심층 학습 (Deep Learning)
가장 활발하게 연구된다!!
여러 비선형 변환 기법의 조합을 통홰 높은 수준의 추상화(다량의 데이터나 복잡한 자료들 속에서 핵심적인 내용또는 기능을 요약하는 작업)를 시도하는 기계학습의 분야
심층 학습 이전에는 기계가 학습을 제대로 할 수 있도록 학습에 필요한 특징 값을 인간이 제공해야 했으나 심층 학습은 데이터로부터 특징 값을 기계 스스로 찾아내고 학습한다.
침층 학습을 위한 심층 신경망 : 심층 신뢰 신경망 , 적층 노이즈 제거 오토인코더, 합성곱 심층 신경망(이미지 인식에 탁월) ,순환신경망(음성인식에 탁월)등이 있다.
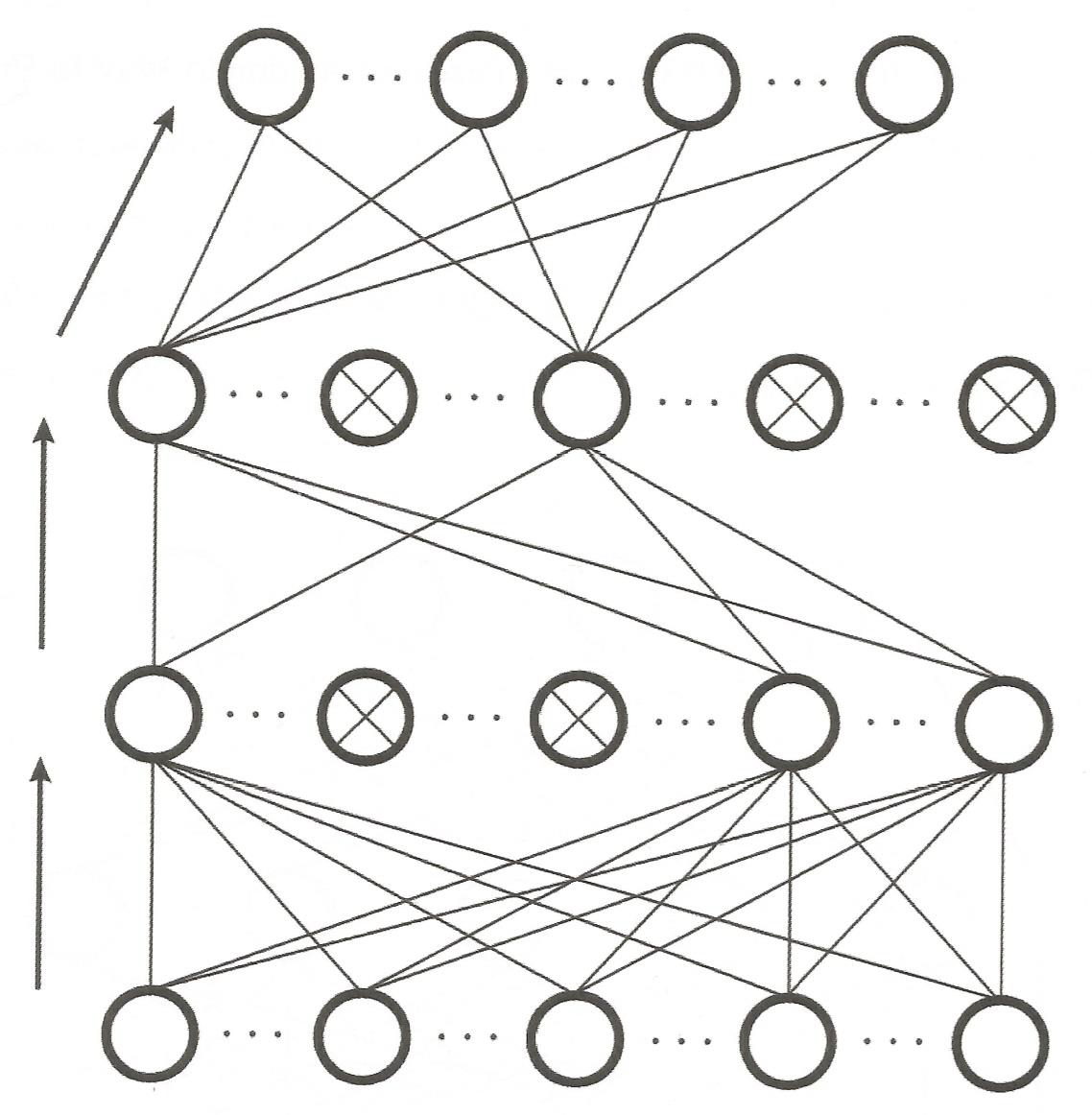
다층 신경망에서 망의 구조가 복잡해질 때의 문제점
다층 신경망에서는 학습 오차를 망 전체에 효율적으로 반영시키기 위해 역전파 알고리즘을 사용한다.
다층 신경망에서 은닉층의 개수가 증가하면 학습 능력이 향상되는 것을 기대하는 것이 일반적!! BUT 실제로는 층이 많아 질수록 기울기 소멸 문제, 과적합 등의 문제가 생긴다.
기울기 소멸 문제
망의 층 수가 적다면 출력층의 오차 역전파는 각 층의 가중치를 원할히 조정하는데 기여하지만 층의 수가 증가하면 역전파가 각층을 통과하면서 오차가 점점 '희석'되어 사라져 버린다. 따라서 가중치를 조정하는데 문제 발생.
오차가 너무 많은 링크의 가중치들에게 분산되어 반영되는 몫이 작아져 가중치 조정에 문제가 발생한다.
과적합 문제
훈련에 사용한 한정된 사례에 너무 특화되어 새로운 사례에 대한 예측의 결과가 오히려 나빠지거나 학습의 효과가 나타나지 않는경우
해결책 ! - 각 층을 단계별로 학습시키는 사전학습과 드롭 아웃 으로 심층 신경망을 구축할 수 있다.
Dropout 알고리즘
심층 신경망의 구축 시 당면하게 되는 과적합 문제의 해결을 위해 제안된 방법
사전 학습이 필요없으며 사전학습에 의존하지 않고도 훨씬 더 간단하고 강력한 형태로 과적합을 방지한다.
