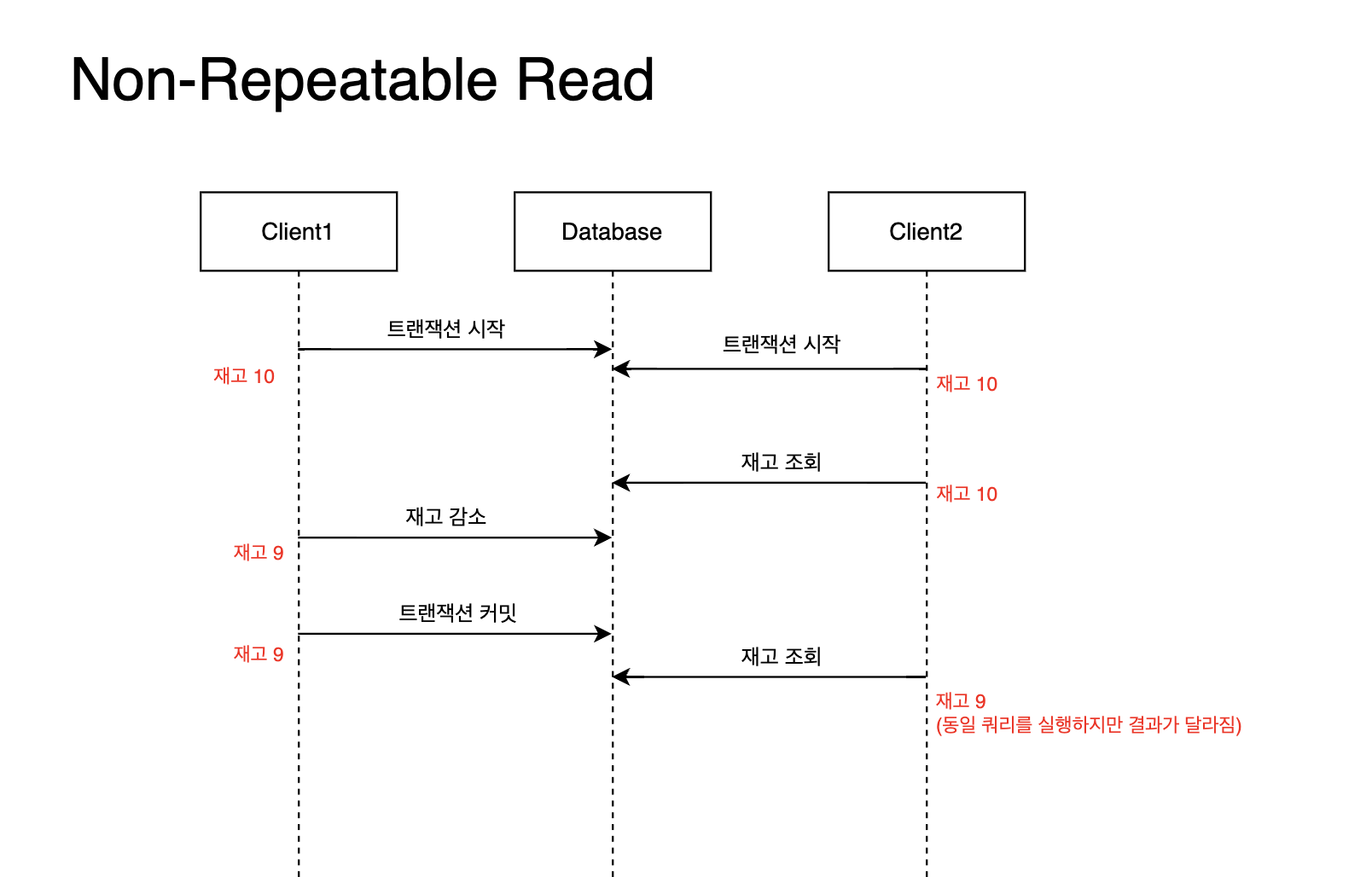
한 트랜잭션에서 동일한 데이터를 조회할때 다른 트랜잭션의 커밋 결과에 의해 값의 멱등성이 깨지는 문제다.
다른 트랜잭션이 커밋되기 전에는 변경사항을 볼 수 없지만, 다른 트랜잭션이 커밋된 이후에는 변경사항을 볼 수 있어 동일한 트랜잭션에서 멱등성이 깨지게 된다.
