1. Prometheus
Prometheus는 시계열 모니터링 및 경고 오픈소스다. 모니터링에 특화되어 있으며, 강력한 쿼리언어(PromQL)를 통해 질의가 가능하다.
1.1 Prometheus의 데이터 표현
Prometheus는 metric과 label 이라는 값으로 시계열 데이터를 구분한다.
Metric은 시계열을 저장하는 기본 단위이며, 측정되는 값을 의미한다.
ex) http_requests_total : http 요청수
Label은 메트릭에 추가 정보를 위해 사용된다. 메트릭의 값들을 세분화해 다양한 차원으로 표현한다.
ex) http_request_total{status=="200"} : http요청중 status 가 200인 요청의 수
1.2 메트릭 타입
prometheus는 네가지의 메트릭을 제공한다.
- Counter : 단조증가 하는 데이터를 표현하기 위한 타입
- Guage : 변화가 있는 데이터를 표현하기 위한 타입
- Histogram : 값의 분포를 표현하기 위한 타입
- Summary : 값의 통계를 표현하기 위한 타입
1.3 데이터 타입
prometheus에서 다루는 데이터 타입은 총 4가지가 있다.
- Instant Vector : 특정 타임스탬프에서의 메트릭 데이터를 나타냄.
- Range Vector : 특정 시간 범위 내의 메트릭 데이터를 나타냄.
- Scalar : 단일 값을 의미한다.
- String : 현재는 사용되지 않으며, 문자열 값이다.
예를 들어보면 다음과 같다.
1.3.1 Instant Vector
node_cpu_seconds_total{mode="idle"}
단 하나의 타임스탬프에서 node_cpu_seconds_total 이라는 메트릭에서 mode 라벨값이 idle인 값만 추출한다.
위 예제에서는 6개의 Scalar값이 샘플링 되었으며, 저 6개의 값을 묶어 Instant Vector라 한다.
1.3.1 Range Vector
node_cpu_seconds_total{mode="idle"}[1m]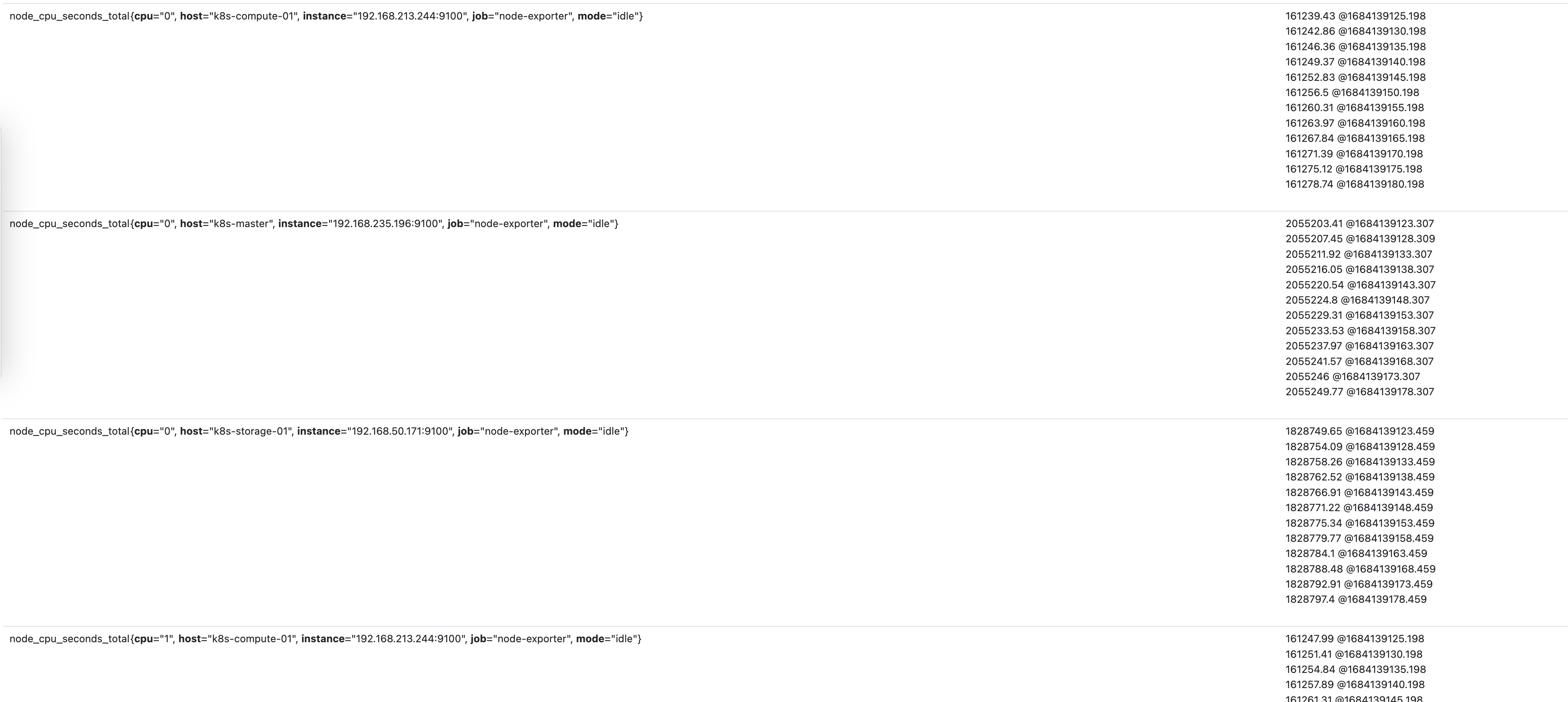
동일한 메트릭에서 1분동안의 데이터를 추출하고, 그결과중 일부다.
Range Vector는 특정 구간에서 샘플링된 모든 데이터를 의미한다.
PromQL을 통해 질의, 연산을 하기 위해선 해당 연산의 결과가 Instant Vector인지, Range Vector인지, Scalar 값인지 잘 인지하고 있어야 한다.
