
프로젝트의 성능 테스트를 진행하며 로그인과 관련된 성능을 최적화한 기록을 정리한 글이다.
서버가 견뎌낼 수 있는 요청수를 파악하기 위해 용량테스트를 진행하고 있었는데, 생각보다 너무 저조한 성능을 보였다.
뭔가 원인이 있을것 같아 로그인 - 정보 요청 이라는 간단한 시나리오로 성능 테스트를 진행해 봤다.
테스트도중 문제를 발견했던 과정, 그리고 이를 해결하는 과정을 정리한 글이다.
테스트 환경
호스트
CPU: i5-10400 (6Core, 12Threads)RAM: 32GBDISK: 1.5TB (500GB M.2, 1TB M.2)
VM
Master: 3개 (docker swarm master)Worker: 2개 (docker swarm worker)- 2master : 모니터링 및 로깅
- 1master, 1worker : Spring App
- 1worker : DB, Redis (CPU 4)
CPU: 2RAM: 4GBDISK: 50GBNETWORK: Docker Network
docker
다음은 서버 인스턴스 현황이다.
MySQL: 1개 (8.0.23, master)Redis: 1개 (7.2.5, master)JVM: 2개 (jshop-0.0.7-beta)
테스트 도구
nGrinder/controller: 1개 (3.5.9-p1)nGrinder/agent: 3개 (3.5.9-p1)
테스트 데이터
user:100만명
테스트 시나리오
- 사용자는 로그인 이후, 자신의 회원 정보를 가져온다.
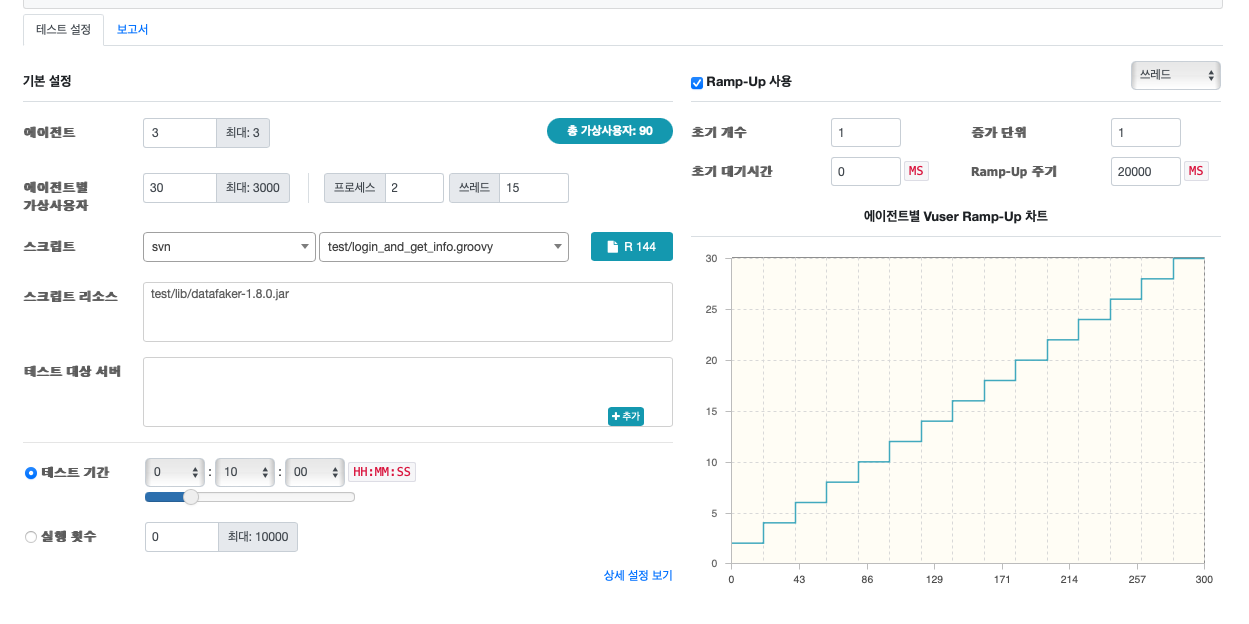
- vuser는 max 90 으로 한다
- ramp up 으로 vuser를 점점 늘린다.
AS IS
vuser
- 최대
90
RPS
- API마다 최대
60 RPS
응답속도
- 로그인 API :
1s - 개인 정보 요청 API :
10ms
TO BE
내가 원하는 사양은 많은 사용자들이 접속하더라도 1초 이내에 원하는 결과를 받아볼 수 있는 것이다.