모든 유닛이 조밀하게 연결된 망에서는 각 유닛에 역전파된 오차의 크기가 저점 작아지게 되어 기울기 소실 문제가 발생한다.
이 문제를 망을 성글게(sparse) 만들어 해결하는것이 드롭아웃 알고리즘이다.
일반적인 심층 신경망을 구축한 후 매 학습 에폭마다 유닛들중 일부를 강제로 제거한다.
유닛의 제거는 드롭아웃 확률에 따라 결정되고 입력데이터의 특성을 반영하기 위해서 남아있는 뉴런들에게 더 큰 가중치를 부여하게 되어 망이 잘 학습할 수 있도록 한다.
정규화 선형함수를 활성화 함수로 사용
망을 더욱 희박하게 만든다.
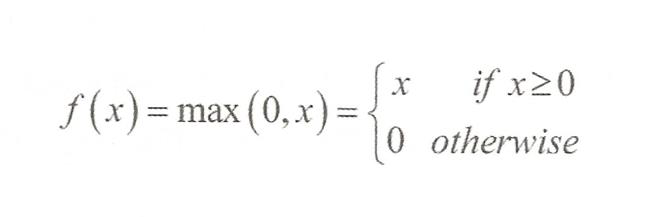
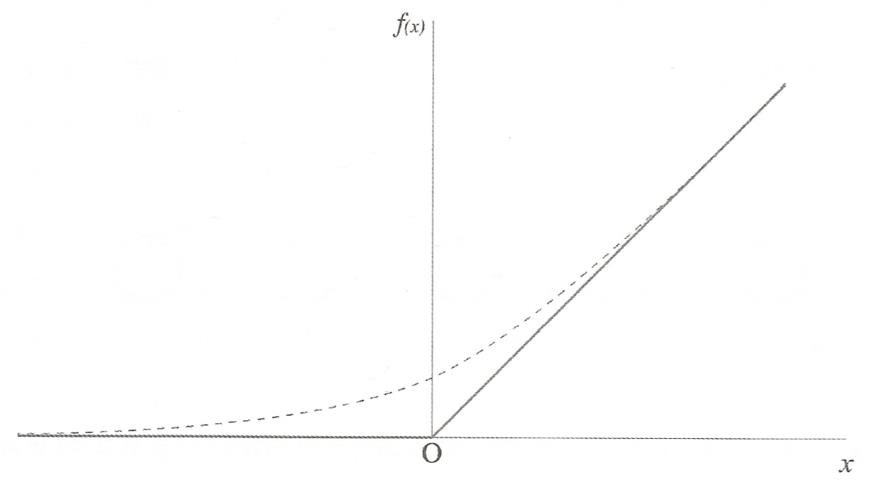
시그모이드 활성화 함수를 쓰지 않는다.
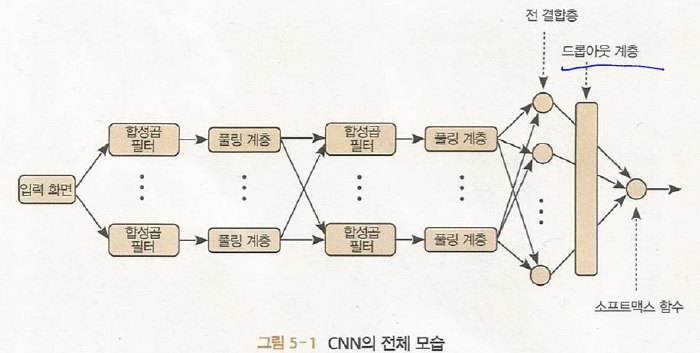