그림을 보면 Client2 의 트랜잭션에서 동일한 쿼리를 조회하지만, Client1 의 트랜잭션에 의해 감소된 재고가 보여 멱등성이 깨지게 된다.
phantom read - 팬텀 리드
한 트랜잭션 내에서 동일한 쿼리를 조회할때 다른 트랜잭션이 추가하거나 삭제한 행이 보였다 안보였다 하는 문제다.
non-repeatable read와 유사하지만, non-repeatable read는 한 레코드에 대한 문제고, phantom read는 여러개 레코드에 관한 문제다.
하나의 트랜잭션에서 동일 레코드의 값은 유지되지만, 레코드 자체가 추가되거나 삭제되는것에 대해서 발생하는 문제다.
동시성 문제의 해결
이러한 데이터베이스의 동시성 문제를 해결하는 방법에는 여러가지가 있다.
- 트랜잭션
- 락 (비관적 락)
- 낙관적 제어 기법 (낙관적 락)
- 외부 자원 활용 (redis)
각 기법들의 특징을 알아보자.
트랜잭션
이 글은 트랜잭션에 대한 설명이 아니기 때문에 트랜잭션의 자세한 설명을 다루진 않는다.
트랜잭션은 데이베이스에서 작업을 수행할 최소 단위로써, 작업의 원자성을 부여하는 역할을 한다.
데이터베이스에서 수행할 작업의 일관성을 유지하기 위해 트랜잭션은 ACID 라는 4가지 특성을 준수한다.
- Atomicity : 원자성, 트랜잭션내의 작업은 모두 수행되거나 모두 수행되지 않아야 한다.
- Consistency : 일관성, 트랜잭션 이후 데이터베이스는 일관성을 유지해야 한다.
- Isolation : 고립성, 각 트랜잭션은 고립적으로 수행되어야 하며 다양한 격리 수준을 제공한다.
- Durability : 지속성, 트랜잭션이 완료되면 그 결과느 영구적으로 저장되어야 한다.
사실 트랜잭션의 목적은 동시성을 제어하는것이 아닌 데이터의 일관성과 무결성을 유지하는것이다. 그리고 그 과정에서 트랜잭션간 동시성 문제가 발생하는것을 막기위해 격리 레벨을 통해 트랜잭션을 제어하는 것이다.
트랜잭션 격리 레벨로 데이터베이스에서 발생하는 동시성 문제의 일부를 해결할 수 있어 잠시 짚고 넘어간다.
READ_COMMITED 격리레벨은 커밋된 내용만 볼 수 있게 하는 격리레벨로, dirty read 문제를 해결해준다.
REPEATABLE_READ 격리레벨은 한 트랜잭션에서 동일 상태의 동일쿼리에 대한 멱등성을 보장해줘 non-repeatable read 문제를 해결해준다.
SERIALIZABLE 격리레벨은 모든 트랜잭션을 직렬화해 모든 읽기 쓰기에 락을 걸어버린다. 이 레벨에서는 모든 동시성 문제가 해결된다는 장점이 있지만, 데이터베이스에 한번에 하나의 트랜잭션만 작업을 수행할 수 있기 때문에 성능에 아주 큰 영향을 주게 된다.
락 (비관적 락)
이 글에선 주로
lost update를 해결하기 위한 관점에서 락을 설명한다.
락은 데이터베이스의 동시성 문제를 해결하기 위한 방법이다.
자원에 접근할때 트랜잭션이 락을 얻고, 락을 얻지 못한 트랜잭션은 대기하게 된다.
공유락과 배타락
데이터베이스의 락에는 공유락과 배타락이 존재한다.
공유락(읽기락) 은 락을 걸면, 다른 트랜잭션의 공유락은 허용하지만 배타락은 허용하지 않는다.
이는 트랜잭션이 일관성 있는 읽기를 보장하기 위해 사용한다.
배타락(쓰기락) 은 락을 걸면, 다른 트랜잭션의 공유락, 배타락을 모두 허용하지 않는다.
만약 쓰기락이 걸린 데이터를 다른 트랜잭션이 변경하려 시도하게 되면 락을 얻을때까지 대기를 하다 락을 얻어 변경을 하거나 너무 오래동안 락을 얻지 못하면 타임아웃으로 트랜잭션이 실패하게 된다.
참고로 락을 걸었지만, 락을 사용하지 않는 요청 (일반 select) 의 경우 데이터 조회가 가능하다.