vuser
- 최대
300
RPS
- API마다 최대
300 RPS
응답속도
- 로그인 API :
1s - 개인 정보 요청 API :
1s
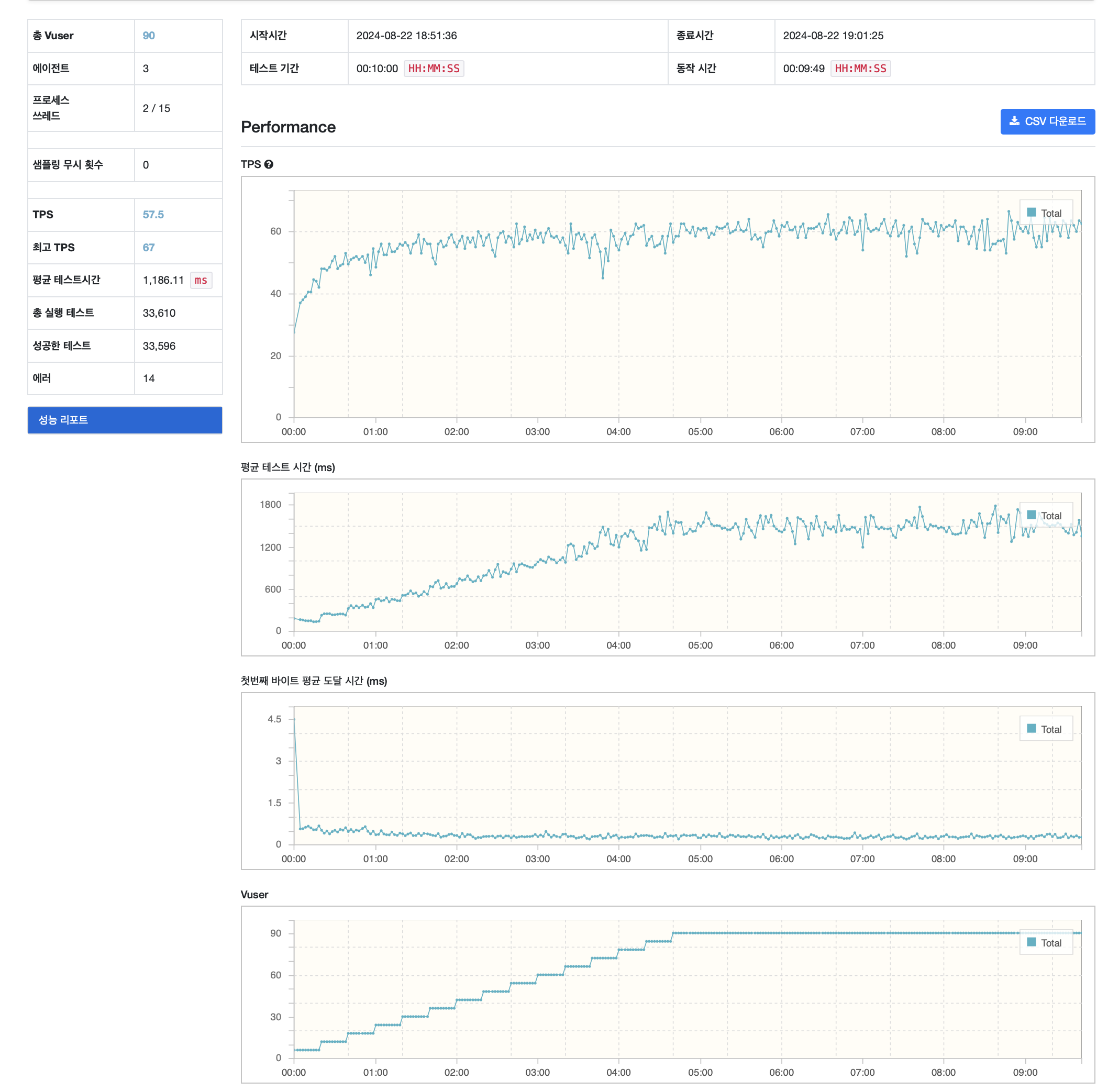
테스트 결과 분석
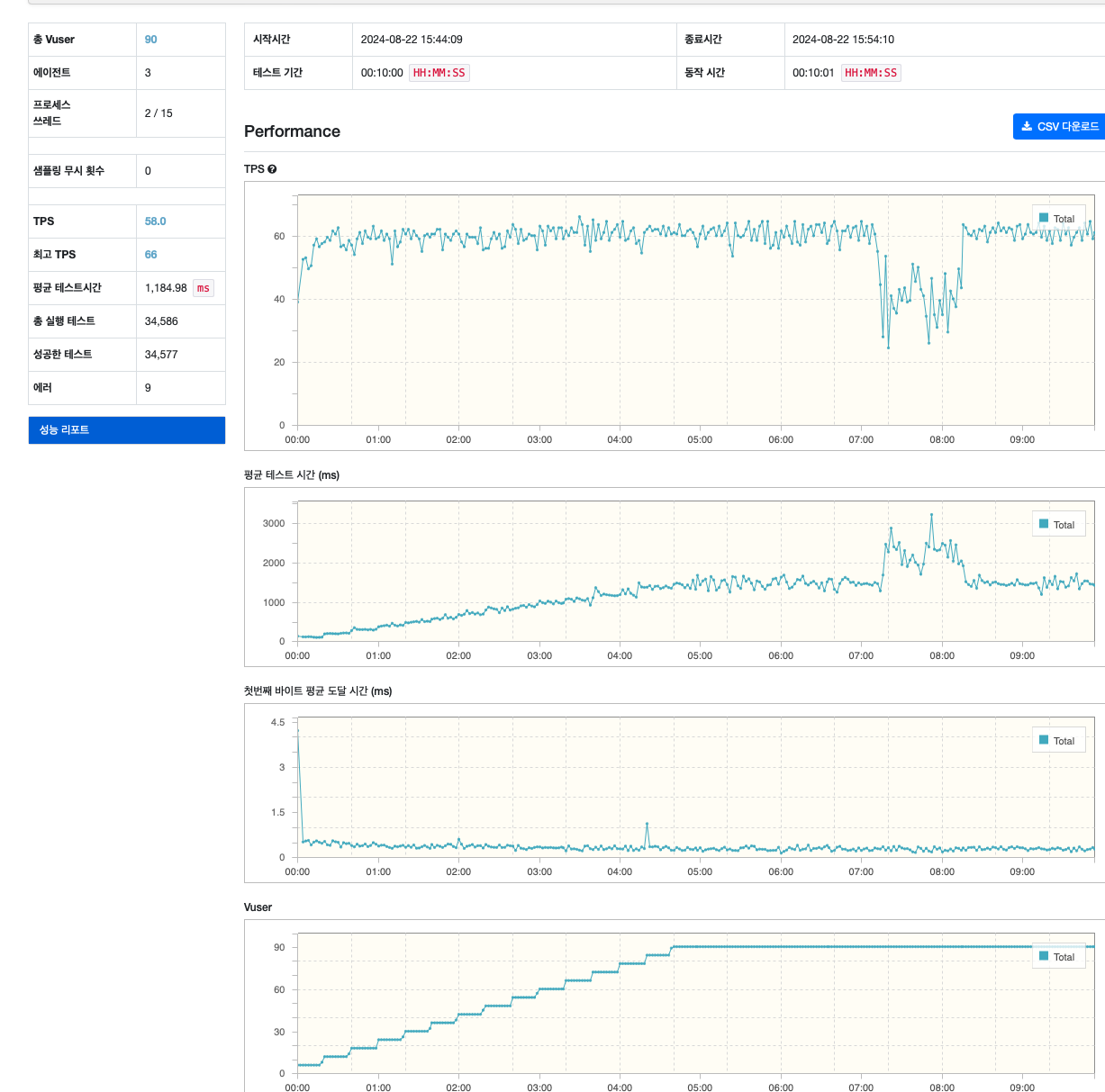
테스트 전에는 이정도 환경에서 약 100RPS는 가뿐하게 나올것이라 생각했다. 하지만 실제로 테스트를 해보니 인스턴스당 약 30RPS 씩 밖에 받지 못하는 것을 확인할 수 있었다.
병목 분석
병목을 찾기 위해 데이터들을 모니터링 해봤다.
