멀티 스레드는 하나의 프로세스에서 여러 개의 스레드를 동시에 실행하는 것으로, 주로 다수의 클라이언트 요청을 동시에 처리하거나 대량의 데이터를 병렬처리하기 위해 사용한다. 멀티 스레드를 사용해 작업을 빠르게 처리할 수 있지만 주의해야 할 부분이 있다.
먼저 멀티 스레드와 관련해 혼동하기 쉬운 병렬처리와 비동기처리에 대해 알아보자.
병렬처리
하나의 작업을 여러 개의 작업으로 나누어 처리하는 방법으로 멀티 코어를 활용해서 각 작업을 동시에 처리하기 때문에 작업 속도를 향상시킬 수 있다. 주로 대량의 데이터를 빠르게 처리해야 하거나, 복잡한 연산을 효율적으로 처리하기 위해 사용된다.
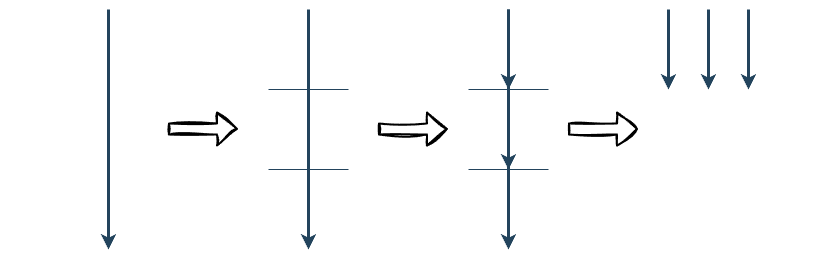
멀티 스레드와 병렬처리는 동시에 처리하는 부분에서 유사한 면이 있지만, 서로 다른 문맥에서 사용된다.
비동기처리
주 실행 흐름에서 발생한 작업의 완료 여부와 관계없이 다음 작업을 계속 수행하는 방식으로 작업을 순차적으로 기다리지 않고 주 실행 흐름은 계속 진행된다.
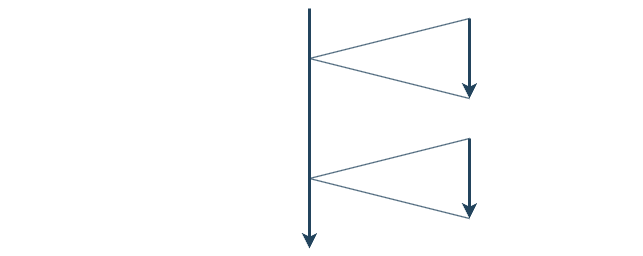
주로 입출력 작업처럼 시간이 오래 걸리는 작업을 대상으로 사용한다.
👉 자바는 비동기 프로그래밍을 지원하기 위해 CompletableFuture를 제공한다.
병렬과 비동기의 차이
두 가지 방법 모두 나누어 따로 처리하기 때문에 비슷해 보이지만 병렬처리는 작업을 분리, 비동기처리는 흐름을 분리하는 것으로 아래 그림처럼 표현할 수 있다.
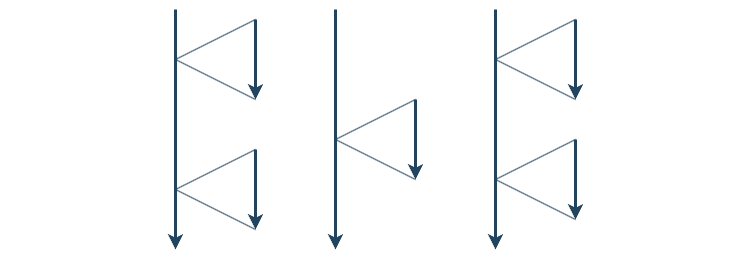
멀티 스레드 환경에서 병렬처리와 비동기처리를 함께 사용하면 작업 대기시간을 최소화하고 시스템 자원을 효율적으로 사용할 수 있어 성능을 향상시킬 수 있다.
동시성 문제를 주의하자!
앞서 살펴본 병렬처리와 비동기처리와 같이 멀티 스레드도 여러 작업을 동시에 처리하는데 이 과정에서 동시성 문제가 발생할 수 있다.
동시성 문제란 여러 스레드가 공유 자원에 동시에 접근하여 예상치 못한 결과를 초래하는 상황을 말하며, 수정 작업이 동반되는 경우 발생한다.