비관적 락
일반적으로 데이터베이스에 배타락을 건다는것은 비관적 락을 의미한다.
데이터의 경합이 많이 발생할것이라는 비관적 관점에서 데이터 변경 전에 락을 걸기 때문에 비관적 락 이라는 이름으로 불린다.
데이터 변경에 배타락을 사용하게 된다면 가장 먼저 락을 얻은 트랜잭션이 작업을 수행하는 동안 다른 트랜잭션을 락을 얻기위해 대기하게 된다.
그리고 락을 얻었던 트랜잭션이 작업을 마무리하면 대기하던 다음 트랜잭션이 락을 얻어 작업을 수행하게 된다.
즉 하나의 데이터에 하나의 트랜잭션만 접근 가능하기 때문에 lost update 문제를 해결해주게 된다.
장단점
비관적 락 은 무결성을 강력하게 보장할 수 있기 때문에 동시에 변경이 많거나 재고, 잔고와 같은 크리티컬한 데이터에서 사용하게 된다.
하지만 이런 방식은 자원에 대한 동시성 문제를 해결할 수 있지만, 다른 트랜잭션의 읽기 쓰기에 대한 락을 걸어버리기 때문에 성능 저하를 불러올 수 있다. (다시 한번 언급하지만, 락을 사용하지 않는 일반 select는 락이 없어도 읽기가 가능하다. 여기서 말한 읽기는 공유락을 말한다)
낙관적 해결 방법 (낙관적 락)
낙관적 해결 방법(이하 낙관적락) 은 위의 비관적 락과 다르게 데이터에 락을 걸지 않는다.
데이터의 경합이 발생하지 않을 것이라는 낙관적 관점에서 사용하는 방법이기 때문에 낙관적 락이라는 이름으로 불린다.
매커니즘
낙관적락의 매커니즘은 우선 데이터 변경을 하게해두고 충돌이 발생하면 그때 처리하자 를 기본 골조로 삼는다.
비관적 락의 경우 데이터를 변경하기 전에 락을 거는 반면, 낙관적락은 데이터를 변경할때 락을 걸지 않는것이 가장 큰 차이다.
하지만 락을 걸지 않기 때문에 언제든 데이터의 충돌이 발생할 수 있다.
이때 충돌이 발생했다면, 변경된 데이터를 반영하지 않는 방법으로 충돌을 해결할 수 있다.
충돌 처리
낙관적 락의 경우 컬럼에 버전 컬럼을 만들어 레코드의 리비전을 관리한다.
충돌이 나타나는 상황은 아래와 같다.
- 레코드의 리비전은 1이다.
- 트랜잭션 A가 업데이트를 위해 레코드의 값을 가져온다. (리비전 1)
- 트랜잭션 B가 업데이트를 위해 레코드의 값을 가져온다. (리비전 1)
- 트랜잭션 A가 업데이트를 위해 리비전을 확인하고 레코드의 리비전과 자신의 리비전이 같으니 업데이트된 데이터를 반영하고 리비전을 2로 올린다. (리비전 2)
- 트랜잭션 B가 업데이트를 위해 리비전을 확인할때 자신의 리비전과 현재 레코드의 리비전이 다르기 때문에 충돌이 발생한다.
- 트랜잭션 B는 충돌이 발생했기 때문에 업데이트 내용을 반영하지 않고 롤백을 하게 된다.
즉 충돌이 발생하면 데이터베이스에서 이를 처리하고 해결하는것이 아닌, 데이터베이스에서는 롤백만 하게 된다.
그리고 충돌에 대한 처리는 애플리케이션 계층에서 하는것이 대부분이다.
보통 이런 충돌이 발생한다면, 애플리케이션에서 다시 데이터를 가져와 다시 업데이트를 진행하고 값을 반영한다.
위의 과정과 이어서 설명해 보자면,
- 트랜잭션 B는 충돌이 발생했기 때문에 업데이트 내용을 반영하지 않고 롤백을 하게 된다.
- 트랜잭션 B를 수행한 클라이언트가 재시도를 위해 트랜잭션C를 수행한다.
- 트랜잭션 C가 업데이트를 위해 레코드의 값을 가져온다. (리비전 2)
- 트랜잭션 C가 업데이트를 위해 리비전을 확인하고 레코드의 리비전과 자신의 리비전이 같으니 업데이트된 데이터를 반영하고 리비전을 3으로 올린다. (리비전 3)
와 같은 과정으로 수행된다.