JVM
우선 JVM을 모니터링 해본 결과, 메모리나 GC에선 큰 이상을 발견할 수 없었다.


하지만 그에 반해 CPU 사용량은 아주 높았다.
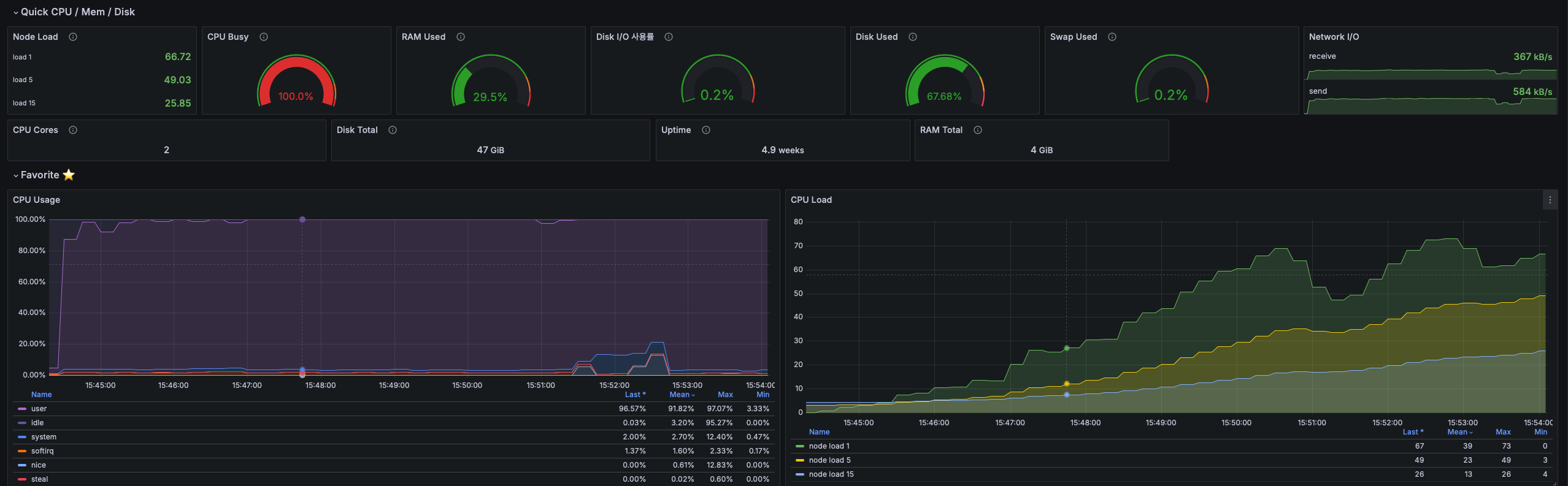
겨우 하나의 인스턴스에서 초당 30개의 로그인, 회원 정보 GET을 처리하는데 사용량 100% 에 1분간 부하는 약 60이 넘을 정도로 심한 부하를 받고 있는 상황이다.
만약 I/O 바운드일 경우 부하가 높을 순 있어도 보통 사용량은 낮은데 이경우 사용량까지 높아서 API중 CPU 바운드 작업으로 인한 병목에 대한 의심이 약간 생겼다.
MySQL
로그인, 회원 정보 GET 요청에서는 각각 회원에 대한 정보를 요청한다.
로그인의 경우 회원 테이블만, 회원 정보의 경우 회원테이블과 연관된 테이블까지 같이 조회해서 넘기게 된다.
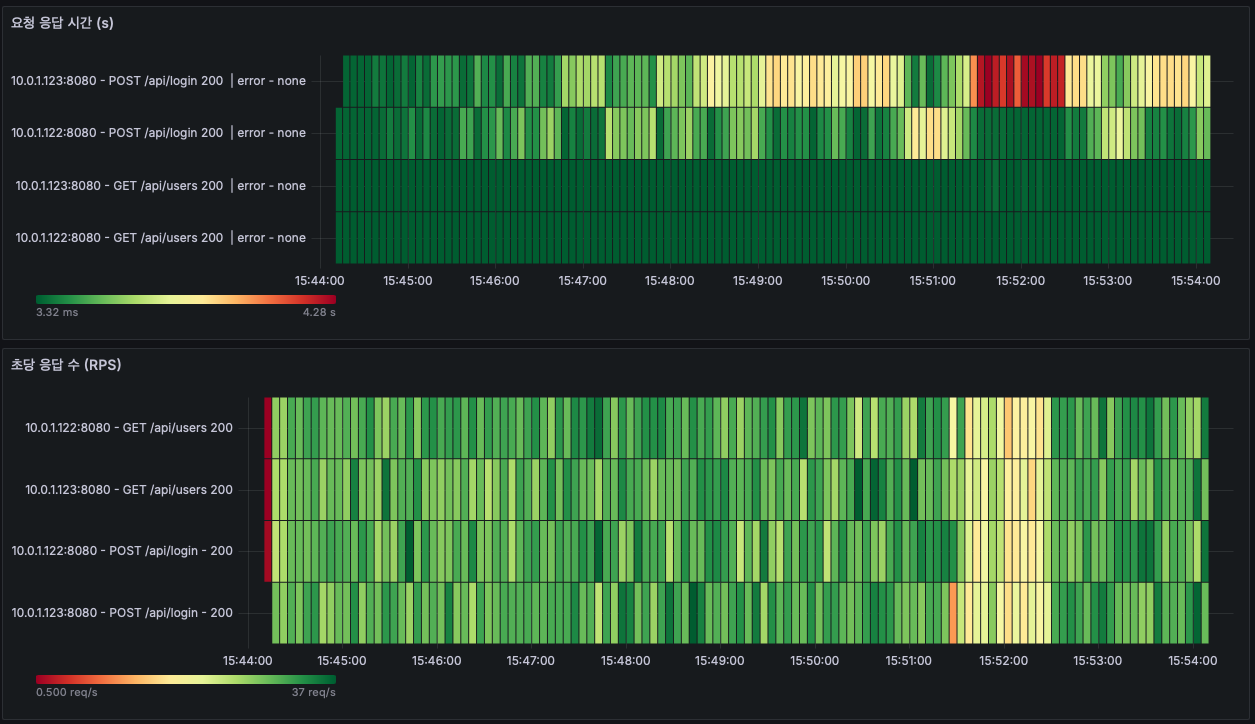