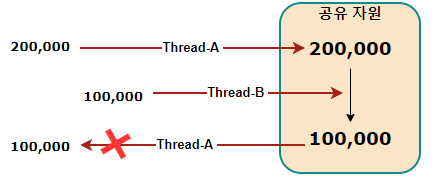
Thread-A가 데이터를 변경하고 값을 조회하는 사이, Thread-B가 동일한 데이터를 수정하게 되면 Thread-A는 예상과 다른 결과를 얻게 된다. 이 문제를 해결하기 위해서는 각 스레드의 작업이 서로에게 영향을 미치지 못하도록 해야 한다.
동시성 문제를 해결하기 위한 여러 가지 방법들이 있지만 세 가지 방법만 다뤄보려고 한다.
synchronized
자바가 제공하는 예약어로, 메서드에 선언하거나 블록 형태로 사용할 수 있다.
pubilc synchronized void synchronizedMethod() {
...
}
syncroized(lock) {
...
}여러 스레드가 동시에 접근하는 경우, lock을 사용해서 한 번에 하나의 스레드만 접근할 수 있도록 한다. 따라서 먼저 접근한 스레드의 처리가 끝날 때까지 다른 스레드는 해당 영역에 접근할 수 없어 스레드의 안정성이 보장된다.
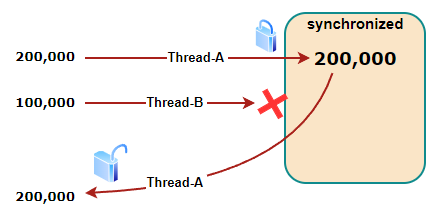
하지만 경우에 따라 lock을 얻고 해제하는 과정으로 인해 성능 저하가 발생할 수 있으며, 잘못된 순서로 lock을 획득하거나 해제할 경우 교착 상태에 빠질 수 있다.
🤔 교착상태란?
여러 작업이 서로 끝나기 만을 기다려 아무것도 완료하지 못하는 상태이다.
ThreadLocal
각 스레드에 연결된 별도의 인스턴스로 다른 스레드의 영향을 받지 않고 값을 저장하고 조회할 수 있다.
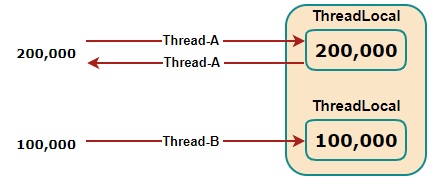
공유 자원을 동기화 처리하는 것이 아니라 별도의 저장소를 사용하기 때문에 보통 스레드 별로 고유한 상태를 유지하고 전파하기 위한 목적으로 사용한다.
🚨 주의!
멀티 스레드 환경에서는 쓰레기 값이 메모리를 차지하지 않도록 사용 후 반드시 remove() 메서드를 호출해서 ThreadLocal을 제거해야 한다.
java.util.concurrent 패키지를 활용하자!
자바에서 동시성 프로그래밍을 지원하는 패키지로 멀티 스레드 환경에서 스레드 간의 작업을 조율하고 동시성 문제를 처리하는데 사용된다. 대표적인 클래스인 ConcurrentHashMap을 통해 어떻게 동시성 문제를 해결하는지 알아보자.
ConcurrentHashMap
버킷 단위로 동기화 처리하며, 이전 버전의 세그먼트 분할 방식이나 synchronized 처리와 비교해 최소한의 lock 사용으로 스레드 안정성을 유지한다.