2. PromQL
PromQL은 Prometheus에 저장된 시계열 데이터를 질의하기 위한 쿼리 언어로써, 다양한 연산들을 지원해준다.
2.1 select query
위에서 설명한 가장 기초적인 쿼리로써 메트릭, 라벨을 통해 Vector를 반환한다.
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
2.2 operator
스칼라끼리, 혹은 스칼라와 인스턴트 벡터, 혹은 인스턴트 벡터끼리 연산을 수행할 수 있다.
3 * 3
node_cpu_seconds_total{mode="idle"} * 10
node_cpu_seconds_total{mode="idle"} + node_cpu_seconds_total{mode="idle"}
node_memory_Buffers_bytes + node_memory_Cached_bytes
인스턴트 벡터의 연산을 위해서는 두 인스턴트 벡터의 메트릭, 라벨이 동일해야 한다.
예를들어 다음과 같은 연산은 불가능하다.
node_cpu_seconds_total{mode="idle"} + node_cpu_seconds_total{mode="user"}메트릭은 같지만, 라벨이 달라 연산이 불가능하다.
2.3 집계함수
인스턴스 벡터를 집계하고 요약하기위해 사용할 수 있다. sum, avg와 같은 함수들로 메트릭을 그룹핑해 집계할 수 있다.
예를들어 위에서 설명한 node_cpu_seconds_total{mode="idle"} 의 결과는 다음과 같다.

집계함수를 통해 해당 값들을 모두 더하거나, 그룹핑해 그룹별로 더할 수 있다.
2.3.1 인스턴트 벡터의 모든 값을 더함.
sum(node_cpu_seconds_total{mode="idle"})
인스턴트 벡터의 모든 값을 더해 하나의 벡터가 결과로 나온다.
2.3.2 인스턴트 벡터를 instance별로 그룹핑해, 합계를 구함.
sum(node_cpu_seconds_total{mode="idle"}) by (instance)
by 절을 활용해 instance별로 집계를 낼 수 있다.
또는, without절을 사용하여, 특정 태그를 제외해 집계를 낼 수 있다.
sum(node_cpu_seconds_total) without (mode)
2.4 구간 함수
Instant Vector가 아닌 Range Vector로 계산을 때리는 함수다.