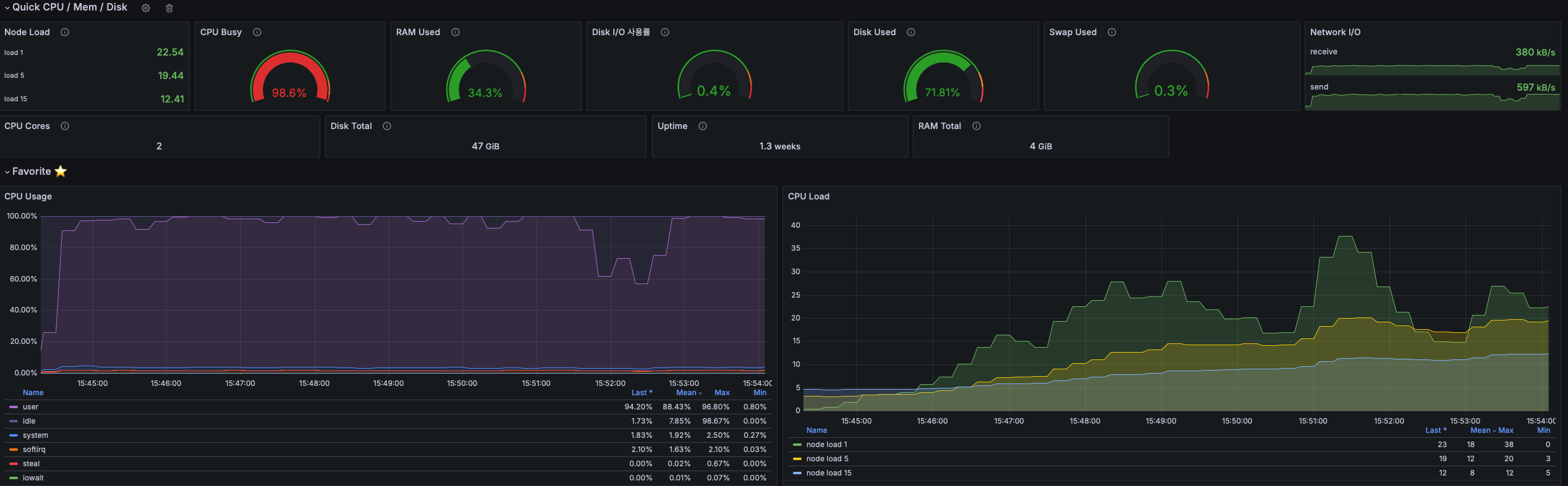
하지만 MySQL 노드 자체에 대한 CPU, IO 부하가 없고, 오히려 더 큰 부하를 요구하는 회원 정보 요청의 경우 빠른 속도로 수행되었기 때문에 로그인 API에 대한 의심이 더욱 커졌다.
아래는 테스트 기간동안의 MySQL 노드의 CPU, Memory, Disk 사용량이다.
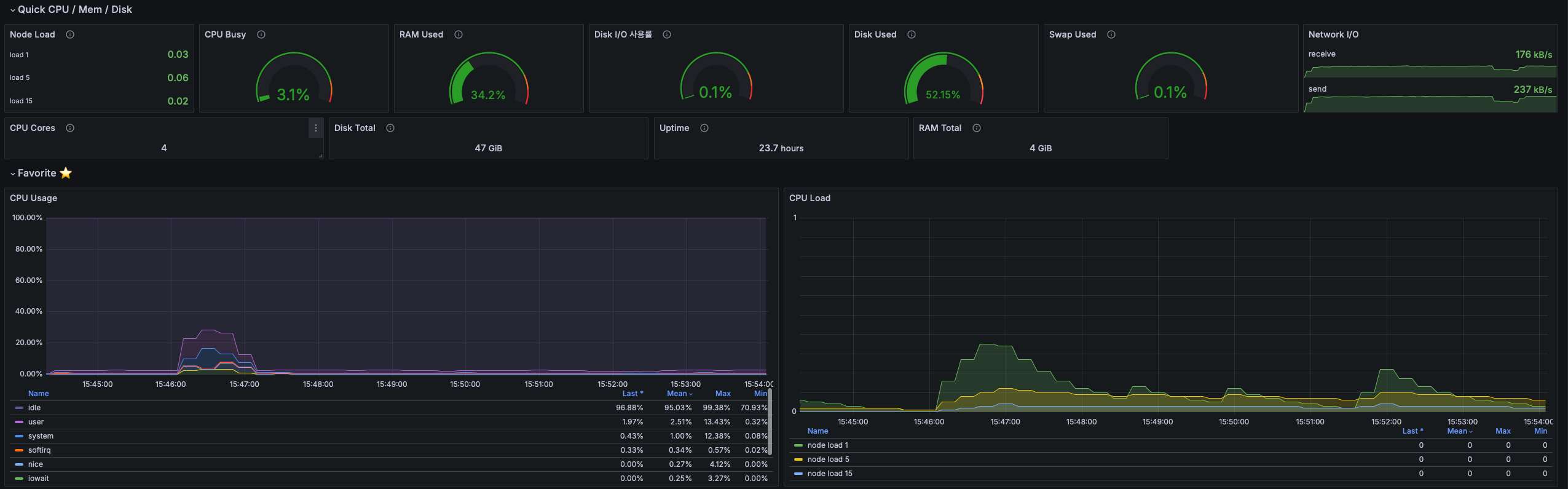
CPU, Memory, Disk 모두 거의 사용하지 않는것, 즉 MySQL은 병목이 아니란것을 확인할 수 있다.
로그 분석
로그를 분석해 봤다.
일반적으로 로그인을 할때는, 사용자 정보를 DB에서 가져와 API로 가져온 정보와 조회를 한다.

그런데 사용자 정보 요청 API 에서는 두번의 쿼리가 나가는것을 확인할 수 있었다.