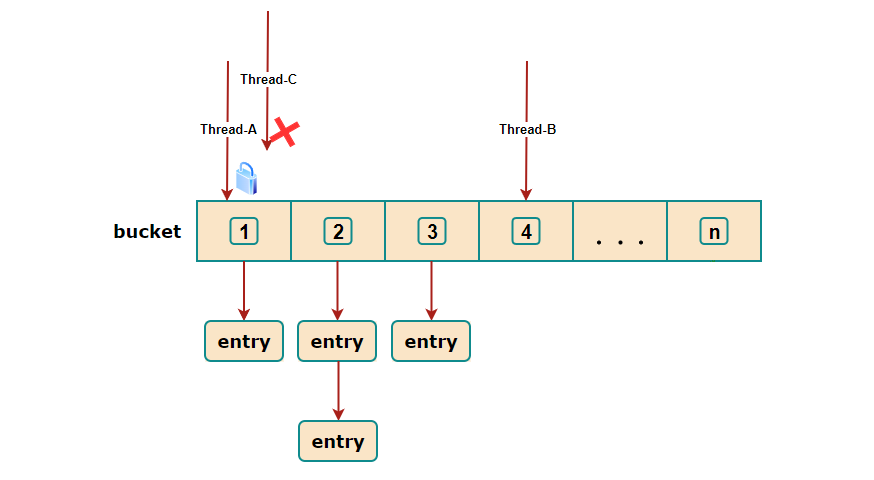
ConcurrentHashMap은 synchronized처럼 스레드의 접근을 제한하는 것이 아니라 volatile과 CAS 연산을 활용해 스레드를 동기화한다.
volatile과 메모리 가시성
간단한 예제와 함께 volatile과 CAS 연산에 대해 알아보자.
public int count = 0; // 공유 변수
for (int i=0; i<50000; i++) {
count++;
}멀티 스레드 환경에서 공유 변수 접근 시, JIT 컴파일러는 캐시를 활용해 내부적으로 최적화 작업을 수행한다. 이렇게 되면 CPU는 캐시를 거쳐 연산을 수행하는데 각 스레드가 캐시의 값을 공유하지 않기 때문에 연산과정이 기대와 다르게 흘러간다.
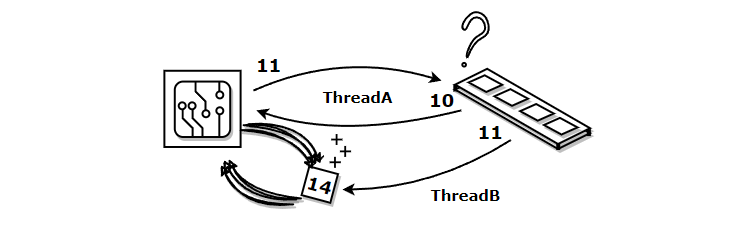
자바의 volatile은 JIT 컴파일러가 최적화 작업을 수행하지 않게 함으로써, 연산과정에서 캐시가 아닌 실제 메모리에 바로 접근하도록 한다. 이를 통해 멀티 스레드 환경에서 메모리 가시성을 확보할 수 있게 되며, 기대한 결과에 가까워진다.
하지만 volatile만으로는 완벽하게 동기화 시킬 수 없다.
CAS(Compare And Swap)와 연산의 원자성
volatile을 선언한 후, count++; 는 세 가지 동작으로 구분할 수 있다.
1. count의 값을 메모리에서 읽는다.
2. CPU가 count에 1을 더한다.
3. 연산 결과를 메모리에 저장한다.만약 하나의 스레드에서 세 번째 과정이 끝나지 않았는데 다른 스레드가 첫 번째 과정을 수행하면 어떻게 될까?
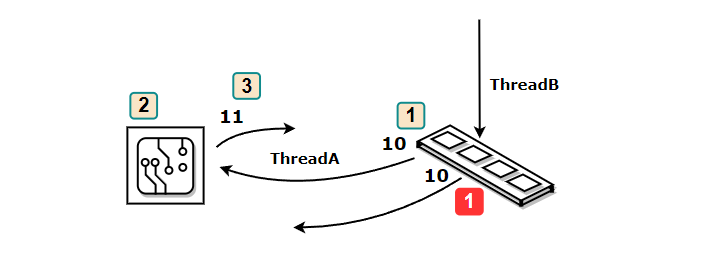
연산이 순차적으로 진행되지 않고 중복된 결과를 반환하게 된다. 세 가지 과정을 하나의 과정 즉, 하나의 연산으로 취급해서 연산의 원자성을 보장하면 이런 문제를 해결할 수 있다.
CAS는 연산의 원자성을 보장하기 위한 알고리즘으로 현재 메모리의 값이 기대값과 다르면 작업을 수행하지 않으며, 다른 전략을 선택하거나 두 값이 동일할 때까지 재시도한다. 이처럼 스레드의 접근을 제한하지 않고, 스스로 접근하지 않도록 해서 동기화 처리하는 것이 핵심이다.
실제 코드를 확인해 보자!