또 마찬가지로, 리비전의 충돌이 발생한다면 또다시 롤백 이후, 재시도가 반복된다.
장단점
낙관적 락은 데이터를 변경할때 락을 걸지 않기 때문에 여러 트랜잭션을 동시에 처리할때 효율이 좋다.
하지만 충돌이 발생할때는 롤백 이후 재시도라는 비교적 큰 비용으로 문제를 해결하게 된다.
이로인해 충돌이 많이 발생하는 데이터에서 낙관적락을 사용하게 된다면 오히려 성능 저하가 발생하게 된다.
또한 롤백 이후 재시도 처리를 애플리케이션 레벨에서 해줘야 하기 때문에 추가 비용이 들어가게 된다.
외부 자원의 활용
데이터베이스의 동시성 문제를 해결하기 위해서 데이터베이스 외의 다른 자원을 활용할 수 있다.
여기선 synchronized와, redis를 사용한 방법에 대해 설명한다.
synchronized
가장 간단한 예시로, 자바의 synchronized 를 예로들 수 있다.
동시성 문제가 발생할 수 있는 메서드에 synchronized 를 사용해 한번에 하나의 요청만 수행할 수 있게 한다면 락과 동일한 효과를 볼 수 있다.
하지만, 여러 메서드에서 하나의 데이터를 수정할때 (예를들어 주문 서비스에서도 상품 재고변경이 일어날 수 있고, 상품 서비스에서도 재고 변경이 일어날 수 있다) synchronized 모니터 관리가 복잡해진다는 점과, 수평 확장을 위해 was를 복제해 사용한다면 synchronized가 사실상 무용지물이 되기 때문에 데이터베이스의 동시성 문제 해결 방법으로는 적절하지 않다.
redis
Redis는 싱글 스레드로 동작하는 특징 때문에 다량의 요청이 동시에 들어오더라도 동시에 하나의 요청만 처리해 동시성 문제가 발생하지 않는다.
이러한 특징을 활용해 레디스에 key-value를 설정하고 이 값을 마치 락 처럼 이용할 수 있다.
분산 시스템에서 공유 자원에 대한 접근을 제어하는 매커니즘을 분산락 이라 한다. 그리고 레디스는 싱글 스레드로 분산락을 사용하기에 적합한 환경을 가지고 있다.
spring application으로 여러개의 요청이 동시에 들어온다면, 우선 레디스에 접근해 락을 얻는 과정을 거친다.
이때 락을 얻은 스레드(요청)은 작업을 수행하고 락을 얻지 못한 스레드(요청) 은 락을 얻기 위해 대기한다.
이때 락을 얻기 위해 대기하는 방법에도 스핀락, pub/sub 방식등이 있다.
redis 분산락의 장단점
Redis 분산락을 사용하게 되면 데이터베이스에 락을 걸지 않고도 간편하게 경합상태를 방지해줄 수 있다.
하지만 레디스를 거쳐가기 때문에 발생하는 성능저하, 그리고 레디스가 SPOF가 될 수 있다는 단점또한 존재한다.
(레디스가 SPOF가 되는것을 방지하기 위한 락킹 매커니즘인 RedLock과 같은 매커니즘도 있다.)
구현
스프링부트 - JPA 환경에서 동시성 문제를 야기하는 코드에 대해 알아보고, 위에서 설명한 이를 해결하기 위한 방법들을 설명한다.
동시성 문제 발생 코드
JPA의 특성상 동시성 문제는 쉽게 발생할 수 있다.
사실 데이터를 변경하는 모든 코드에서 동시성 문제가 발생할 수 있다.
다음 코드는 쿠폰을 발급하기 위한 코드로, 쿠폰은 제한된 수량만큼만 발급해야 한다는 조건이 있다.
Coupon.java
public UserCoupon issueCoupon(User user) {
...
if (remainingQuantity <= 0) {
// 예외 발생
}
// 쿠폰 발급
remainingQuantity--;
return UserCoupon
.builder()
.user(user)
.coupon(this)
.build();
}CouponService.java
@Transactional
public Long issueCoupon(String couponId, Long userId) {
Coupon coupon = getCoupon(couponId);
User user = userRepository.getReferenceById(userId);
UserCoupon userCoupon = coupon.issueCoupon(user);
userCouponRepository.save(userCoupon);
return userCoupon.getId();
}남은 수량이 0이라면, 더이상 쿠폰을 발급하지 않고 예외를 발생시키기 때문에 문제가 없을것 같지만 동시성 문제가 발생하게 된다.