2.4.1 rate, irate 함수
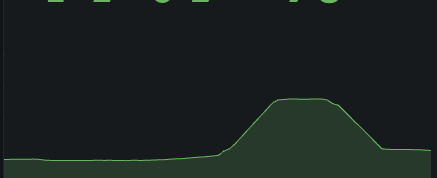
rate와 irate 함수는 증가율을 계산하는 함수다.
rate와 irate의 다른점은
- rate는 구간 평균 증가율을 계산한다. (구간 데이터들의 평균 변화율)
- irate는 순간 증가율을 계산한다. (현재데이터와 직전데이터의 변화율)
때문에 rate는 좀 더 완만한 변화를 그리게 되고, irate는 즉각적인 변화를 보이게 된다.
rate
irate
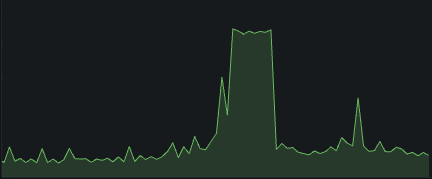
각 함수는 필요에 맞게 사용하면 된다.
2.4.1 aggregate_over_time
시계열 분석에 당연히 필요한 구간 집계 함수들이다.
일정 시간동안의 합이나 평균, 표준편차들을 구할 수 있고 (2.3) 에서 설명한 대부분의 함수의 구간 집계 버전이라 생각하면 된다.
많이 사용하는 예시중 하나로 볼린저 밴드가 있다.
m일동안의 평균과 n일 동안의 표준편차로 구할 수 있다.
avg_over_time(price{symbol="symbol"}[m]) + 2 * stddev_over_time(price{symbol="symbol"}[n])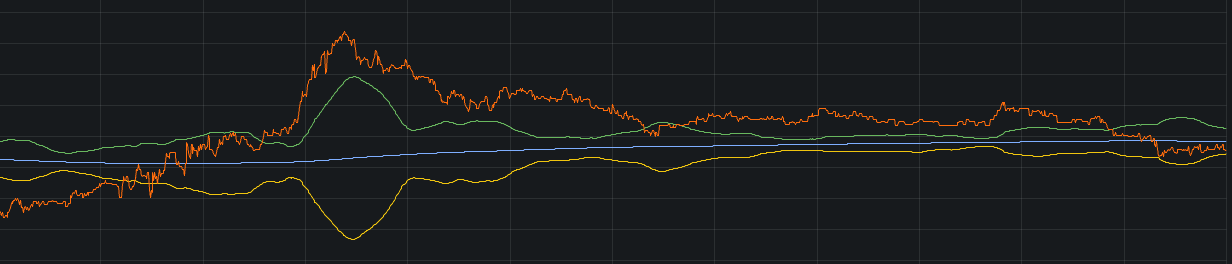
2.5 벡터매칭 (join)
prometheus에서 가장 많이 사용되는 기능중 하나인 join (Vector Matching) 기능이다.
매칭 방법에 따라 one to one, one to many, many to one 으로 나뉜다.
2.5.1 one to one 매칭
각 인스턴스별로 매칭에 참여할 데이터가 하나씩 있을때 가능한 매칭이다.