ConcurrentHashMap의 실제 코드를 보면 대부분의 필드가 volatile로 선언되어 있는 것을 확인할 수 있다.
transient volatile Node<K,V>[] table;
private transient volatile Node<K,V>[] nextTable;
private transient volatile long baseCount;
...연산의 원자성은 putVal() 메서드에서 확인해 보자.
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
...
else {
synchronized (f) {
...
}
}
...
}수정 작업 시 노드가 비어있다면 casTabAt() 메서드를 호출하고, 이미 노드가 있다면 synchronized로 동기화 처리한다. casTabAt() 메서드는 미리 생성한 Unsafe 클래스의 인스턴스로 compareAndSetObject() 메서드를 호출하는데 이름에서 알 수 있듯이 CAS 연산을 지원한다.
//ConcurrentHashMap
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
//Unsafe
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetObject(Object o, long offset,
Object expected,
Object x);compareAndSetObject() 메서드는 네이티브 메서드로, 하드웨어 수준에서 연산의 원자성을 보장하는 방법을 제공한다.
CAS 연산은 기대값과 실제 메모리 값이 동일한 경우에만 수행된다고 했다. 실제 코드에서 casTabAt() 메서드의 세 번째 매개 변수에 왜 null이 전달되는지 고민해 보면 ConcurrentHashMap이 제공하는 원자적 연산을 이해하는데 도움이 될 거라 생각한다!
🤔 네이티브 메서드란?
자바 코드로 직접 구현하지 않고, 외부 언어(C, C++, 어셈블리 등)로 작성된 네이티브 코드를 호출하는 메서드이다. 자바 언어로는 표현하기 어려운 연산이나 하드웨어 접근 등을 처리하기 위해 사용한다.
이 외에도 유용한 기능을 많이 제공하기 때문에 java.util.concurrent 패키지를 사용해서 동시성 문제를 해결하는 것이 좋다.
정리
멀티 스레드와 관련 개념에 대해 알아보고, 멀티 스레드 사용 시 발생할 수 있는 문제와 해결법에 대해 알아보았다. 이를 간단히 정리해 보자.
- 멀티 스레드, 병렬처리, 비동기처리 모두 동시에 처리하기 때문에 유사하지만 다른 개념이다.
| 구분 | 설명 |
|---|---|
| 멀티 스레드 | 웹 애플리케이션처럼 다수의 요청 즉, 여러 흐름을 동시에 처리해야 할 때 사용한다. |
| 병렬처리 | 작업을 여러 작업으로 나누어 빠르게 처리해야 할 경우 사용한다. |
| 비동기처리 | 실행 흐름에서 발생한 작업의 결과 여부와 상관없이 진행한다. |
- 멀티 스레드 사용 시 동시성 문제를 주의해야 하며, 다음 세 가지 방법을 통해 문제를 해결할 수 있다.
| 구분 | 설명 |
|---|---|
| synchronized | lock을 사용해서 공유 자원에 여러 스레드가 접근하지 못하도록 한다. |
| ThreadLocal | 엄밀히 따지자면 동기화 처리는 아니지만, 별도의 저장 공간을 사용해서 동시성 문제를 해결할 수 있다. |
| ConcurrentHashMap | 버킷 단위의 CAS 연산과 최소한의 lock을 사용해서 스레드의 안정성을 보장한다. |
- ConcurrentHashMap은 메모리 가시성과 연산의 원자성을 활용해서 동기화 처리한다.
| 구분 | 설명 |
|---|---|
| volatile | 메모리 가시성을 확보하기 위해 사용하며, 연산 과정에서 캐시를 거치지 않고 바로 메모리에 접근하도록 한다. |
| CAS 연산 | 연산의 원자성을 보장하기 위해 사용하며, 기대값과 현재 메모리 값을 비교해 동일한 경우에만 연산을 수행한다. |
참고
Java API Documents - ConcurrentHashMap
https://github.com/openjdk-mirror/jdk7u-jdk/.../ConcurrentHashMap.java
https://yeoonjae.tistory.com/entry/Java-ConcurrentHashMap
https://itsromiljain.medium.com/curious-case-of-concurrenthashmap-90249632d335
https://pplenty.tistory.com/17
https://medium.com/double-pointer/guide-to-concurrenthashmap-in-java-9ba810b5182d

좋은 정보 얻어갑니다, 감사합니다.