예를들어 쿠폰의 수량이 하나 남은 상황에서, 두개의 쿠폰의 발급 요청이 들어오게 되면 각 요청(스레드)의 영속성 컨텍스트에 수량이 하나남은 쿠폰정보가 저장되게 된다.
이 상황에서 각 요청(스레드)에서 위 로직은 문제없이 통과되게 된다. 그리고 두개의 쿠폰이 정상적으로 발급되게 된다.
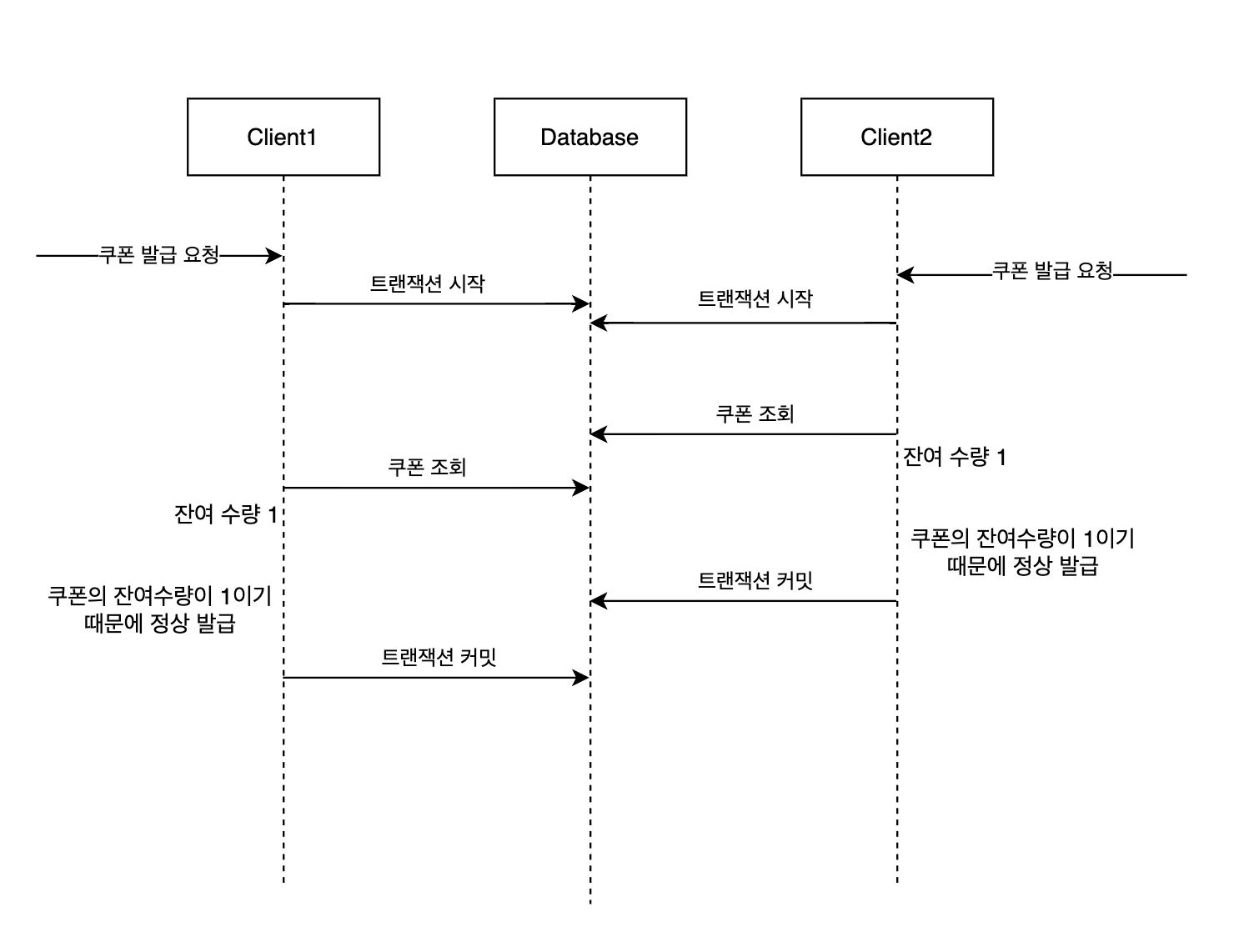
즉 변경사항이 반영이 되지 않는 lost update 문제가 발생하게 된다.