예를들어 다음과 같은 데이터가 있다고 해보자
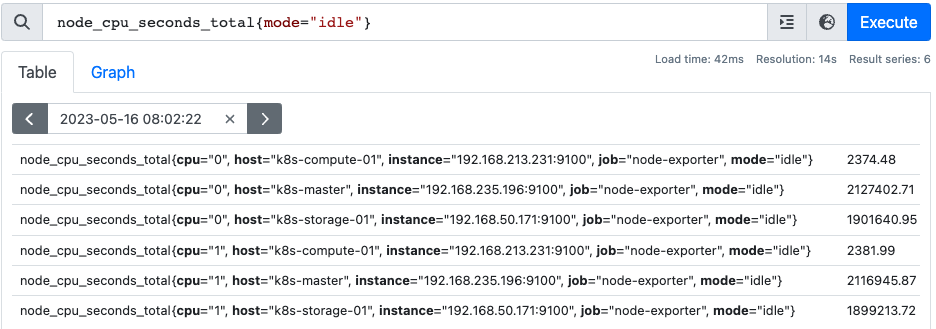
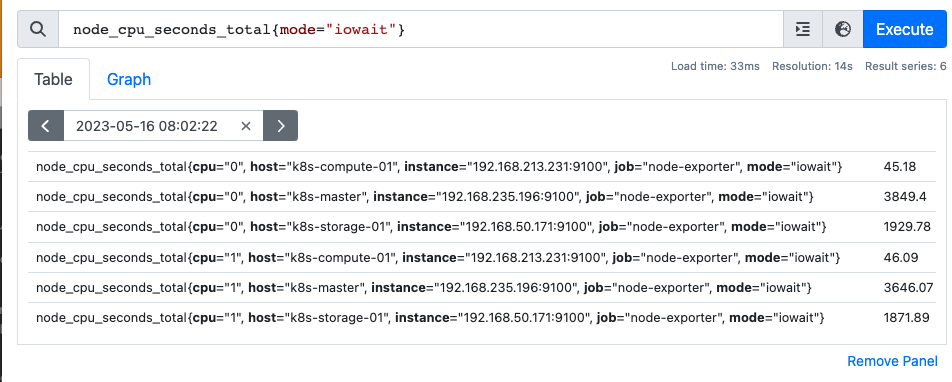
node_cpu_seconds_total 은 호스트의 cpu 사용상태를 나타내는 메트릭으로, idle은 유휴상태, iowait은 io를 위해 기다리는 상태를 의미한다. (의미보다는 연산 방법에 대해 설명한다)
두 벡터는 label이 다르기 때문에 기본 연산으로는 연산이 불가능하므로, 벡터매칭 키워드인 on, ignoring을 사용하여 join을 해야한다.
one-to-one 매칭은 두 벡터의 데이터가 일대일 대응을 통해 계산된다. 위의 두 벡터는 라벨이 다르기 때문에 on 이라는 키워드를 통해 해당 라벨만을 사용해 매칭을 시도한다.
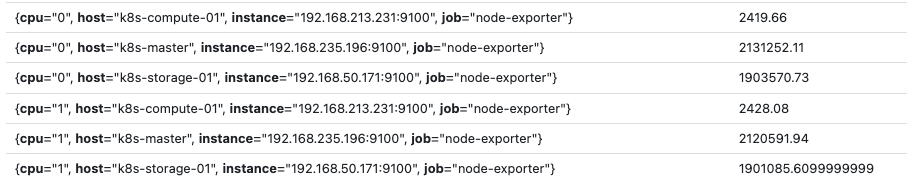
node_cpu_seconds_total{mode="idle"} + on (cpu, instance) node_cpu_seconds_total{mode="iowait"} on 또는 ignoring은 매칭에 사용되는 라벨을 정의한다. one-to-one 매칭에서는 각 데이터가 일대일 대응을 해야하므로, 일대일 대응을 만족하는 라벨을 on 또는 ignoring으로 사용해주면 된다.
또한 위의 두 벡터의 경우 mode라는 라벨을 제외하면, 각 데이터가 일대일 매칭이 되므로
node_cpu_seconds_total{mode="idle"} + ignoring (mode) node_cpu_seconds_total{mode="iowait"} 라는 쿼리도 동일하게 동작한다.
2.5.2 one to many, many to one 매칭
하나의 데이터에 여러개의 데이터가 매칭되는 방식이다.