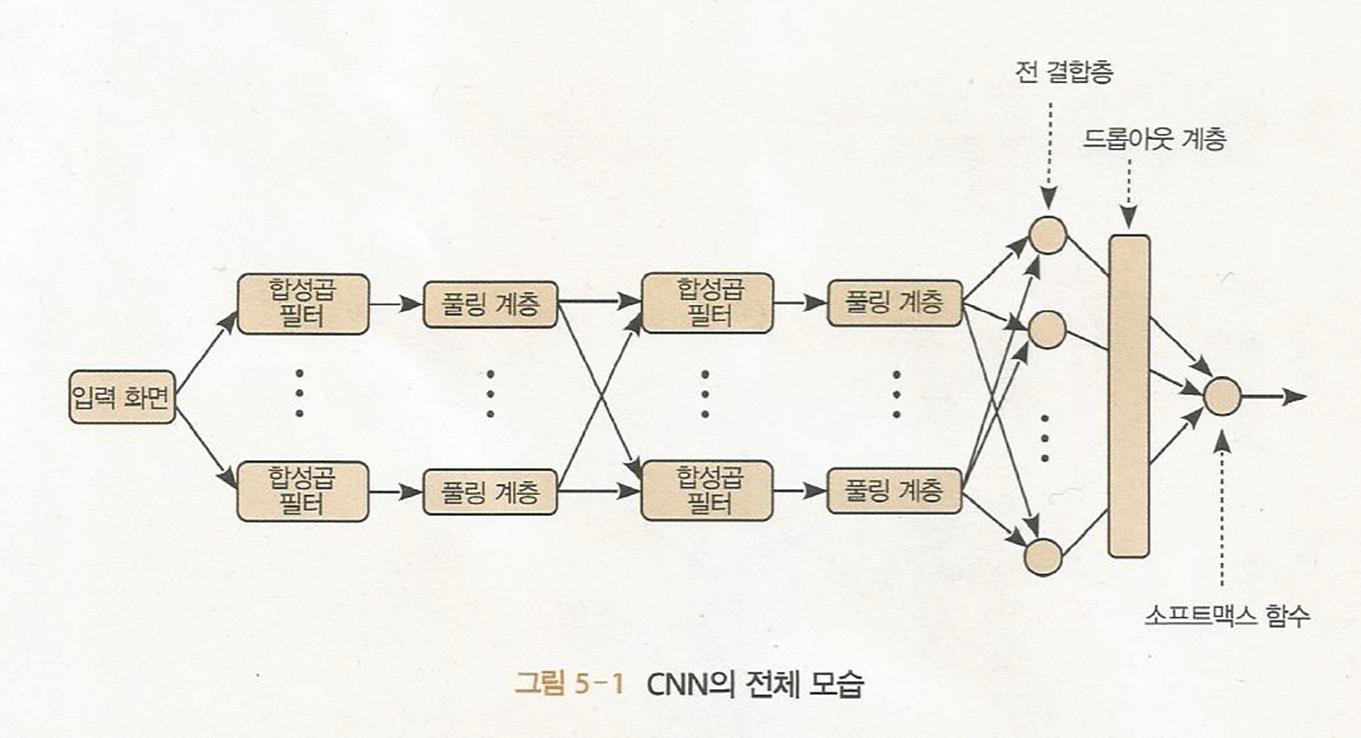
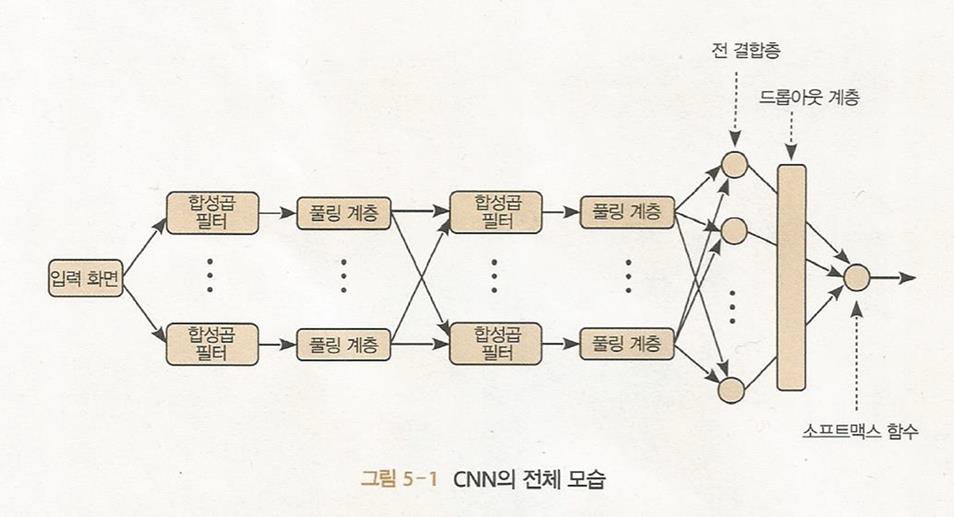
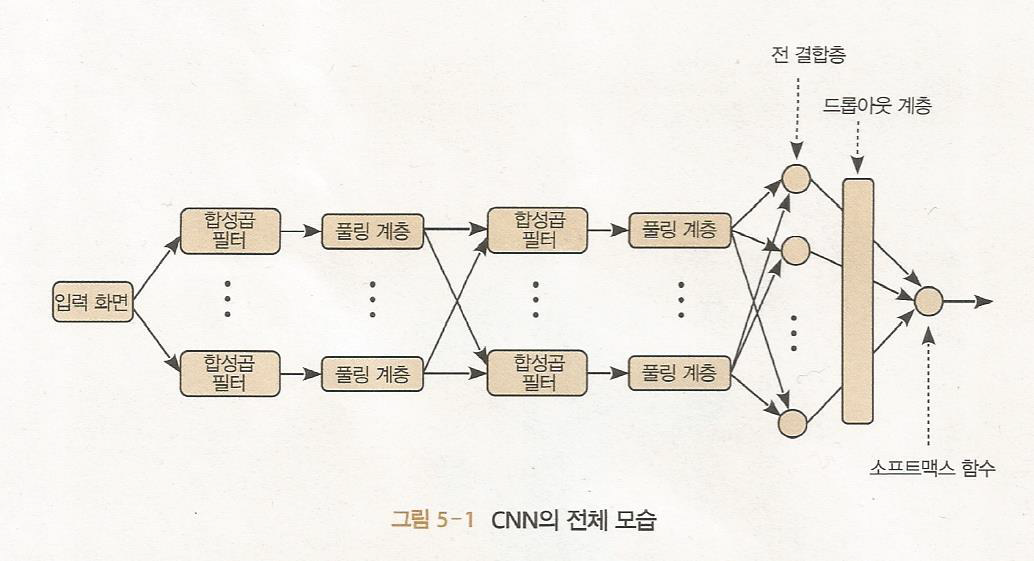
합성곱 신경망(CNN) 이미지에 탁월
CNN은 이미지인식에 적합하게 특화된 몇 가지 타입들의 층들로 구성되어있다.
다수의 합성곱층, 풀링층(부차샘플링층)과 완전 연결 다층 퍼셉트론으로 구성되어있다.
합성곱 필터 - 이미지 특징 추출
풀링 계층 - 해상도를 낮춰 물체의 본질만 추출
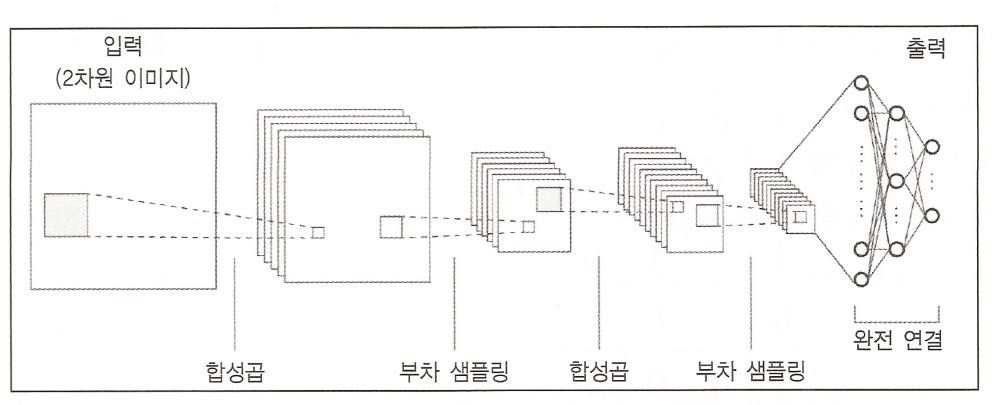
합성곱 층과 풀링층을 통해 2차원 데이터로부터 에지(데이터값이 크게 변화되는 지점)와 수차(영상이 빛깔이 있어보이거나 일그러지는 현상) 같은 특징을 추출하여 다층 퍼셉트론에 입력
다층 퍼셉트론은 이 특징들을 써서 데이터를 적절히 분류한다 - 특징지도!!