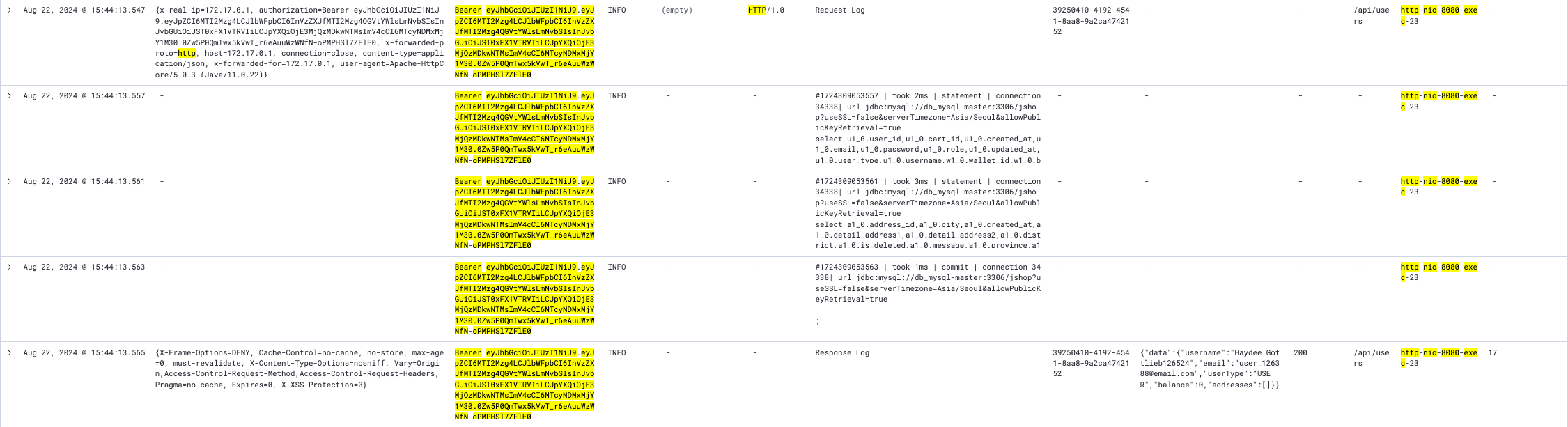
이 요소가 병목이 될것같진 않지만, 그래도 성능을 위해 최적화를 해두는것이 좋을것 같다.
결론
로그인 API , 회원 정보 요청 API 에서 CPU 바운드 작업으로 인한 병목이 강하게 의심되는 대목이다.
문제 해결
우선 눈에 보이는 문제부터 하나씩 해결해 봤다.
1. 쿼리 최적화
현재 회원 정보 요청 API 에서 두번의 쿼리로 데이터를 요청한다.
public UserInfoResponse getUserInfo(Long userId) {
User user = getUser(userId);
List<Address> addresses = addressRepository.findByUser(user);
return UserInfoResponse.of(user, addresses);
}하지만 이경우 굳이 따로 보낼 이유가 없어 한번에 모든 데이터를 가져오도록 수정해 줬다.
User 엔티티에 양방향 연관관계를 추가해주고, 모든 데이터를 패치 조인할 수 있는 메서드를 하나 추가해 줬다.
@OneToMany(fetch = FetchType.LAZY, mappedBy = "user")
private List<Address> addresses; @EntityGraph(attributePaths = {"wallet", "addresses"})
Optional<User> findUserWithWalletAndAddressById(@Param("id") Long id);레이지 로딩이 아니게 가져오는지 테스트까지 완료하고 배포해 동일 테스트로 수행해 봤다.
// then
assertThat(Hibernate.isInitialized(findUser.getAddresses())).isFalse();
assertThat(Hibernate.isInitialized(findUser.getWallet())).isTrue(); // then
assertThat(Hibernate.isInitialized(findUser.getAddresses())).isTrue();
assertThat(Hibernate.isInitialized(findUser.getWallet())).isTrue();

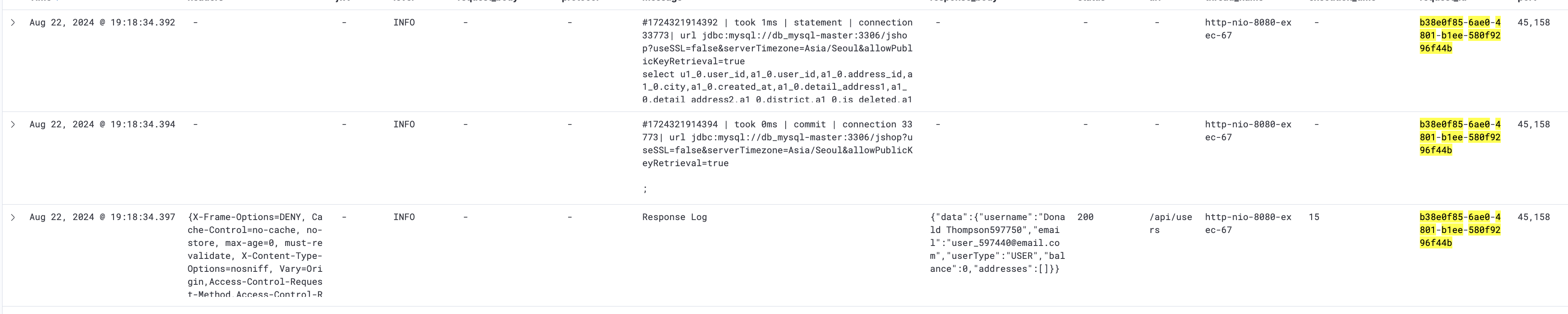
결과
사용자 정보 요청 쿼리가 2번에서 1번으로 줄었지만 여기가 병목이 아니었기 때문에 큰 성능 향상은 있지 않았다.