실제 테스트코드를 작성해 확인해보자.
쿠폰의 수량을 10으로 설정하고, 100개의 요청을 동시에 보내는 예제다.
CouponServiceTest.java
@Test
public void test() throws InterruptedException {
// given
Coupon coupon = FixedDiscountCoupon
.builder()
.name("쿠폰")
.discountPrice(100L)
.totalQuantity(10)
.remainingQuantity(10)
.build();
User user = User
.builder()
.build();
couponRepository.save(coupon);
userRepository.save(user);
AtomicInteger counter = new AtomicInteger(0);
// when
ExecutorService executors = Executors.newFixedThreadPool(100);
for (int i = 0; i < 100; i++) {
executors.submit(() -> {
couponService.issueCoupon(coupon.getId(), user.getId());
counter.getAndIncrement();
});
}
// then
executors.shutdown();
executors.awaitTermination(1, TimeUnit.MINUTES);
assertThat(counter.get()).isEqualTo(10);
}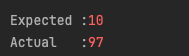
결과를 확인해보면 훨씬 상회하는 숫자인 97개가 발급되는것을 확인할 수 있다.
이제 이 문제를 해결하기 위해 위헤서 설명한 방법들을 적용해보자.
synchronized
쿠폰 발급 메서드에 synchronized를 사용함으로써, 동시에 하나의 유저만 쿠폰을 발급할 수 있게 한다.
CouponService 를 synchronized 하게 실행하기 위한 Wrapper 클래스를 하나 만든다.
CouponServiceWrapper.java
@Service
@RequiredArgsConstructor
public class CouponServiceWrapper {
private final CouponService couponService;
synchronized public void issueCoupon(String couponId, Long userId) {
couponService.issueCoupon(couponId, userId);
}
}CouponService 에 synchronized를 바로 쓸 수 없는 이유는 @Transactional 의 동작과 관련이 있다. (프록시)
트랜잭션 격리 레벨 - Serializable
트랜잭션 격리 레벨을 Serializable 로 설정한다면, 한번에 하나의 트랜잭션만 수행되기 때문에 동시성 문제를 해결할 수 있다.
SERIALIZABLE 모드로 설정하기 위해선 @Transactional 어노테이션에 설정을 추가하면 된다.
기본은 데이터베이스의 격리 레벨로 동작한다.
CouponService.java
@Transactional(isolation = Isolation.SERIALIZABLE)
public Long issueCoupon(String couponId, Long userId) {
Coupon coupon = getCoupon(couponId);
User user = userRepository.getReferenceById(userId);
UserCoupon userCoupon = coupon.issueCoupon(user);
userCouponRepository.save(userCoupon);
return userCoupon.getId();
}비관적락
쿠폰을 발급받을때 비관적락을 설정함으로써 다른 트랜잭션이 쿠폰 레코드에 접근하는것을 방지할 수 있다.
트랜잭션 내에서 select 로 데이터를 조회할때 for update 를 사용한다면 락(비관적 락)을 걸 수 있다.
스프링 데이터 JPA에서는 @Lock 어노테이션으로 편하게 락을 사용할 수 있다.
CouponRepository.java
public interface CouponRepository extends JpaRepository<Coupon, String> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
public Optional<Coupon> findById(String couponId);
}sql 로그를 확인하면 for update 가 붙어서 나가는것을 알 수 있다.

낙관적락
비관적락과 마찬가지로, @Lock 어노테이션으로 낙관적락을 편하게 사용할 수 있다.
다만 낙관적락은 리비전을 위한 컬럼이 필요하기 때문에 엔티티에 필드를 추가해줘야 한다.
CouponRepository.java
public interface CouponRepository extends JpaRepository<Coupon, String> {
@Lock(LockModeType.OPTIMISTIC)
public Optional<Coupon> findById(String couponId);
}Coupon.java
// 아래 필드 추가
@Version
private Long version;로그를 확인하면 낙관적락의 리비전 체크에서 발생한 충돌을 확인할 수 있다.