합성곱층
합성곱을 수행하면서 특징을 추출하기 위해 여러가지 필터를 학습하는 층
필터들을 커널이라 하며 합성곱한 이미지들을 특징지도라고 함
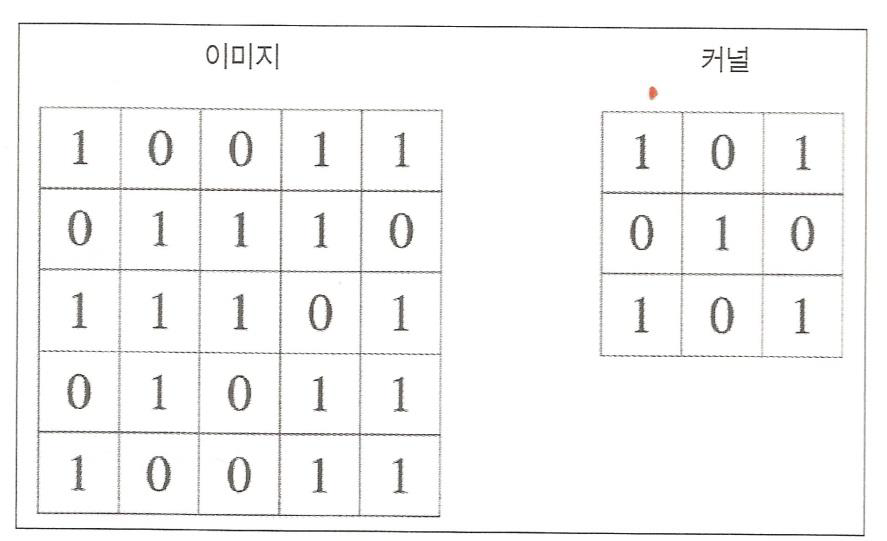
겹치는 부분을 곱하고 다 더한값이 결과이다.
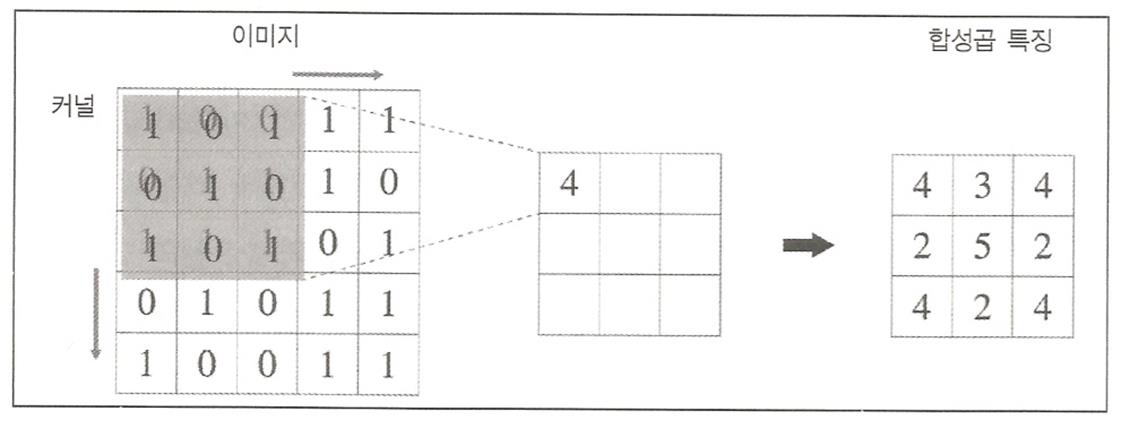 합성곱 연산
합성곱 연산
커널값을 바꾸면 여러가지 다양한 특징들을 추출할 수 있다.
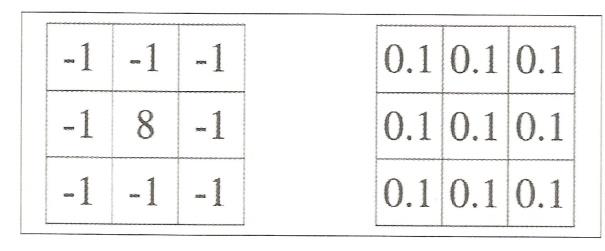
좌측 커널은 색의 차이를 강조하고 이미지의 에지를 출력한다
우측커널은 원래 값을 약화 시켜 흐려진 이미지를 추출
CNN은 학습 알로리즘을 통해 스스로 적당한 커널 값을 학습(CNN에서 학습하는 파라미터는 커널의 가중치)
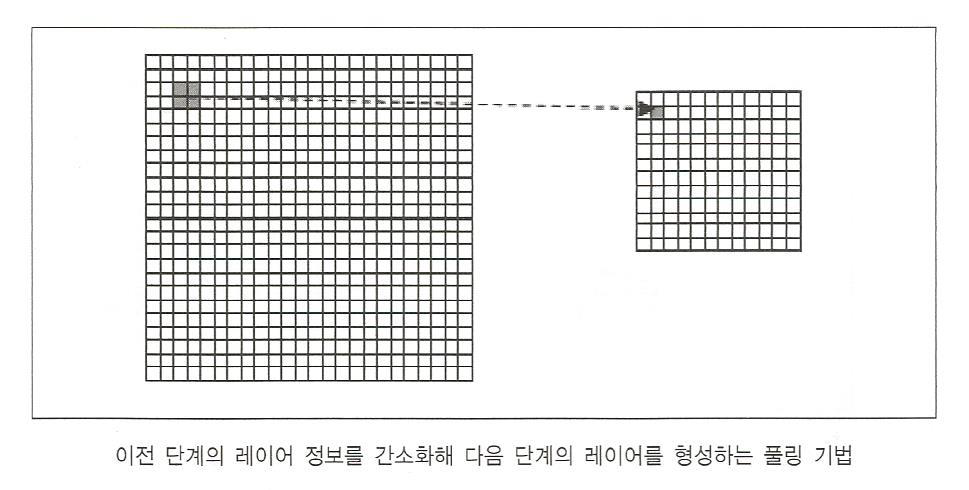
풀링층 -down sampling
학습 과정이 없으며 단순히 합성곱 층에서 전파되어온 이미지들을 다운 샘플링하는 층
해상도를 낮춰 이미지의 세밀한 부분을 지우는 대신 물체의 본질적인 특징만을 추출하기 위해 사용
여러 방법중 최댓값 수집(max-pooling) 방식이 가장많이 쓰인다.