2. 톰캣 튜닝
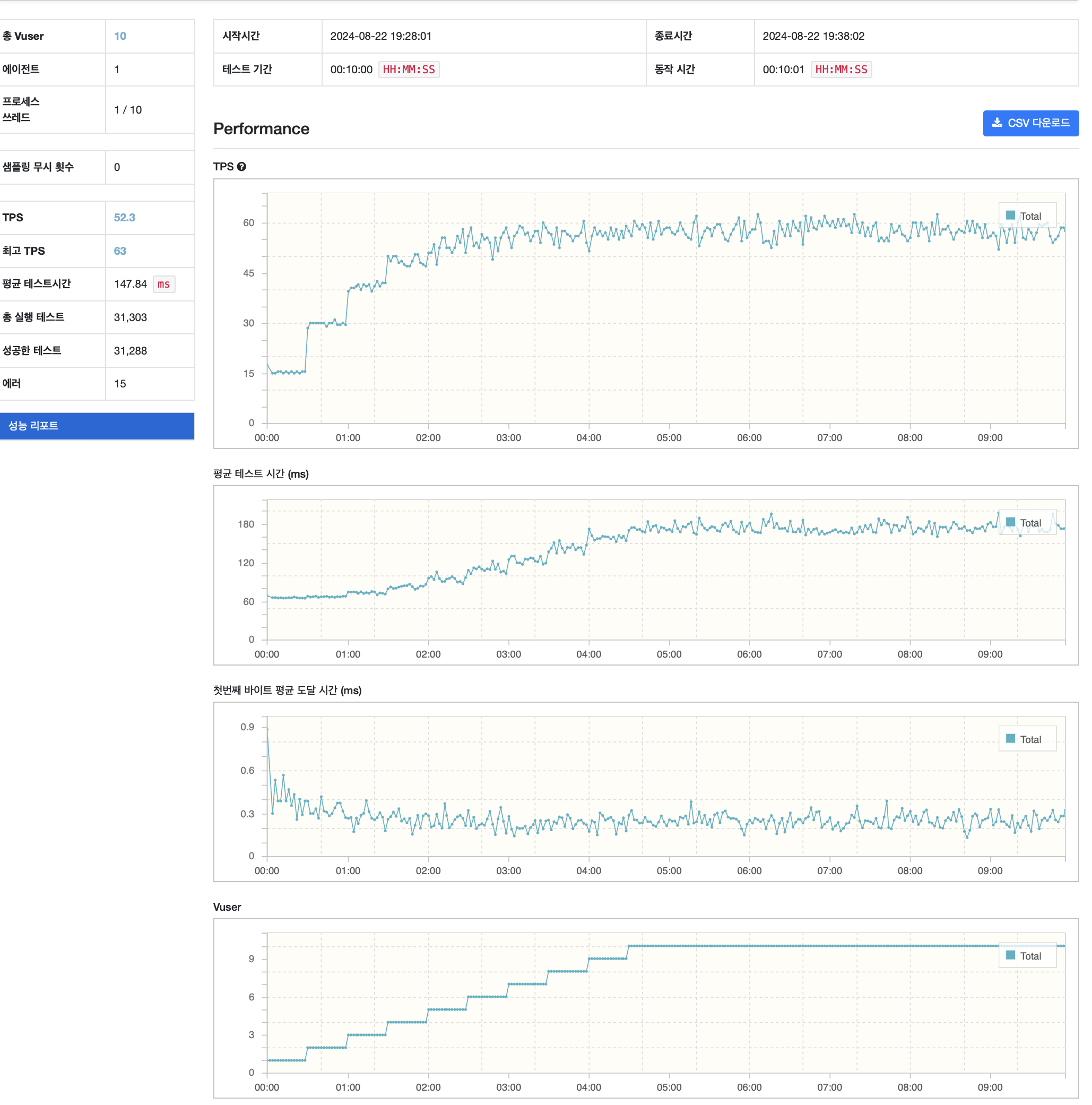
다음은 혹시 2코어인 환경에서 너무 많은 스레드로 인해 컨텍스트 스위치가 자주 발생해 생기는 문제를 의심해 봤다.
현재 톰캣 기본 설정을 쓰고 있었으므로 요청 스레드 200 개가 생성되게 된다.
혹시 2코어에서 이들간 스위칭이 많이 일어나서 발생하는 문제인가 싶어서 요청 스레드 수를 10 까지 줄이고 테스트 해봤다.
server:
tomcat:
threads:
max: 10
min-spare: 2
accept-count: 100결과
하지만 여전히 성능은 60RPS 에서 크게 나아지지 않았다.
3. 로그인 API 병목 제거
로그인 API의 수행 속도가 느려지는걸로 보아 아무래도 로그인과 관련된 CPU 바운드 작업이 병목으로 의심이 되어, 몇가지 실험을 해봤다.
로그 설정
우선 실행 속도를 측정하기 위해 실행 속도 AoP를 추가했다.
모든 메서드의 실행 속도를 로그로 출력한다.
이로 인해 부하가 약간 늘어날 수 있지만, 현재 CPU 바운드의 부하를 잡아야 하기 때문에 넣었다.
그리고 몇가지 가설로 실험을 진행해 봤다.
가설 1) 스프링 시큐리티가 병목을 일으킨다.
처음 한 의심은 스프링 시큐리티 필터들을 지나며 과도한 CPU 작업이 있어 이점이 병목으로 작용하는가 였다.
실험 1.1) 필터를 무시하는 검색 API 테스트
시큐리티 필터를 무시하는 검색 API를 가지고 실험을 해봤다.
내 가정이 맞다면, 높은 RPS를 보여줄 것이다.
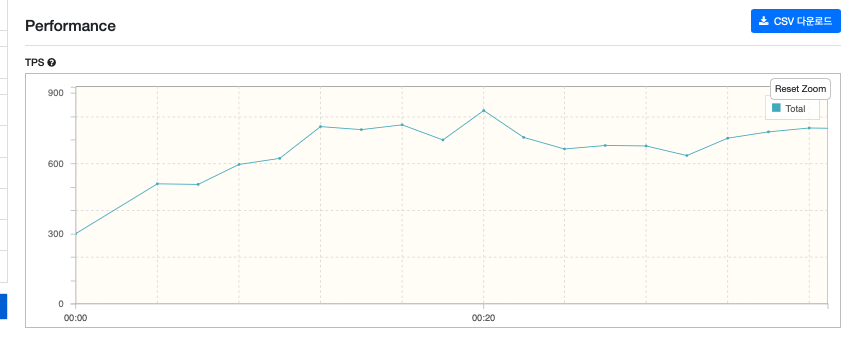
결과는 실제로 높은 RPS를 보여주었다.
하지만, 이것이 스프링 시큐리티 필터의 병목에 대한 증거가 될 수 없기에 몇가지 실험을 더 진행해봤다.
실험 1.2) 필터를 거치는 조회 API (로그인 없이)
만약 스프링 시큐리티를 통과하는 API가 높은 RPS를 보여준다면 스프링 시큐리티가 병목이라는 가정이 거짓이게 된다.
미리 로그인을 해 토큰을 얻고 회원 정보 요청 API 만 테스트를 진행해봤다.
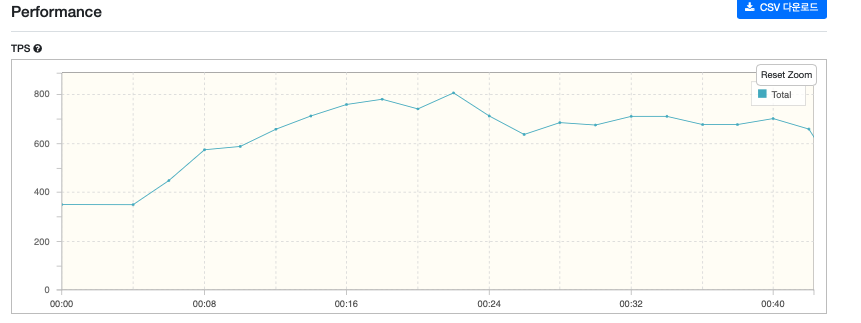
하지만 예상과 다르게 시큐리티 필터를 통과하는 API도 높은 RPS를 보여줬다.