또한 쿠폰 발급 비즈니스 로직에서는 재시도의 필요가 없기 때문에 재시도를 하지 않았지만 재시도가 필요하다면 spring-retry 의존을 추가해볼 수 있다.
Redis 분산락
여기선 redisson의 설정에 대해선 다루진 않는다.
Redis의 분산락을 사용해, 한번에 하나의 요청만 데이터베이스에 접근하도록 한다.
CouponService.java
@Transactional
public Long issueCoupon(String couponId, Long userId) {
RLock lock = redissonClient.getLock("coupon");
try {
lock.tryLock(1, TimeUnit.MINUTES);
Coupon coupon = getCoupon(couponId);
User user = userRepository.getReferenceById(userId);
UserCoupon userCoupon = coupon.issueCoupon(user);
userCouponRepository.save(userCoupon);
return userCoupon.getId();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}redissonClient 락을 얻고, 락을 반환하는 로직을 비즈니스 로직 앞뒤에 추가해준다.
이렇게되면 비즈니스 로직을 수행하기 위해 Redis에 락을 요청하게되고 Redis는 싱글스레드로 동작하며 한번에 하나의 요청(스레드) 만 락을 가질 수 있도록 한다.
정리
데이터베이스에서 동시에 많은 사용자가 동일한 데이터를 조작하게 된다면 동시성 문제가 발생할 수 있다.
동시성 문제를 해결하기 위한 다양한 방법들에 대해 알아보았다.
각 방법들의 특징을 정리하면 다음과 같다.
트랜잭션
- 트랜잭션의 목적은 동시성 문제해결을 위한것이 아닌 데이터의 일관성과 무결성 유지다.
- 트랜잭션의 격리 레벨을 설정하면 동시성 문제를 해결할 수 있다.
SERIALIZABLE로 설정하게 되면 모든 동시성 문제가 해결되지만 동시에 하나의 트랜잭션만 수행되기 때문에 성능이 매우 낮아지게 된다.
락(비관적 락)
- 데이터베이스에 락을 걸음으로써 동시에 하나의 트랜잭션만 데이터를 처리할 수 있도록 하는 매커니즘이다.
- 데이터 경합이 발생할것이라 예측하고 데이터 변경 전에 미리 락을 거는 비관적 락 방법이 있다.
- 비관적락의 경우 동시성 문제를 깔끔하게 해결할 수 있지만, 다른 트랜잭션의 읽기 쓰기를 모두 막기 때문에 성능 저하가 발생할 수 있다.
- 하지만 데이터 경합 발생확률이 높거나, 비즈니스적으로 중요한 데이터라면 비관적락을 사용해 동시성 문제를 해결할 수 있다.
- 락 경합과정에서 데드락이 발생할 수 있는 문제가 있다.
낙관적 해결 방법(낙관적 락)
- 데이터에 경합이 발생하지 않을것을 예상하고 락을 걸지 않고 충돌이 발생할때 조치를 취하는 매커니즘이다.
- 비관적락에 비해 락을 걸지 않기 때문에 성능상에서 이점이 있다.
- 하지만 충돌이 발생할 경우 롤백과 재시도등 비관적락보다 높은 비용이 요구되기 때문에 데이터의 특징을 잘 보고 사용을 해야한다.
- 재시도의 경우 데이터베이스에서 처리되는것이 아닌 애플리케이션 레벨에서 처리되는것이기 때문에 개발자가 직접 처리해줘야 한다.
- 비교적 경합 발생 확률이 낮은 데이터에 사용한다면 성능면에서 최적화를 할 수 있다.
- 락 경합이 없기 때문에 데드락이 발생하지 않는다.
redis 분산락
- 싱글 스레드인 Redis를 사용해 락을 제어함으로써 여러 요청을의 동시성을 제어하는 매커니즘이다.
- 싱글스레드인 레디스를 사용하기 때문에 데드락의 걱정 없이 데이터베이스의 경쟁 상태를 방지할 수 있다.
- 레디스에 키-값으로 락을 저장해 락을 획득할때 값을 올리고 락을 반납할때 값을 내리는 방법으로 구현한다.
- 락을 얻기위해 대기하는 방법에는 스핀락과, pub/sub 방식이 있다.
- 레디스가 SPOF로 작용할 수 있기 때문에 이에대한 조치가 필요하다. (RedLock 등)
- 외부 자원인 레디스를 거치기 때문에 발생하는 오버헤드가 있다.