최댓값 수집 방식에는 이미지를 겹치지 않는 부차 영역들로 분할한 후 각각의 부차 영역에서 최대값들만 추출
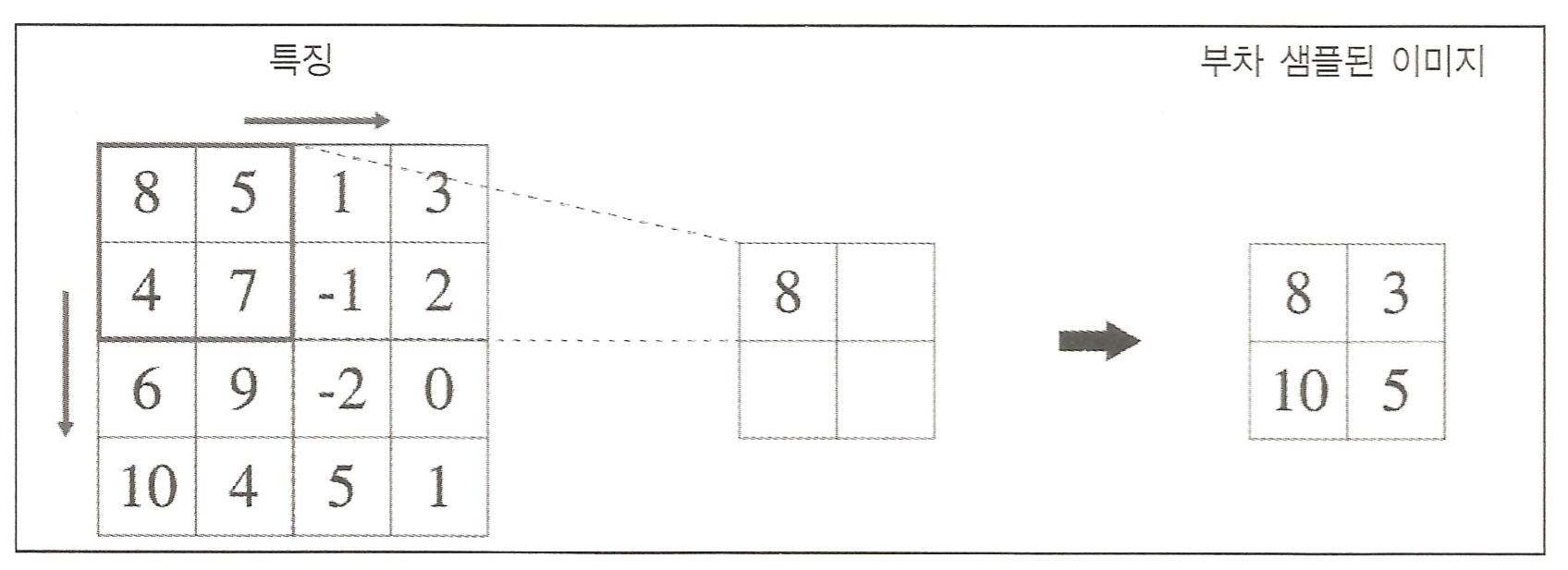
CNN은 합성곱과 풀링을 통해 입력 데이터로부터 강건한 특징들을 추출한다.
완전연결 다층 퍼셉트론
컨볼루션 풀링 연산을 통해 추출된 특징을 사용하여 분류 또는 회귀를 수행하는 다층 퍼셉트론으로 구성
다층 퍼셉트론 부분에는 직전 층으로부터 전방향으로 전체 연결된 층이 반복되어 들어갈 수 있다.
분류 문제에 적용되는 컨볼루션 신경망의 경우 마지막 층은 소프트맥스 연산을 하는 SM층으로 구성하는 것이 일반적 SM층은 각 노드의 출력값이 0이상이고 노드들의 출력의 합이 1이 되도록 하는층
오차함수
앞부분에도 있지만 다시한번더!
신경망 모델의 학습은 오차 함수를 최소화 하는 가중치를 찾는 것. 오차 함수를 최소화 하는 가중치를 찾기 위해 기본적으로 경사하강법 이용
출력층의 출력값이 실수 값인 경우 오차 함수는 오차 제곱이나 오차 제곱의 평균으로 정의
3개이상의 부류가 있는 다부류 분류기의 경우
출력 노드가 부류 개수 만큼있고 각 노드가 해당 부류에 속할 확률을 출력하도록 하는 신경망으로 구현할 수 있다>
출력 노드의 값이 해당 부류에 속할 확률값인 분류기를 신경망으로 구현하려면, 출력 노드의 출력값이 0이상이면서 전체 출력값의 합이 1이 되도록 만들어야한다(이건 시그모이드 함수로!!)
이를 위해 출력층으로 소프트맥스 층을 사용하는데 각 노드의 출력값은 오른쪽의 식에 따라 계산됨.
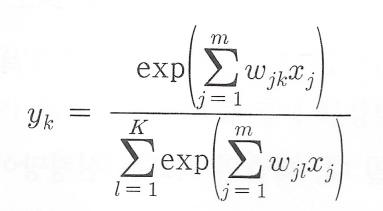
분자- 입력합 분모- 소프트맥스층
다부류 문제에서 학습데이터 (xi,ti)의 조건부 확률은 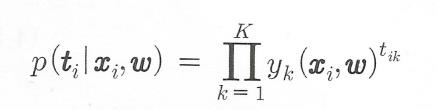
식이 복잡하네..
따라서 전체 데이터 D에 대한 가능도는
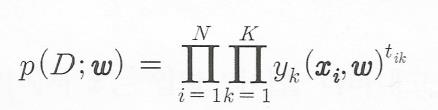
확률이 높을수록 올바르게 분류한다.