여기서 로그인 API가 병목으로 작용한다는것을 알 수 있다.
가설 2) 로그인 API가 병목을 일으킨다.
이번에는 로그인만으로 테스트를 진행해봤다.
실험 2.1) 로그인 API만 테스트
내 가설이 맞다면 약 60 RPS 정도가 나오고, 높은 CPU 사용량, 로드를 보일 것이다.
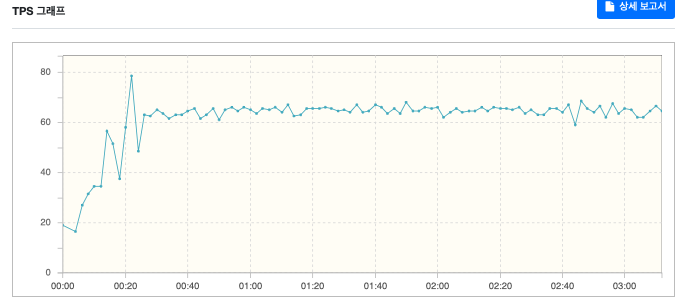
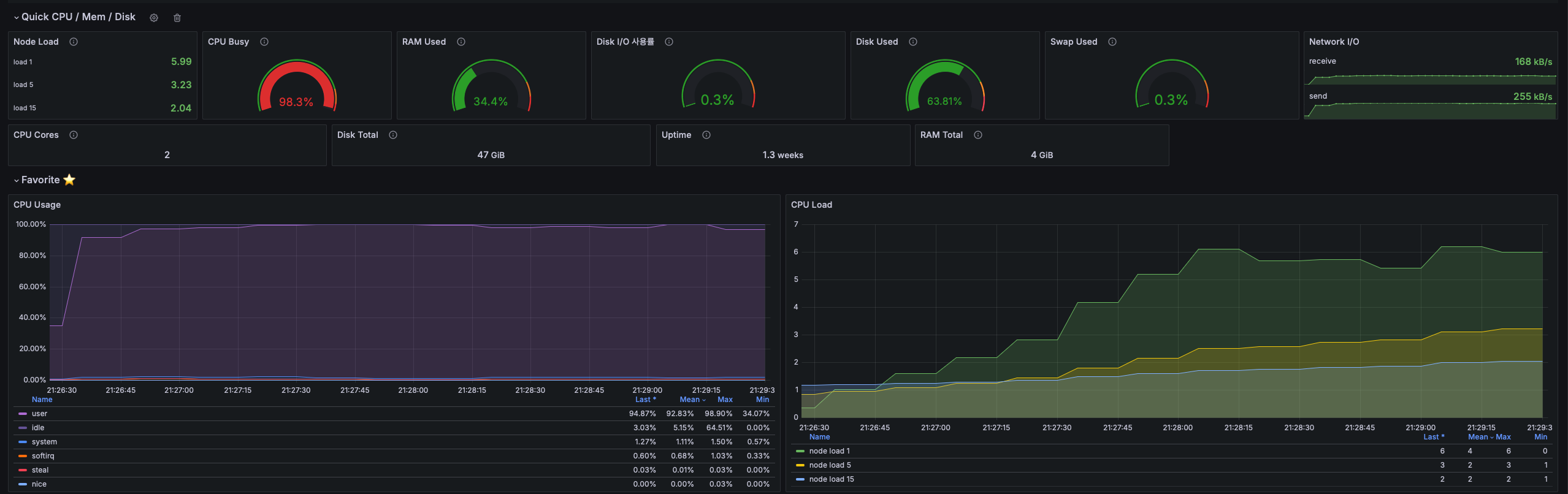
예상대로 약 60RPS에, 높은 CPU 사용량, 로드를 보여줬다.
로그인 API가 병목으로 작용한 것이다.
PasswordEncoder
현재 로그인 과정을 보면
- JSON Body로 사용자 정보 전송
- DB 에서 동일 사용자 정보 패치
- 암호화된 비밀번호 비교
이다.
이 과정에서 CPU 바운드 병목으로 작용할 곳은 비밀번호 비교 밖에 없어서 이 부분을 좀 찾아봤다.
스프링 시큐리티는 보안을 위해 비밀번호를 항상 인코딩된 해시값으로 저장하게 하고 사용자 인증이 필요할때는 사용자로부터 raw 비밀번호를 받아 인코딩해 저장된 값과 비교한다.
이때 스프링 시큐리티에서는 PasswordEncoder 인터페이스를 구현한 빈을 사용한다.
나의 경우 BCryptPasswordEncoder 를 사용했다.
BCryptPasswordEncoder
BCryptPasswordEncoder 는 의도적으로 느리게 동작하는 해싱 알고리즘으로 강력한 해싱으로 높은 수준의 암호화 능력을 가진다.
BCryptPasswordEncoder 는 생성자로 암호화 강도 값을 받을 수 있다. (4 ~ 31, default 10)
이 값은 해시 함수의 반복을 설정하는 인수로 2 ^ {강도} 의 수만큼 해싱이 이루어지게 된다.
즉 인수가 4일경우 16번의 해싱이, 기본값 10일 경우 1024 번의 해싱이 반복되게 된다.
이로인해 많은 반복이 의도적인 지연을 발생시키고 악의적인 사용자의 brute force를 방어할 수 있게 되는것이다.
하지만 반복 해싱 작업은 높은 CPU 사용량을 필요로 하고 내 경우에서 이것이 병목으로 작용했던 것이다.
그래서 암호화 강도를 최소수치인 4까지 낮추어 테스트를 진행해 봤다.