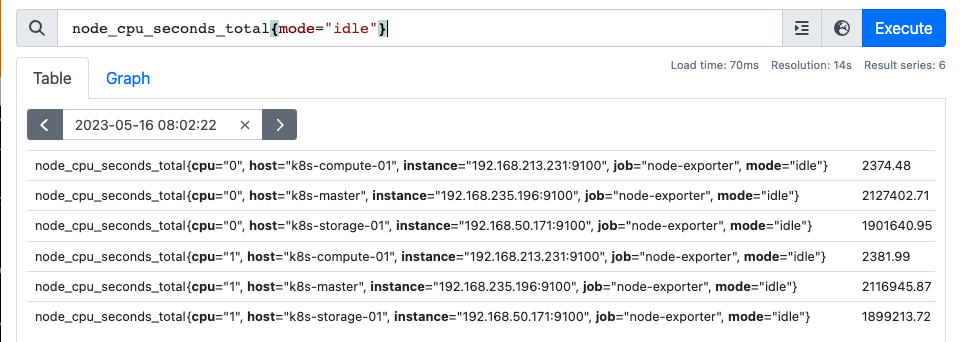
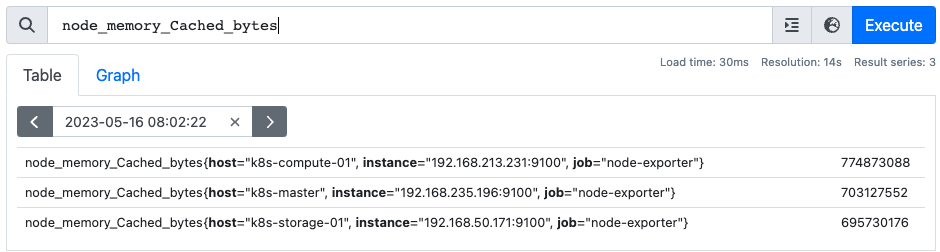
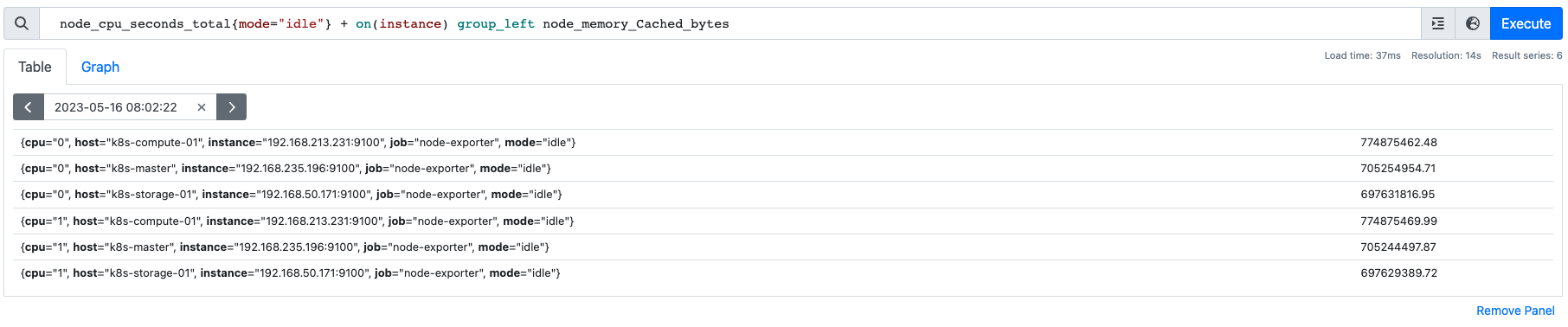
node_memory_Cached_bytes 메트릭은 각 인스턴스의 캐시메모리 크기를 나타내는 메트릭으로 각 인스턴스마다 하나의 데이터를 가지고 있다.
두 벡터는 instance 를 기준으로 2(cpu) : 1(memory) 의 관계를 보인다.
이 둘을 매칭하기 위해선 카디널리티의 개념이 필요하다. 카디널리티란 한 메트릭이 가지는 데이터 포인트의 개수를 의미한다.
일대다 매칭에서는 카디널리티가 더 높은 쪽을 group_{left, right}로 명시해 해당 벡터를 기준으로 매칭이 이뤄진다.
node_cpu_seconds_total{mode="idle"} + on(instance) group_left node_memory_Cached_bytesnode_memory_Cached_bytes 보다 node_cpu_seconds_total{mode="idle"}가 instance 라벨에 대해 카디널리티가 더 높기 때문에 group_left로 지정해 연산이 이루어진다.