위의 식을 최대로 하는 가중치를 찾아야된다~
가능도를 최대로 하는 가중치 차라미터 w가 가장 바람직한 파라미터 가능도를 최대화하는 파라미터를 찾는 것을 최대 가능도 추정이라고 한다.
오차 함수E(w)를 음의 로그 가능도 함수로 다음과 같이 정의
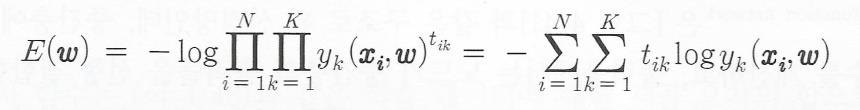
이런것이 있다고만 알아두자
하나의 학습데이터에 대한 오차 함수는 음의로그 가능도 함수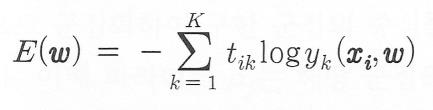
전체 데이터에 대한 가능도를 최대화하는 최대가능도 추정에 따라 가중치 파라미터 w를 결정하는 것은 교차 엔트로피 오차 함수를 최소화하는 가중치 파라미터를 찾는 것과 같다.
CNN프로그램
다시 보면 합성곱 필터~ 풀링 계층은 입력층이다
은닉층은 1024개 이고 출력은 10개이다.
드롭아웃 계층 - 은닉층의 뉴런의 일부를 망에서 제거!
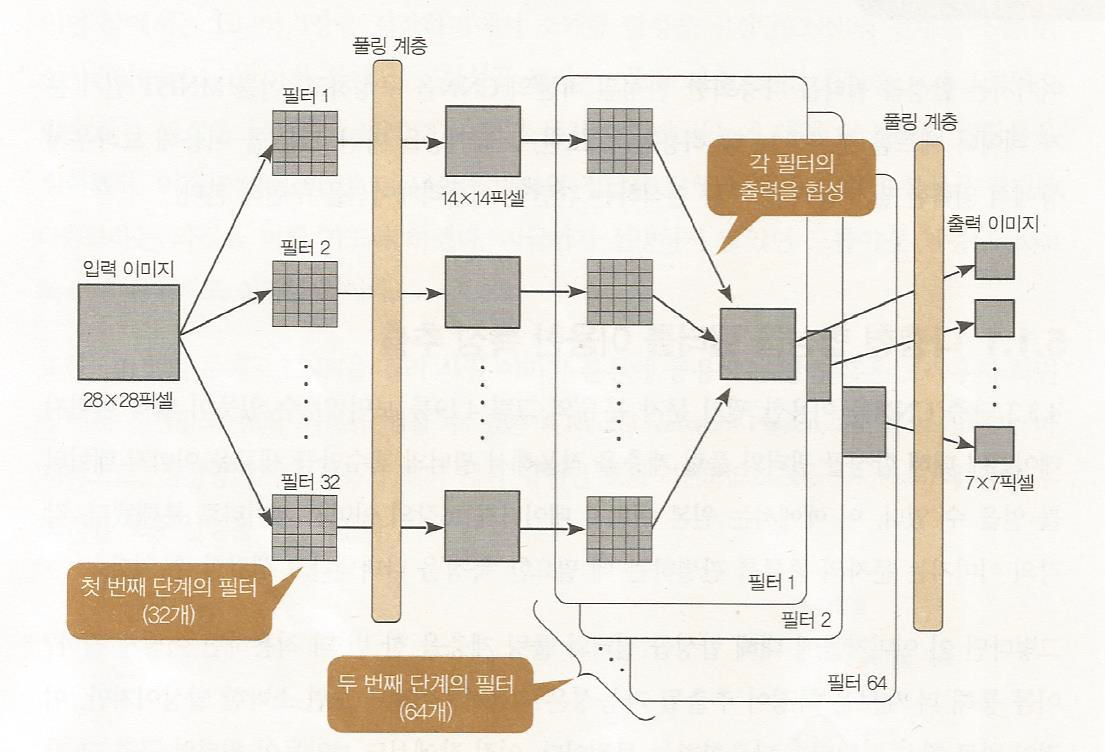
합성곱 신경망의 입력 - 28 x 28 픽셀의 입력이미지기 때문에 784개의 뉴런 필요
첫번째 합성곱층
- 5x5 필터 32개를 통해서(합성곱이용) 24 x 24 픽셀 크기의 32개의 특징지도를 얻어서 출력한다. (크기가 줄어든다)
합성곱 방법은 앞의 게시물에 있다!
같은 크기의 특징지도를 얻을려면
이미지들을 padding을 해준다. 28 x 28 픽셀 사이즈로 유지하려고 모든방향으로 픽셀을 2개씩(값은 0) 추가해서 padding 하고 합성곱을 하면 28 x 28이 유지가 된다.