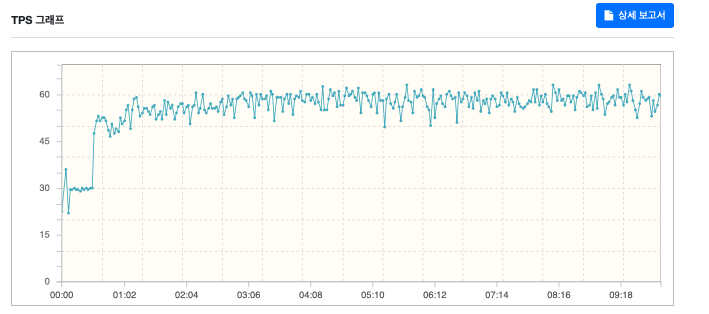
하지만 성능에는 큰 영향을 주지 못해 다른 암호화 알고리즘을 찾아봤다.
Pbkdf2PasswordEncoder
Pbkdf2PasswordEncoder 역시 반복을 통한 해싱으로 의도적인 지연을 발생시켜 보안을 강화하는 방식이다.
보안을 위해선 높은 반복 (약 1초가 걸리도록) 설정하는것이 좋지만, 지금 나의 경우 그렇게까지 높은 보안이 필요로 하지는 않는다.
그래서 좀 더 낮은 반복수로 설정을 해 테스트를 진행해 봤다.
여기서 자바, 스프링의 장점이 나오는데 시큐리티는 PasswordEncoder 라는 인터페이스로 정말 잘 추상화 되어있기 때문에 실제 구현체가 어떤것을 사용하든 상관이 없다. 즉 내가 빈으로 등록하는 PasswordEncoder 만 바꿔주면 된다.
@Bean
public PasswordEncoder passwordEncoder() {
String secret = "my-secret";
return new Pbkdf2PasswordEncoder(secret, 64, 100, SecretKeyFactoryAlgorithm.PBKDF2WithHmacSHA256);
}보통 보안을 위해 10,000 정도의 반복이 요구되지만, 나의 경우 반복을 100 으로 설정해 주었다.
그리고 테스트를 진행해본 결과 눈에 띄는 성능 향상을 확인할 수 있었다.
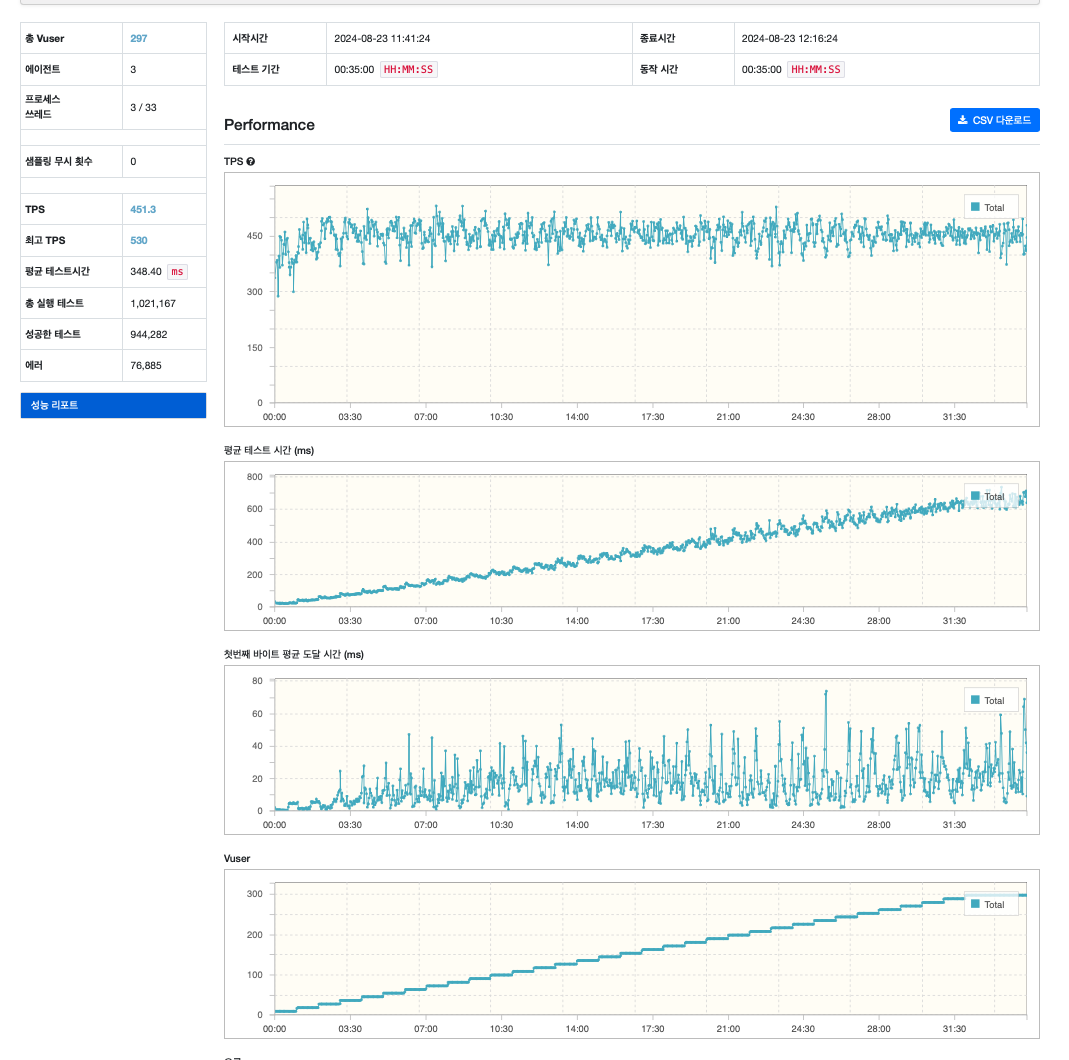
약 300명의 vuser 가 요청하더라도 평균 응답 시간 400ms 이내, 400RPS 로 동작했다.
정리
다른 성능 테스트도중 성능이 생각보다 너무 안나와 로그인과 간단한 API로 부하를 높혀가며 테스트를 진행해 봤다.
테스트 결과 DB, IO 쪽 부하는 없는 반면 CPU쪽 부하는 아주 높게 나와 시큐리티와 관련된 병목이 아닌가 의심이 들었다.
실제로 로그인 과정에서 비밀번호 인코딩이 의도적으로 지연된 동작을 하게됨을 알 수 있었고 이를 제거하니 성능이 약 7 ~ 8 배 향상한것을 확인할 수 있었다.
실제 서비스 라면 보안과 성능사이의 적절한 타협점을 찾아야 한다.
모니터링 시스템을 잘 구축해둬서, CPU 바운드로인한 병목을 파악한것이 문제 해결에 큰 도움이 되었다.
ref