합성곱 수행과정
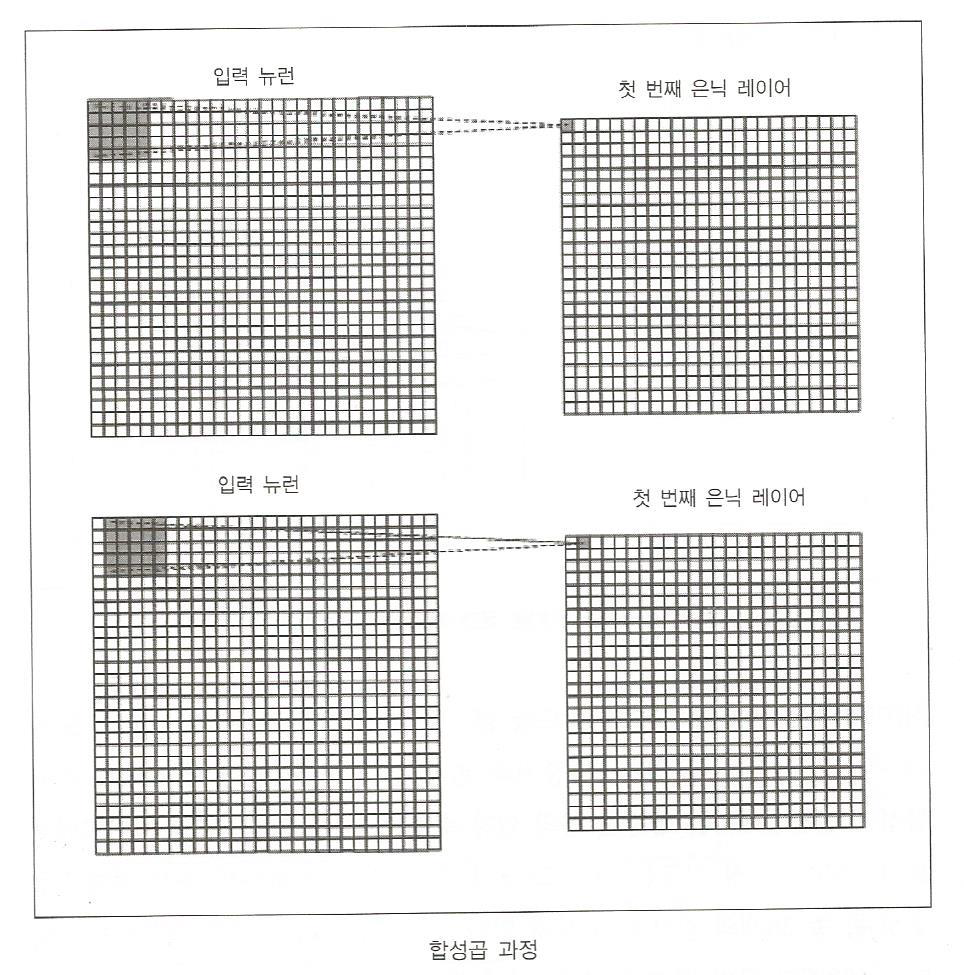
5x5 커널 필터
여기서 가중치 값이 필터의 값이다. 한픽셀씩 이동하면서 합성곱을 수행한다.
이런 뉴런이 31개가 더 존재 (이 사진에서는 padding이 빠져있다)
1번째 풀링층
- 32개의 특징지도를 2x2픽셀 부분영역으로 쪼개고 가장 큰값을 추려서(max-pooling)down sampling한다. 따라서 반으로 줄인 14 x 14 특징지도 32개를 결과로 낸다.
2번째 합성곱층
- 이전 층에서 넘어온 14 x 14 특징지도 32개로 64개의 특징지도를 만든다. 이걸 다음 풀링층으로 넘겨준다.
14 X 14 특징지도로 64개의 새로운 특징지도에 모든방향 padding을해서 18 x 18 픽셀로 만들어서 합성곱을 한다.
필터1의 결과 특징지도 만들어지는 과정 - 풀링층에서 넘어온 32개의 특징지도에 첫번째 행,첫번째열에 5 X 5 필터를 적용해(새로운 필터) 차례대로 합성곱을 수행한뒤 이것들을 다 더한값이 결과 특징지도의 첫번째 행 첫번째 열의 값이다.
필터를 한 픽셀씩 옮긴뒤 모두 더해서 결과 특징지도를 만들어간다.
이 과정을 64개의 다른 필터로 수행
따라서 5x5 픽셀 필터 32개가 한세트이고 총64 세트가 필요하다!!!. 32 X 64 = 2048개의 필터 필요
2번째 풀링계층
두번째 풀링 층에서도 첫번째와 같이 2 x 2부분영역으로 나눠서 최대값을 뽑아서 1/4 사이즈의 결과이미지를 뽑아낸다.
7 X 7 사이즈의 이미지가 64개 생성된다.
이 64개의 이미지가 다층신경망의 은닉층으로 입력된다.
CNN 프로그램
텐서플로우로 실행
CNN-02 - 사례에 대한 data준지
CNN-03
2 - 사례를 2차원 tenser 선언 28 x 28 = 784개
3 - 2차 합성곱에서 쓸려고 4차원으로 바꾸어준다.
4 - 5X5 4차원 필터를 초기화한다.
5 - 사례 data와 필터 가중치와 합성곱을 연산 padding을 결과와 같게 준다.
6 - 필터의 개수만큼 임계값 초기화
7 - 합성곱 연산후 편차를 더해서 결과를 도출한다. (정규화 선형함수 사용)
8 - h_pool1 은 32개의 특징지도 max pooling하여 사이즈가 14 x14 로 줄어든다.
h_pool1의 입력은 14 x 14의 64개의 이미지이다.
CNN-04
1 - 필터의 갯수 선언
2 - 4차원 tensor 초기화
3 - 32개의 특징지도와 가중치 합성곱
h_conv_cutoff = 2번째 합성곱의 14x14의 65개 특징지도 data
6 - 7 X 7 크기의 65개 특징지도를 max pooling한다.
CNN-05
1 - 2차원 배열 형태로 만들어준다.
4 - 가중치 참조
5 - 은닉층 뉴런의 임계치값
6 - 가중치와 넘어온 data의 합성곱
7 - 확률 변수 선언
8 - drop out 적용
11 - softmax함수를 사용 0~1의 결과값이 나온다.
CNN-06
1 - target 목표 출력을 다루기위한 placeholder 선언
2 - loss 정의
3 - loss를 최소화 하기위한 가중치 찾기
4 - equal을 써서 출력값과 target이 일치하는지 확인
CNN-08
매번 500번째 교차 엔트로피의 정확도를 출력한다.
마지막줄 신명망내의 가중치를 file에 저장한다.
필기 문자 자동 인식 프로그램
위에서 나온 가중치로 손글씨 인식 program을 돌릴수 있다.
실제로 사용할때는 dropout을 안한다고 한다.
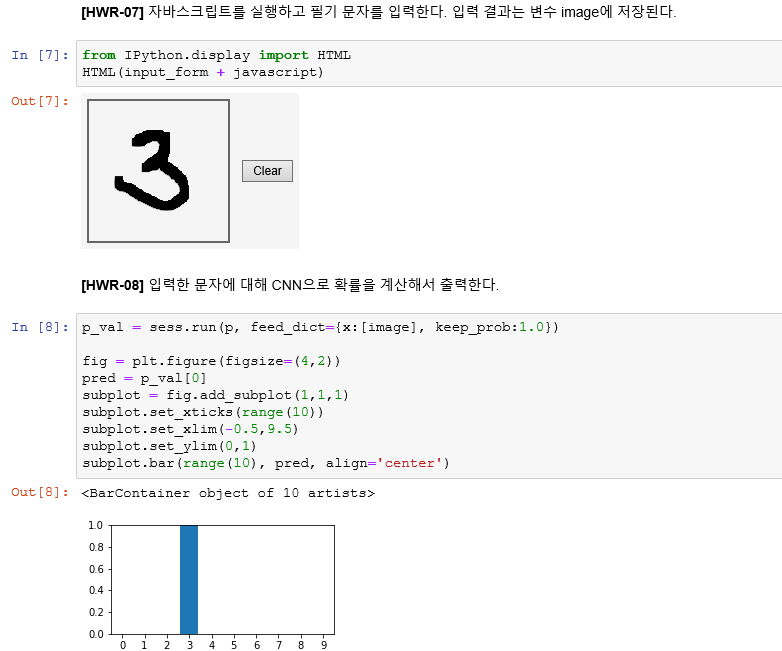
칸에 마우스로 숫자를 그린다.
3일 확률이 1이라는것을 알 수 있다.
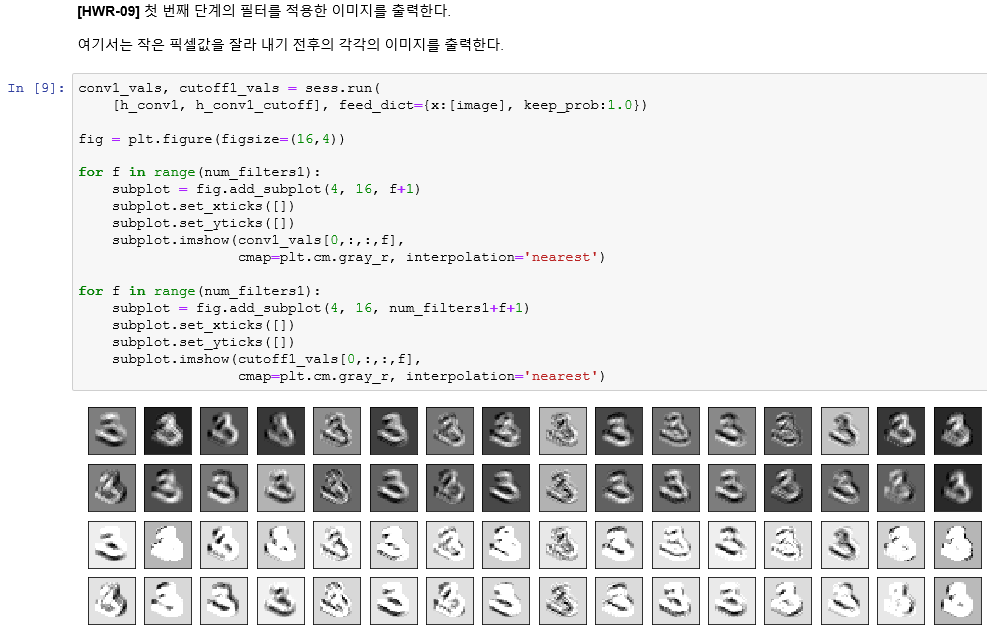
찻반쩨 힙상겁 얀신흐 32개의 출력 특징지도이다.
밑에 2줄이 최종적인 이미지 (첫번째 합성곱층에서 만들어지는)
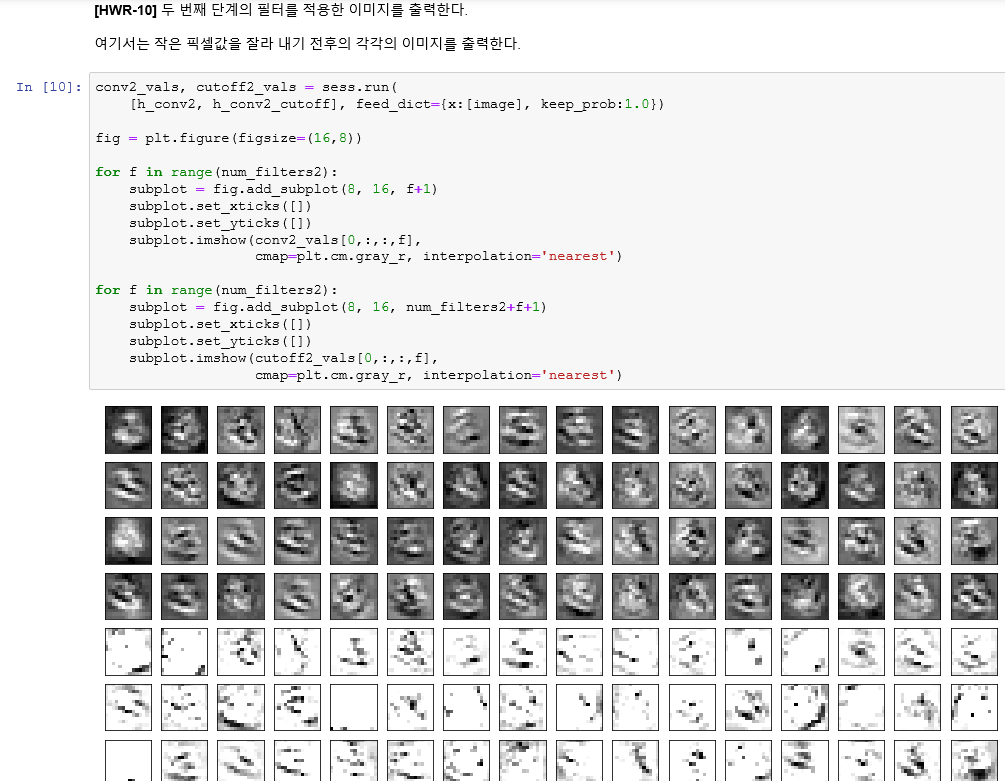
두번째 합성곱 연산의 64개의 특징지도
사전 학습과 심층 신뢰 신경망 적층 노이즈 제거 오토인코더는 수업을 하지 않았다 !
이렇게 심층신경망을 공부해봤는데 굉장히 재미있는 분야 같다. 어떤식으로 활용을 내가 할수 있을지는 고민해봐야겠지만 ! 졸프하는게 어느정도 마무리가 되면 이쪽도 좀 더 공부해 봐야겠다. !
